病历图片pdf转文本的方法
任务:提取病历。一些医疗记录存在于 pdf 书籍中,但这些 PDF 是图片格式。这些内容需要转换成文本内容。
思路:将pdf文件转换成单张图片集,然后ocr识别单张图片,拼接识别出来的文字。
使用pypdf2模块读取pdf和二进制内容,使用wand模块将页面转换为图片并保存。
1 阅读pdf并转换成图片
安装 pypdf2 包。
点安装 pypdf2
安装python包:wand
点安装魔杖
魔杖的文件:https://docs.wand-py.org/
上码:
导入 io
从 wand.image 导入图像
从 wand.color 导入颜色
从 PyPDF2 导入 PdfFileReader、PdfFileWriter
导入 json
备忘录 u003d {}
使用 PyPDF2 的 PdfFileReader 读取 pdf 文件
def getPdfReader(文件名):
阅读器 u003d memo.get(文件名,无)
如果读者是无:
阅读器 u003d PdfFileReader(文件名,严格 u003d 假)
备忘录[文件名] u003d 阅读器
返回读者
将带页码的pdf页面转换成图片格式
def _run_convert(文件名,页面,resu003d120):
idx u003d 页 + 1
pdfile u003d getPdfReader(文件名)
pageObj u003d pdfile.getPage(page) # 页面从 0 开始
dst_pdf u003d PdfFileWriter()
dst_pdf.addPage(pageObj)
pdf_bytes u003d io.BytesIO()
dst_pdf.write(pdf_bytes)
pdf_bytes.seek(0)
img u003d 图片(文件u003dpdf_bytes,分辨率u003dres)
img.format u003d 'png'
图像.压缩\质量 u003d 100
img.background_color u003d 颜色(“白色”)
img_path u003d '{}{}.png'.format(文件名[:filename.rindex('.')], idx)
img.save(文件名u003dimg_path)
img.destroy()
执行后会报错,缺少ImageMagick。
安装 ImageMagick
ImageMagick 是一个免费的开源图像编辑软件。它可以从命令行使用,也可以通过 C/C++、Perl、Java、PHP、Python 或 Ruby 调用库进行编程。 ImageMagic 的主要关注点是性能,减少 bug 并提供稳定的 API 和 ABI。
下载地址:https://imagemagick.org/scrip...
使用方法参考:https://www.cnblogs.com/Renyi...
之后,继续报错,缺少另一个软件Ghostscript。
wand.exceptions.DelegateError: FailedToExecuteCommand `"gswin64c.exe" -q -dQUIET -dSAFER -dBATCH -dNOPAUSE -dNOPROMPT -dMaxBitmapu003d500000000 -dAlignToPixelsu003d0 -dGridFitTTu003d2 "-sDEVICEu003dpngalpha" -dTextAlphaBitsu003d4 - dGraphicsAlphaBitsu003d4 "-r120x120" -dPrintedu003dfalse "-sOutputFileu003dC:/Users/ADMINI~1/AppData/Local/Temp/magick-ZsQSfEM-CFt6Gr4NZ7mUFFR2UbaYvaQr%d" "-fC:/Users/ADMINI~1/AppData /Local/Temp/magick-eT1ogBLBCjx3Tm4r2jidCDxbn3jmkZw6" "-fC:/Users/ADMINI~1/AppData/Local/Temp/magick-UaYBnaqm--_f0Gm6CSzMe8LnumhQQ16A"' ��
) @error/delegate.c/ExternalDelegateCommand/516
说明系统中没有ghostscript软件,需要安装ghostscript。 Ghostscript 是一套基于 Adobe、PostScript 和可移植文档格式 (PDF) 的页面描述语言编译的免费软件。 Ghostscript 是 ImageMagick 的基本组成部分。
下载地址:https://ghostscript.com/relea...
您可以下载适用于 Windows(64 位)的 Ghostscript 9.55.0。
至此,图片就可以生成了。

2调用百度智能云识别文字
首先,你需要有一个百度账号才能注册。拥有帐户后,您还需要创建一个“应用程序”。
打开https://cloud.baidu.com/produ...,在“产品”-“人工智能”-“OCR字符识别”下选择“通用场景字符识别”。
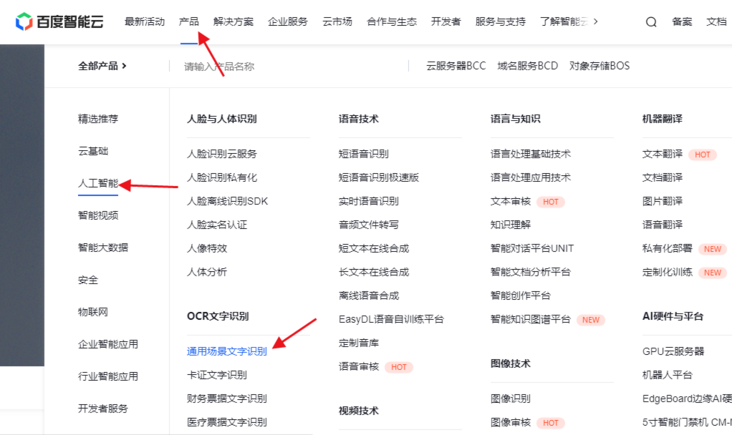
然后,点击下图中的“立即使用”。
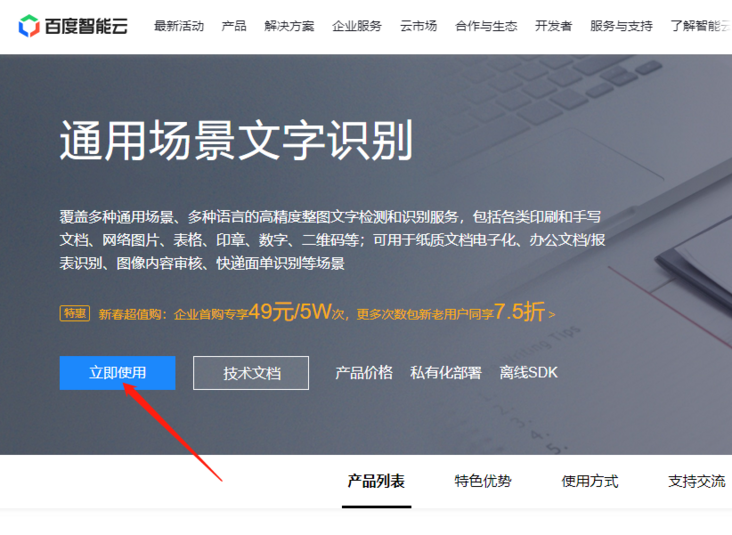
然后点击下图中的“创建应用”。
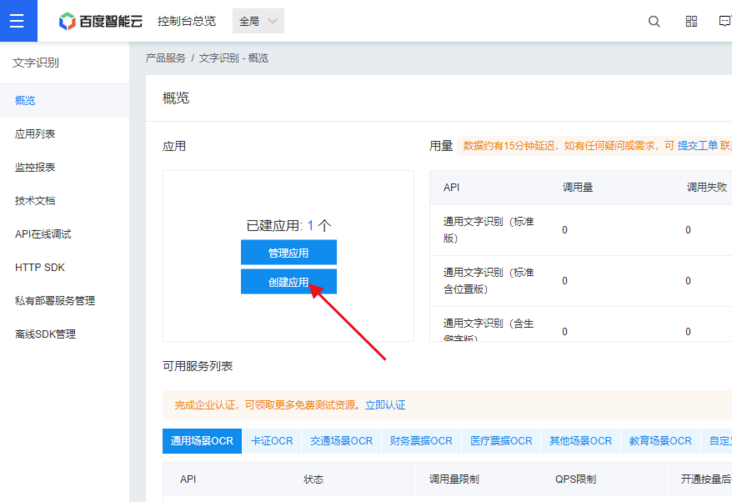
填写信息后,将创建一个应用程序。我创建的是“病历识别”。
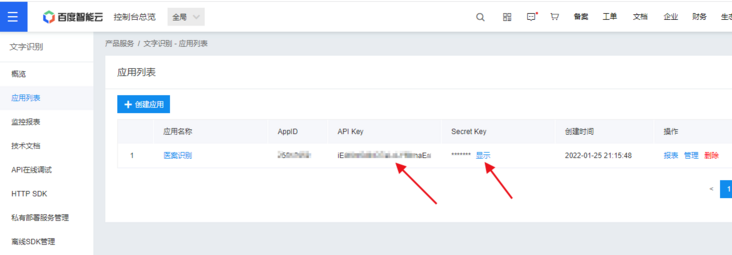
上图中,APIKey和Secret Key就是我们接下来需要用到的。
上码:
def ocr_baidu(文件名,访问权限_token):
编码:utf-8
'''
通用字符识别
'''
请求_url u003d "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
以二进制方式打开图片文件
f u003d 打开(文件名,'rb')
img u003d base64.b64encode(f.read())
参数 u003d {“图像”:img}
access_token u003d '[调用认证接口获取的token]'
请求\url u003d 请求\url + "?access_tokenu003d" + access_token
标头 u003d {'content-type': 'application/x-www-form-urlencoded'}
response u003d requests.post(request_url, datau003dparams, headersu003dheaders)
如果响应:
打印(response.json())
对于 response.json().get("words_result") 中的单词:
# print(words.get("words"))
打印(字)
返回 response.json().get("words_result")
其他:
返回无
最终结果是一个列表,其中包含一个以单词为key的字典,如下图所示:
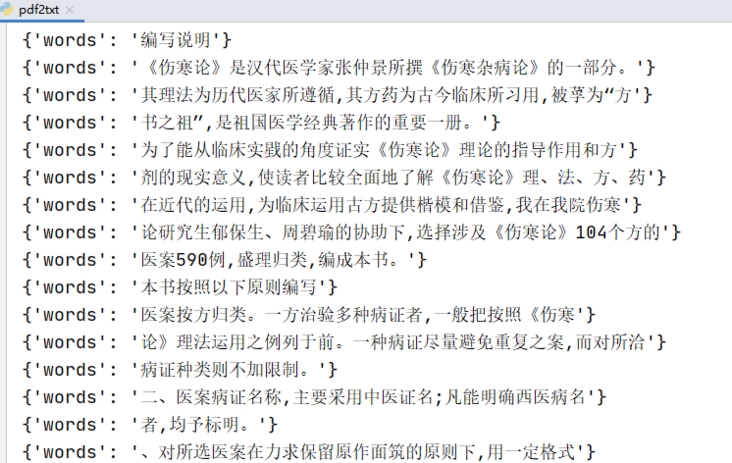
3 合并文本
比如“写作说明”应该是标题,第二个到第三个值组合成一个段落。最好的方法应该是使用nlp技术进行语义识别。在这里,我们只是做字符识别,不是很准确。
上码:
def 是_ChineseMarks(char):
如果 char u003du003d "." 或 char u003du003d "?" 或 char u003du003d "!"或 char u003du003d """ 或 char u003du003d ": ":
返回真
其他:
返回错误
def merge2txt(words_list, line_max_numu003d26, title_max_numu003d10):
'''
{'words': '准备说明'}
{'字':'<伤寒论是汉代医学家张仲景《伤寒杂病论》的一部分。'}
{'字':'其原理和方法为历代医家所遵循,其方剂为古今临床常用,尊为“方”'}
{'字':'《书始祖》,是中国医学典籍的重要一卷。'}
1.Title:如果 words 对应字符串的长度小于title_max_num,并且No.如果数字结束,则表示当前是一个title。
2.Paragraph:如果最后一个字符是。句号,且长度小于line_max_num,表示当前是一个段落。
:param words_list:
:param line_max_num:
:param 标题_max_num:
:return: 合并后的文本内容
'''
txt u003d ""
for i in words_list:
单词 u003d str(i.get("单词"))
if (not is_ChineseMarks(words[-1])) 和 len(words) <u003d title_max_num:
txt +u003d " " # 8 个空格
txt +u003d 单词
txt +u003d "\n"
elif is_ChineseMarks(words[-1]) 和 len(words) <u003d line_max_num:
txt +u003d 单词
txt +u003d "\n"
txt +u003d " " # 4个空格,表示段落的开头
其他:
如果 txt.endswith("\n"):
txt +u003d " "#4个空格,表示段落的开头
txt +u003d 单词
返回 txt
调用百度的ocr服务也需要访问_token,这个访问_token是由创建应用所使用的API Key和Secret key生成的。可以参考百度的文档:https://ai.baidu.com/ai-doc/R...
获取\token() 代码:
定义获取_token():
#client_id为官网获取的AK和client_secret为官网获取的SK
client_id u003d "使用你的 API 密钥"
client_secret u003d "使用你的密钥"
主机 u003d 'https://aip.baidubce.com/oauth/2.0/token?grant_typeu003dclient_credentials&client_idu003d' + client_id + '&client_secretu003d' + client_secret
响应 u003d requests.get(主机)
打印(主机)
打印(response.content)
如果响应:
access\token u003d response.json().get("access\token")
返回访问权限_token
上层主要功能:
如果 __name__ u003du003d "__main__":
filename u003d "G:\数据\上课;上课开始\网络编程\2018\网络\病历pdf传输文本\温病论医疗案例选编\选编伤寒论医案汇编.pdf"
_run_convert(文件名, 3)
访问\令牌 u003d 获取\令牌()
filename u003d "G:\数据\上课;上课开始\网络编程\2018\网络\病历pdf传输文本\温病论医学案例选编\医学选编伤寒论例4.png"
words_list u003d ocr_baidu(文件名,访问权限_token)
txt u003d merge2txt(words_list,26,10)
打印(txt)
合并后得到的结果如下:

原图如下:

可以看出识别率还是有一些问题的。百度的ocr识别率毋庸置疑。应该是中国最好的。关键问题可能是pdf生成图片时像素不够,导致图片不清晰。这个问题的解决方法会写在下一篇文章中。

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126440条内容
已为社区贡献126440条内容

所有评论(0)