
使用 Supabase 加载 Python 数据
在数据科学方面,Python 是一个很好的选择。借助多种库和内置分析工具,您可以轻松处理数据,分析最复杂的数据集,并以精美的图表和图形可视化您的结果。
Supabase 是建立在 PostgreSQL 之上的后端即服务。它是构建现代数据密集型应用程序和工具的绝佳选择。
感谢我们令人难以置信的社区,Supabase 现在拥有功能强大且开源的Python SDK。使用 Supabase 和 Python,您只需几行代码即可自动执行 CRUD 操作等任务。本指南将首先在 Supabase 中创建一个简单的模式,然后我们将使用 Supabase Python SDK 展示如何加载示例数据。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--5tMN4E00--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/7rbpzdndztdn4end2clq.jpeg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--5tMN4E00--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/7rbpzdndztdn4end2clq.jpeg)
先决条件
在我们深入研究之前,让我们看一下您需要的一些先决条件:
-
Python版本> 3.7
-
SDK 仅支持版本 > 3.7。您可以从此处的下载受支持的 Python 版本。
-
Python虚拟环境
-
这是可选的,但它会避免包依赖和版本冲突的问题。您可以在此处找到创建虚拟环境的步骤。我们将使用 PyCharm 来利用它的 venv 创建功能。
-
Faker python包
-
我们将使用 Python 中 Faker 库中的faker-commerce包来生成真实的样本数据。
使用 Python 将数据加载到 Supabase
Supabase 是为开发者打造的,你可以使用现有的 Github 账户免费上手。设置好 Supabase 帐户后,您将访问 Supabase 仪表板。从这里,转到所有项目 > 新项目。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Ck8Zg67O--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/1.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Ck8Zg67O--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/1.png)
为您的项目命名并设置数据库密码。您还可以根据项目要求选择区域并调整定价方案。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--GY761KFv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/2.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--GY761KFv--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/2.png)
您的项目将在 2 分钟内启动。
在Supabase中创建表
在此示例中,我们将在 Supbase 中创建 2 个表:
-
Vendor(字段为 vendor\name、vendor\location 和 total\employees)
-
产品(供应商_id 作为 FK、产品_名称、价格和总订单)
数据库架构将如下所示:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--tRDL97h6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/3.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--tRDL97h6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/3.png)
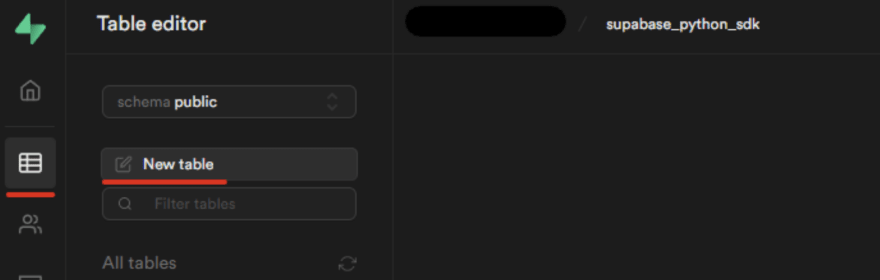
现在让我们开始创建表。创建项目后,您需要转到表编辑器 > 新表
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--byC7Uta---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// supbase.com/images/blog/python-1/4.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--byC7Uta---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// supbase.com/images/blog/python-1/4.png)
现在,您可以根据定义的模式创建表。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--HUDTRNfj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/5.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--HUDTRNfj--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/5.png)
单击保存以创建您的供应商表。同样,创建产品表。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--qeYx_3Wn--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/6.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--qeYx_3Wn--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/6.png)
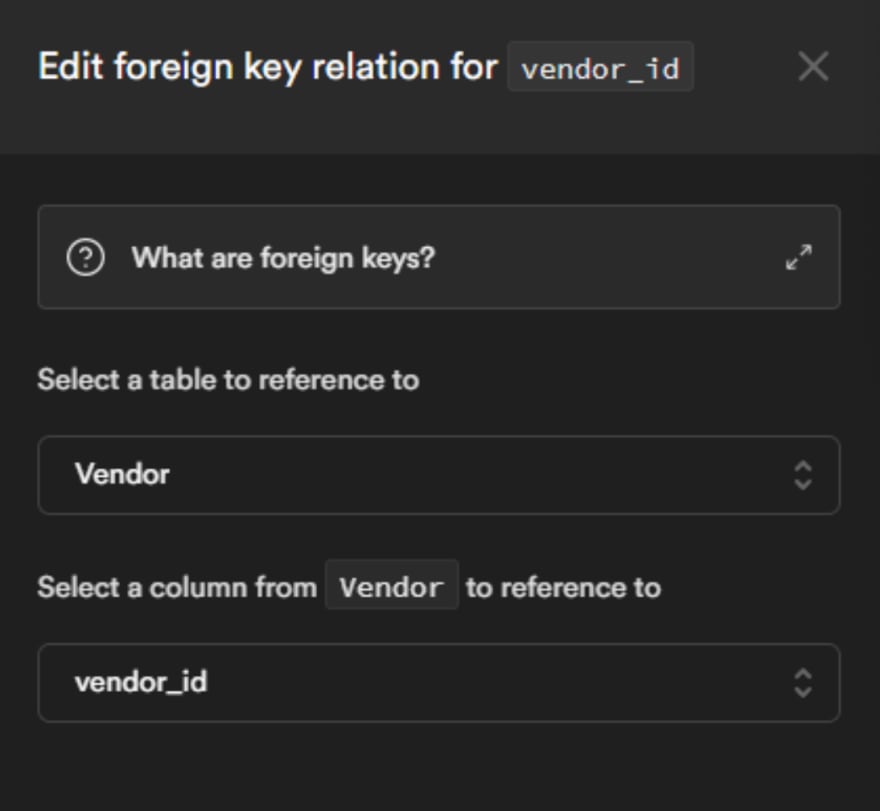
在点击 Save 之前,您需要设置 Product 和 Vendor 表之间的外键关系。为此,请选择“vendor_id”旁边的按钮
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--pw1qSlD8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/7.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--pw1qSlD8--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/7.png)
从“供应商”表中选择供应商_id 主键。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--lycGAKJ5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/8.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--lycGAKJ5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/8.png)
单击保存,您就可以开始了。您现在应该在表编辑器下看到 2 个表。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--kdhoELZ5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/9.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--kdhoELZ5--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/9.png)
安装Python SDK
设置表并安装先决条件后,您现在可以开始使用Python SDK。要安装 SDK,请运行以下命令:
pip3 install supabase
确保您在 python 虚拟环境中运行它。这将需要几分钟才能完成。
使用 Supabase API 密钥
SDK 身份验证使用指向项目 URL 的 API 密钥。要查找您的项目 URL 和 API,请转到设置 > API。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--J31TS4HG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/10.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--J31TS4HG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/10.png)
设置环境变量
API 凭证和项目 URL 可以存储在环境变量中。在 bash/zsh 中设置环境变量非常简单。我们需要做的就是运行:
export <variable_name>=<variable_value>
进入全屏模式 退出全屏模式
因此,对于我们的示例,我们将像这样设置它们:
export SUPABASE_URL=<<the value under config > URL>>
export SUPABASE_KEY=<<the value present in Project API keys > anon public>>
export SUPABASE_SECRET_KEY=<<the value present in Project API keys > service_role secret>>
进入全屏模式 退出全屏模式
插入数据到 Supabase
这是我们将用于将随机数据插入表中的代码片段:
import os
import json
from dotenv import load_dotenv
from supabase import create_client, Client
from faker import Faker
import faker_commerce
def add_entries_to_vendor_table(supabase, vendor_count):
fake = Faker()
foreign_key_list = []
fake.add_provider(faker_commerce.Provider)
main_list = []
for i in range(vendor_count):
value = {'vendor_name': fake.company(), 'total_employees': fake.random_int(40, 169),
'vendor_location': fake.country()}
main_list.append(value)
data = supabase.table('Vendor').insert(main_list).execute()
data_json = json.loads(data.json())
data_entries = data_json['data']
for i in range(len(data_entries)):
foreign_key_list.append(int(data_entries[i]['vendor_id']))
return foreign_key_list
def add_entries_to_product_table(supabase, vendor_id):
fake = Faker()
fake.add_provider(faker_commerce.Provider)
main_list = []
iterator = fake.random_int(1, 15)
for i in range(iterator):
value = {'vendor_id': vendor_id, 'product_name': fake.ecommerce_name(),
'inventory_count': fake.random_int(1, 100), 'price': fake.random_int(45, 100)}
main_list.append(value)
data = supabase.table('Product').insert(main_list).execute()
def main():
vendor_count = 10
load_dotenv()
url: str = os.environ.get("SUPABASE_URL")
key: str = os.environ.get("SUPABASE_KEY")
supabase: Client = create_client(url, key)
fk_list = add_entries_to_vendor_table(supabase, vendor_count)
for i in range(len(fk_list)):
add_entries_to_product_table(supabase, fk_list[i])
main()
进入全屏模式 退出全屏模式
总结一下我们使用此代码片段所做的工作:
-
我们在表中随机插入了 10 个供应商。
-
对于 10 个供应商中的每一个,我们都插入了许多不同的产品
读取存储在 Supabase 中的数据
也可以直接从 Supabase 仪表板查看数据。为此,请转到Table Editor > All tables
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--uMX6DuvH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/11.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--uMX6DuvH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/11.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--fdLUz_3_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/12.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--fdLUz_3_--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://supabase .com/images/blog/python-1/12.png)
注意:如果您看不到任何数据,您应该点击刷新按钮。
结论
使用 Python,将数据加载到 Supabase 很容易。只需几个简单的步骤即可开始使用 Python SDK 和 Supabase。在本博客系列的下一部分中,我们将学习如何使用 Metabase 可视化我们刚刚加载到 Supabase 中的数据。敬请关注!
如果您有任何问题,请通过Twitter或加入我们的Discord联系。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐
 0
0 0
0- 0



 已为社区贡献27131条内容
已为社区贡献27131条内容

所有评论(0)