Nodejs/serialize/MySQL——基础、连接表和优化
在本文中,您将看到:
-
MySQL、SQL、ORM和序列化之间的概念关系
-
使用sequenize
-
sequelize中连接表关系的概念、用法、原理及区别
-
如何优化数据库查询
1 概念
MySQL
大多数人都知道 MySQL 和 SQL。毕竟是教科书上写的。 MySQL 是典型的关系型数据库。怎么称呼它为关系型?
简而言之,关系数据库是由多个可以相互连接的二维行和列表组成的数据库。
这里有两点:::二维行列表::(体现在单个表的数据结构中)和::互连::(体现在表关系和库引擎的特性上)。
与MongoDB等NoSQL相比,二维行列表的优势在于:
-
严谨的数据结构带来的可靠性:每列的数据类型甚至大小都是由模型定义的,一切都是稳定的
-
“平面层”带来的理解便利:每一条数据都是“平面层”。毕竟自由嵌套实在是太南了,看不懂
SQL
既然关系数据库是一个统一的标准,那么只要各个公司按照标准来实现,剩下的就可以统一了,比如对数据库的访问。
这就是 SQL 所做的。它只是一个字符串,可以理解为对关系数据库进行任何操作的命令。但是,考虑到关系设计已经简化了复杂的事情,SQL 只做这些事情:
-
定义库、表本身、表之间的关系
-
一个表的增删改查
-
借助表间关系,一次可以联合访问多个表中的数据
-
访问一些基本的算术函数
简而言之,如果你把这些放在一起,理论上,你可以用“只有一个 SQL”做任何你想做的事情。了解更多:根据我的知识水平,只能看菜鸟教程
ORM 和 Sequelize
但是 SQL 还远远不够,因为字符串本身没有约束。你可能想查一个数据,但你一抖手误删了库,就只能跑了。另外,用代码写一堆字符串真的很丑。
所以有一种东西叫做orm。什么是ORM?它的字面意思是:“对象关系映射”::有点风。
其实就是把数据库表映射成语言对象;然后,暴露一堆方法来检查数据库,ORM负责将方法调用转换成SQL;因为表中的记录是key-value的形式,所以查询的返回结果通常是一个对象,方便数据的使用。这样就提高了数据库访问的便利性和稳定性。
方法 SQL
业务逻辑 <------> ORM <-----> 数据库
数据对象数据
然而,ORM 只是一种解决方案。在右侧,它不受数据库类型的限制。支持任何遵循 SQL 的关系型数据库;在左边,它不受语言类型的限制。每个家族都有比较成熟的实现方案,甚至根据语言特点增加了一些语言级别的优化支持。
在 nodejs 中,“Sequlizejs”可能是最出色的 ORM 实现了。 Sequlizejs 植根于 nodejs,完美支持 Promise 调用。此外,您可以使用 async/await 与业务代码紧密结合;如果使用 ts,模型定义中的类型提醒可以使调用更容易。
官方文档在这里:<Sequelize V5>
2 基本用法
表/模型定义
前面说过,ORM的第一步是建立对象和数据表的映射关系。例如在 Sequlize 中,我们关联一个站点的表
常量模型 u003d sequelize.define('站', {
身份证:{
字段:'id',
类型:Sequelize.INTEGER,
允许空:假,
主键:真,
自动增量:真,
},
存储_id: Sequelize.STRING(20),
名称:Sequelize.STRING(20),
类型:Sequelize.TINYINT,
状态:Sequelize.TINYINT,
ip: Sequelize.STRING(20),
盘子_no: Sequelize.STRING(20),
相关\工作\订单\id:Sequelize.BIGINT,
});
可以看出,在定义过程中,数据类型是从sequenize静态属性中引用的。这些类型可以覆盖数据库中的类型,但名称不对应。详情:lib/data-types.js
你也可以自定义define的第三个参数。这些配置会被合并到Sequlize构造函数的define字段中,用于定义模型与数据表的关联行为,例如“自动更新_at并在表中创建_at”。参考型号|续集选项在
但是,模型属于模型,用于ORM。数据库中的表应该是自己建的。通过客户端或以下方式创建 SQL 表:
创建表 `station`(
`id`bigint(11) 无符号 NOT NULL AUTO_INCREMENT,
`store_id`varchar(20) NOT NULL DEFAULT '',
`name`varchar(20) NOT NULL DEFAULT '',
`type`tinyint(4) NOT NULL DEFAULT '0',
`status`tinyint(4) NOT NULL DEFAULT '0',
`ip`varchar(20) NOT NULL DEFAULT '',
`related_work_order_id`bigint(20) NOT NULL DEFAULT '0',
`created_at`datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at`datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`plate_no`varchar(20) NOT NULL DEFAULT '',
主键 (`id`)
) ENGINEu003dInnoDB AUTO_INCREMENTu003d7 DEFAULT CHARSETu003dutf8 COMMENTu003d'Station table';
基本 CURD
Sequelize 对象提供了丰富的 API,例如:
-
findOne,findAll......
-
创建,更新插入......
-
聚合,最大......
应该不需要重复API的调用,文件/lib/model.js~Model一切都安排在家里了。这里我们主要看一下调用基本api时Sequlize变成了什么,这对于理解ORM和SQL的对应关系很有帮助。
一个例子:findAll
没有给定属性时,serialize会默认取出模型中的定义作为属性,与Select *相比节省了数据库操作成本和传输带宽。
最简单的,当我执行
Station.findAll()
Sequelize 的 SQL 转换是这样的
选择
`id`,
`store_id`,
`name`,
`type`,
`status`,
`ip`,
`plate_no`
从
`station`作为 `station`;
我们可以简单地添加一些条件:
Station.findAll({
属性:['ip'],
其中:{
状态:1,
},
顺序:[
[ '名称', 'ASC' ],
],
限制:10,
偏移量:5,
});
SQL(还是很清楚的)
从 `station`中选择 `ip`作为 `station`其中 `station`.`status`u003d 1 由 `station`.`name`排序限制 5、10;
第二个例子:findOrCreate
一些高级 API 触发数据库事务:
事情通常没有那么简单,比如我调整的时候
Station.findOrCreate({
其中:{
编号:1,
},
默认值:{
名称:'哈哈',
},
});
要知道,不能用SQL语句实现,所以sequelize启动事务,做“查询->判断->添加”
开始交易;
选择 `id`, `store_id`, `name`, `type`, `status`, `ip`, `plate_no`FROM `station`AS `station`WHERE `station`.`id`u003d
插入 `station`(`id`,`name`) 值 (2,`haha`);
提交;
3.联表查询
3.1 为什么需要连接表
之前我们有一个Station表,现在我们多了一个Car表,通过station_id记录了Car所在的Station。我想检查车站列表和它们包含的汽车。
先找到Station,然后where-station_id-in检查Car,最后编写逻辑遍历Station。一个一个地插入Car是可行的。但一方面,多查询一次会增加数据库资源的消耗,另一方面,它也有更多的处理逻辑。
因此,我们需要利用“关系型数据库”擅长的“表间关系”一次性完成上述查询和数据整合。
3.2 联合声明关系
在 Sequelize 中,关联表关系需要在模型关联方法中进行标注,通常采用这种格式:
File.belongsTo(用户, {...option});
检查时使用包含
文件.findOne({
包括:[{ 型号:用户}],
});
和模型定义本身一样,这个标签并不对数据库进行操作,而是在 ORM 层建立模型之间的关系。当我们调用 JOIN 表查询时,这种关系会被转换成“JOIN”等 JOIN SQL 语句。
查询操作始终是“包含”,但是否标记以及使用哪种标记方法决定了关联表查询是否可以在后续查询中使用,以及查询的SQL和查询结果的组织。
首先,澄清一个标记行为中的几个概念
-
两种型号
-
上述查询模型与其他表模型的关系就是上述查询模型与源模型的关系
-
目标模型:具有标记关系的模型。由于这个标记,它没有获得关联表查询的能力(上面的用户)
-
四个关联键
-
foreignKey:外键,用于关联外部模型。:: 带有外键的模型对于关联模型来说是唯一的:
-
目标键
-
源密钥
-
otherKey:一个foreignKey不够用时的替代品
表之间的关系通常包括:一对一、一对多、多对多。
3.3 一对一关系(belongsTo / hasOne)
[serialize] 一对一关系文档
[误解] 我之前在这里有一个误会。我以为“一对一”就像夫妻一样“双向独特”,但事实并非如此。我们的关系声明只能从源模型向一个方向发起,即“一对一”的关系也是单向的。只能保证“源模型记录对应一个目标模型记录”,反之亦然。
和“儿子。哈松”一样,不能保证“父亲”只有一个儿子。
一对一关系可以用belongsTo和hasOne来标记。
1 属于
File_ ID 中有一个创建者标记您:: 所属的用户(目标模型)。在这里,用户可能不会只有一个文件,而是一个文件只能与一个用户关联。
File.BelongsTo(用户,{
foreignKey: 'creator_id', // 如果这个没有定义,也会自动定义为“目标模型名+目标模型主键名”,即user_id
targetKey: 'id', // 目标模型的关联键,默认主键,通常省略
});
// 这里是 creator_ ID 位于源模型文件上
2 笑声
条件或文件模型中是否有创建者_ ID 标记您所属的用户。在这种情况下,如果把User作为源模型,在User侧,假设一个User只有一个File,我们需要从User那里获取File:
用户.HasOne(文件,{
foreignKey: 'creator_id', // 如果这个没有定义,也会自动定义为“源模型名+源模型主键名”,即user_id
sourceKey: 'id', // 源模型的关联键,默认主键,通常省略
}
// 这里是 creator_ ID 在目标模型文件上
HasOne 将 foreignKey 反转为源模型,因此在 targetKey 和 sourceKey 使用默认值(通常相同)的前提下,使用 BelongsTo 或 HasOne 作为 foreignKey 的位置很方便。
3 BelongsTo 和 HasOne
BelongsTo 和 HasOne 可以定义“一对一”的关系。在三个key的帮助下,理论上可以互相替换。

其实转换后的SQL是一样的::LEFT JOIN::
# File.BelongsTo(用户)
选择 `FileClass`.`id`, `user`.`id`AS `user.id`
来自 `file``FileClass`
左连接 `user`ON `FileClass`.`creator_id `u003d `user`.`id`
User.HasOne(文件)
选择 `UserClass`.`id`, `file`.`id`AS `file.id`
来自 `user``UserClass`
左连接 `file`ON `UserClass`.`id `u003d `file`.`creator_id `
但在“概念”层面,“归属感”和“拥有一个”是两个不同的东西。哪个模型相对于另一个模型真正“独特”,那么这个模型应该有一个foreignKey。
3.4 一对多(hasMany)
:: hasMany可以理解为“hasOne的多选版”::和hasOne一样,这里需要:“目标模型”只属于“源模型”:
在上面的场景中,File 模型中有一个#creator_ID 标记了你创建的User。在这里,我们得到了用户创建的所有文件。
User.HasMany(文件,{
foreignKey: 'creator_id', // 如果这个没有定义,也会自动定义为“源模型名+源模型主键名”,即user_id
sourceKey: 'id', // 源模型的关联键,默认主键,通常省略
}
// 这里是 creator_ ID 在目标模型文件上
hasOne 和 hasOne 之间的深刻差异
其实:在findAll下,SQL和“一对一”是一样的:(也就是ORM不能限制左连接的个数,所谓的一对一就是“对所有的连接都选一个” )。
# User.HasMany(文件)
选择 `UserClass`.`id`, `file`.`id`作为 `file.id`
来自 `user``UserClass`
左连接 `file`ON `UserClass`.`id `u003d `file`.`creator_id `
:: findOne不一样:::如果使用hasOne,SQL只需要给一个全局LIMIT 1,意思是“我在JOIN中只想要一个源模型和一个目标模型”
# findOne: User.HasOne(文件)
选择 `UserClass`.`id`, `file`.`id`AS `file.id`
来自 `user``UserClass`
左连接 `file`ON `UserClass`.`id `u003d `file`.`creator_id `
限制 1;
但是,如果您标记 hasMany 并使用 findOne 检查,您说的是“一个源模型,但与之关联的 N 个目标模型”。这时候如果全局给LIMIT 1,就会误杀目标模型的查询结果。因此,首先“LIMIT”查询自身得到“一个源模型”,然后“LEFT JOIN”得到“其关联的N个目标模型”
# findOne: User.HasMany(文件)
选择 `UserClass`.`id`, `file`.`id`AS `file.id`
从 (
选择 `UserClass`.`id`,
来自 `user``UserClass`
限制 1
) `UserClass`
左连接 `file`ON `UserClass`.`id `u003d `file`.`creator_id `
3.5 多对多关系
有时,目标模型和源模型并不是彼此唯一的。一个Group(文件夹)可能有多个用户,一个User也可能有多个组,这直接导致:“给任何模型添加foreignKey都是不合理的”:
我们需要“中间模型”作为媒人来维护“目标模型”和“源模型”之间的关系。中间模型有两个外键(一个被另一个键替换),它们对于目标模型和源模型都是唯一的。
User.BelongsToMany(组,{
通过:GroupUser,//
foreignKey: 'group_id', // 如果这个没有定义,也会自动定义为“目标模型名+目标模型主键名”,即user_id
otherKey: 'user_id',
}
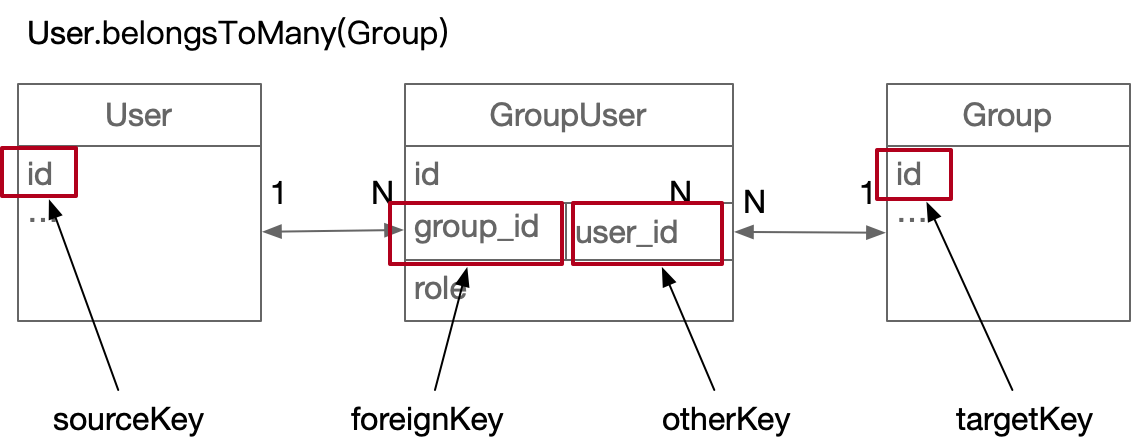
findOne时,SQL如下:先加入GroupUser#inner#Group,然后LEFT JOIN结果给User
# findOne(User): User.BelongsToMany(Group)
选择 `UserClass`.`id`, `group`.`id`AS `group.id`
从 (
选择 `UserClass`.`id`,
来自 `user``UserClass`
限制 1
) `UserClass`
左连接 (`group_user``group->GroupUser`
内连接 `group`ON `group`.`id`u003d `group->GroupUser`.`group_id`)
开 `UserModel`.`id`u003d `group->GroupUser`.`user_id`;
3.6 几个连接
-
left outer join(相当于left join,因为默认是outer):以左边表的行为为标准,合并并返回左边的行;当右侧没有关联记录时,返回该行,右侧添加的字段为空
-
右连接:与左相反,以右表为准
-
内连接:只有当左右值匹配时才能返回,相当于取交集
-
full join:当两边任意一个匹配时返回,相当于union set
在include中,如果需要:true配置,SQL会从LEFT JOIN变为INNER JOIN,剔除没有关联记录的行
4 优化数据库查询
上面提到的东西只是“可用的”。事实上,业务查询场景很可能是复杂的。随便写,DBA会叫门的。
4.1 慢查询、全表扫描和索引
在数据库领域,人们经常提到“慢查询”,它是指查询时间超过规定时间的查询。慢查询的危害在于,不仅本次查询的请求时间变长,而且会长期占用系统资源,影响其他查询或者干脆挂掉数据库。
“慢查询”最常见的罪魁祸首是“全表扫描”,这意味着数据库引擎为了找到一条记录,一个一个地搜索整个表,直到找到该记录。想象一下,如果你有几亿条数据,而你要检查的数据恰好是相对落后的。你什么时候能找到这个? (复杂度是 O(n))那么如何不“全表扫描”呢?
例如,当您使用主键检查一条记录时,您不会扫描整个表。
File.findByPk(123);
因为 MySQL 默认会在主键列中添加“索引”。
:: 索引在哪里? MySQL建立btree::(不同数据库的实现方式不同,但btree是主流)。这样,“Station with id 318”只需要沿着根节点找到,意思是这样的:
3xx --> 31x --> 318
4.2 索引其他列
那么如果我检查正常列怎么办?您还可以通过索引提高查询效率。
文件.findOne({
其中:{
名称:“站 1”
}
})
您还可以手动向该列添加索引:
在文件(名称)上创建索引 index_name;
但是,这个索引的实现与主键索引不同。它不是直接查找数据记录,而是在主键 id 上建立 btree。现在检查“名称为 station1 的记录”的过程与此类似:
开始
--> 名称:站... --> 名称:站 --> 名称:站 1
--> 获取 id:816 的 station1
--> id: 8xx --> id: 81x --> id: 816
--> 获取816的数据
如果这条路径太长,还有更进一步的步骤。对于经常查询的列,例如文件名和作者,可以创建一个“覆盖索引”:
在文件(名称,作者)上创建索引 index\name\and\address;
这时候如果我只根据名字查作者:
文件.findOne({
其中:{
名称:“站 1”
},
属性:['作者']
})
因为地址已经保存在索引中,所以不需要访问源数据:
开始
--> 名称:站... --> 名称:站 --> 名称:站 1
--> 获取地址为 xxx 的 station1
索引越多越好?
但是,指数并不是越多越好。索引虽然提高了查询的效率,但牺牲了插入和删除的效率。想象一下,以前你只需要在表上堆新数据,但现在你必须修改索引。比较麻烦的是索引是平衡树,很多场景下都需要调整整棵树。 (为什么默认主键自增?我猜也是为了降低插入数据时树操作的成本)
因此,我们一般会考虑为“where”或“order”常用的列添加索引。
4.3 查询语句优化
如前所述,为普通列添加索引可以提高查询效率,并使查询通过“btree”而不是“全表扫描”。但前提不是“选择*”而是使用属性只提取你想要的列:
其中:{
属性:['id', 'name']
}
但是,并非所有查询都遵循“btree”。不好的sql还是会触发全表扫描,产生慢查询,应该尽量避免。
当您对列进行定位时,MySQL 仅对以下运算符使用索引:<、<u003d、u003d、>、>u003d、BETWEEN、IN,有时还有 LIKE。
把它放在序列中:
Sequelize.Op.gt|gte|lt|lte|eq|between|in ...
比如可以用in,尽量不要用not in
// 不好
状态:{
[Op.notIn]: [ 3, 4, 5, 6 ],
},
// 好
状态:{
[Op.in]: [ 1, 2 ],
},
具体网上搜索“避免全表扫描”就不进行了。
5 总结
-
MySQL通过SQL进行操作,ORM基于业务编程语言进一步抽象操作,最终转化为SQL。 Sequenize 是节点上的 ORM
-
本文介绍sequenize的模型建立和查询语法
-
联表有3种关系。通过四种标记联想,讨论了这些联想的概念、用法、原理和区别。
-
索引对数据库优化具有重要意义。同时,我们应该避免在句子中不使用索引
https://zhuanlan.zhihu.com/p/150560731

MongoDB社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献32862条内容
已为社区贡献32862条内容

所有评论(0)