微服务框架下的分布式数据系统冗余数据同步
在微服务框架下,各个服务的数据组织与存储原则上应该进行拆分,以保证微服务在开发与部署方面的松散耦合、可扩展性、以及独立性。这里分享K8S部署Canal实现分布式数据系统中的冗余数据同步。
背景
我们都知道,在微服务框架下,各个服务的数据组织与存储原则上也应该进行拆分,以保证微服务在开发与部署方面的松散耦合、可扩展性、以及独立性。
但是,数据拆分又带来了新的挑战——跨服务数据访问的实现。这是一个复杂的问题,可能是很多种不同的情况,比如(但不仅限于这些):
- 跨服务业务流程的关键数据
- 跨服务信息查询的关联数据
对于业务流程的关键数据,通常是直接放在服务接口中传输,以保证业务的正确执行。也有的系统采用消息队列来实现服务间的调用,那么,关键数据也跟随队列消息传输。今天,所要讨论的是第二种情况——跨服务信息查询的关联数据。
思考
分布式数据的数据一致性
如何实现跨服务信息查询的关联数据获取,首先可以排除与业务流程关键数据一样的直接通过接口访问获取,因为这会导致微服务间的接口访问量骤增,毕竟绝大部分场景中,查询请求量是远大于写数据请求量的。因此,就需要利用分布式数据系统来实现。
在分布式数据系统中,CAP原则包含了三个要素:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容忍性(Partition tolerance)
但是,在实际项目中,往往很难做到全部满足,所以,就必须做出取舍。而对于分布式数据系统而言,不同节点之间的通信中断,还需要保证系统正常工作,这是基本要求。因此,就需要在一致性与可用性上取得平衡。对于大多数查询的关联数据,其实并一定要求具备强一致性。而是通过实现数据的最终一致性,来换取系统的高可用性。
所谓最终一致性,就是不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。
关于数据一致性,还有一些概念,比如ACID、强一致性、弱一致性、顺序一致性等。这里就不一一展开。
设计方案探究
上面讲了一堆枯燥的概念,接下来,让我们聊点实实在在的。首先,到底什么样的数据是跨服务的信息查询关联数据?最典型的就是,商品概要信息——除了商品服务,还有订单、物流、促销等不同的服务也需要,但是其他这些服务只需要查询,并不能修改商品服务中的商品数据。
其次,对于大多数中小型系统而言,一般有如下几种设计方案:
- 冗余数据作为值对象,跟随业务实体一起保存。通俗的讲,就是商品概要信息跟订单信息放在同一条记录中。
- 冗余数据采用源数据复制的方式单独保存。通俗的讲,就是创建单独的商品概要信息冗余表,从商品服务的源表复制数据过来。
- 对于一些被多个微服务用到的公共数据,尤其,如果还有一些特殊应用需求的时候,往往会使用其他异构的数据系统来处理。比如,数据检索功能要求高时采用 Elasticsearch,存在高并发场景时采用 Redis 等等。
这里对前两种方案做个对比。方案一的优点是查询简单,但是缺点也是很明显的,主要体现在两点:
- 源数据更新后,每个含有该冗余数据的业务表都需要同步,高耦合度带来高复杂度;
- 重复数据太多,增加硬件成本。
而方案二则相反,虽然查询时增加一次联表,但大大减少了重复数据,降低了成本,也使得更新数据的同步与业务的耦合度大大降低了,而变得简单多了,大大提升了可维护性。
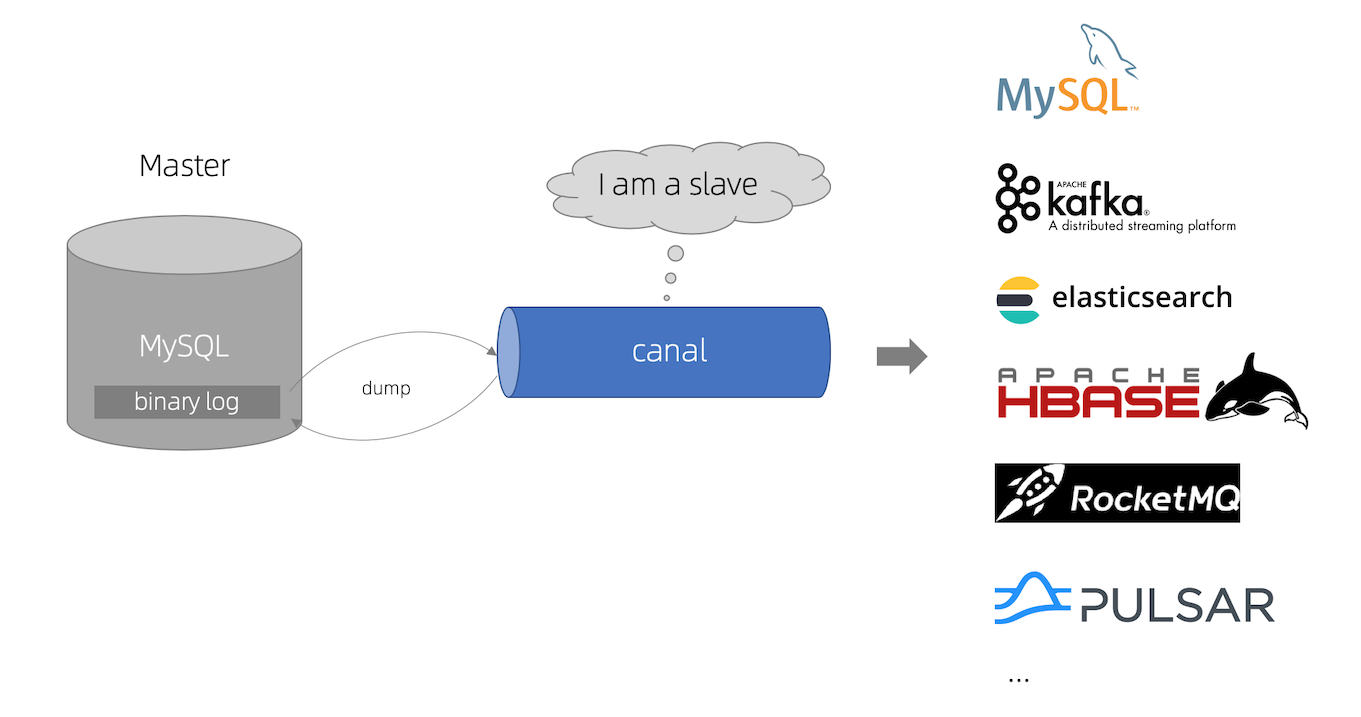
MySQL + Canal(K8S)实战
实际项目中,数据库采用的是MySQL,而大名鼎鼎的Canal,就是一套成熟的基于MySQL的增量数据同步解决方案。

Canal 官方所提供的 Canal Server 与 Canal Adapter,已经非常强大,通过配置就可以搞定。如果对高可靠性有要求,可以配套 ZooKeeper 部署,同时在 Canal Server 与 Canal Adapter 之间使用消息队列(比如,Kafka、RabbitMQ等)代替 TCP 直连,实现数据分发。
MySQL
首先,MySQL 需要开启 binlog。在 MySQL 8 中,binlog 默认是开启的;而如果是 MySQL 5.7,则需要在 my.cnf 配置文件中,[mysqld] 下面添加 log-bin。
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复Canal Server
Canal Server 采用 StatefulSet 模式在 Kubernetes 中部署。
apiVersion: apps/v1
kind: StatefulSet
metadata:
# ...
spec:
# ...
template:
spec:
containers:
- image: 'canal/canal-server:v1.1.6'
imagePullPolicy: IfNotPresent
name: canal-server
ports:
- containerPort: 11111
name: canal
protocol: TCP
volumeMounts:
- mountPath: /home/admin/canal-server/conf/example
name: volume-canal-server-conf
subPath: conf/example
volumes:
- name: volume-canal-server-conf
persistentVolumeClaim:
claimName: canal-server-conf挂载的存储声明里,是配置文件 conf/example/instance.properties。监控以 “myapp_” 开头的数据库的所有表。
# position info
canal.instance.master.address=x.x.x.x:3306
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
# enable druid Decrypt database password
canal.instance.enableDruid=false
# table regex
canal.instance.filter.regex=myapp_.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*Canal Adapter
由于官方并没有提供 Canal Adapter 的 docker 镜像,只能自己构建。下载 Canal Adapter 压缩包,解压;复制 bin/startup.sh,在最后加两行。
sleep 3s
tail -F logs/adapter/adapter.log编写 Dockfile,其中用修改的 startup.sh 覆盖,生成 canal-adapter 镜像。
FROM adoptopenjdk/openjdk11:centos-jre
RUN mkdir -p /opt/canal/adapter
ADD adapter /opt/canal/adapter
COPY startup.sh /opt/canal/adapter/bin/startup.sh
EXPOSE 8081
WORKDIR /opt/canal/adapter
CMD ["/bin/sh", "-c", "/opt/canal/adapter/bin/startup.sh"]
Canal Adapter 采用 Deployment 模式在 Kubernetes 中部署。
apiVersion: apps/v1
kind: Deployment
metadata:
# ...
spec:
template:
spec:
containers:
- image: 'registry.xxxx.com/common/canal-adapter:1.1.6'
name: canal-adapter
volumeMounts:
- mountPath: /opt/canal/adapter/conf
name: volume-canal-adapter-conf
subPath: conf
volumes:
- name: volume-canal-adapter-conf
persistentVolumeClaim:
claimName: canal-adapter-conf挂载的存储声明里,是从 Canal Adapter 压缩包中复制出来的 conf 文件夹。其中,appliation.yml 修改如下。
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
# ...
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: canal-server:11111
# ...
srcDataSources:
defaultDS:
url: jdbc:mysql://x.x.x.x:3306/myapp_product?useUnicode=true
username: canal
password: canal
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: myapp
outerAdapters:
- name: logger
- name: rdb
key: myapp_order
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://x.x.x.x:3306/myapp_order?useUnicode=true
jdbc.username: canal
jdbc.password: canal文件夹 rdb 下是同步表配置文件,下面的 order_product.yml 是一个例子。其中几个值要与 application.yml 中对应的保持一致。
dataSourceKey: defaultDS
destination: example
groupId: myapp
outerAdapterKey: myapp_order
concurrent: true
dbMapping:
database: myapp_product
table: product
targetTable: order_product
targetPk:
id: id
# mapAll: true
targetColumns:
id:
title:
image_url:
kinds:
status:
commitBatch: 3000 # 批量提交的大小
另外,Adapter的 REST 接口可以用来手动执行全量同步。
curl "http://localhost:8081/etl/rdb/myapp_order/order_product.yml" -X POST结束语
Canal 可以轻松实现 MySQL 的增量数据同步,也可以全量同步。但是,删除数据的同步还是需要另辟蹊径实现的。好在大部分情况下,一方面是,多余的数据(源表中已删除)一般不会对业务产生什么影响,另一方面,很多数据的所谓删除其实采用的是软删除,实际上是 UPDATE,并不是 DELETE 的硬删除。所以,利用K8S的定时任务,每天半夜里慢慢清理一下就行了。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)