阿帕奇气流。如何让复杂的工作流程变得轻而易举
简介
几周前,我开始根据功能请求使用这个平台。该功能与 GCP、观测和要处理的大量数据相关联。我一直在寻找真正强大的东西,以使创建和运行工作的流程变得简单而干净。我们也不应该忘记一致性、容错性和正确的错误处理。
我的研究将我带到了编排主题,尤其是 Apache Airflow。
为什么需要编排?
如果您只是将一些数据导出到 Excel 的简单任务,那么您可能根本不需要使用编排。但是,如果您正在处理数据,在处理后为您带来非常好的利润,或者您主要每天处理大量非干净数据 - 似乎您是在正确的地方开始考虑它.
例如,如果您的公司处理大量数据并为您的客户提供良好的建议并从中获利,那么几乎在所有情况下工作流程都是相同的。每天晚上,在 S3 存储桶/Azure Blob 存储中的某个地方,您的提供者都会在其中创建一些包含原始数据的文件。其次,您收集该数据并在结构上对其进行聚合(例如,推送到 BigQuery 表)。此外,您使用复杂的 SQL 脚本处理它,进行(再次)聚合,并修补一些无效数据。之后,您需要使用一些外部 API(甚至可能是您的特殊服务)检查该数据,但是数据量太大而无法在没有并行性或队列处理的情况下开始工作。最后,在验证之后,您需要将最终结果与一些数据预览工具(如 Tableau 仪表板)连接起来,以将其展示给您的客户。
正如我们所看到的,这个过程乍一看并不那么容易。在现实生活中还有更多的案例(管道)需要处理。
因此,您需要有一个工作流管理器。在过去的几年里,事实上,这就是 Apace Airflow。
历史
Airflow 诞生于 2014 年,就像 Airbnb 的一个内部项目。从一开始,它就是一个开源项目,因此很容易通过 PR 尽可能快地提供适当的功能。 2016 年,该项目转移到 Apache Incubator,2019 年 Airflow 成为 Apache Software Foundation 的顶级项目。
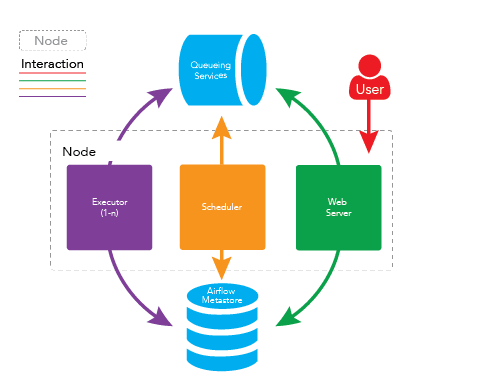
组件
Airflow 是一个 python 项目,所以几乎所有的功能都是 python 代码。
要开始使用 Airflow,您需要提供配置。并且配置很大程度上取决于将完成这项工作的并行任务的数量。
此外,还有一些必需的组件,这些组件将始终在您的清单中检测到:
-
元数据数据库 - 数据库,Airflow 在其中保存有关当前和过去任务、法规和结果的所有元信息。我会在这里推荐使用 Postgres(更稳定和有效的工作流程),但也有 MYSQL、MSSQL 和 SQLite 的配置和连接。
-
Scheduler - 系统组件,它解析带有管道描述的文件并将它们推送到
Executor -
Web Server - 基于 Flask 的应用程序,通过 gunicorn 运行。主要目标是直观地显示管道过程并提供对它的控制。
-
Executor - 特殊部分,运行代码(作业)(见执行)
此外,还有一些依赖于任务的组件:
-
Triggerer - 以一种简单的方式 - 是异步操作符的事件循环。目前,它们并不多,因此,您需要在工作流程中考虑
Triggerer组件 -
Worker - 来自 Celery lib 的修改后的 worker。 Celery 可以运行您的任务的小节点。
执行
描述作业的 Python 代码必须在某处执行。这部分属于Executor。 Airflow 支持下一种执行器:
-
SequentialExecutor - 在本地运行代码,在 Airflow 的主线程中;
-
LocalExecutor - 在本地运行代码,但在OS的不同进程中
-
CeleryExecutor - 在 Celery worker 中完成工作(Celery lib)
-
DaskExecutor - 在 Dask 集群中
-
KubernetesExecutor - 在 k8 pod 中
根据我的经验,生产代码基于 Celery/Kubernetes 执行器。您需要记住这一事实,因为您必须小心管道中任务之间的依赖关系。每个任务都将在其隔离的环境中运行,并且很有可能在不同的物理设备(计算机)上运行。因此,“将文件下载到磁盘”和“将文件上传到云存储”的任务顺序将无法正常工作。更详细的信息可以在这里找到
如您所见,Airflow 是非常可定制的。可以以大多数自定义方式进行配置,以尽可能接近要求。
一般来说,有 2 种最广泛的架构:单节点和多节点:

安装
有几种方法可以安装 Apache Airflow。让我们检查一下。
- PIP 包管理器
不是一个简单的方法。首先,您需要在安装和配置数据库之后安装所有依赖项(使用 SQLite,您只能使用SequentialExecutor)。一个好的做法是初始化 python 虚拟环境,然后开始使用 Airflow:
python -m pip install apache-airflow
airflow webserver
airflow scheduler
进入全屏模式 退出全屏模式
- 分离的 Docker 镜像
当您尝试在裸机服务器上运行 Airflow 时,我发现这很有用。
docker run … postgres
docker run … apache/airflow scheduler
docker run … apache/airflow webserver
进入全屏模式 退出全屏模式
- Docker 撰写
在我看来 - 干净简单的方法。您只需要创建一个包含所有配置的 docker-compose 文件,这样您就可以重用不同的变量和连接:
docker compose up
进入全屏模式 退出全屏模式
- 天文学家 CLI
我没有用这个工具做太多工作,但它周围有一个很好的社区。此外,他们有一个用于任何钩子/操作符的内部注册表,这将简化 Airflow 的工作过程。
基本概念
这个故事的主要实体是 DAG(有向无环图)——任务的管家。它的传播标题,你可以用不同的语言来认识它。
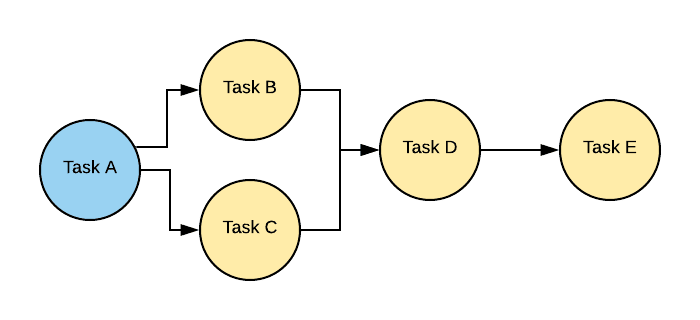
这个图的边是Task,它是Operator的一个实例。
所有的算子,大体上可以分为:
-
Action operator - 做一些动作(ReloadJobOperator等)
-
Transfer operator - 将数据从一个地方迁移到另一个地方(S3ToGCPOperator)
-
传感器操作员 - 等待一些操作 (BQTablePartitionSensor)
每个管道都在Task Instance内部工作 - 具有时间跨度的运算符实例(当此运算符启动时)。您还可以配置Variables和Connections- 环境变量,它们负责保存不同的连接字符串、登录名等。使用 Web 部件,您可以在 UI 中配置它们。
最后但并非最不重要的 -Hook- 是外部服务的接口。 Hooks 是流行的库、API、DB 的包装器。例如。 - 如果您需要处理与某个 SQL 服务器的连接,您可以开始考虑 SqlServiceHook(并且它已经存在)。
创建 DAG。主要时刻
首先,你需要一些声明:
import requests
import pandas as pd
from pathlib import Path
from airflow.models import DAG
from airflow.operators.python import PythonOperator
进入全屏模式 退出全屏模式
接下来,让我们为下载数据创建 2 个函数并对其进行旋转(不要忘记检查执行程序,以确保这 2 个任务是否会在一个地方运行)
def download_data_fn():
url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv'
resp = requests.get(url)
Path('titanic.csv').write_text(resp.content.decode())
def pivot_data_fn():
df = pd.read_csv('titanic.csv')
df = df.pivot_table(index='Sex', columns='Pclass', values='Name', aggfunc='count')
df.reset_index().to_csv('titanic_pivoted.csv')
进入全屏模式 退出全屏模式
最后一步是创建具有执行顺序的 DAG:
with DAG(dag_id='titanic_dag', schedule_interval='*/9 * * * *') as dag:
download_data = PythonOperator(
task_id='download_data',
python_callable=download_data_fn,
dag=dag,
)
pivot_data = PythonOperator(
task_id='pivot_data',
python_callable=pivot_data_fn,
dag=dag,
)
download_data >> pivot_data
# variants:
# pivot_data << download_data
# download_data.set_downstream(pivot_data)
# pivot_data.set_upstream(download_data)
进入全屏模式 退出全屏模式
创建的文件必须位于所有 DAG 所在的文件夹中。默认情况下,它是 - $AIRFLOW_HOME/dags。如果是这样 - 调度程序会将其带到执行顺序,并且执行程序将每 9 分钟运行一次。
XComs
有时我们在任务 A 和任务 B 之间存在依赖关系。我们不仅希望一个接一个地运行任务,还希望在控制台中传递一些结果,例如管道。为此,我们可以使用 XComs。
使用 XComs(跨任务通信),一个任务可以将特殊元数据写入元数据数据库,而另一个任务可以读取该数据。我们可以把前面的例子稍微修改一下:
def download_data_fn(**context):
filename = 'titanic.csv'
url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv'
resp = requests.get(url)
Path(filename).write_text(resp.content.decode())
#context['ti'].xcom_push(key='filename', value=filename) # option 1
return filename # option 2
def pivot_data_fn(ti, **context):
# filename = ti.xcom_pull(task_ids=['download_data'], key='filename') # option 1
filename = ti.xcom_pull(task_ids=['download_data'], key='return_value') # option 2
df = pd.read_csv(filename)
df = df.pivot_table(index='Sex', columns='Pclass', values='Name', aggfunc='count')
df.reset_index().to_csv('titanic_pivoted.csv')
with DAG(dag_id='titanic_dag', schedule_interval='*/9 * * * *') as dag:
download_data = PythonOperator(
task_id='download_data',
python_callable=download_data_fn,
provide_context=True,
)
pivot_data = PythonOperator(
task_id='pivot_data',
python_callable=pivot_data_fn,
provide_context=True,
)
download_data >> pivot_data
进入全屏模式 退出全屏模式
正如我们所见,使用 XCom 对象有多种不同的方式,但您应该记住,数据必须很小。如果数据量很大,您将花费时间将数据保存到 DB 并且可能达到元 DB 的限制。其次,Airflow 只是一个编排器,绝不能用于数据处理。
缺点
你需要知道并记住很多事情才能获得好的结果。这是一个复杂的工具,但它做复杂的工作。此外,在大多数调试和跟踪情况下,您将拥有 Airflow 的本地实例,因此您将拥有一些临时和生产环境。
替代品
很高兴知道 Airflow 不是市场上唯一的一种。有Dagster和Spotify Luigi等。但是它们各有优缺点,请确保您对市场进行了良好的调查,以选择最适合您任务的工具。
这就是今天的全部内容;)我希望这篇文章能给他们一些线索和基础知识,让他们开始使用 Airflow 和编排。敬请关注!

Python社区为您提供最前沿的新闻资讯和知识内容
更多推荐

 0
0 0
0- 0



 已为社区贡献126442条内容
已为社区贡献126442条内容

所有评论(0)