K8S的介绍和架构
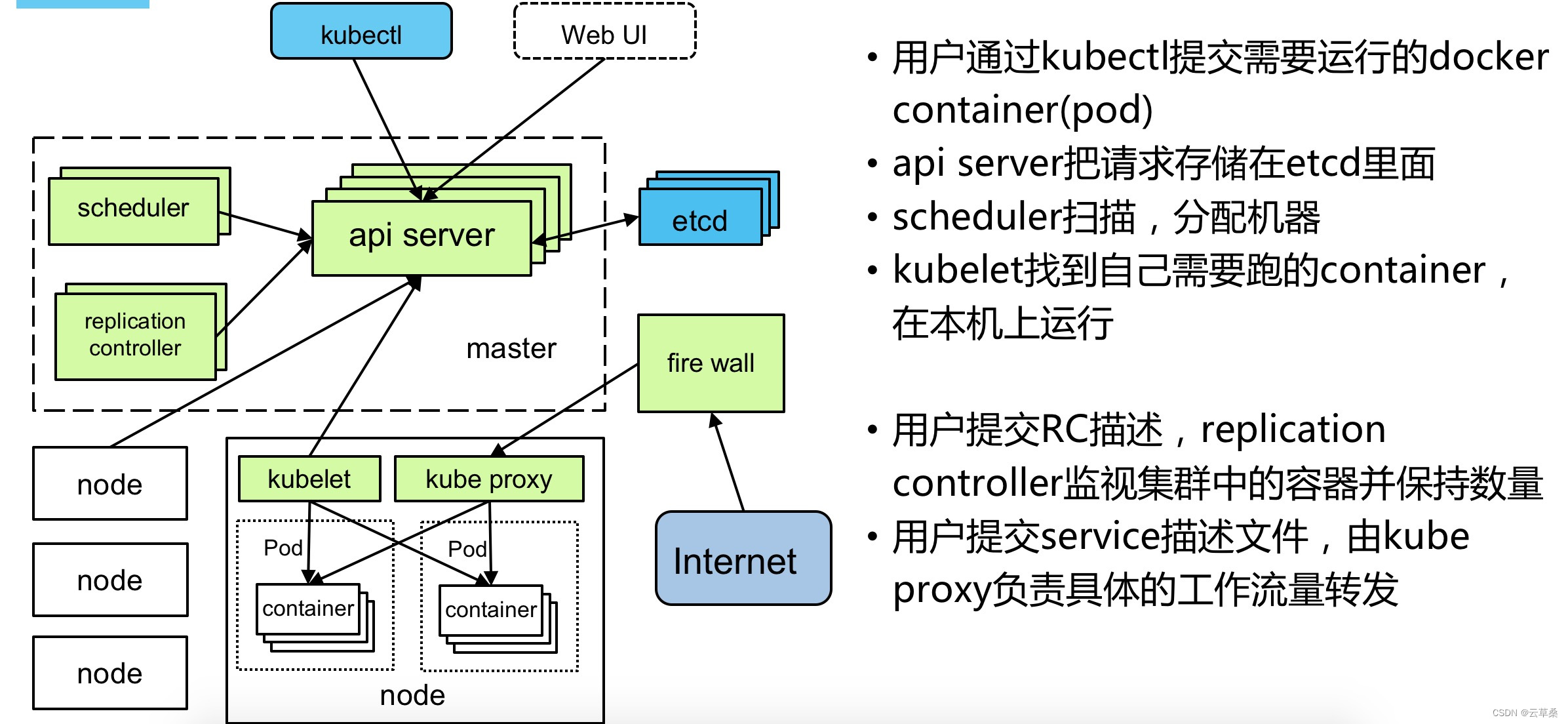
Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg),目前已经成为容器编排一个标准。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩、高可用等一系列完整功能,提高了大规模容器集群管理的便捷性。容器编排轻量级开源弹性伸缩负载均衡二、Kubernetes架构和组件。
仅供入门
K8S的介绍和架构
一. 什么是kubernetes
Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg),目前已经成为容器编排一个标准。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩、高可用等一系列完整功能,提高了大规模容器集群管理的便捷性。
Kubernetes优势:
- 容器编排
- 轻量级
- 开源
- 弹性伸缩
- 负载均衡
二、Kubernetes架构和组件

2.1 核心组件
2.1.1 Kubernetes Master控制组件,调度管理整个系统(集群),包含如下组件:
a、Kubernetes API Server
作为Kubernetes系统的入口,其封装了核心对象的增删改查操作,以RESTful API接口方式提供给外部客户和内部组件调用。它是系统管理指令的统一入口,任何对资源进行增删改查的操作都要交给APIServer处理后再提交给etcd。kubectl是直接和APIServer交互的。
a,提供了资源对象的唯一操作入口,其他所有组件都必须通过它提供的API来操作资源数据,只有API Server与存储通信,其他模块通过API Server访问集群状态。实现集群故障检测和恢复的自动化工作,负责执行各种控制器,主要有:
第一,是为了保证集群状态访问的安全。
第二,是为了隔离集群状态访问的方式和后端存储实现的方式:API Server是状态访问的方式,不会因为后端存储技术etcd的改变而改变。
b,作为kubernetes系统的入口,封装了核心对象的增删改查操作,以RESTFul接口方式提供给外部客户和内部组件调用。对相关的资源数据“全量查询”+“变化监听”,实时完成相关的业务功能
b、Kubernetes Scheduler
为新建立的Pod进行节点(node)选择(即分配机器),**负责集群的资源调度**。组件抽离,可以方便替换成其他调度器。
a,Scheduler收集和分析当前Kubernetes集群中所有Minion/Node节点的资源(内存、CPU)负载情况,然后依此分发新建的Pod到Kubernetes集群中可用的节点。
b,实时监测Kubernetes集群中未分发和已分发的所有运行的Pod。
c,Scheduler也监测Minion/Node节点信息,由于会频繁查找Minion/Node节点,Scheduler会缓存一份最新的信息在本地。
d,Scheduler在分发Pod到指定的Minion/Node节点后,会把Pod相关的信息Binding写回API Server。
c、Kubernetes Controller
负责执行各种控制器,目前已经提供了很多控制器来保证Kubernetes的正常运行。
- Replication Controller
管理维护Replication Controller,关联Replication Controller和Pod,保证Replication Controller定义的副本数量与实际运行Pod数量一致。
- Node Controller
管理维护Node,定期检查Node的健康状态,标识出(失效|未失效)的Node节点。
- Namespace Controller
管理维护Namespace,定期清理无效的Namespace,包括Namesapce下的API对象,比如Pod、Service等。
- Service Controller
管理维护Service,提供负载以及服务代理。
- EndPoints Controller
管理维护Endpoints,关联Service和Pod,创建Endpoints为Service的后端,当Pod发生变化时,实时更新Endpoints。
- Service Account Controller
管理维护Service Account,为每个Namespace创建默认的Service Account,同时为Service Account创建Service Account Secret。
- Persistent Volume Controller
管理维护Persistent Volume和Persistent Volume Claim,为新的Persistent Volume Claim分配Persistent Volume进行绑定,为释放的Persistent Volume执行清理回收。
- Daemon Set Controller
管理维护Daemon Set,负责创建Daemon Pod,保证指定的Node上正常的运行Daemon Pod。
- Deployment Controller
管理维护Deployment,关联Deployment和Replication Controller,保证运行指定数量的Pod。当Deployment更新时,控制实现Replication Controller和 Pod的更新。
- Job Controller
管理维护Job,为Jod创建一次性任务Pod,保证完成Job指定完成的任务数目
- Pod Autoscaler Controller
实现Pod的自动伸缩,定时获取监控数据,进行策略匹配,当满足条件时执行Pod的伸缩动作。
2.1.2 Kubernetes Node运行节点,运行管理业务容器,包含如下组件:
a、Kubelet
负责管控容器,Kubelet会从Kubernetes API Server接收Pod的创建请求,启动和停止容器,监控容器运行状态并汇报给Kubernetes API Server。
b、Kubernetes Proxy
负责为Pod创建代理服务,Kubernetes Proxy会从Kubernetes API Server获取所有的Service信息,并根据Service的信息创建代理服务,实现Service到Pod的请求路由和转发,从而实现Kubernetes层级的虚拟转发网络。该模块实现了Kubernetes中的服务发现和反向代理功能。
反向代理方面:kube-proxy支持TCP和UDP连接转发,默认基于Round Robin算法**将客户端流量转发到与service对应的一组后端pod。
** 服务发现方面: kube-proxy使用etcd的watch机制,监控集群中service和endpoint对象数据的动态变化,并且维护一个service到endpoint的映射关系,从而保证了后端pod的IP变化不会对访问者造成影响。另外kube-proxy还支持session affinity。
c、Docker
Node上需要运行容器服务。
2.1.3 master和node之外的组件:
a、etcd
一个高可用的K/V键值对存储和服务发现系统,etcd的功能是给flannel 提供数据存储,可以单机部署或者集群部署。
b、flannel
这里并不一定非要是flannel,也可以是其他。所有node上都是以flannel为主流来进行部署。**所有node节点上的docker启动的时候需要flannel分发IP地址,而flannel 就会去请求etcd中的配置,各个node分配不同的IP网段,类似于咱路由器DHCP 的功能,这样就有效的避免了IP地址的冲突,同时flannel 对docker容器的数据包进行转发到另一个node节点上,flannel服务这样就实现了整个K8S集群中docker容器网络互通问题。**
图解 K8s 核心概念和术语
我第一次接触容器编排调度工具是 Docker 自家的 Docker Swarm,主要解决当时公司内部业务项目部署繁琐的问题,我记得当时项目实现容器化之后,花在项目部署运维的时间大大减少了,当时觉得这玩意还挺新鲜的,原来自动化运维可以这么玩。
K8s 三大核心功能
K8s 是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过 K8s 能够进行应用的自动化部署和扩缩容。
K8s 是比容器更上一层的架构,它可以支持多种容器技术,比如我们熟悉的 Docker,K8s 定位是一个容器调度工具,它主要具备以下三大核心能力:
1、自动调度
k8s 将用户部署提交的容器放到 k8s 集群的任意一个节点中,k8s 可以根据容器所需要的资源大小,以及节点的负载情况来决定容器放在哪个节点上面。

2、自动修复
当 k8s 的健康检查机制发现某个节点出现问题,它会自动将该节点上的资源转移到其它节点上面完成自动恢复。

3、横向自动扩缩容
在 k8s 1.1+ 版本中,有一个功能叫 “ Horizontal Pod Autoscaler”,简称 “HPA”,意思是 Pod自动扩容,它可以预先定义 Pod 的负载指标,当达到预期设定的负载指标后,就会根据指标自动触发自动动态扩容/缩容行为。
1)横向自动扩容

2)横向自动缩容

节点
从上面的图可以看出来,k8s 集群的节点有两个角色,分别为 Master 节点和 Node 节点,整个 K8s 集群Master 和 Node 节点关系如下图所示:

1、Master 节点
Master 节点也称为控制节点,每个 k8s 集群都有一个 Master 节点负责整个集群的管理控制,我们上面介绍的 k8s 三大能力都是经过 Master 节点发起的,Master 节点包含了以下几个组件:

- API Server:提供了 HTTP Rest 接口的服务进程,所有资源对象的增、删、改、查等操作的唯一入口;
- Controller Manager:k8s 集群所有资源对象的自动化控制中心;
- Scheduler:k8s 集群所有资源对象自动化调度控制中心;
- ETCD:k8s 集群注册服务发现中心,可以保存 k8s 集群中所有资源对象的数据。
2、Node
Node 节点的作用是承接 Master 分配的工作负载,它主要有以下几个关键组件:

- kubelet:负责 Pod 对应容器的创建、启停等操作,与 Master 节点紧密协作;
- kube-porxy:实现 k8s 集群通信与负载均衡的组件。
从图上可看出,在 Node 节点上面,还需要一个容器运行环境,如果使用 Docker 技术栈,则还需要在 Node 节点上面安装 Docker Engine,专门负责该节点容器管理工作。
Pod
Pod 是 k8s 最重要而且是最基本的一个资源对象,它的结构如下:

从以上 Pod 的结构图可以看出,它其实是容器的一个上层包装结构,这也就是为什么 K8s 可以支持多种容器类型的原因,基于这方面,我理解 k8s 的定位就是一个编排与调度工具,而容器只是它调度的一个资源对象而已。
Pod 可包含多个容器在里面,每个 Pod 至少会有一个 Pause 容器,其它用户定义的容器都共享该 Pause 容器,Pause 容器的主要作用是用于定义 Pod 的 ip 和 volume。
Pod 在 k8s 集群中的位置如下图所示:

Label
Label 在 k8s 中是一个非常核心的概念,我们可以将 Label 指定到对应的资源对象中,例如 Node、Pod、Replica Set、Service 等,一个资源可以绑定任意个 Label,k8s 通过 Label 可实现多维度的资源分组管理,后续可通过 Label Selector 查询和筛选拥有某些 Label 的资源对象,例如创建一个 Pod,给定一个 Label,workerid=123,后续可通过 workerid=123 删除拥有该标签的 Pod 资源。

Replica Set
Replica Set 目的是为了定义一个期望的场景,比如定义某种 Pod 的副本数量在任意时刻都处于 Peplica Set 期望的值,假设 Replica Set 定义 Pod 的副本数目为:replicas=2,当该 Replica Set 提交给 Master 后,Master 会定期巡检该 Pod 在集群中的数目,如果发现该 Pod 挂掉了一个,Master 就会尝试依据 Replica Set 设置的 Pod 模版创建 Pod,以维持 Pod 的数量与 Replica Set 预期的 Pod 数量相同。
通过 Replica Set,k8s 集群实现了用户应用的高可用性,而且大大减少了运维工作量。因此生产环境一般用 Deployment 或者 Replica Set 去控制 Pod 的生命周期和期望值,而不是直接单独创建 Pod。

类似 Replica Set 的还有 Deployment,它的内部实现也是通过 Replica Set 实现的,可以说 Deployment 是 Replica Set 的升级版,它们之间的 yaml 配置文件格式大部分都相同。
Service (服务注册与发现+负载均衡)
Service 是 k8s 能够实现微服务集群的一个非常重要的概念,顾名思义,k8s 的 Service 就是我们平时所提及的微服务架构中的“微服务”,本文上面提及的 Pod、Replica Set 等都是为 Service 服务的资源, 如下图表示 Service、Pod、Replica Set 的关系:

从上图可看出,Service 定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,而 Service 则是通过 Label Selector 实现关联与对接的,Replica Set 保证服务集群资源始终处于期望值。
以上只是一个微服务,通常来说一个应用项目会由多个不同业务能力而又彼此独立的微服务组成,多个微服务间组成了一个强大而又高可用的应用服务集群。

Namespace
Namespace 顾名思义是命名空间的意思,在 k8s 中主要用于实现资源隔离的目的,用户可根据不同项目创建不同的 Namespace,通过 k8s 将资源分配到不同 Namespace 中,即可实现不同项目的资源隔离:

K8S集群安装
一、 环境准备
1. 1 机器环境
非常重要必须看咯
1、节点CPU核数必须是 :>= 2核 /内存要求必须是:>=2G ,否则k8s无法启动
2、DNS网络: 最好设置为 本地网络连通的DNS,否则网络不通,无法下载一些镜像
3、兼容问题
docker 19 kubernetes1.19.x
docker 20 kubernetes 1.20.x
在k8s1.21.1之后 k8s的默认容器不是Docker是Containerd (需要的 可以找我拿公开课)
注意:使用docker版本v20.10.8、kubernetes v1.20.5、Go版本v1.13.15
| 节点hostname | 作用 | IP |
|---|---|---|
| kmaster | kmaster | 192.168.3.10 |
| knode1 | kwork1 | 192.168.3.11 |
| knode2 | kwork2 | 192.168.3.12 |
1.2 设置主机别名
1
2
3
[root@localhost ~]# hostnamectl set-hostname kmaster --static
[root@localhost ~]# hostnamectl set-hostname kworker1 --static
[root@localhost ~]# hostnamectl set-hostname kworker2 --static
1.3 服务器静态IP配置
1
2
3
4
5
6
7
8
9
10
11
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
BOOTPROTO="static" #dhcp改为static
ONBOOT="yes" #开机启用本配置
IPADDR=192.168.3.10 #静态IP 192.168.8.11/192.168.8.12
GATEWAY=192.168.3.1 #默认网关
NETMASK=255.255.255.0 #子网掩码
DNS1=114.114.114.114 #DNS 配置
DNS2=8.8.8.8 #DNS 配置【必须配置,否则SDK镜像下载很慢】
## 重启所有服务器
[root@localhost ~] reboot
1.4 查看主机名
1
2
## 看看别名是否生效
hostname
1.5 配置IP host映射关系
1
2
3
4
5
## 编辑/etc/hosts文件,配置映射关系
vi /etc/hosts
192.168.3.10 kmaster
192.168.3.11 kworker1
192.168.3.12 kworker2
1.6 安装依赖环境
注意:每一台机器都需要安装此依赖环境
yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstatlibseccomp wget vim net-tools git iproute lrzsz bash-completion tree bridge-utils unzip bind-utils gcc
1.7 防火墙配置
安装iptables,启动iptables,设置开机自启,清空iptables规则,保存当前规则到默认规则
1
2
3
4
# 关闭防火墙(生产环境建议使用放行端口)
systemctl stop firewalld && systemctl disable firewalld
# 置空iptables (生产环境别执行)
yum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables -F && service iptables save
1.8 关闭selinux[必须操作]
因为在K8S集群安装的时候需要执行脚本,如果Selinux没有关闭它会阻止执行。
1
2
3
4
# 关闭swap分区【虚拟内存】并且永久关闭虚拟内存
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# 关闭selinux
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
二、系统设置调整
2.1 调整内核参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
#将优化内核文件拷贝到/etc/sysctl.d/文件夹下,这样优化文件开机的时候能够被调用
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
#手动刷新,让优化文件立即生效
sysctl -p /etc/sysctl.d/kubernetes.conf
2.2 调整系统临时区
1
2
3
4
5
6
7
#设置系统时区为中国/上海
timedatectl set-timezone "Asia/Shanghai"
#将当前的UTC 时间写入硬件时钟
timedatectl set-local-rtc 0
#重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
2.3 关闭系统不需要的服务(生产环境别玩儿)
systemctl stop postfix && systemctl disable postfix
2.4 设置日志保存方式
2.4.1 创建保存日志的目录
mkdir /var/log/journal
2.4.2 创建配置文件存放目录
mkdir /etc/systemd/journald.conf.d
2.4.3 创建配置文件
1
2
3
4
5
6
7
8
9
10
11
12
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
Storage=persistent
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
SystemMaxUse=10G
SystemMaxFileSize=200M
MaxRetentionSec=2week
ForwardToSyslog=no
EOF
2.4.4 重启systemd journald 的配置
systemctl restart systemd-journald
2.4.5 打开文件数调整(可忽略,不执行)
1
2
echo "* soft nofile 65536" >> /etc/security/limits.conf
echo "* hard nofile 65536" >> /etc/security/limits.conf
2.4.6 kube-proxy 开启 ipvs 前置条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
#使用lsmod命令查看这些文件是否被引导
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
=========================执行结果================================
ip_vs_sh 16384 0
ip_vs_wrr 16384 0
ip_vs_rr 16384 0
ip_vs 147456 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack_ipv4 20480 0
nf_defrag_ipv4 16384 1 nf_conntrack_ipv4
nf_conntrack 114688 2 ip_vs,nf_conntrack_ipv4
libcrc32c 16384 2 xfs,ip_vs
三、Docker部署
3.1 安装docker
1
2
3
4
5
6
# 安装依赖
yum install -y yum-utils device-mapper-persistent-data lvm2
#紧接着配置一个稳定的仓库、仓库配置会保存到/etc/yum.repos.d/docker-ce.repo文件中
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
#更新Yum安装的相关Docker软件包&安装Docker CE(这里安装Docker最新版本)
yum update -y && yum install docker-ce
3.2 设置docker daemon文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#创建/etc/docker目录
mkdir /etc/docker
#更新daemon.json文件
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://ebkn7ykm.mirror.aliyuncs.com",
"https://docker.mirrors.ustc.edu.cn",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
#注意:一定注意编码问题,出现错误---查看命令:journalctl -amu docker 即可发现错误
#创建,存储docker配置文件
# mkdir -p /etc/systemd/system/docker.service.d
3.3 重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
四、kubeadm安装K8S
4.1 yum仓库镜像
国内镜像配置(国内建议配置)
1
2
3
4
5
6
7
8
9
10
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
官网镜像配置
1
2
3
4
5
6
7
8
9
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
4.2 安装kubeadm 、kubelet、kubectl(1.20.5)
1
2
3
# 指定版本
yum install -y kubelet-1.20.5 kubeadm-1.20.5 kubectl-1.20.5 --disableexcludes=kubernetes
systemctl enable kubelet && systemctl start kubelet
注意:以上操作所有机器都必须安装
五、准备k8s镜像
5.1 修改配置文件
[root@master ~]$ kubeadm config print init-defaults > kubeadm-init.yaml
该文件有两处需要修改:
- 将
advertiseAddress: 1.2.3.4修改为本机地址,比如使用192.168.3.191作为master,就修改advertiseAddress: 192.168.3.191 - 将
imageRepository: k8s.gcr.io修改为imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
修改完毕后文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.3.191 # 本机IP
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers #镜像仓库
kind: ClusterConfiguration
kubernetesVersion: v1.20.1
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 新增Pod子网络
scheduler: {}
5.2 根据配置文件拉取镜像
[root@kmaster ~]$ kubeadm config images pull --config kubeadm-init.yaml
六、K8S的Master部署
6.1 执行初始化
[root@master ~]$ kubeadm init --config kubeadm-init.yaml
6.2 验证是否成功
1
2
3
## 如果在执行完成后出现下面的语句 代表成功 并记录下加入worker节点的命令
kubeadm join 192.168.3.10:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:13aff92657d0f3451ac68e3200ebc3c1c6ea6980b1de700ba257ad1538e0ce3
6.3 查看Master节点网络状态
1
2
3
4
5
6
7
8
9
10
11
12
## 配置kubectl执行命令环境
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
## 执行kubectl命令查看机器节点
kubectl get node
-----------------------------------------
NAME STATUS ROLES AGE VERSION
master NotReady master 48m v1.20.1
## 发现节点STATUS是NotReady的,是因为没有配置网络
6.4 配置网络
使用以下命令安装Calico网络
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
wget https://docs.projectcalico.org/manifests/calico.yaml
## 编辑calico.yaml
## 修改calico.yaml文件设置指定的网卡
# Cluster type to identify the deployment type
- name: CLUSTER_TYPE
value: "k8s,bgp"
# IP automatic detection
- name: IP_AUTODETECTION_METHOD
value: "interface=en.*"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Never"
## 构建calico网络
kubectl apply -f calico.yaml
此时查看node信息, master的状态已经是Ready了.
1
2
3
[root@master ~]$ kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready master 48m v1.20.5
看到STATUS是Ready的,说明网络已经通了。
七、追加Node节点
1
2
3
## 到其他几个node节点进行执行即可
kubeadm join 192.168.3.10:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:37eb59b3459a1651222a98e35d057cfd102e8ae311c5fc9bb4be22cd46a59c29
八、验证状态
1
2
3
4
5
6
7
8
[root@kmaster ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
kmaster Ready control-plane,master 26m v1.20.5
kworker1 Ready <none> 5m37s v1.20.5
kworker2 Ready <none> 5m28s v1.20.5
[root@kmaster ~]# kubectl get pod -n kube-system -o wide
## 如果看到下面的pod状态都是Running状态,说明K8S集群环境就构建完成
安装 Kubernetes Dashboard
下载Dashboard
安装
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml
创建dashboard-admin.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
cat > dashboard-admin.yaml << EOF
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: admin
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: admin
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
EOF
创建登录用户
kubectl apply -f dashboard-admin.yaml
查看admin-user账户的token
1
2
3
4
5
6
kubectl -n kube-system get secret|grep admin-token
kubectl -n kube-system describe secret admin-token-w94tz
## 直接获取token
kubectl -n kube-system get secret admin-token-w94tz -o jsonpath={.data.token}|base64 -d
火狐浏览器直接访问,输入token即可正常访问
https://192.168.3.251:31443/
解决谷歌无法验证证书问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15openssl genrsa -out dashboard.key 2048 # 172.16.64.229为master节点的IP地址 openssl req -new -out dashboard.csr -key dashboard.key -subj '/CN=172.16.64.229' openssl x509 -req -in dashboard.csr -signkey dashboard.key -out dashboard.crt kubectl delete secret kubernetes-dashboard-certs -n kubernetes-dashboard kubectl create secret generic kubernetes-dashboard-certs --from-file=dashboard.key --from-file=dashboard.crt -n kubernetes-dashboard kubectl get pod -n kubernetes-dashboard kubectl delete po kubernetes-dashboard-b65488c4-rcdjh -n kubernetes-dashboard ## 批量删除 kubectl get pod -n kubernetes-dashboard | grep -v NAME | awk '{print "kubectl delete po " $1 " -n kubernetes-dashboard"}' | sh1 2 3kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.5/aio/deploy/recommended.yaml 所以我们找到配置文件:https://github.com/kubernetes/dashboard/tree/master/aio/deploy
附录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
kubectl delete node --all # 删除所有的节点
kubeadm reset -f # 重置kubeadm
modprobe -r ipip
lsmod
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
yum remove kube*演示模板
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-demo-deployment
labels:
app: nginx-deploy-demo
spec:
# 配置rs
replicas: 3
selector:
matchLabels:
app: nginx-rs
## 配置是POD模板
template:
metadata:
labels:
app: nginx-rs
env: testing
spec:
containers:
- name: nginx-container
imagePullPolicy: Always
image: nginx
ports:
- name: nginx-port
containerPort: 80 #必须和dockerfile中暴露端口一致
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30335
selector:
app: nginx-rs完整模板
apiVersion: apps/v1 # 指定api版本,此值必须在kubectl api-versions中
kind: Deployment # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: demo # 资源的名字,在同一个namespace中必须唯一
namespace: default # 部署在哪个namespace中
labels: # 设定资源的标签
app: demo
version: stable
spec: # 资源规范字段
replicas: 1 # 声明副本数目
revisionHistoryLimit: 3 # 保留历史版本
selector: # 选择器
matchLabels: # 匹配标签
app: demo
version: stable
strategy: # 策略
rollingUpdate: # 滚动更新
maxSurge: 30% # 最大额外可以存在的副本数,可以为百分比,也可以为整数
maxUnavailable: 30% # 示在更新过程中能够进入不可用状态的 Pod 的最大值,可以为百分比,也可以为整数
type: RollingUpdate # 滚动更新策略
template: # 模版
metadata: # 资源的元数据/属性
annotations: # 自定义注解列表
sidecar.istio.io/inject: "false" # 自定义注解名字
labels: # 设定资源的标签
app: demo
version: stable
spec: # 资源规范字段
containers:
- name: demo # 容器的名字
image: demo:v1 # 容器使用的镜像地址
imagePullPolicy: IfNotPresent # 每次Pod启动拉取镜像策略,三个选择 Always、Never、IfNotPresent
# Always,每次都检查;Never,每次都不检查(不管本地是否有);IfNotPresent,如果本地有就不检查,如果没有就拉取(手动测试时,
# 已经打好镜像存在docker容器中时,使用存在不检查级别,
# 默认为每次都检查,然后会进行拉取新镜像,因镜像仓库不存在,导致部署失败)
resources: # 资源管理
limits: # 最大使用
cpu: 300m # CPU,1核心 = 1000m
memory: 500Mi # 内存,1G = 1000Mi
requests: # 容器运行时,最低资源需求,也就是说最少需要多少资源容器才能正常运行
cpu: 100m
memory: 100Mi
livenessProbe: # pod 内部健康检查的设置
httpGet: # 通过httpget检查健康,返回200-399之间,则认为容器正常
path: /healthCheck # URI地址
port: 8080 # 端口
scheme: HTTP # 协议
# host: 127.0.0.1 # 主机地址
initialDelaySeconds: 30 # 表明第一次检测在容器启动后多长时间后开始
timeoutSeconds: 5 # 检测的超时时间
periodSeconds: 30 # 检查间隔时间
successThreshold: 1 # 成功门槛
failureThreshold: 5 # 失败门槛,连接失败5次,pod杀掉,重启一个新的pod
readinessProbe: # Pod 准备服务健康检查设置
httpGet:
path: /healthCheck
port: 8080
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 5
#也可以用这种方法
#exec: 执行命令的方法进行监测,如果其退出码不为0,则认为容器正常
# command:
# - cat
# - /tmp/health
#也可以用这种方法
#tcpSocket: # 通过tcpSocket检查健康
# port: number
ports:
- name: http # 名称
containerPort: 8080 # 容器开发对外的端口
protocol: TCP # 协议
imagePullSecrets: # 镜像仓库拉取密钥
- name: harbor-certification
affinity: # 亲和性调试
nodeAffinity: # 节点亲和力
requiredDuringSchedulingIgnoredDuringExecution: # pod 必须部署到满足条件的节点上
nodeSelectorTerms: # 节点满足任何一个条件就可以
- matchExpressions: # 有多个选项,则只有同时满足这些逻辑选项的节点才能运行 pod
- key: beta.kubernetes.io/arch
operator: In
values:
- amd64
---
apiVersion: v1 # 指定api版本,此值必须在kubectl api-versions中
kind: Service # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: demo # 资源的名字,在同一个namespace中必须唯一
namespace: default # 部署在哪个namespace中
labels: # 设定资源的标签
app: demo
spec: # 资源规范字段
type: ClusterIP # ClusterIP 类型
ports:
- port: 8080 # service 端口
targetPort: http # pod端口容器暴露的端口
protocol: TCP # 协议
name: http # 端口名称
nodePort: 31319 # 对外访问端口
selector: # 选择器
app: demo
K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)