segement anything 论文阅读笔记
本人个人学习笔记,如有错误欢迎指正,欢迎友好交流讨论
一、介绍
在介绍部分提到了clip,align等基于大模型llm的微调方法,后续给出了本文的任务
1、何种任务能实现零样本泛化?
2、对应的模型架构是什么?
3、哪些数据能驱动该任务和模型?
文中给出了对应的模型结构,结构为带prompt的图像,通过对其进行分割。
二、模型的核心任务:
1、主要任务
对比NLP的prompt以及视觉prompt,定义提示的可分割任务。传统的nlp任务通过文字引导模型产生特定输出,而sam通过对模型的prompt拓展,采用多模态的prompt,例如框以及提示点。最后对于任意的输入,我们需要给出合适的输出(一个掩码分割)如下图所示,点即为prompt
2、预训练
传统的交互式模型训练需要用户多次提供提示,模型逐步优化掩码,最终达到精确效果。而在sam中对于任意的单次模糊输入提示,都得给出合理的分割。于是对于训练数据,sam有如下设计:对每个训练样本(图像+真实掩码),自动生成多组提示:
-
明确提示:从真实掩码中采样精确点/框
-
模糊提示:在物体边缘或重叠区域采样模棱两可的点
-
噪声提示:添加随机偏移的框或低分辨率掩码
三个训练阶段:

3、模型的零样本迁移:
因为庞大的预训练量,sam可以作为基础模型适应下游的训练任务
三、论文的模型设计
模型为三个部分,一个图像编码器,一个prompt编码器以及解码器
Image encoder:
采用MAE的预训练好的vit模型作为视觉编码器
prompt encoder:
对于prompt encoder,论文中分为两类
一类为稀疏提示,如点,框,文本。
点和框位置编码,采用正弦编码(trans结构),将坐标映射到高维空间。加上类型嵌入
文本编码:使用clip文本编码器
第二类为稠密提示,连续,高维的掩码图
采用轻量卷积神经网络提取掩码的局部以及全局特征。
Mask decoder:
SAM的decoder采用双向交叉注意力机制

分类头

关于前景概率的介绍:
指模型对图像中每个像素属于目标物体(即“前景”)的置信度评分。

损失函数的设计:
SAM采用 Focal Loss + Dice Loss 的线性组合
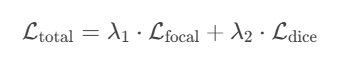
其中,Focal Loss用于解决类别不平衡问题,公式如下
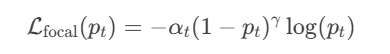
明显的看出,可以抑制趋近于1或者0的梯度,放大在0.5的梯度,也就是放大分类不明显的梯度
dice梯度为优化掩码的交并比,X为预测的像素集合,Y为真实掩码的像素集合
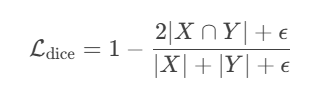
换为概率p则为以下形式
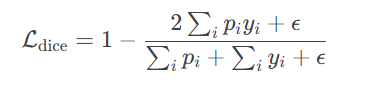
四、数据引擎
首先介绍数据集的大小:
为1100万张图片以及11亿个高质量的分割掩码(这也注定了消耗是巨大的,普通科研工作者无法做到),数据生成的方式是数据引擎,通过三个阶段的自动化或半自动化生成高质量的掩码。(因为市面上很少有到像素级别的高质量掩码,需要自己做)
引擎的三个阶段
1、人工辅助标注阶段
通过工作人员使用交互式工具点击对象的前景来进行标注,只进行分割,不设置标签(即不进行分类任务,无类别标签)

2、半自动标注阶段
第一阶段问题为主要针对显著对象,对于小物体的分割能力较弱。
方案:使用第一阶段的标注数据训练一个通用目标检测器,对图像生成置信度较高的掩码员工对已经生成自动掩码的图像上标注未检测的物体。自动标注无法处理低置信度对象,人工介入保障了困难样本的质量。
3、全自动标注


均匀的铺设点阵目的为对每个物体都有相应的prompt提示,从而进行训练。真实掩码来源于前面两个阶段标注的掩码。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)