
python实现web请求与响应
HTTP(Hypertext Transfer Protocol)是 Web 上传输数据的协议,负责浏览器与服务器之间的通信。GET:请求服务器获取资源,通常用于读取数据。POST:提交数据到服务器,通常用于表单提交、文件上传等。PUT:更新服务器上的资源。DELETE:删除服务器上的资源。
Web请求
Web 请求通常包括以下几个部分:
- 请求行:包括请求方法(如 GET、POST、PUT、DELETE)、URL 和 HTTP 协议版本(如 HTTP/1.1)。
- 请求头:包含关于客户端信息、请求体类型、浏览器类型等的元数据。
- 请求体:在 POST 请求中包含用户提交的数据,如表单数据或文件。
Web 响应
Web 响应由服务器返回,通常包括以下几个部分:
- 响应行:包括 HTTP 协议版本、状态码和状态消息。
- 响应头:包括关于响应的信息,如内容类型、服务器信息等。
- 响应体:包含实际返回的数据(如 HTML 页面、JSON 数据等)。
HTTP 协议概述
HTTP(Hypertext Transfer Protocol)是 Web 上传输数据的协议,负责浏览器与服务器之间的通信。常见的 HTTP 方法有:
- GET:请求服务器获取资源,通常用于读取数据。
- POST:提交数据到服务器,通常用于表单提交、文件上传等。
- PUT:更新服务器上的资源。
- DELETE:删除服务器上的资源。
常见的 HTTP 状态码包括:
- 200 OK:请求成功,服务器返回所请求的数据。
- 301 Moved Permanently:资源已永久移动。
- 404 Not Found:请求的资源不存在。
- 500 Internal Server Error:服务器内部错误。
Python 的 requests 库
Python 的 requests 库是发送 HTTP 请求和处理响应的最常用工具,它提供了简单、直观的 API,使得 Web 请求和响应的操作变得非常容易。通过 requests,我们可以轻松地发送 GET、POST 请求,处理 JSON 响应,管理请求头等。
安装requests库
在使用 requests 之前,我们需要先安装它。如果你没有安装,可以通过以下命令安装:
发送 GET 请求
GET 请求通常用于获取数据,我们通过 requests.get () 来发送 GET 请求,并可以处理返回的响应。
![]()
#发送GET请求
![]()
#输出响应的状态码

#输出响应的内容
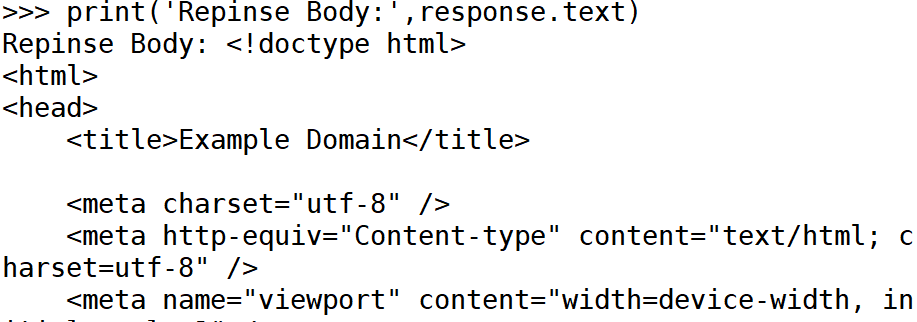
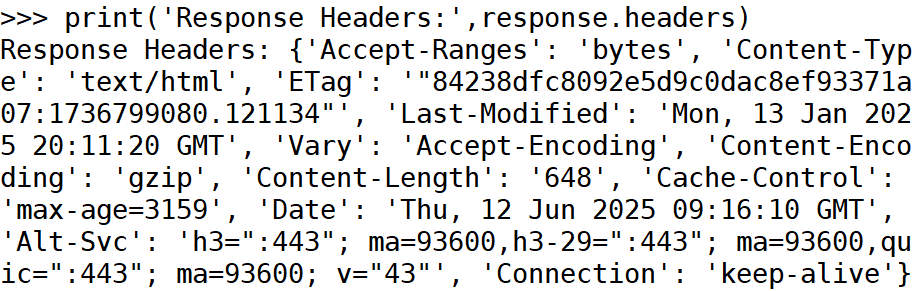
#输出响应头
#获取响应内容的长度
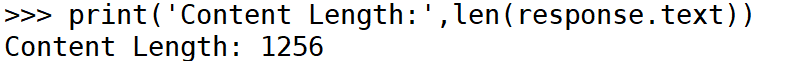
代码解释:
- requests.get () 用于发送 GET 请求,获取指定 URL 的数据。
- response.status_code 获取 HTTP 响应状态码。
- response.text 获取响应的正文内容(通常是 HTML 或 JSON 数据)。
- response.headers 获取响应头。
- len (response.text) 返回响应正文的长度,帮助我们了解返回内容的大小。
发送 POST 请求
POST 请求用于将数据提交到服务器,通常用于表单提交或上传文件。我们使用 requests.post () 来发送 POST 请求。
#发送POST请求

#输出响应状态码

#输出响应内容(JSON格式)

代码解释:
- requests.post () 用于发送 POST 请求,将数据提交到服务器。
- data 参数是一个字典,包含了我们要提交的数据。requests 会自动将其编码为 application/x-www-form-urlencoded 格式。
- response.json () 用于解析返回的 JSON 数据。
处理响应头和状态码
响应头提供了关于服务器的信息,状态码则告诉我们请求是否成功。我们可以通过 response.headers 获取响应头,通过 response.status_code 获取状态码。
#发送GET请求

#获取响应状态码

#获取内容类型

代码解释:
- response.headers 返回响应头,包含如 Content-Type、Date、Server 等信息。
- response.status_code 返回 HTTP 状态码。
- response.headers.get ('Content-Type') 获取响应的内容类型 (如 text/html、application/json)
发送带查询参数的 GET 请求
在 GET 请求中,我们可以通过 URL 传递查询参数。例如,访问一个包含参数的 URL。
#发送带查询参数的GET请求

#输出相应内容
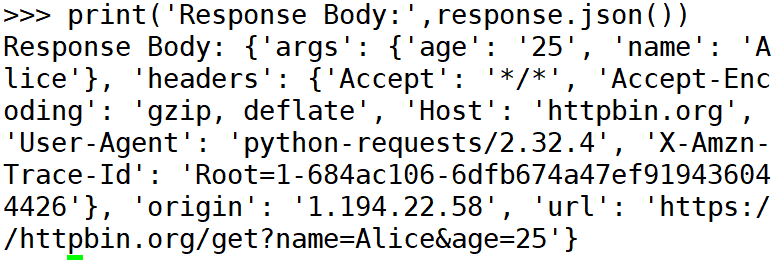
代码解释:
- params 是一个字典,包含要传递的查询参数。requests.get () 会自动将这些参数编码到 URL
送带表单数据的 POST 请求
POST 请求可以用来提交表单数据,下面的例子展示了如何使用 requests 发送带表单数据的
POST 请求。
#发送带表单数据的POST请求

#输出响应的内容
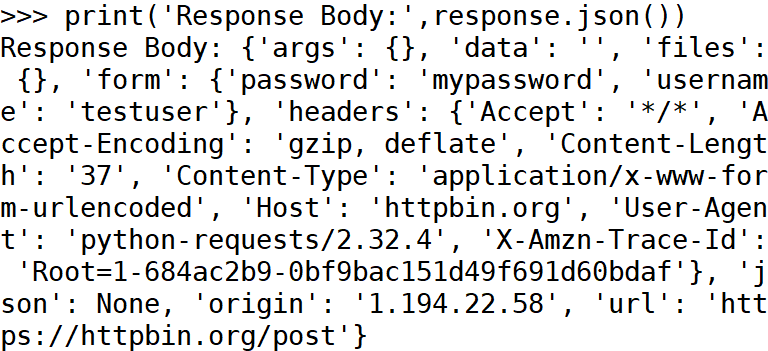
代码解释:
- data 参数是一个字典,包含表单提交的数据,requests 会自动将数据编码为 application/x-www-form-urlencoded 格式。
处理 JSON 响应
许多 Web API 返回的数据格式是 JSON,Python 的 requests 库提供了方便的 JSON 处理方法。
#发送GET请求并获取JSON响应

#解析JSON数据![]()
#输出用户的GItHub信息
代码解释:
- response.json () 将响应的内容解析为 Python 字典,方便我们处理 JSON 数据。
文件操作
文件操作是 Python 编程中常见的任务。Python 提供了多种方法来读取、写入和管理文件,能够处理文本文件、二进制文件以及目录操作等。掌握文件操作的基础和技巧是高效编程的关键。
打开文件的模式
Python 使用内置的 open () 函数来打开文件。打开文件时,我们需要指定文件模式(即操作文件的方式)。常见的文件模式如下:
常见的文件打开模式
| 模式 | 描述 |
|---|---|
| r | 只读模式(默认模式)。文件必须存在。如果文件不存在,会抛出 FileNotFoundError 异常 |
| w | 写入模式。如果文件存在,会覆盖文件内容。如果文件不存在,会创建新文件 |
| a | 追加模式。如果文件存在,写入的数据会追加到文件末尾;如果文件不存在,会创建新文件 |
| x | 独占创建模式。若文件已存在,操作会失败并抛出 FileExistsError 异常。此模式通常用于创建文件时防止覆盖现有文件 |
| rb | 二进制读取模式,用于读取非文本文件(如图片、音频文件) |
| wb | 二进制写入模式,用于写入非文本文件 |
| r+ | 读写模式。文件必须存在。既可以读取文件内容,也可以写入数据 |
| w+ | 读写模式。如果文件存在,会覆盖文件内容;如果文件不存在,会创建新文件 |
| a+ | 读写模式。文件存在时,数据会追加到文件末尾;如果文件不存在,会创建新文件 |
| rb+ | 二进制读写模式 |
打开文件并使模式
#以制度模式打开文件

#以写入模式打开文件,文件内容会被覆盖

#以追加模式打开文件,新的内容会追加到文件末尾

#以二进制模式打开文件(例如读取图片)

读取文件
Python 中的文件读取功能非常强大。以下是几种常见的读取方式:
read () 方法
read () 方法用于读取文件中的所有内容。读取后的内容会作为字符串返回。

readline () 方法
readline () 方法每次读取一行文件内容,适用于需要逐行处理文件的情况。

readlines () 方法
readlines () 方法会一次性读取文件中的所有行,并将每行数据存储为一个列表的元素,适用于需要读取整个文件并进行处理的情况。

写入文件
Python 提供了几种方法将数据写入文件。写入操作常用于日志记录、数据导出等场景。
使用 write () 方法写入文件
write () 方法将指定的字符串写入文件。若文件以 w 模式打开,原文件内容会被覆盖;若以 a 模式打开,内容会被追加到文件末尾。

使用 writelines () 方法写入多行数据
writelines () 方法接受一个可迭代对象(如列表、元组等),将其元素写入文件中,每个元素将作为一
行写入文件。

文件操作中的注意事项
在进行文件操作时,需要注意以下几个问题:
文件是否存在
在打开文件时,必须确保文件路径正确。如果文件不存在,可以使用os.path.exists()检查文件是否存在,或者使用try-except捕获FileNotFoundError异常。
import os
if os.path.exists('example.txt'):
with open('example.txt', 'r') as file:
content = file.read()
else:
print("文件不存在!")文件权限
在操作文件时,可能会遇到权限不足的问题。例如,尝试写入只读文件,或访问没有读取权限的文件。在这种情况下,可以使用try-except来捕获PermissionError 异常。
try:
with open('readonly_file.txt', 'w') as file:
file.write("尝试写入只读文件")
except PermissionError:
print("权限不足,无法写入文件。")文件自动关闭
使用with open()语句时,Python会自动管理文件的打开和关闭,无需显式调用file.close()。这有助于避免文件未关闭的问题,减少资源泄漏的风险。
其他常用文件操作
获取文件信息
Python提供了 os和 os.path 模块,可以获取文件的大小、修改时间等信息。
import os
file_path = 'example.txt'
print("文件大小:", os.path.getsize(file_path), "字节")
print("文件修改时间:", os.path.getmtime(file_path))删除文件
使用os.remove()可以删除文件:
import os
file_path = 'example.txt'
if os.path.exists(file_path):
os.remove(file_path)
print(f"{file_path}已删除!")
else:
print("文件不存在!")错误处理与异常捕获
在进行 Web 请求时,可能会发生各种错误,例如网络超时、服务器错误等。requests 库通过异常处理机制帮助我们捕获这些错误。Python 的 try语句能够捕获和处理代码块中的异常,从而避免程序崩溃,并且提供了处理错误的机会。
try语句的使用
try语句用于捕获和处理异常,它由三部分组成try语句用于捕获和处理异常,它由三部分组成:
| 组成部分 | 描述 |
|---|---|
| try 块 | 包含可能引发异常的代码,运行出错时跳转到对应 except 块处理 |
| except 块 | try 块代码出现异常时跳转执行,可指定捕获的异常类型(如 Timeout、HTTPError 等 ) |
| else 块(可选) | try 块代码未抛出异常时,执行其中代码 |
| finally 块(可选) | 无论是否发生异常,其中代码都会执行,常用于清理资源(如关闭文件、数据库连接等 ) |
import requests
from requests.exceptions import RequestException, Timeout, HTTPError
try:
# 发送GET请求,并设置超时时间为5秒
response = requests.get("https://www.example.com", timeout=5)
# 如果状态码不是200,抛出HTTPError异常
response.raise_for_status() # 如果状态码是404或500,抛出异常
# 如果请求成功,则输出响应内容
print("Response Body:", response.text)
# 捕获请求超时异常
except Timeout:
print('Request timed out')
# 捕获HTTP错误(如状态码404、500等)
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
# 捕获其他网络相关的错误
except RequestException as req_err:
print(f'Request error occurred: {req_err}')
# 可以在finally块中清理资源(如关闭文件或连接)
finally:
print("Request attempt completed.")代码解释:
- try 块 发起 HTTP 请求,设置超时 5 秒,用 response.raise_for_status() 检查状态码,若服务器返回 404、500 等错误码,抛出 HTTPError 异常
- except 块 - Timeout 请求超时(超 5 秒)时,捕获 Timeout 异常,打印 “Request timed out”
- except 块 - HTTPError 响应状态码为 HTTP 错误(如 404 )时,捕获 HTTPError 异常,打印相关错误信息
- except 块 - RequestException 捕获其他网络相关错误(如连接问题、DNS 解析失败等 ),因它是 requests 库异常基类,可捕获该库抛出的任意异常
- finally 块 无论是否异常都会执行,用于释放资源 / 收尾,此处打印 “Request attempt completed.” 标识请求结束
常处理总结:
异常处理让我们在程序运行中捕获到错误并做出相应处理,避免程序崩溃。
通过 try..except结构,可以精确捕获并处理不同类型的异常。
finally块用于清理工作,在请求处理完成后可以释放资源(如关闭文件、数据库连接等)

更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)