
第九章 tcp拥塞控制--基于Linux3.10
Linux提供丰富的拥塞控制算法,这些算法包括Vegas、Reno、HSCTP(High Speed TCP)、Westwood、BIC-TCP、CUBIC、STCP(Scalable TCP)、Hybla以及Veno等,对于Linux3.10而言,这些算法在添加到内核时会被注册到同一个链表。9.1 CUBIC拥塞控制tcp_sock函数使用到的控制拥塞变量如下:snd_cwnd:
下载地址《http://download.csdn.net/detail/shichaog/8620701》
Linux提供丰富的拥塞控制算法,这些算法包括Vegas、Reno、HSCTP(High Speed TCP)、Westwood、BIC-TCP、CUBIC、STCP(Scalable TCP)、Hybla以及Veno等,对于Linux3.10而言,这些算法在添加到内核时会被注册到同一个链表。
9.1 CUBIC拥塞控制
tcp_sock函数使用到的控制拥塞变量如下:
snd_cwnd:拥塞控制窗口的大小
snd_ssthresh:慢启动门限,如果snd_cwnd值小于此值这处于慢启动阶段。
snd_cwnd_cnt:当超过慢启动门限时,该值用于降低窗口增加的速率。
snd_cwnd_clamp:snd_cwnd能够增加到的最大尺寸。
snd_cwnd_stamp:拥塞控制窗口有效的最后一次时间戳
snd_cwnd_used:用于标记在使用的拥塞窗口的高水位值,当tcp连接的数量被应用程序限制而不是被网络所限制时,该变量用于下调snd_cwnd值。
Linux也支持用户空间动态插入拥塞控制算法,通过tcp_cong.c注册,拥塞控制使用的函数通过向tcp_register_congestion_control传递tcp_congestion_ops实现,用户插入的拥塞控制算法需要支持ssthresh和con_avoid。
tp->ca_priv用于存放拥塞控制私有数据。tcp_ca(tp)返回值是指向该地址空间的。
当前有三种拥塞控制算法:
最简单的源于TCP reno(高速、高伸缩性)。
其次是更复杂点的BIC算法、Vegas和Westwood+算法,这类算法对拥塞的控制会依赖于其它事件。
优秀的TCP拥塞控制算法是复杂的,这需要再公平和性能之间权衡。
当前Linux系统使用的拥塞控制算法取决于sysctl接口的net.ipv4.tcp_congestion_control。缺省的拥塞控制算法是最后注册的算法(LIFO),如果全部编译成模块,则将使用reno算法,如果使用缺省的Kconfig配置,CUBIC算法将会编译进内核(不是编译成module),并且内核将使用CUBIC算法作为默认的拥塞控制算法。
cubic使用的算法
窗长增长函数:
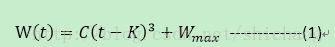
C是cubic参数,t是自上一次窗口减少的时间,K是上述函数在没有丢包时从W增加到 所花费的时间周期。其计算公式是
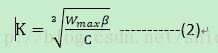
在拥塞避免阶段收到ACK时。CUBIC在下一个RTT使用公式1计算窗口增长率。其将 设置成拥塞窗口大小。
根据当前拥塞窗口大小,CUBIC有三种状态,TCP状态(t时刻窗长小于标准TCP窗长)、凹区域(拥塞窗口小于 )、凸区域(拥塞窗口大于 )。
cubic慢启动门限阈值
该方法在快速和长距离网络上使用立方函数修改拥塞线性窗口。该方法使窗口的增加独立于RTT(round trip times),这使得具有不同RTT的流具有相对均等的网络带宽。到达稳定阶段,CUBIC在稳定阶段将急速向饱和点增加,但是快到饱和点时增加速度会变慢。该特性使得CUBIC在带宽延迟积(BDP bandwith and delay product)较大时具有很好的可扩展性、稳定性和公平性。立方根计算方法Newton-Raphson,误差约为0.195%。
首先找慢启动门限初始值snd_ssthresh,在TCP套接字初始化时tcp_prot的init成员会被调用,该函数直接指向tcp_v4_init_sock()。下列代码片段的2163行对套接字进行初始化。
net/ipv4/tcp_ipv4.c
2159 static int tcp_v4_init_sock(struct sock *sk)
2160 {
//icsk—意为inet connection sock
2161 struct inet_connection_sock *icsk = inet_csk(sk);
//套接字初始化
2163 tcp_init_sock(sk);
//ipv4连接的套接字操作函数集
2165 icsk->icsk_af_ops = &ipv4_specific;
2166
2171 return 0;
2172 }
2852 struct proto tcp_prot = {
2853 .name = "TCP",
2854 .owner = THIS_MODULE,
2855 .close = tcp_close,
2856 .connect = tcp_v4_connect,
2857 .disconnect = tcp_disconnect,
2858 .accept = inet_csk_accept,
2859 .ioctl = tcp_ioctl,
2860 .init = tcp_v4_init_sock,
2897 }
tcp_init_sock()用于初始化套接字,由于sk_alloc()函数在为套接字分配内存时,已经将一些变量的初始值设置为了0,所以tcp_init_sock()并没有初始化所有变量。
<net/ipv4/tcp.c>
372 void tcp_init_sock(struct sock *sk)
373 {
374 struct inet_connection_sock *icsk = inet_csk(sk);
//如9.1节所述,tcp_sock的结构体中包含了拥塞控制所需的各种变量
375 struct tcp_sock *tp = tcp_sk(sk);
//存放乱序tcp包的套接字链表初始化
377 skb_queue_head_init(&tp->out_of_order_queue);
//重传、延迟ack以及探测定时器初始化。
378 tcp_init_xmit_timers(sk);
//记录套接字直接拷贝到用户空间信息的结构体ucopy初始化
379 tcp_prequeue_init(tp);
380 INIT_LIST_HEAD(&tp->tsq_node);
//重传超时值,起始值设置为1s。
382 icsk->icsk_rto = TCP_TIMEOUT_INIT;
//mdev -- medium deviation,用于RTT测量的均方差
383 tp->mdev = TCP_TIMEOUT_INIT;
//初始拥塞窗口大小,初始值10,这就意味着窗长在大于10时才会进入拥塞算法,而一开始进入的是慢启动阶段。
390 tp->snd_cwnd = TCP_INIT_CWND;
//慢启动门限0x7FFFFFFF
395 tp->snd_ssthresh = TCP_INFINITE_SSTHRESH;
//拥塞窗口最大窗长
396 tp->snd_cwnd_clamp = ~0;
//mss maximum segment size,初始值设置为536,不包括SACKS(selective ACK)
397 tp->mss_cache = TCP_MSS_DEFAULT;
398
399 tp->reordering = sysctl_tcp_reordering;
400 tcp_enable_early_retrans(tp);
401 icsk->icsk_ca_ops = &tcp_init_congestion_ops;
//时间戳偏移
403 tp->tsoffset = 0;
//套接字当前状态sysctl_tcp_rmem[1]对应的是default,[0]是min,[2]最大值
405 sk->sk_state = TCP_CLOSE;
//发送和接收buffer,
416 sk->sk_sndbuf = sysctl_tcp_wmem[1];
417 sk->sk_rcvbuf = sysctl_tcp_rmem[1];
423 }
CUBIC算法慢启动门限ssthresh在两种情况下会得到更新,一种是在接收到ack应答包,另一种是在发生拥塞时,慢启动门限回退。对应使用到的处理函数分别是bictcp_acked()和bictcp_recalc_ssthresh()。
434 static struct tcp_congestion_ops cubictcp __read_mostly = {
//CUBIC算法变量初始化,在tcp三次连接时,回调用其初始化套接字的拥塞控制变量。
435 .init = bictcp_init,
//拥塞时慢启动门限回退计算
436 .ssthresh = bictcp_recalc_ssthresh,
437 .cong_avoid = bictcp_cong_avoid, //拥塞控制
438 .set_state = bictcp_state, //如果拥塞状态是TCP_CA_Loss,Reset拥塞算法CUBIC的各种变量
//拥塞窗口回退。
439 .undo_cwnd = bictcp_undo_cwnd,
//当tcp_ack调用tcp_clean_rtx_queue将收到应答的数据包从重传队列删除时,会调用bictcp_acked更新慢启动阈值
440 .pkts_acked = bictcp_acked,
441 .owner = THIS_MODULE,
442 .name = "cubic",
443 };
在tcp_ack()函数收到ack包时,会调用tcp_clean_rtx_queue()将已经收到应答包的帧从重传队列删除,在这个函数的末尾会调用bictcp_acked()更新慢启动门限值。
396 static void bictcp_acked(struct sock *sk, u32 cnt, s32 rtt_us)
397 {
398 const struct inet_connection_sock *icsk = inet_csk(sk);
399 const struct tcp_sock *tp = tcp_sk(sk);
400 struct bictcp *ca = inet_csk_ca(sk);
401 u32 delay;
//1)混合慢启动(train和delaed)标志hystart默认是开启的,2)当前窗长snd_cwnd应该满足小于tcp_init_sock()函数设置//值,3)hystart_low_window是内核设置的最小拥塞窗口值16。
429 if (hystart && tp->snd_cwnd <= tp->snd_ssthresh &&
430 tp->snd_cwnd >= hystart_low_window)
431 hystart_update(sk, delay);
432 }
358 static void hystart_update(struct sock *sk, u32 delay)
359 {
360 struct tcp_sock *tp = tcp_sk(sk);
361 struct bictcp *ca = inet_csk_ca(sk);
362
363 if (!(ca->found & hystart_detect)) {
364 u32 now = bictcp_clock();
//不论是train方法还是delayed方法满足离开慢启动条件,这里将当前的snd_cwnd设置成新的慢启动门限,即由0x7FFFFFFF
//设置成16。
388 if (ca->found & hystart_detect)
389 tp->snd_ssthresh = tp->snd_cwnd;
390 }
391 }
9.2 cubic拥塞代码实现
慢启动slow start
tcp_ack()在正确接收到应答包后,有如下代码:
icsk->icsk_ca_ops->cong_avoid(sk, ack, in_flight);该代码调用tcp_cubic.c文件的437行函数。
net/ipv4/tcp_cubic.c
305 static void bictcp_cong_avoid(struct sock *sk, u32 ack, u32 in_flight)
306 {
307 struct tcp_sock *tp = tcp_sk(sk);
308 struct bictcp *ca = inet_csk_ca(sk);
//检查发送出去还没收到ACK包的数量是否已达到拥塞控制窗口上限,达到则返回。
310 if (!tcp_is_cwnd_limited(sk, in_flight))
311 return;
//当前窗长小于慢启动门限,则进入慢启动控制,否则进入拥塞避免
313 if (tp->snd_cwnd <= tp->snd_ssthresh) {
//判断是否需要重置sk的CUBIC算法使用到的变量。
314 if (hystart && after(ack, ca->end_seq))
315 bictcp_hystart_reset(sk);
//慢启动处理函数
316 tcp_slow_start(tp);
317 } else {
//更新ca(congestion avoid)的cnt成员,拥塞避免函数会使用该成员
318 bictcp_update(ca, tp->snd_cwnd);
//拥塞避免处理算法
319 tcp_cong_avoid_ai(tp, ca->cnt);
320 }
321
322 }
RFC2861,检查是否被应用程序或者拥塞窗口限制,其参数in_flight是已经发送但是还没有经过确认的数据包,如果被限制则返回1,说明需要进行拥塞控制,否则不需要拥塞控制。
net/ipv4/tcp_cong.c
284 bool tcp_is_cwnd_limited(const struct sock *sk, u32 in_flight)
285 {
286 const struct tcp_sock *tp = tcp_sk(sk);
287 u32 left;
//未确认包数量大于等于当前的窗长,返回true
289 if (in_flight >= tp->snd_cwnd)
290 return true;
//还可以发送的窗口剩余量
292 left = tp->snd_cwnd - in_flight;
//判断SK的sk_route_caps成员是否支持gso,这是软件实现的功能。
293 if (sk_can_gso(sk) &&
// tcp_tso_win_divisor是sysctl接口,即一个TSO帧可以占用拥塞窗口长度的百分比。
294 left * sysctl_tcp_tso_win_divisor < tp->snd_cwnd &&
//最大GSO段的大小
295 left * tp->mss_cache < sk->sk_gso_max_size &&
//最多GSO段的个数
296 left < sk->sk_gso_max_segs)
297 return true;
//没有使用tcp_tso_win_divisor时,最多TSO可以延迟发送的MSS的最多个数
298 return left <= tcp_max_tso_deferred_mss(tp);
299 }
不论是reno还是cubic等拥塞控制算法,它们使用慢启动处理函数是一样的。当前3.10版本的内核支持RFC2581基本规范。
net/ipv4/tcp_cong.c
309 void tcp_slow_start(struct tcp_sock *tp)
310 {
311 int cnt; /* increase in packets */
312 unsigned int delta = 0;
313 u32 snd_cwnd = tp->snd_cwnd;
//如果管理员使用sysctl接口,配置了慢启动增加值,就按照管理员的设置来,否则会以指数方式增加窗长
320 if (sysctl_tcp_max_ssthresh > 0 && tp->snd_cwnd > sysctl_tcp_max_ssthresh)
321 cnt = sysctl_tcp_max_ssthresh >> 1; /* limited slow start */将慢启动门限除以二。
322 else
323 cnt = snd_cwnd; /* exponential increase */
// snd_cwnd_cnt在拥塞发生时会被重置0,否则其值是一直增长的,如果起始snd_cwnd 等于10
325 tp->snd_cwnd_cnt += cnt;
326 while (tp->snd_cwnd_cnt >= snd_cwnd) {//窗长+1
327 tp->snd_cwnd_cnt -= snd_cwnd;
328 delta++;
329 }
330 tp->snd_cwnd = min(snd_cwnd + delta, tp->snd_cwnd_clamp); //发送窗长不能超限
331 }
拥塞避免congestion avoid
拥塞避免:从慢启动可以看到,cwnd可以很快的增长上来,从而最大程度利用网络带宽资源,但是cwnd不能一直这样无限增长下去,一定需要某个限制。TCP使用了一个叫慢启动门限(ssthresh)的变量,当cwnd超过该值后,慢启动过程结束,进入拥塞避免阶段。对于大多数TCP实现来说,ssthresh的值是65536(同样以字节计算)。拥塞避免的主要思想是加法增大,也就是cwnd的值不再指数级往上升,开始加法增加。此时当窗口中所有的报文段都被确认时,cwnd的大小加1,cwnd的值就随着RTT开始线性增加,这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。
Cubic窗长更新函数如下,更新的公式参考公式1、2:
207 static inline void bictcp_update(struct bictcp *ca, u32 cwnd)
208 {
209 u64 offs;
210 u32 delta, t, bic_target, max_cnt;
211
212 ca->ack_cnt++; /* count the number of ACKs */
213
214 if (ca->last_cwnd == cwnd &&
215 (s32)(tcp_time_stamp - ca->last_time) <= HZ / 32)
216 return;
217
218 ca->last_cwnd = cwnd;
219 ca->last_time = tcp_time_stamp;
220
221 if (ca->epoch_start == 0) {
222 ca->epoch_start = tcp_time_stamp; /* record the beginning of an epoch */
223 ca->ack_cnt = 1; /* start counting */
224 ca->tcp_cwnd = cwnd; /* syn with cubic */
225
226 if (ca->last_max_cwnd <= cwnd) {
227 ca->bic_K = 0;
228 ca->bic_origin_point = cwnd;
229 } else {
230 /* Compute new K based on
231 * (wmax-cwnd) * (srtt>>3 / HZ) / c * 2^(3*bictcp_HZ)
232 */
233 ca->bic_K = cubic_root(cube_factor
234 * (ca->last_max_cwnd - cwnd));
235 ca->bic_origin_point = ca->last_max_cwnd;
236 }
237 }
//254~303参考公式1和公式2.
254 t = ((tcp_time_stamp + msecs_to_jiffies(ca->delay_min>>3)
255 - ca->epoch_start) << BICTCP_HZ) / HZ;
256
257 if (t < ca->bic_K) /* t - K */
258 offs = ca->bic_K - t;
259 else
260 offs = t - ca->bic_K;
261
262 /* c/rtt * (t-K)^3 */
263 delta = (cube_rtt_scale * offs * offs * offs) >> (10+3*BICTCP_HZ);
264 if (t < ca->bic_K) /* below origin*/
265 bic_target = ca->bic_origin_point - delta;
266 else /* above origin*/
267 bic_target = ca->bic_origin_point + delta;
268
269 /* cubic function - calc bictcp_cnt*/
270 if (bic_target > cwnd) {
271 ca->cnt = cwnd / (bic_target - cwnd);
272 } else {
273 ca->cnt = 100 * cwnd; /* very small increment*/
274 }
275
276 /*
277 * The initial growth of cubic function may be too conservative
278 * when the available bandwidth is still unknown.
279 */
280 if (ca->last_max_cwnd == 0 && ca->cnt > 20)
281 ca->cnt = 20; /* increase cwnd 5% per RTT */
282
283 /* TCP Friendly */
284 if (tcp_friendliness) {
285 u32 scale = beta_scale;
286 delta = (cwnd * scale) >> 3;
287 while (ca->ack_cnt > delta) { /* update tcp cwnd */
288 ca->ack_cnt -= delta;
289 ca->tcp_cwnd++;
290 }
291
292 if (ca->tcp_cwnd > cwnd){ /* if bic is slower than tcp */
293 delta = ca->tcp_cwnd - cwnd;
294 max_cnt = cwnd / delta;
295 if (ca->cnt > max_cnt)
296 ca->cnt = max_cnt;
297 }
298 }
299
300 ca->cnt = (ca->cnt << ACK_RATIO_SHIFT) / ca->delayed_ack;
301 if (ca->cnt == 0) /* cannot be zero */
302 ca->cnt = 1;
303 }
<net/ipv4/tcp_cong.c>
334 /* In theory this is tp->snd_cwnd += 1 / tp->snd_cwnd (or alternative w) */
335 void tcp_cong_avoid_ai(struct tcp_sock *tp, u32 w)
336 {
337 if (tp->snd_cwnd_cnt >= w) {
338 if (tp->snd_cwnd < tp->snd_cwnd_clamp)
339 tp->snd_cwnd++;
340 tp->snd_cwnd_cnt = 0;
341 } else {
342 tp->snd_cwnd_cnt++;
343 }
344 }
后来的“快速恢复”算法是在上述的“快速重传”算法后添加的,当收到3个重复ACK时,TCP最后进入的不是拥塞避免阶段,而是快速恢复阶段。快速重传和快速恢复算法一般同时使用。快速恢复的思想是“数据包守恒”原则,即同一个时刻在网络中的数据包数量是恒定的,只有当“老”数据包离开了网络后,才能向网络中发送一个“新”的数据包,如果发送方收到一个重复的ACK,那么根据TCP的ACK机制就表明有一个数据包离开了网络,于是cwnd加1。如果能够严格按照该原则那么网络中很少会发生拥塞,事实上拥塞控制的目的也就在修正违反该原则的地方。
快速重传和快速恢复
当收到乱序包时,tcp可能会立即应答,重复的应答不应该被延迟,重复ACK的目的是让对端知道一个收到数据包乱序了,并且通知对端其期望的序列号。
由于TCP并不知道一个重复的ACK源于一个丢失的数据包还是数据包的重组,其会继续等待是否有相同重复的ACK应答包。其基于如果数据包是乱序的,则收到重复的ACK应该数量在一个或者两个,然后是一个新的ACK到来,如果重复的ACK出现三次及以上,则预示着一个数据包丢失了。TCP然后会立即重传似乎丢失的数据包而不会等待重传定时器到期。
在快速重传似乎丢失的数据包后,拥塞避免算法,而不是慢启动算法被调用。这就是快速恢复的意义。这一方法使得在中度拥塞的情况下能有较高的吞吐率。
具体来说快速恢复的主要步骤是:
1.当收到3个重复ACK时,把ssthresh设置为cwnd的一半,把cwnd设置为ssthresh的值加3,然后重传丢失的报文段,加3的原因是因为收到3个重复的ACK,表明有3个“老”的数据包离开了网络。
2.再收到重复的ACK时,拥塞窗口增加1。
3.当收到新的数据包的ACK时,把cwnd设置为第一步中的ssthresh的值。原因是因为该ACK确认了新的数据,说明从重复ACK时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态。
更多推荐
 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)