
经典数据集介绍-数据集制作-YOLOv5参数解读
本笔记是根据小土堆教学视频做的笔记,内容详细,不枯燥。推荐给想要学习目标检测的学生。以下个人笔记供您参考。如有错误,请指正! 目标检测:位置+类别 人脸检测:人脸目标 文本检测:文本目标 主流的目标检测以矩阵框的形式输出 语义分割,如下图,可以达到更高的准确率 VOC数据集介绍 有VOC 2007和VOC 2012 官网:VOC数据集 对于 VOC2012,大部分注释工作都用于增加分割和动作分类数
本笔记是根据小土堆教学视频做的笔记,内容详细,不枯燥。推荐给想要学习目标检测的学生。以下个人笔记供您参考。如有错误,请指正!
目标检测:位置+类别
人脸检测:人脸目标
文本检测:文本目标
主流的目标检测以矩阵框的形式输出
语义分割,如下图,可以达到更高的准确率

VOC数据集介绍
有VOC 2007和VOC 2012
官网:VOC数据集

对于 VOC2012,大部分注释工作都用于增加分割和动作分类数据集的大小,并且没有为分类/检测任务执行额外的注释。下面的列表总结了 VOC2012 和 VOC2011 之间的数据差异。
以 VOC207 为例:
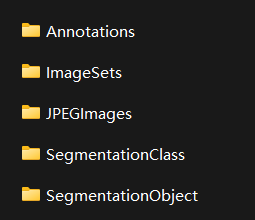
Annotations:包括描述图片各种信息的xml文件,尤其是目标的位置坐标
Imagesets:主要关注Main文件夹的内容。 Main文件夹中的文件包括不同类别目标的训练/验证数据集的图像名称
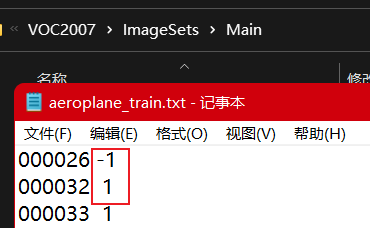
例如:1表示图中有飞机,-1表示没有飞机
JPEGImages:原始图像
SegmentationClass/Object:用于语义分割
COCO数据集介绍

常用的数据集是COCO2017
官网:COCO2017数据集
制作数据集
数据集制作详解
1.获取自己的数据集——手动标注
-
获取自己的数据集——半手动标注(微调标注的数据集)
-
模拟数据集(GAN,数字图像处理方法)(效果可能不是很好)
使用 Roboflow
收集图片
-
对与在野外看到的图像相似的图像进行训练至关重要。从最终部署项目的相同配置中收集各种图像。
-
从一个公共数据集开始训练你的初始模型,然后在推理期间从野外采样图像以迭代改进你的数据集和模型。
创建标签
1.Roboflow Annotate是一个简单的基于 Web 的工具,用于管理和标记您的团队的图像,并以YOLOv5 的注释格式导出它们。
无论您是否使用 Roboflow](https://roboflow.com/annotate?ref=ultralytics)标记图像[,您都可以使用它将数据集转换为 YOLO 格式,创建 YOLOv5 YAML 配置文件,并将其托管以导入到您的训练脚本中。
- 在线网站:数据集制作(makesense)
脚步:
添加维度类别

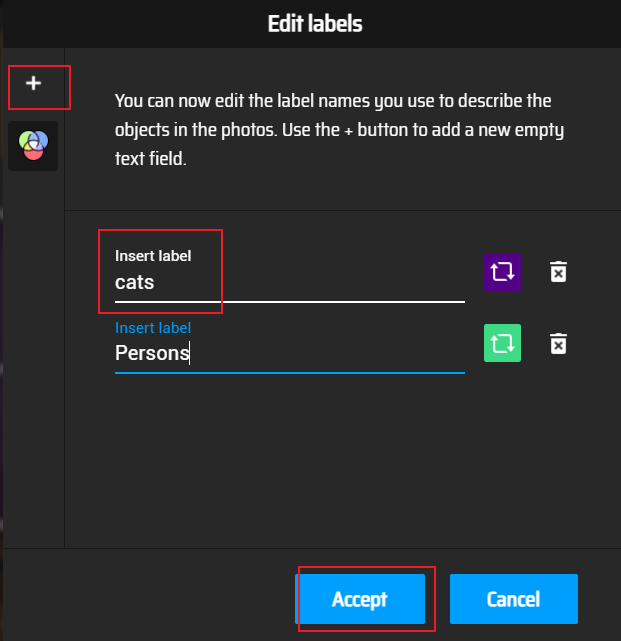
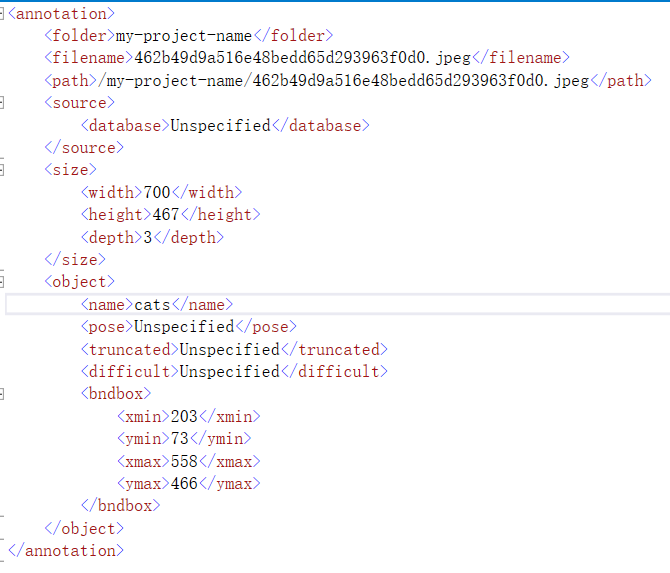
添加类别后,选择图片上要识别的内容框,然后选择右侧的标签类别。标记完所有标签后,在 Actions/Export Annotations 中导出标签。以下是xml文件格式的内容,包括文件名、路径、图片信息、物体对象(标签、坐标矩形框标识物体)等
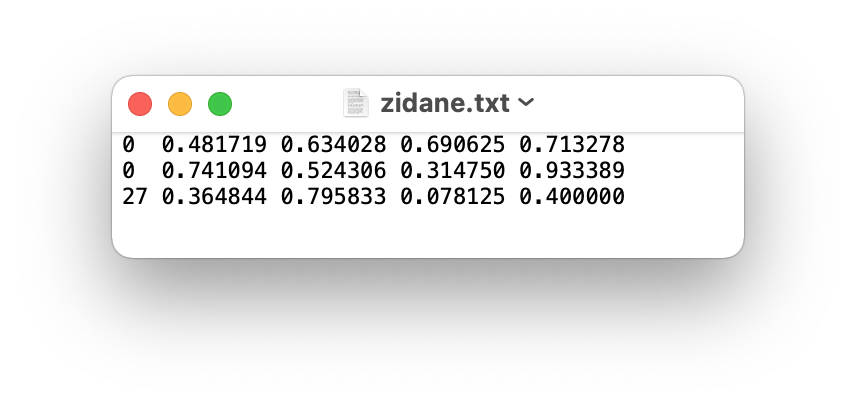
导出的 YOLO 为 txt 格式。内容如下:第一个0/1/2代表类别,第二个和第三个是物体中心的坐标,第四个和第五个是宽高
-
每个对象一行
-
每一行都是类 x_center y_center 宽高格式。
-
框坐标必须是标准化的 xywh 格式(从 0 - 1) 如果您的框以像素为单位,则将 x_center 和 width 除以图像宽度,将 y_center 和 height 除以图像高度。
-
类号是零索引的(从 0 开始)。

您可以选择AI标签,系统会提示您创建尚未创建的标签,并自动在图片上构图对象。点击。
1.多人在线注释
网址:数据集制作(cvat)(需要VPN)

创建任务,添加标签,加载图片并提交。
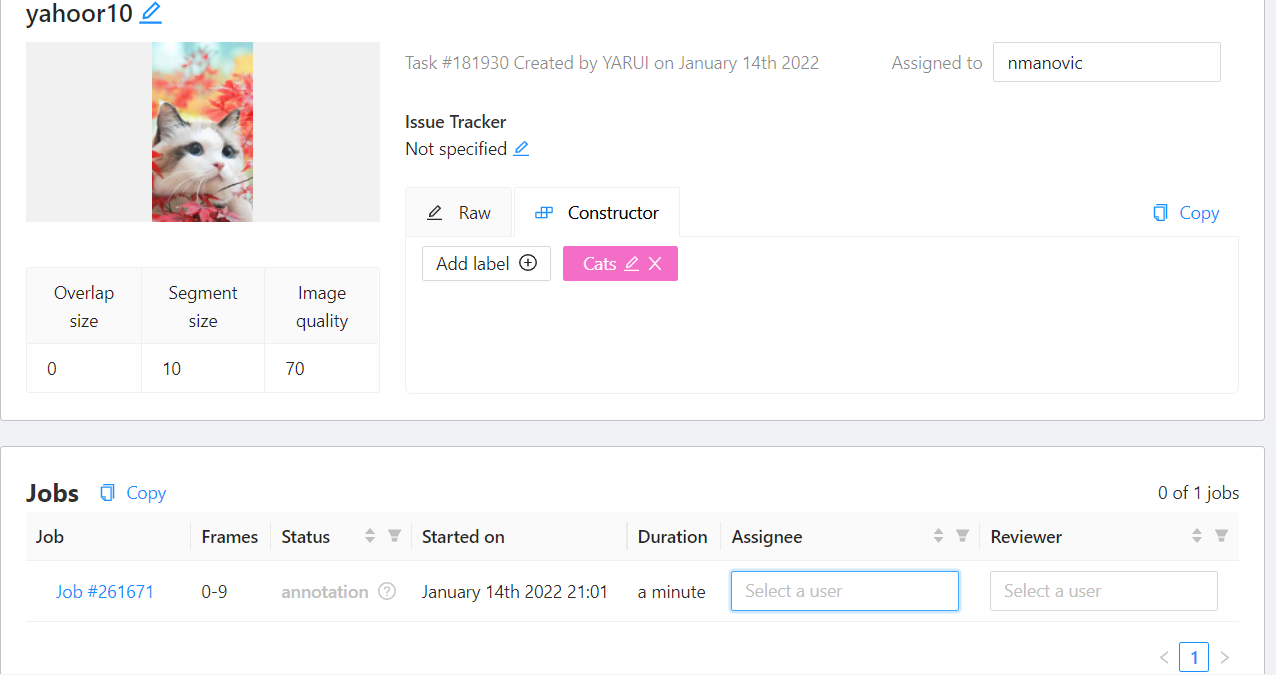
项目可以分配给某些人

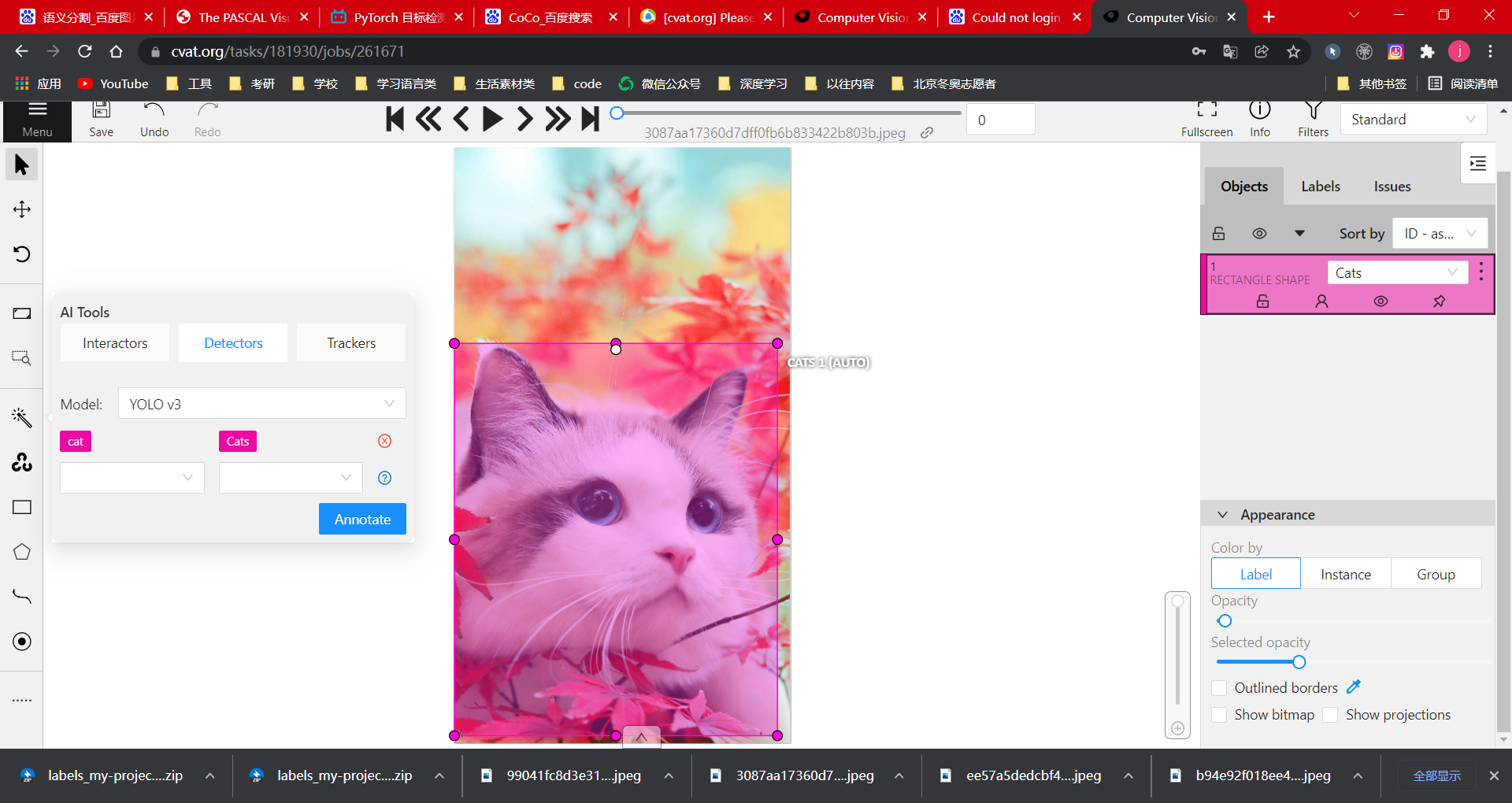
可选择自动识别功能
选择 Detectors,然后为模型选择 YOLO v3。该模型可以识别许多内容。比如选择cat(3)后,会自动识别框选。如果被识别为猫,则将其标记为自己的标签类别,即(4)
导出类型很多,支持COCO类型
可以看到,当用 Pycharm 打开一个 json 文件时,它只会出现在一行上。我们可以按两次shift,选择Action,输入reformat code,将代码调整为json数据格式
手动准备数据集
1.###创建dataset.yaml
根据后续要求修改:
只需要修改dataset的yaml,其他的不要修改
定义的数据集配置文件
1)数据集根目录路径和train / val / test图像目录的相对路径(或带有图像路径的\ * .txt文件),
**3)**类名列表 # 注意标签的顺序,不要颠倒
# Train/val/test 设置为 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2 , ..]
路径:../datasets/coco128 # 数据集根目录
train: images/train2017 # 训练图像(相对于“路径”)128 个图像
val: images/train2017 # val images (relative to 'path') 128 images
测试:# 测试图像(可选)
类
nc: 80 # 类数
名称:[“人”、“自行车”、“汽车”、“摩托车”、“飞机”、“公共汽车”、“火车”、“卡车”、“船”、“红绿灯”、
“消防栓”、“停车标志”、“停车计时器”、“长凳”、“鸟”、“猫”、“狗”、“马”、“羊”、“牛”、
“大象”、“熊”、“斑马”、“长颈鹿”、“背包”、“雨伞”、“手提包”、“领带”、“手提箱”、“飞盘”、
“滑雪板”、“滑雪板”、“运动球”、“风筝”、“棒球棒”、“棒球手套”、“滑板”、“冲浪板”、
“网球拍”、“瓶子”、“酒杯”、“杯子”、“叉子”、“刀”、“勺子”、“碗”、“香蕉”、“苹果”、
“三明治”、“橙子”、“西兰花”、“胡萝卜”、“热狗”、“披萨”、“甜甜圈”、“蛋糕”、“椅子”、“沙发”、
“盆栽”、“床”、“餐桌”、“马桶”、“电视”、“笔记本电脑”、“鼠标”、“遥控器”、“键盘”、“手机”、
“微波炉”、“烤箱”、“烤面包机”、“水槽”、“冰箱”、“书”、“时钟”、“花瓶”、“剪刀”、“泰迪熊”、
'吹风机', '牙刷' ] # 类名
按照方法1收集图片并创建标签,然后按照以下格式创建目录
../datasets/coco128/images/im0.jpg # 主要不改变图片的名字
../datasets/coco128/labels/im0.txt # 主要不改变标签名称

因为检索需要时间,如果item很大,可以把这些数据集的内容放到外面,即右键Mark Directory as/Excluded,其他内容不会被修改
YOLOv5-6.0
下载链接:YOLOv5-6.0
YOLOv5官方代码基于pytoch框架实现
选择对应的加拿大配置环境,通过系统提示Txt包下载需求
如果作者没有提供需求txt文件,根据报错信息手动添加

检测.py
信息设置可以有以下几种形式:本地图片、视频、目录下的文件、实时检测到的视频流
! zwz 100101 zwz 100102 zwz 100100
1.–iu-轮胎
以上图片的选择区域由IOU thres控制,选择最佳结果
! swz 100104 swz 100105 swz 100103
如果需要带一些参数执行,可以在下图中进行配置
! swz 100107 swz 100108 swz 100106
! swz 100110 swz 100111 swz 100109
只识别汽车(2类)并用txt保存测试结果

通过设置 opt u003d parser parse_Args() 设置断点并观察各种参数的值。没有默认值。如果未定义,则为 FALSE
常用参数分析如下:
定义解析_opt():
解析器 u003d argparse.ArgumentParser()
parser.add_argument('--weights', nargsu003d'+', typeu003dstr, defaultu003dROOT / 'yolov5x6.pt', helpu003d'model path(s)')#可以改变网络模型如所须
parser.add_argument('--source', typeu003dstr, defaultu003dROOT / 'data/images', helpu003d'file/dir/URL/glob, 0 for webcam')#中间路径可以是图片/视频。如果是文件夹,将检测所有图像
parser.add_argument('--imgsz', '--img', '--img-size', nargsu003d'+', typeu003dint, defaultu003d[640], helpu003d'推理大小h,w')#IMG大小在训练时会缩放,输入输出一样
parser.add_argument('--conf-thres', typeu003dfloat, defaultu003d0.25, helpu003d'置信度阈值')#置信度,0.25表示概率大于0.25。我认为是这个对象,可以根据需要反复调试
parser.add_argument('--iou-thres', typeu003dfloat, defaultu003d0.45, helpu003d'NMS IoU threshold')#可以从多个方面判断对象,但可以选择最好的一个。当重叠部分与所有框选区域相比达到0.45时,认为是同一个目标,所以不选。如果iou为0,则不存在相交帧
parser.add_argument('--max-det', typeu003dint, defaultu003d1000, helpu003d'每个图像的最大检测数')
parser.add_argument('--device', defaultu003d'', helpu003d'cuda 设备,即0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', actionu003d'store_true', helpu003d'show results')#TRUE 只要--View img 被定义。执行以下帮助
parser.add_argument('--save-txt', actionu003d'store_true', helpu003d'save results to *.txt')#可以保存一些注解
parser.add_argument('--save-conf', actionu003d'store_true', helpu003d'在--save-txt 标签中保存置信度')
parser.add_argument('--save-crop', actionu003d'store_true', helpu003d'保存裁剪的预测框')
parser.add_argument('--nosave', actionu003d'store_true', helpu003d'不保存图像/视频')
parser.add_argument('--classes', nargsu003d'+', typeu003dint, helpu003d'filter by class: --classes 0, or --classes 0 2 3')#'+' 表示可以分配多个值来选择要识别的对象,
parser.add_argument('--agnostic-nms', actionu003d'store_true', helpu003d'class-agnostic NMS')#设置后增强NMS,提升识别概率
parser.add_argument('--augment', actionu003d'store_true', helpu003d'augmented inference')#设置后识别概率增强
parser.add_argument('--visualize', actionu003d'store_true', helpu003d'visualize features')
parser.add_argument('--update', actionu003d'store_true', helpu003d'更新所有模型')
parser.add_argument('--project', defaultu003dROOT / 'runs/detect', helpu003d'save results to project/name')#设置保存路径
parser.add_argument('--name', defaultu003d'exp', helpu003d'保存结果到项目/名称')
parser.add_argument('--exist-ok', actionu003d'store_true', helpu003d'existing project/name ok, do not increment')#是保存在现有文件还是创建一个新文件
parser.add_argument('--line-thickness', defaultu003d3, typeu003dint, helpu003d'边界框厚度(像素)')
parser.add_argument('--hide-labels', defaultu003dFalse, actionu003d'store_true', helpu003d'隐藏标签')
parser.add_argument('--hide-conf', defaultu003dFalse, actionu003d'store_true', helpu003d'hide confidences')
parser.add_argument('--half', actionu003d'store_true', helpu003d'使用FP16半精度推理')
parser.add_argument('--dnn', actionu003d'store_true', helpu003d'使用OpenCV DNN进行ONNX推理')#Opencv接口类型
选择 u003d parser.parse_args()
opt.imgsz *u003d 2 if len(opt.imgsz) u003du003d 1 else 1 # 展开
打印_args(FILE.stem,选择)
返回选择
train.py
1.矩形训练
以前训练会按照指定的方块完成图片(如第一张图),现在只会加一点点(如第二张图),以减少不必要的信息,加快速度训练速度。


1.——简历
根据指定的模型进行训练。注意指定的文件需要放在weights目录下。默认u003d假
- --noautoanchor
采用k-means聚类+遗传算法生成与当前数据集匹配度更高的anchors。如果要使用这个脚本,需要注意两点:
- 训练。 PY_解析opt下的参数noautoanchor必须为False,即未定义,默认开启
2.炒作。刮。 yaml下的anchors参数必须注释掉
k-means是一种非常经典且有效的聚类方法,它通过计算样本之间的距离(相似度)将距离较近的样本聚集到同一类别(聚类)中
k-means算法的主要流程
1.手动设置聚类数K,假设ku003d2;
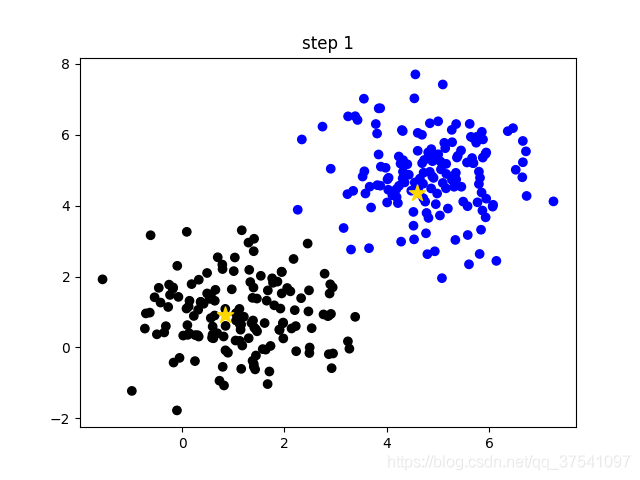
2.在所有样本中,随机选择k个样本作为初始聚类中心。下图中(随机簇),两个黄色小星代表随机初始化的两个簇中心;
3.计算每个样本到每个簇中心的距离(以欧几里得距离为例),然后将样本划分到最近的簇中。如下图(步骤0),不同的簇用不同的颜色区分;
4.更新聚类中心,计算每个聚类中所有样本的平均值(方法不唯一)作为新的聚类中心。如下图(步骤1),两颗黄色小星已经移动到对应星团的中心;
- 重复步骤 3 到 4,直到聚类中心不变或聚类中心变化很小,满足给定的终止条件。如下图(步骤2),最终的聚类结果。
! swz 100128 swz 100129 swz 100127
! zwz 100131 zwz 100132 zwz 100130
! zwz 100137 zwz 100138 zwz 100136
1.——进化
yolov5提供了超参数优化方法——hyperparametric evolution,即超参数进化。超参数进化是一种使用遗传算法(GA)进行超参数优化的方法。我们可以通过这种方法选择更合适的超参数。
提供的默认参数也是通过在 COCO 数据集上使用超参数进化而来的。由于超参数演化会消耗大量资源和时间,如果默认参数的训练结果能够满足你的使用,那么使用默认参数也是一个不错的选择。
1.-四边形
quad 数据加载器是我们认为的一个实验性功能,它可能会在较低的 --img 尺寸下进行更高的 --img 尺寸训练的一些好处。
可以预见,–quad 模型可以在 --img-sizes 大于 640 时运行推理,而普通模型在大于 640 图像大小时性能较差(两个模型都在 --img 640 处训练)。用640大小训练,然后在大于640的图片中会有更好的测试效果
不过比较(总是有比较)是四边形模型在 640 处执行缓慢
- --linear-lr
# 调度器
如果 opt.linear_lr:
lf u003d lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # 线性
其他:
lf u003d one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
如果定义,则以线性方式处理,如果未定义,则以余弦方式处理
1.--标签平滑
神经网络会促使自己朝着正确标签和错误标签最大差异的方向学习。当训练数据较少,不足以代表所有样本特征时,会导致网络过拟合。
标签平滑可以解决上述问题。这是一种正则化策略,主要是通过soft one hot来增加噪声,在计算损失函数时降低真实样本标签类别的权重,最后抑制过拟合。
相关参数如下:
parser.add_argument('--weights', typeu003dstr, defaultu003dROOT / '', helpu003d'initial weights path')#当你添加yolov5s从模型加载pt或者其他模型文件时,默认情况下从头开始训练可以为空
parser.add_argument('--cfg', typeu003dstr, defaultu003d'models/yolov5x.yaml', helpu003d'model.yaml path')#加载模型配置,在yaml中有模型,根据模型/yolov5x Yaml结构训练模型
parser.add_argument('--data', typeu003dstr, defaultu003dROOT / 'data/coco128.yaml', helpu003d'dataset.yaml path')#数据集路径可以是coco128 yaml,coco.yaml ,VOC.yaml,Argoverse.yaml
parser.add_argument('--hyp', typeu003dstr, defaultu003dROOT / 'data/hyps/hyp.scratch.yaml', helpu003d'hyperparameters path')#hyperparameters
parser.add_argument('--epochs', typeu003dint, defaultu003d300)#训练轮数
parser.add_argument('--batch-size', typeu003dint, defaultu003d16, helpu003d'total batch size for all GPUs')#设置batch_size,一组图片放多少
parser.add_argument('--imgsz', '--img', '--img-size', typeu003dint, defaultu003d640, helpu003d'train, val image size (pixels)')#设置图片尺寸统一
parser.add_argument('--rect', actionu003d'store_true', helpu003d'rectangular training')#没有默认值。定义后执行帮助内容。矩形是矩阵的训练方法
parser.add_argument('--resume', nargsu003d'?', constu003dTrue, defaultu003d'runs/train/exp/weights/last.pt', helpu003d'恢复最近的训练')#Train基于指定的模型。注意指定的文件需要放在weights目录下。默认u003d假
parser.add_argument('--nosave', actionu003d'store_true', helpu003d'只保存最终检查点')#看帮助
parser.add_argument('--noval', actionu003d'store_true', helpu003d'only validate final epoch')
parser.add_argument('--noautoanchor', actionu003d'store_true', helpu003d'disable autoanchor check')#一般不定义
parser.add_argument('--evolve', typeu003dint, nargsu003d'?', constu003d300, helpu003d'evolve hyperparameters for x generation')
parser.add_argument('--bucket', typeu003dstr, defaultu003d'', helpu003d'gsutil bucket')#没关系
parser.add_argument('--cache', typeu003dstr, nargsu003d'?', constu003d'ram', helpu003d'--将图像缓存在“ram”(默认)或“disk”')#缓存以获得更好的训练
parser.add_argument('--image-weights', actionu003d'store_true', helpu003d'使用加权图像选择进行训练')#对于一些表现不佳的test,下一轮的训练,增加重量,但效果不是很好
parser.add_argument('--device', defaultu003d'', helpu003d'cuda 设备,即0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', actionu003d'store_true', helpu003d'vary img-size +/- 50%%')
parser.add_argument('--single-cls', actionu003d'store_true', helpu003d'将多类数据训练为单类')#训练列表类别
parser.add_argument('--adam', actionu003d'store_true', helpu003d'use torch.optim.Adam() 优化器')#如果定义,则使用优化器,默认为随机梯度下降
parser.add_argument('--sync-bn', actionu003d'store_true', helpu003d'使用SyncBatchNorm, 仅在DDP模式下可用')#DDP适用于多GPU分布
parser.add_argument('--workers', typeu003dint, defaultu003d0, helpu003d'dataloader workers的最大数量')#这个参数最好从小调整

学AI,认准AI Studio!GPU算力,限时免费领,邀请好友解锁更多惊喜福利 >>>
更多推荐

 0
0 0
0- 0



 已为社区贡献126467条内容
已为社区贡献126467条内容

所有评论(0)