GKE 容器被“内存 cgroup 内存不足”杀死,但监控、本地测试和 pprof 显示使用量远低于限制
回答问题 我最近将一个新的容器映像推送到我的一个 GKE 部署中,并注意到 API 延迟上升并且请求开始返回 502。 查看日志我发现容器由于OOM而开始崩溃: Memory cgroup out of memory: Killed process 2774370 (main) total-vm:1801348kB, anon-rss:1043688kB, file-rss:12884kB, sh
回答问题
我最近将一个新的容器映像推送到我的一个 GKE 部署中,并注意到 API 延迟上升并且请求开始返回 502。
查看日志我发现容器由于OOM而开始崩溃:
Memory cgroup out of memory: Killed process 2774370 (main) total-vm:1801348kB, anon-rss:1043688kB, file-rss:12884kB, shmem-rss:0kB, UID:0 pgtables:2236kB oom_score_adj:980
查看内存使用情况图表,Pod 使用的内存总和并没有超过 50MB。我最初的资源请求是:
...
spec:
...
template:
...
spec:
...
containers:
- name: api-server
...
resources:
# You must specify requests for CPU to autoscale
# based on CPU utilization
requests:
cpu: "150m"
memory: "80Mi"
limits:
cpu: "1"
memory: "1024Mi"
- name: cloud-sql-proxy
# It is recommended to use the latest version of the Cloud SQL proxy
# Make sure to update on a regular schedule!
image: gcr.io/cloudsql-docker/gce-proxy:1.17
resources:
# You must specify requests for CPU to autoscale
# based on CPU utilization
requests:
cpu: "100m"
...
然后我尝试将 API 服务器的请求增加到 1GB,但没有帮助。最后,帮助将容器映像恢复到以前的版本:
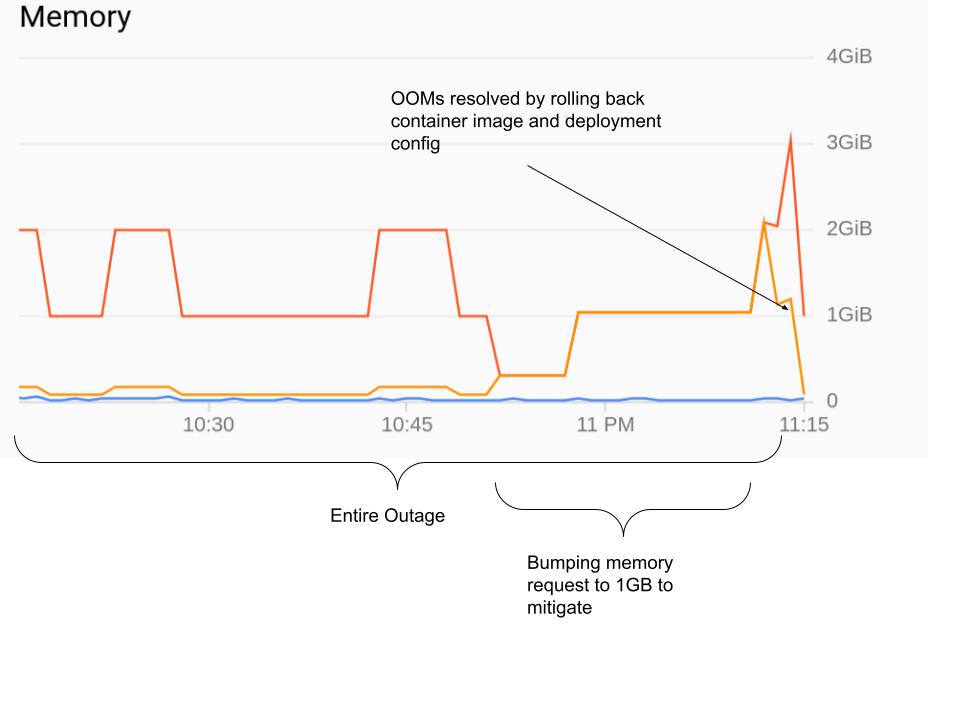
查看 golang 二进制文件中的更改,没有明显的内存泄漏。当我在本地运行它时,它最多使用 80MB 的内存,即使在与生产环境相同的请求负载下也是如此。
我从 GKE 控制台获得的上图也显示了 pod 使用的内存远低于 1GB 内存限制。
所以我的问题是:当 GKE 监控和在本地运行它只使用 1GB 限制中的 80MB 时,什么可能导致 GKE 终止我的 OOM 进程?
\u003du003du003d 编辑 u003du003du003d
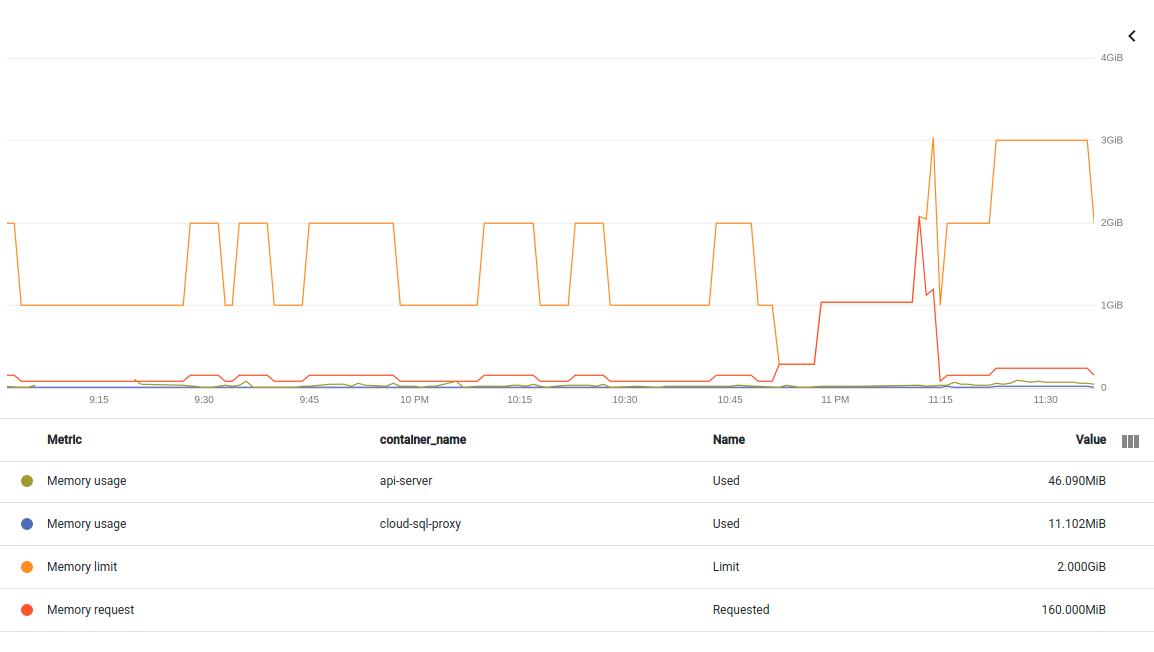
添加另一个相同中断的图表。这次拆分 pod 中的两个容器。如果我理解正确,这里的指标是non-evictable container/memory/used_bytes:
container/memory/used_bytes GA
Memory usage
GAUGE, INT64, By
k8s_container Memory usage in bytes. Sampled every 60 seconds.
memory_type: Either `evictable` or `non-evictable`. Evictable memory is memory that can be easily reclaimed by the kernel, while non-evictable memory cannot.
编辑 2021 年 4 月 26 日
我尝试将部署 yaml 中的资源字段更新为请求的 1GB RAM 和 Paul 和 Ryan 建议的 1GB RAM 限制:
resources:
# You must specify requests for CPU to autoscale
# based on CPU utilization
requests:
cpu: "150m"
memory: "1024Mi"
limits:
cpu: "1"
memory: "1024Mi"
不幸的是,在使用kubectl apply -f api_server_deployment.yaml更新后,结果相同:
{
insertId: "yyq7u3g2sy7f00"
jsonPayload: {
apiVersion: "v1"
eventTime: null
involvedObject: {
kind: "Node"
name: "gke-api-us-central-1-e2-highcpu-4-nod-dfe5c3a6-c0jy"
uid: "gke-api-us-central-1-e2-highcpu-4-nod-dfe5c3a6-c0jy"
}
kind: "Event"
message: "Memory cgroup out of memory: Killed process 1707107 (main) total-vm:1801412kB, anon-rss:1043284kB, file-rss:9732kB, shmem-rss:0kB, UID:0 pgtables:2224kB oom_score_adj:741"
metadata: {
creationTimestamp: "2021-04-26T23:13:13Z"
managedFields: [
0: {
apiVersion: "v1"
fieldsType: "FieldsV1"
fieldsV1: {
f:count: {
}
f:firstTimestamp: {
}
f:involvedObject: {
f:kind: {
}
f:name: {
}
f:uid: {
}
}
f:lastTimestamp: {
}
f:message: {
}
f:reason: {
}
f:source: {
f:component: {
}
f:host: {
}
}
f:type: {
}
}
manager: "node-problem-detector"
operation: "Update"
time: "2021-04-26T23:13:13Z"
}
]
name: "gke-api-us-central-1-e2-highcpu-4-nod-dfe5c3a6-c0jy.16798b61e3b76ec7"
namespace: "default"
resourceVersion: "156359"
selfLink: "/api/v1/namespaces/default/events/gke-api-us-central-1-e2-highcpu-4-nod-dfe5c3a6-c0jy.16798b61e3b76ec7"
uid: "da2ad319-3f86-4ec7-8467-e7523c9eff1c"
}
reason: "OOMKilling"
reportingComponent: ""
reportingInstance: ""
source: {
component: "kernel-monitor"
host: "gke-api-us-central-1-e2-highcpu-4-nod-dfe5c3a6-c0jy"
}
type: "Warning"
}
logName: "projects/questions-279902/logs/events"
receiveTimestamp: "2021-04-26T23:13:16.918764734Z"
resource: {
labels: {
cluster_name: "api-us-central-1"
location: "us-central1-a"
node_name: "gke-api-us-central-1-e2-highcpu-4-nod-dfe5c3a6-c0jy"
project_id: "questions-279902"
}
type: "k8s_node"
}
severity: "WARNING"
timestamp: "2021-04-26T23:13:13Z"
}
Kubernetes 似乎几乎立即杀死了使用 1GB 内存的容器。但同样,指标显示该容器仅使用 2MB 内存:
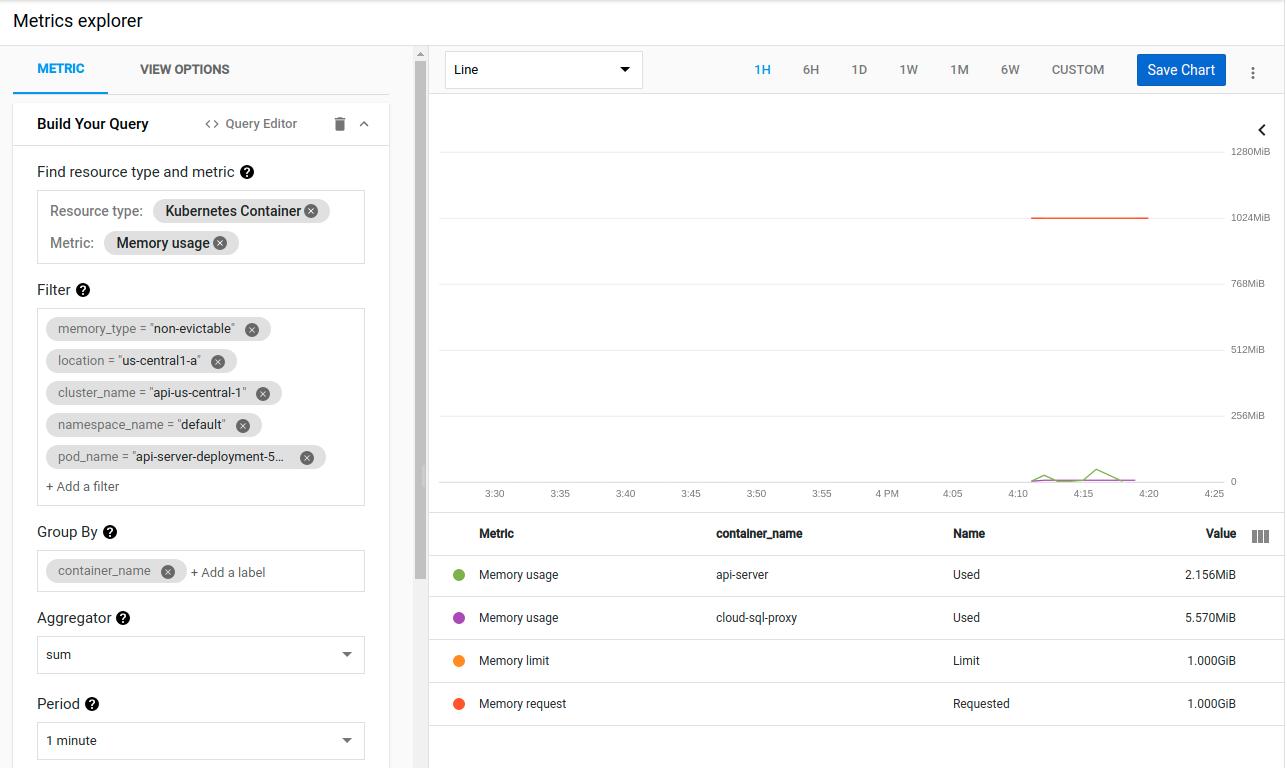
我再次感到难过,因为即使在负载下,当我在本地运行它时,这个二进制文件也不会使用超过 80MB。
我也试过运行go tool pprof <url>/debug/pprof/heap。它显示了几个不同的值,因为 Kubernetes 不断地破坏容器。但没有一个高于~20MB,而且内存使用量也没有异常
编辑 04/27
我尝试为 pod 中的两个容器设置 requestu003dlimit:
requests:
cpu: "1"
memory: "1024Mi"
limits:
cpu: "1"
memory: "1024Mi"
...
requests:
cpu: "100m"
memory: "200Mi"
limits:
cpu: "100m"
memory: "200Mi"
但它也没有工作:
Memory cgroup out of memory: Killed process 2662217 (main) total-vm:1800900kB, anon-rss:1042888kB, file-rss:10384kB, shmem-rss:0kB, UID:0 pgtables:2224kB oom_score_adj:-998
并且内存指标仍然显示单位数 MB 的使用情况。
更新 04/30
我通过煞费苦心地逐一检查我的最新提交来确定似乎导致此问题的更改。
在有问题的提交中,我有几行像
type Pic struct {
image.Image
Proto *pb.Image
}
...
pic.Image = picture.Resize(pic, sz.Height, sz.Width)
...
其中picture.Resize最终调用resize.Resize。我将其更改为:
type Pic struct {
Img image.Image
Proto *pb.Image
}
...
pic.Img = picture.Resize(pic.Img, sz.Height, sz.Width)
这解决了我的直接问题,容器现在运行良好。但它没有回答我原来的问题:
-
为什么这些行会导致 GKE OOM 我的容器?
-
为什么 GKE 内存指标显示一切正常?
Answers
确保“保证”的 QoS 类对您的方案没有帮助。您的一个进程导致父 cgroup 超出其内存限制 - 反过来由您针对相应容器指定的内存限制值设置 - 并且 OOM 杀手终止它。这不是 pod 驱逐,因为您可以在日志中清楚地看到 OOM 杀手的商标信息。如果另一个 pod 分配了如此多的内存,从而使节点处于内存压力之下,那么“保证的”QoS 类将有所帮助 - 在这种情况下,您的“保证”的 pod 将得以幸免。但是在你的情况下,Kubelet 从来没有在这一切中得到任何消息——比如决定完全驱逐 pod——因为OOM 杀手的行为更快。
Burak Serdar 在其评论中有一个很好的观点——大内存块的临时分配。情况很可能是这样,因为在您粘贴的消息中收集数据的分辨率是 60 秒。那是很多时间。一个人可以在不到 1 秒的时间内轻松填满 GB 的 RAM。我的假设是,内存“峰值”永远不会被渲染,因为指标永远不会被及时收集(即使你直接查询 cAdvisor 也会很棘手,因为它有 10-15 秒的分辨率来收集它的指标)。
如何更多地了解正在发生的事情?几个想法:
-
有一些工具可以显示应用程序实际分配了多少,直至框架级别。在 .NET 中,dotMemory 是一种常用的工具,可以在容器内运行并捕获正在发生的事情。 Go 可能有一个等价物。这种方法的问题在于,当容器被 OOMKilled 时,该工具会随之被删除
-
在您自己的应用程序中写入有关内存使用情况的详细信息。在这里你会发现一个电影,它捕获了一个分配内存的进程,直到它的父容器被 OOM 杀死。相应的 .NET 应用程序不时将其使用的内存量写入控制台,即使容器不再存在,Kubernetes 日志也会显示这些内存量,从而可以查看发生了什么
-
限制应用程序,使其处理少量数据(例如,如果您每分钟只处理 1 张图片,暂时从内存的角度来看会发生什么)
-
查看详细的OOM杀手内核日志,可以看到cgroup中的所有进程。在一个容器中拥有多个进程是完全有效的(就像在该容器中除了 PID 1 的进程之外的其他进程一样),OOM 杀手可以很好地杀死其中的任何一个。在这种情况下,您可能会偶然发现意想不到的曲折。然而,在您的场景中,主进程似乎已被终止,否则容器不会被 OOMkilled,因此这种情况不太可能发生。
只是为了完整起见:底层框架可以强制执行低于容器内存限制的限制。例如。在 .NET 中,当在具有内存限制的容器中运行时,这是 75%。换句话说,一个 .NET 应用程序在具有 2,000 MiB 限制的容器内分配内存将在 1,500 MiB 时出错。然而在这种情况下,您会得到一个退出代码 139 (SIGSEGV)。这似乎不适用于此处,因为 OOM 杀手终止了该进程,并且从内核日志中可以清楚地看到实际使用了所有 1 GiB (anon-rss:1043688kB)。据我所知,Go 还没有类似的设置,尽管社区一再要求它。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献20439条内容
已为社区贡献20439条内容

所有评论(0)