
Linux环境下使用NLPIR(ICTCLAS)中文分词详解
本文作者:合肥工业大学 管理学院 钱洋 email:1563178220@qq.com 欢迎交流,禁止将本人博客直接复制下来,上传到百度文库等平台。NLPIR介绍NLPIR是中科院出的一款汉语分词系统(又名ICTCLAS2013),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。工程lib目录下win32、win64、linux32、linu
本文作者:合肥工业大学 管理学院 钱洋 email:1563178220@qq.com 欢迎交流,禁止将本人博客直接复制下来,上传到百度文库等平台。
NLPIR介绍
NLPIR是中科院出的一款汉语分词系统(又名ICTCLAS2013),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。工程lib目录下win32、win64、linux32、linux64都是包含库文件的文件夹。你需要根据自己的系统配置,选择相关的目录里的文件。
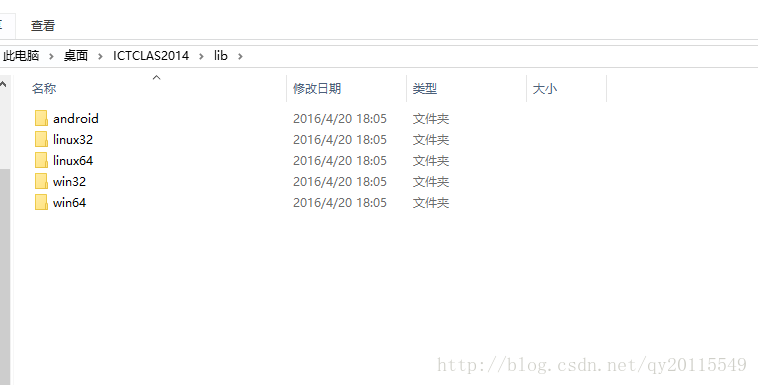
关于中科院分词软件的详细使用请见:http://www.datalearner.com/blog/1051461066435555。下面主要讲解linux下如何配置使用中科院分词软件。
Linux下的使用
首先,需要你建一个工程,在工程中,你需要将lib文件夹下的
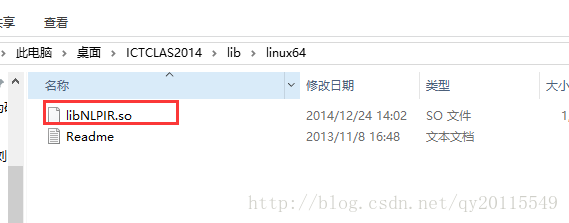
拷贝到工程的bin目录下。
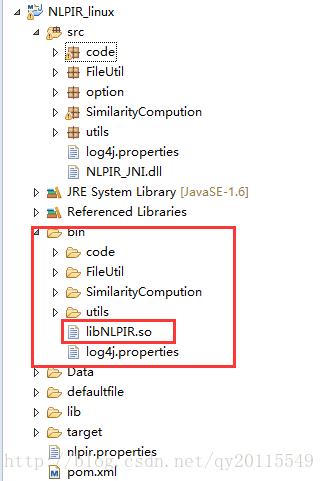
接下是将Data文件夹,拷贝到新建的工程的根目录中。

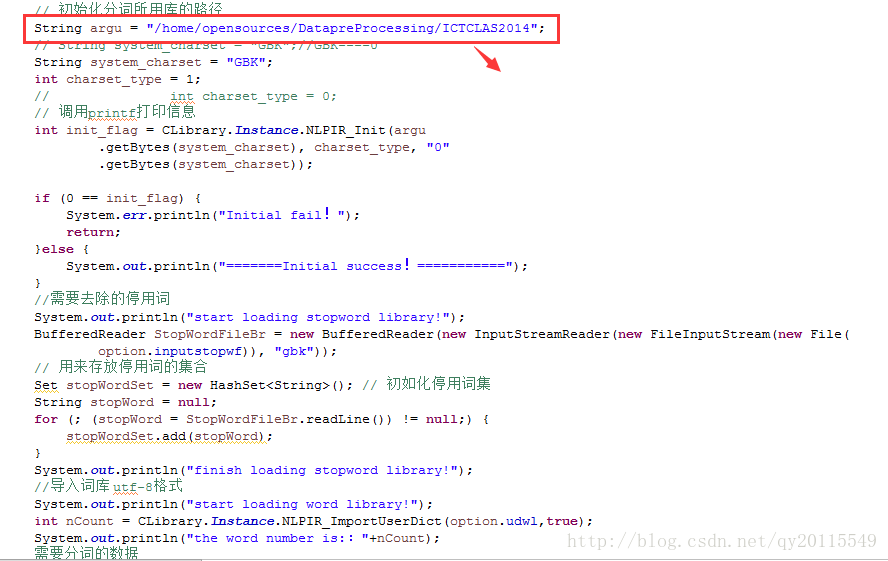
以下是核心程序的部分,标红的是配置的NLPIR中linux64在linux下的目录。

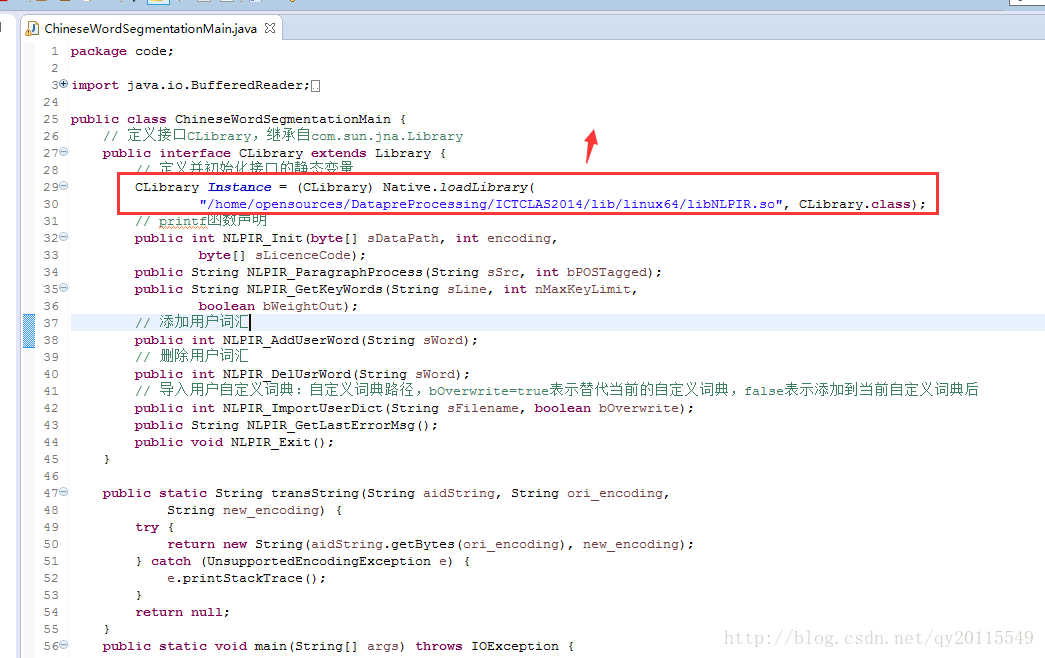
下面是配置argu的路径,这里注释错了就没有改,忽略掉吧,哈哈。
这个路径就是ICTCLAS的解压路径。

核心程序
由于最近正在做开源系统的集成工作,所以写了本篇博客。这里给出核心代码,供大家学习参考。
package code;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.kohsuke.args4j.CmdLineException;
import org.kohsuke.args4j.CmdLineParser;
import com.sun.jna.Library;
import com.sun.jna.Native;
import FileUtil.FileGetData;
import option.SampleCmdOption;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
* @
*/
public class ChineseWordSegmentationMain {
// 定义接口CLibrary,继承自com.sun.jna.Library
public interface CLibrary extends Library {
// 定义并初始化接口的静态变量
CLibrary Instance = (CLibrary) Native.loadLibrary(
"/home/opensources/DatapreProcessing/ICTCLAS2014/lib/linux64/libNLPIR.so", CLibrary.class);
// printf函数声明
public int NLPIR_Init(byte[] sDataPath, int encoding,
byte[] sLicenceCode);
public String NLPIR_ParagraphProcess(String sSrc, int bPOSTagged);
public String NLPIR_GetKeyWords(String sLine, int nMaxKeyLimit,
boolean bWeightOut);
// 添加用户词汇
public int NLPIR_AddUserWord(String sWord);
// 删除用户词汇
public int NLPIR_DelUsrWord(String sWord);
// 导入用户自定义词典:自定义词典路径,bOverwrite=true表示替代当前的自定义词典,false表示添加到当前自定义词典后
public int NLPIR_ImportUserDict(String sFilename, boolean bOverwrite);
public String NLPIR_GetLastErrorMsg();
public void NLPIR_Exit();
}
public static String transString(String aidString, String ori_encoding,
String new_encoding) {
try {
return new String(aidString.getBytes(ori_encoding), new_encoding);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) throws IOException {
System.out.println(args[1]);
//开始解析命令参数
SampleCmdOption option = new SampleCmdOption();
CmdLineParser parser = new CmdLineParser(option);
try {
if (args.length == 0){
showHelp(parser);
return;
}
parser.parseArgument(args);
//开始初步参数校验并调用程序开始运行
}catch (CmdLineException cle){
System.out.println("Command line error: " + cle.getMessage());
showHelp(parser);
return;
}catch (Exception e){
System.out.println("Error in main: " + e.getMessage());
e.printStackTrace();
return;
}
// 初始化分词所用库的路径
String argu = "/home/opensources/DatapreProcessing/ICTCLAS2014";
// String system_charset = "GBK";//GBK----0
String system_charset = "GBK";
int charset_type = 1;
// int charset_type = 0;
// 调用printf打印信息
int init_flag = CLibrary.Instance.NLPIR_Init(argu
.getBytes(system_charset), charset_type, "0"
.getBytes(system_charset));
if (0 == init_flag) {
System.err.println("Initial fail!");
return;
}else {
System.out.println("=======Initial success!===========");
}
//需要去除的停用词
System.out.println("start loading stopword library!");
BufferedReader StopWordFileBr = new BufferedReader(new InputStreamReader(new FileInputStream(new File(
option.inputstopwf)), "gbk"));
// 用来存放停用词的集合
Set stopWordSet = new HashSet<String>(); // 初如化停用词集
String stopWord = null;
for (; (stopWord = StopWordFileBr.readLine()) != null;) {
stopWordSet.add(stopWord);
}
System.out.println("finish loading stopword library!");
//导入词库 utf-8格式
System.out.println("start loading word library!");
int nCount = CLibrary.Instance.NLPIR_ImportUserDict(option.udwl,true);
System.out.println("the word number is::"+nCount);
// 需要分词的数据
FileGetData fileData=new FileGetData();
List<String> fileList = fileData.getFiles(option.inputfdir);
for (String file:fileList) {
System.out.println("The current segment file is:"+file.split("==")[0]);
BufferedReader reader = new BufferedReader( new InputStreamReader( new FileInputStream( new File(file.split("==")[0])),"utf-8"));
String s=null;
// 把过滤后的字符串数组存入到一个字符串中
StringBuffer finalStr = new StringBuffer();
while ((s=reader.readLine())!=null) {
//添加词典,中文必须是utf-8
String spiltResultStr = CLibrary.Instance.NLPIR_ParagraphProcess(s.replaceAll("发表在", "").replaceAll("\\d{1,4}\\p{Blank}楼", "").replaceAll("\\d{1,4}楼", "").replaceAll("http://[^\\s\"']+\\p{Alnum}", "").replaceAll("\\d{4}\\p{Punct}\\d{1,2}\\p{Punct}\\d{1,2}", "").replaceAll("\\d{4}\\p{Punct}\\d{1,2}\\p{Punct}\\d{1,2}\\s\\d{1,2}:\\d{1,2}:\\d{1,2}", "").replaceAll("\\d{1,2}:\\d{1,2}:\\d{1,2}", "").replaceAll("\\d{4}\\p{Punct}\\d{1,2}\\p{Punct}\\d{1,2}\\s\\d{1,2}:\\d{1,2}", "").replaceAll("\\d{5,200}", "").replaceAll("\\p{Alpha}{5,200}", "").replaceAll("\\p{Punct}", ""), 0);
// 得到分词后的词汇数组,以便后续比较
String[] resultArray = spiltResultStr.split(" ");
// 过滤停用词
for (int i = 0; i < resultArray.length; i++) {
if (stopWordSet.contains(resultArray[i])) {
resultArray[i] = null;
}
}
for (int i = 0; i < resultArray.length; i++) {
if (resultArray[i] != null&&resultArray[i].length()!=0) {
finalStr = finalStr.append(resultArray[i].trim()).append(" ");
}
}
}
BufferedWriter destFileBi = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(
option.outfdir+"\\"+file.split("==")[1]))));
// System.out.println("当前完成用户为:"+dataList.get(j).split("\u0001")[0]);
// 将过滤后的文本信息写入到指定文件中
destFileBi.append(finalStr.toString()+"\r\n");
destFileBi.newLine();
reader.close();
destFileBi.close();
StopWordFileBr.close();
}
}
public static void showHelp(CmdLineParser parser){
System.out.println("WordSegmentation [options ...] [arguments...]");
parser.printUsage(System.out);
}
}
其中,参数配置如下程序:
package option;
import org.kohsuke.args4j.Option;
/**
* @author:合肥工业大学 管理学院 钱洋
* @email:1563178220@qq.com
* @
*/
public class SampleCmdOption {
@Option(name="--inputstopwf", usage="Specify you file of stop word.The file type must be gbk.Default file is ../defaultfile/adduserdict.txt")
public String inputstopwf = "/home/opensources/DatapreProcessing/ICTCLAS2014/stopword.txt";
@Option(name="--udwl", usage="Specify you file of user-defined word library.The file type must be utf-8.Default file is ../defaultfile/adduserdict.txt")
public String udwl = "/home/opensources/DatapreProcessing/ICTCLAS2014/adduserdict.txt";
@Option(name="--inputfdir", usage="Specify your input directory file of text")
public String inputfdir = "";
@Option(name="--outfdir", usage="Specify your output directory file of text after segmentation")
public String outfdir = "";
}
linux下运行程序
这里讲程序打包成WordS.jar可运行的java文件。在linux下面输入上面SampleCmdOption 中的参数便可以运行了,so easy!
如下,是运行的命令。
cd /home/opensources/DatapreProcessing/
java -jar WordS.jar --inputfdir /home/opensources/DatapreProcessing/WordSegData/Text --outfdir /home/opensources/DatapreProcessing/WordSegData/AfterSeg
合肥工业大学 管理学院 钱洋 email:1563178220@qq.com 欢迎交流
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)