AKS 中的 Pod 到 Pod 网络延迟
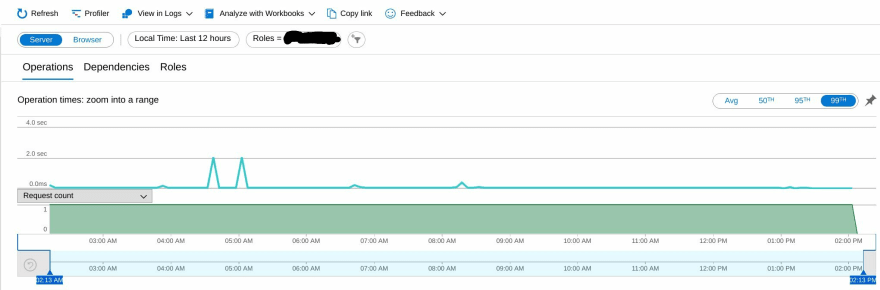
在过去的几个月里,我一直在观察我们 AKS 集群中 pod 之间的内部 http 通信的间歇性网络延迟。但是“间歇”和“缓慢”是什么意思呢?一张图片胜过一千个字,所以我们开始:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--F5fczxuJ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/2gl2sifgf09mj5bk0fxp.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--F5fczxuJ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/2gl2sifgf09mj5bk0fxp.jpg)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--sKG5LJYx--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/4dw5wbdsgi1a8lpbqd0p.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--sKG5LJYx--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/4dw5wbdsgi1a8lpbqd0p.jpg)
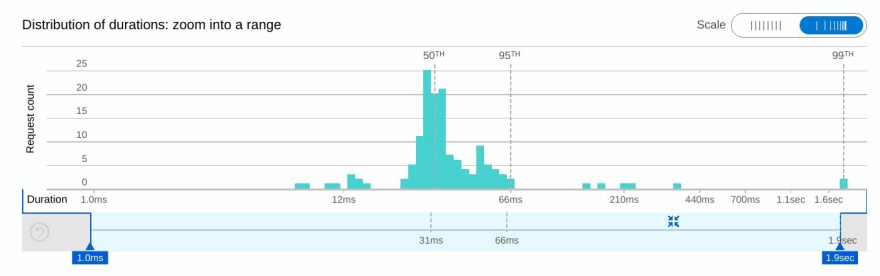
您会很快注意到有一些异常值,从 200-300 毫秒到 2 秒不等!
经过仔细检查,其中一个进程外的 pod 到 pod 调用花费了太长时间:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--20cKswT---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to -uploads.s3.amazonaws.com/uploads/articles/7glyrksxprzy29px9y0u.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--20cKswT---/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to -uploads.s3.amazonaws.com/uploads/articles/7glyrksxprzy29px9y0u.jpg)
现在,原因可能是多方面的:
- 发件人问题(发送延迟)
2.网络问题(传输延迟)
- 收件人问题(接收/处理延迟)
从上面的最后一个屏幕截图看来,收件人处理响应的速度非常快,而时间在两者之间的某个地方丢失了。
即使我觉得这帮不上什么忙,我还是打开了一个 MS Support Ticket 来检查我们的 AKS 集群中的任何网络问题...... MS Support 代理建议嗅探网络流量,这是一个非常好的提示(我不过,我必须复习我的 Wireshark 知识)。
事实证明,在 K8s 集群中的 Pod 之间嗅探网络流量非常容易(前提是您具有管理员访问权限)。 MS 建议使用 ksniff 但也有更简单的方法,我后来才在上搜索。所以使用 ksniff 你只需要:
- 安装 krew(kubectl 的插件安装程序) -https://krew.sigs.k8s.io/docs/user-guide/setup/install/
2.安装ksniff -https://github.com/eldadru/ksniff#installation
-
安装 Wireshark/tshark - 这里我有一个问题,默认 Ubuntu 存储库包含旧版本的 Wireshark/tshark,所以这个 github 问题评论帮助了我
-
嗅
kubectl sniff POD-NAME -n POD-NAMESPACE-NAME -p
进入全屏模式 退出全屏模式
(参数 -p 很重要,否则我得到“......无法访问'/tmp/static-tcpdump':没有这样的文件或目录”错误)
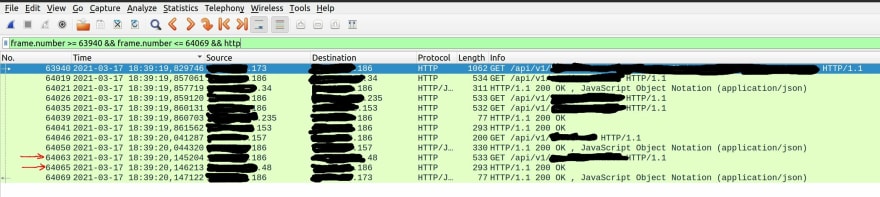
...瞧,Wireshark 会自动打开并开始获取网络流量。我将http放入过滤器中,这样我就只能看到 http 流量并开始等待再次出现问题...这需要 7-8 小时。这就是我得到的(这次是 317 毫秒而不是 2 秒,但它会有所不同):
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--g7UWGIal--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/pbf05gn43vvzvyk30ja0.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--g7UWGIal--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/pbf05gn43vvzvyk30ja0.jpg)
然而,在 Application Insights 屏幕截图中占用 300 多毫秒的请求在此跟踪中只占用了 1 毫秒......奇怪的是它开始的时间要晚得多——比我在 Application Insights 中看到的要晚 300 毫秒......
删除 Wireshark 中的http过滤器显示了一些有趣的 DNS 通信,红色标记的请求-响应需要 300 毫秒!
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--YGbYi73i--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/bmvyz6x9095xr32nss1w.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--YGbYi73i--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/bmvyz6x9095xr32nss1w.png)
事实证明,我们在调用 pod 配置中使用了目标服务(Kubernetes 服务,后面有 1 个或多个 pod)主机名,如下所示:
http://xxxxxxxx.default.svc.cluster.local/api/...
并且不知何故,AKS 或 K8s 通过再次附加.default.svc.cluster.local(或其中的一部分)来尝试多个 DNS 查找,直到最后它尝试查找当然会立即找到的原始主机名......并且其中一个 DNS 查找需要更长的时间不时。
解决方案(至少现在,直到 MS 提出更好的解决方案):在我们的调用 pod 配置中删除所有目标服务主机名的后缀.default.svc.cluster.local。现在的画面不一样了:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--PVBskAIT--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/qhs5tax1re6v9gtuacv4.jpg)
](https://res.cloudinary.com/practicaldev/image/fetch/s--PVBskAIT--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/uploads/articles/qhs5tax1re6v9gtuacv4.jpg)
希望以上内容可以帮助某人避免此问题!

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献4375条内容
已为社区贡献4375条内容

所有评论(0)