跑 AI 大模型的 K8s 与普通 K8s 有什么不同?
得益于AI开始火的时候,云原生体系已经普及,所以当前绝大多数的AI底层都是基于Kubernetes集群进行的资源管理(不像大数据,早期大量使用Yarn进行资源管理,在云原生普及后,还得面临这种云原生改造)。都知道云原生已经是Kubernetes的天下了,各大领域()早已纷纷采纳。那在面对大模型AI火热的当下,咱们从程序员三大件“计算、存储、网络”出发,一起看看这种?有哪些底层就可以构筑AI竞争的地
得益于 AI 开始火的时候,云原生体系已经普及,所以当前绝大多数的 AI 底层都是基于 Kubernetes 集群进行的资源管理(不像大数据,早期大量使用 Yarn 进行资源管理,在云原生普及后,还得面临 Spark on K8s 这种云原生改造)。

都知道云原生已经是 Kubernetes 的天下了,各大领域(大数据、互联网,基因、制药、时空、遥感、金融、游戏等)早已纷纷采纳。那在面对大模型 AI 火热的当下,咱们从程序员三大件 “计算、存储、网络” 出发,一起看看这种 跑大模型 AI 的 K8s 与普通的 K8s 有什么区别?有哪些底层就可以构筑 AI 竞争的地方。
计算
Kubernetes 是一个在大量节点上管理容器的系统,其主要功能总结起来,就是在想要启动容器的时候,负责 “找一个「空闲」节点,启动容器”。但是它默认考虑的启动因素(资源类)主要就是 “CPU + 内存”。就是容器指定 “我要多少 CPU + 多少内存”,然后 K8s 找到符合这个要求的节点。

但是,当容器运行需要特殊 “资源” 的时候,K8s 就熄火了。因为它不是认识 “GPU” 这种异构资源,不知道节点上面有多少 “异构资源”(只统计剩余 CPU + 内存资源)。
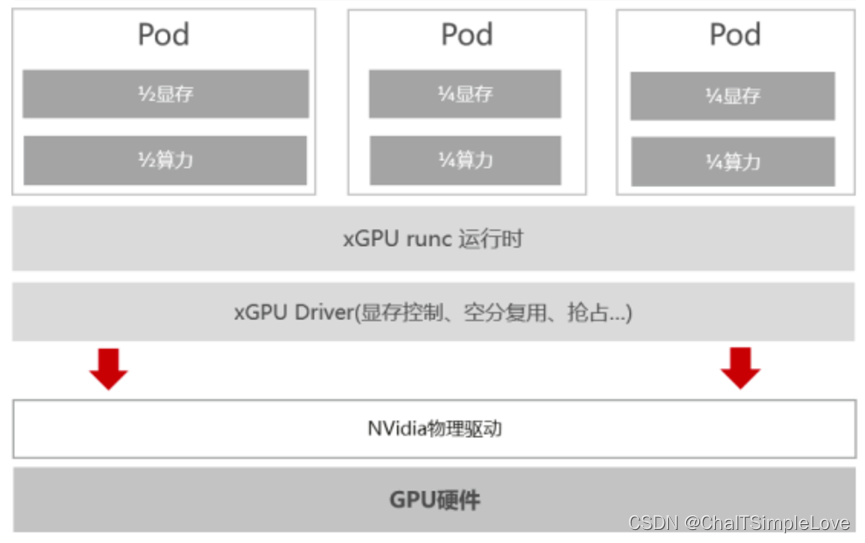
K8s 自己知道,异构资源千千万,每种使用方法也不一样,自己开发肯定搞不完。比如有 RoCE 网卡,GPU 卡,NPU 卡,FPGA,加密狗 等等各种硬件。仅单纯的 GPU 管理,就可以有 “每个容器挂 1 个 GPU”,或者 “几个容器共用 1 个 GPU”,甚至 “1 个 GPU 切分成多个 vGPU 分别给不同容器用” 多种用法。

所以,为了成为一个通用的资源调度系统,它(K8s)搞了个插件框架,来辅助自己判断节点有没有 “特殊资源”,叫做 Device-plugin 插件。用户需要自己完成这个 Device-plugin 的开发对接,来实时通知 K8s 节点上面 GPU 的使用情况,辅助 K8s 按需分配 GPU 算力。
总结就是咱们的 AI 集群里面,总会有一个 GPU 的 Device-plugin 用来辅助 GPU 调度。例如昇腾、含光等各家自研 NPU,就算是最简单的整卡调度,也得带这个 DP(Device-plugin)。

如果还需要 MIG 这样利用 vGPU 功能来提升 GPU 的利用率的话,那么 Device-plugin 插件的实现也会复杂很多。因为 A100 之前没有提供 GPU 虚拟化的标准实现,这个就看各家神通了。

其实目的都是大同小异的:就是增强 Device-plugin 插件逻辑,实现 GPU 资源的复用(显存 + 算力隔离),来提升底层 GPU 整体的利用率。虽然 K8s 新版本 1.27 之后,可以使用 DRA(Dynamic Resource Allocation) 框架实现动态切分,但是当前绝大多数的集群,依然是使用 DP 完成这个逻辑。

而且,K8s 设置的 “异构资源” 调度框架中,认为资源分配必须是 “整数” 的,即 容器可以要 1 个 GPU 卡,但是不能要 0.5 个 GPU 卡。所以想要实现多个容器,共用 1 个 GPU 卡的话(自己控制分时用,比如白天容器 1 用,晚上容器 2 用,这种性能比 vGPU 切分后用更好),还得增强 DP 逻辑(以及调度逻辑,后面会讲)。
最后,异构硬件故障的检测,任务的快速恢复,都需要这个 DP 的深入参与。
存储
其实 Kubernetes 集群本身也不管存储,主要管理的是容器 “如何接入” 存储。通过引入 PV 和 PVC 概念,标准的 K8s 都可以做到将存储挂载至容器中,使得容器里面的程序,像使用本地文件一样的访问远端存储。

在大规模 AI 训练场景下,样本数据的大小还是很可观的,基本都几百 T 的级别。所以 AI-Infrastructure 对存储的要求也会比较高。
更大的区别在于:训练是多轮迭代来逼近目标范围的,因为训练数据量太大,数据无法全部放入内存,在每轮迭代结束后,需要重新从文件系统里读取数据进行下一轮迭代的训练。即得重新访问样本进行一轮计算。那么如果每次都重新访问 “远程” 存储,性能必将大受影响(100T 数据,每个 epoch 重新读一遍 OBS 桶,你想想那得多慢)。
所以如何将大量的样本数据,就近缓存,就是 AI+K8s 系统需要重点考虑的问题。分布式缓存加速系统,就是其中一条路线。

常见的有 Juicefs,Alluxio 等产品,以及各云厂商提供的自研产品。它们的特点是:利用服务器本身就带的高速存储(比如 NVME/M.2 高速本地盘),来缓存样本数据。并提供分布式文件系统,达到就近全量存储的目的。这样在多轮的 epoch 训练中,可以大幅的提升样本访问速度,加快整体训练进度。
所以建设 or 使用 分布式缓存系统,也是 AI 平台建设中的重要一环。
网络
在 Kubernetes 的标准框架里,容器是只有 1 个网络平面的。即容器里面,只有 1 个 eth0 网卡。所以无论是利用 overlay 实现容器隧道网络,还是 underlay 实现容器网络直通,其目的都是解决容器网络 “通与不通” 的问题。

而大规模 AI 集群中,百亿、千亿级别参数量的大模型通常需要做分布式训练,这时参数梯度等信息要在节点间交换,就需要使用 RDMA 网络来传递。否则以普通以太网进行传输,其仅仅解决 “通与不通” 这种入门要求,参数信息传的实在太慢了。
RDMA 可以绕过 TCP/IP 协议栈,并且不需要 CPU 干预,直接从网卡硬件上开始网络数据传递,网络传输性能可以大幅的提升,大大加快训练参数的交换。

所以咱们的 AI 集群中,必须要将 RDMA 网络管理起来,使得所有 AI 容器可以通过这条路,完成各种集合通信算法(AllReduce 等)。

如上图,除了 「底部」 那条咱们平时看到的容器网络那条线外,顶部还有一个 「参数面」 网络。一般成本考虑咱们都是走 RoCE 方案,即用 IB 网卡 + 以太网交换机(而不是 IB 专用交换机)实现。而且由于 RDMA 协议要求网络是无损的(否则性能会受到极大的影响),而咱们要在以太网上实现无损网络,就需要引入 PFC(Priority-Based Flow Control) 流控逻辑。

这个就需要同时在交换机和服务器 RoCE 网卡上,两侧同时配置 PFC 策略进行流控,以实现无损网络。

可见,「参数面」网络的管理,会比普通主机网络,多一份 PFC 调优的复杂度。而且,由于 NCCL 性能直接影响训练速度,所以定位 NCCL 性能掉速 or 调优 NCCL 性能,也是系统必须提供的运维能力之一。
并且 RoCE 网卡 的管理,也属于 “异构资源”,也需要开发 Device-plugin 来告知 K8s 如何分配这种 RoCE 网卡。而且 GPU 和 RoCE 网卡 是需要进行联合分配的,因为硬件连接关系,必须是靠近在一起的配对一起用,如下:

调度
标准 K8s 集群的容器调度,都是单个容器独立考虑的:即取一个容器,找到其适合的节点,然后取下个容器调度。但是分布式 AI 训练容器不一样,它们是一组容器。这一组容器,必须同时运行,才可以进行集合通信,即所谓的 All_or_Nothing。通常也会叫 「Gang Scheduling」,这个是分布式 AI 场景的强诉求。否则会因为多个分布式作业在资源调度层面出现争抢,导致出现资源维度的死锁,结果是谁都没法正常训练。

因此 K8s 自带的 Scheduler 调度器对这种分布式 AI 训练中的 「pod-group」 型资源调度就无能为力了。这时 K8s 提供的「调度插件」框架,又再次发挥作用。用户可以自己开发调度器,集成到 K8s 集群中,实现自己的容器调度逻辑。
于是,各家又开始整活了。什么 Coscheduling,Yunikorn,Volcano,Koordinator,Katalyst 等纷纷上线。目的都差不多,先补 Gang Scheduling 基本功能,再补些 MPI 等辅助功能。

这里我们以 Volcano 为例,它除了完成分布式 AI 训练中 「Pod-group」 这种容器组的调度,还实现了容器组之间 「SSH 免密登录」,MPI 任务组的 「Hostfile 文件」 这些辅助实现。
小结
Kubernetes 云原生管理平台,已经成为 AI 数据中心的标准底座。由于 AI-Infrastructure 设备价格昂贵(参数面一根 200Gb 的网线要 7000 元,一台 8 卡的 GPU 服务器,超 150 万元),所以提升资源利用率是一个收益极大的途径。
在 提升资源利用率 方法上,常见有(1)调度算法的增强和(2)业务加速 2 种方式。
- (1)调度增强上,又分
Volcano这种pod-group组调度,来提升分布式训练的资源利用率。以及通过Device-plugin来获得vGPU算力切分或者多容器共用GPU卡的方式。 - (2)业务加速路径中,也有通过分布式缓存加速数据访问的。以及通过参数面
RDMA网络来加速模型参数同步的。

以上这些就是唐老师小结的,与平常使用 CPU 类业务的 K8s 集群不太不一样的地方。可见除了 Kubernetes 本身的复杂性外,要做好 AI 平台底层的各项竞争力,还是需要投入不少人力的。
- 来源 | OSCHINA 社区
- 作者 | 华为云开发者社区-tsjsdbd
- 原文链接:https://my.oschina.net/u/4526289/blog/10106268

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 2
2 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)