python自动化运维快速入门
DevOps是一种文化、一组实践和工具,旨在提高组织交付应用程序和服务的能力。它强调开发团队和运维团队之间的协作,通过自动化软件交付和基础设施变更来缩短开发周期。在本文中,我们学习了Python在DevOps与自动化运维中的应用:容器化与Docker:使用Python操作Docker和Docker Compose持续集成/持续交付(CI/CD):使用Python构建简单的CI/CD流水线监控与日志
今天,我们将学习Python在DevOps与自动化运维中的应用。DevOps是一种结合开发(Development)和运维(Operations)的方法论,它强调自动化和团队协作,而Python是实现DevOps自动化的理想工具。
02 DevOps基础
什么是DevOps?
DevOps是一种文化、一组实践和工具,旨在提高组织交付应用程序和服务的能力。它强调开发团队和运维团队之间的协作,通过自动化软件交付和基础设施变更来缩短开发周期。
DevOps核心原则
-
自动化 :自动化重复任务,减少人为错误
-
持续集成/持续交付(CI/CD) :频繁地集成代码并自动部署
-
基础设施即代码(IaC) :使用代码管理和配置基础设施
-
监控与日志 :实时监控系统并收集日志
-
协作与沟通 :打破团队之间的壁垒
03 自动化脚本编写
文件操作自动化
import os
import shutil
import glob
# 创建目录
def create_directory(path):
if not os.path.exists(path):
os.makedirs(path)
print(f"目录 {path} 创建成功")
else:
print(f"目录 {path} 已存在")
# 复制文件
def copy_files(source_dir, dest_dir, pattern="*"):
create_directory(dest_dir)
for file in glob.glob(os.path.join(source_dir, pattern)):
if os.path.isfile(file):
shutil.copy2(file, dest_dir)
print(f"文件 {file} 复制到 {dest_dir}")
# 批量重命名文件
def batch_rename(directory, old_prefix, new_prefix):
for filename in os.listdir(directory):
if filename.startswith(old_prefix):
new_name = filename.replace(old_prefix, new_prefix, 1)
os.rename(
os.path.join(directory, filename),
os.path.join(directory, new_name)
)
print(f"文件 {filename} 重命名为 {new_name}")
# 清理临时文件
def clean_temp_files(directory, extensions=[".tmp", ".bak"]):
count = 0
for ext in extensions:
for file in glob.glob(os.path.join(directory, f"*{ext}")):
os.remove(file)
count += 1
print(f"删除文件: {file}")
print(f"共删除 {count} 个临时文件")
# 使用示例
if __name__ == "__main__":
create_directory("backup")
copy_files("source", "backup", "*.txt")
batch_rename("backup", "old_", "new_")
clean_temp_files("temp")
系统信息收集
import platform
import psutil
import socket
import datetime
def get_system_info():
info = {}
# 系统信息
info["系统"] = platform.system()
info["系统版本"] = platform.version()
info["架构"] = platform.architecture()
info["处理器"] = platform.processor()
# 内存信息
mem = psutil.virtual_memory()
info["总内存"] = f"{mem.total / (1024**3):.2f} GB"
info["可用内存"] = f"{mem.available / (1024**3):.2f} GB"
info["内存使用率"] = f"{mem.percent}%"
# 磁盘信息
disk = psutil.disk_usage('/')
info["总磁盘空间"] = f"{disk.total / (1024**3):.2f} GB"
info["可用磁盘空间"] = f"{disk.free / (1024**3):.2f} GB"
info["磁盘使用率"] = f"{disk.percent}%"
# 网络信息
info["主机名"] = socket.gethostname()
info["IP地址"] = socket.gethostbyname(socket.gethostname())
# 运行时间
boot_time = datetime.datetime.fromtimestamp(psutil.boot_time())
uptime = datetime.datetime.now() - boot_time
info["系统启动时间"] = boot_time.strftime("%Y-%m-%d %H:%M:%S")
info["运行时间"] = str(uptime).split('.')[0] # 去除微秒
return info
def print_system_info():
info = get_system_info()
print("系统信息报告")
print("=" * 50)
for key, value in info.items():
print(f"{key}: {value}")
print("=" * 50)
if __name__ == "__main__":
print_system_info()
批量服务器管理
import paramiko
import concurrent.futures
import getpass
def execute_command(server, username, password, command):
"""在远程服务器上执行命令"""
client = paramiko.SSHClient()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
try:
client.connect(server, username=username, password=password)
print(f"连接到 {server} 成功")
stdin, stdout, stderr = client.exec_command(command)
output = stdout.read().decode()
error = stderr.read().decode()
if output:
print(f"[{server}] 输出:\n{output}")
if error:
print(f"[{server}] 错误:\n{error}")
return True
except Exception as e:
print(f"[{server}] 错误: {str(e)}")
return False
finally:
client.close()
def batch_execute(servers, username, password, command):
"""在多个服务器上并行执行命令"""
print(f"在 {len(servers)} 台服务器上执行命令: {command}")
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = {
executor.submit(execute_command, server, username, password, command): server
for server in servers
}
success = 0
for future in concurrent.futures.as_completed(futures):
server = futures[future]
if future.result():
success += 1
print(f"命令执行完成: {success}/{len(servers)} 台服务器成功")
if __name__ == "__main__":
servers = ["server1.example.com", "server2.example.com", "server3.example.com"]
username = input("用户名: ")
password = getpass.getpass("密码: ")
command = input("要执行的命令: ")
batch_execute(servers, username, password, command)
04 基础设施即代码(IaC)
基础设施即代码是一种使用代码来管理和配置基础设施的方法,它使基础设施的部署和管理变得可重复、可靠和可版本控制。
使用Python和Fabric自动化部署
Fabric是一个Python库,用于通过SSH执行本地或远程shell命令。
from fabric import Connection, task
@task
def deploy(c, branch="main"):
"""部署Web应用"""
print(f"开始部署分支: {branch}")
# 连接到服务器
with Connection('user@server.example.com') as c:
# 进入项目目录
with c.cd('/var/www/myapp'):
# 拉取最新代码
c.run(f"git pull origin {branch}")
# 安装依赖
c.run("pip install -r requirements.txt")
# 执行数据库迁移
c.run("python manage.py migrate")
# 收集静态文件
c.run("python manage.py collectstatic --noinput")
# 重启应用服务器
c.run("sudo systemctl restart gunicorn")
# 检查应用状态
c.run("sudo systemctl status gunicorn")
print("部署完成!")
@task
def rollback(c, commit_hash):
"""回滚到指定版本"""
print(f"开始回滚到版本: {commit_hash}")
with Connection('user@server.example.com') as c:
with c.cd('/var/www/myapp'):
# 回滚到指定版本
c.run(f"git reset --hard {commit_hash}")
# 安装依赖
c.run("pip install -r requirements.txt")
# 执行数据库迁移
c.run("python manage.py migrate")
# 收集静态文件
c.run("python manage.py collectstatic --noinput")
# 重启应用服务器
c.run("sudo systemctl restart gunicorn")
print("回滚完成!")
使用方法:
# 部署主分支
fab deploy
# 部署特定分支
fab deploy --branch=develop
# 回滚到特定版本
fab rollback --commit-hash=abc123
05 容器化与Docker
容器化是一种轻量级的虚拟化技术,它将应用程序及其依赖打包成一个独立的单元。Docker是最流行的容器化平台之一。
使用Python操作Docker
Python可以通过docker-py库与Docker API交互,实现容器的自动化管理。
import docker
# 创建Docker客户端
client = docker.from_env()
# 列出所有容器
def list_containers():
containers = client.containers.list(all=True)
print(f"共有 {len(containers)} 个容器:")
for container in containers:
status = "运行中"if container.status == "running"else container.status
print(f"ID: {container.short_id}, 名称: {container.name}, 状态: {status}")
# 启动容器
def start_container(container_id):
try:
container = client.containers.get(container_id)
container.start()
print(f"容器 {container.name} 已启动")
except docker.errors.NotFound:
print(f"容器 {container_id} 不存在")
except Exception as e:
print(f"启动容器时出错: {str(e)}")
# 停止容器
def stop_container(container_id):
try:
container = client.containers.get(container_id)
container.stop()
print(f"容器 {container.name} 已停止")
except docker.errors.NotFound:
print(f"容器 {container_id} 不存在")
except Exception as e:
print(f"停止容器时出错: {str(e)}")
# 创建并运行新容器
def run_container(image, name=None, ports=None, volumes=None, environment=None):
try:
container = client.containers.run(
image,
name=name,
ports=ports,
volumes=volumes,
environment=environment,
detach=True
)
print(f"容器 {container.name} 已创建并运行")
return container
except Exception as e:
print(f"创建容器时出错: {str(e)}")
return None
# 使用示例
if __name__ == "__main__":
# 列出所有容器
list_containers()
# 运行Nginx容器
nginx = run_container(
"nginx:latest",
name="my-nginx",
ports={"80/tcp": 8080},
volumes={"/local/path": {"bind": "/usr/share/nginx/html", "mode": "ro"}}
)
# 运行Redis容器
redis = run_container(
"redis:latest",
name="my-redis",
ports={"6379/tcp": 6379}
)
# 再次列出所有容器
list_containers()
# 停止容器
if nginx:
stop_container(nginx.id)
使用Docker Compose
Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。Python可以生成和管理Docker Compose配置文件。
import yaml
import subprocess
import os
def generate_compose_file(services, output_file="docker-compose.yml"):
"""生成Docker Compose配置文件"""
compose_config = {
"version": "3",
"services": services
}
with open(output_file, "w") as f:
yaml.dump(compose_config, f, default_flow_style=False)
print(f"Docker Compose配置已保存到 {output_file}")
def run_compose_command(command, compose_file="docker-compose.yml"):
"""运行Docker Compose命令"""
cmd = ["docker-compose", "-f", compose_file, command]
print(f"执行命令: {' '.join(cmd)}")
try:
result = subprocess.run(cmd, check=True, text=True, capture_output=True)
print(result.stdout)
return True
except subprocess.CalledProcessError as e:
print(f"命令执行失败: {e}")
print(e.stderr)
return False
# 使用示例
if __name__ == "__main__":
# 定义服务
services = {
"web": {
"image": "nginx:latest",
"ports": ["8080:80"],
"volumes": ["./html:/usr/share/nginx/html:ro"],
"depends_on": ["app"]
},
"app": {
"build": "./app",
"environment": ["DEBUG=True", "DB_HOST=db"],
"depends_on": ["db"]
},
"db": {
"image": "postgres:13",
"volumes": ["postgres_data:/var/lib/postgresql/data"],
"environment": [
"POSTGRES_PASSWORD=example",
"POSTGRES_DB=myapp"
]
}
}
# 生成Docker Compose文件
generate_compose_file(services)
# 创建html目录和示例文件
os.makedirs("html", exist_ok=True)
with open("html/index.html", "w") as f:
f.write("<h1>Hello from Docker Compose!</h1>")
# 启动服务
run_compose_command("up -d")
# 查看服务状态
run_compose_command("ps")
# 停止服务
run_compose_command("down")
06 持续集成/持续交付(CI/CD)
CI/CD是一种自动化软件交付的方法,它包括持续集成(CI)、持续交付(CD)和持续部署。
使用Python构建简单的CI/CD流水线
import os
import subprocess
import datetime
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
class CIPipeline:
def __init__(self, repo_url, branch="main", work_dir="./workspace"):
self.repo_url = repo_url
self.branch = branch
self.work_dir = work_dir
self.start_time = None
self.end_time = None
self.status = "未开始"
self.log = []
def log_step(self, step, message):
"""记录步骤日志"""
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log_entry = f"[{timestamp}] [{step}] {message}"
print(log_entry)
self.log.append(log_entry)
def run_command(self, command, step_name):
"""运行命令并记录日志"""
self.log_step(step_name, f"执行命令: {command}")
try:
result = subprocess.run(
command,
shell=True,
check=True,
text=True,
capture_output=True
)
self.log_step(step_name, "命令执行成功")
if result.stdout:
self.log_step(step_name, f"输出:\n{result.stdout}")
return True
except subprocess.CalledProcessError as e:
self.log_step(step_name, f"命令执行失败: {e}")
if e.stdout:
self.log_step(step_name, f"标准输出:\n{e.stdout}")
if e.stderr:
self.log_step(step_name, f"错误输出:\n{e.stderr}")
return False
def checkout(self):
"""检出代码"""
if not os.path.exists(self.work_dir):
os.makedirs(self.work_dir)
self.log_step("检出", f"创建工作目录: {self.work_dir}")
# 克隆仓库
cmd = f"git clone {self.repo_url} {self.work_dir}"
if not self.run_command(cmd, "检出"):
return False
# 切换到工作目录
os.chdir(self.work_dir)
# 拉取最新代码
cmd = "git fetch --all"
if not self.run_command(cmd, "检出"):
return False
# 切换到指定分支
cmd = f"git checkout {self.branch}"
if not self.run_command(cmd, "检出"):
return False
# 拉取最新变更
cmd = f"git pull origin {self.branch}"
if not self.run_command(cmd, "检出"):
return False
return True
def install_dependencies(self):
"""安装依赖"""
# 检查是否有requirements.txt文件
if os.path.exists("requirements.txt"):
cmd = "pip install -r requirements.txt"
return self.run_command(cmd, "依赖安装")
else:
self.log_step("依赖安装", "未找到requirements.txt文件,跳过依赖安装")
return True
def run_tests(self):
"""运行测试"""
# 检查是否有测试目录
if os.path.exists("tests") or os.path.exists("test"):
cmd = "pytest"
return self.run_command(cmd, "测试")
else:
self.log_step("测试", "未找到测试目录,跳过测试")
return True
def build(self):
"""构建项目"""
# 检查是否有setup.py文件
if os.path.exists("setup.py"):
cmd = "python setup.py build"
return self.run_command(cmd, "构建")
else:
self.log_step("构建", "未找到setup.py文件,跳过构建")
return True
def deploy(self, deploy_script=None):
"""部署项目"""
if deploy_script:
cmd = f"python {deploy_script}"
return self.run_command(cmd, "部署")
else:
self.log_step("部署", "未提供部署脚本,跳过部署")
return True
def send_notification(self, recipients, smtp_server, smtp_port, sender, password):
"""发送通知邮件"""
subject = f"构建通知: {os.path.basename(self.repo_url)} - {self.status}"
# 创建邮件内容
body = f"""
<h2>构建信息</h2>
<p><strong>仓库:</strong> {self.repo_url}</p>
<p><strong>分支:</strong> {self.branch}</p>
<p><strong>状态:</strong> {self.status}</p>
<p><strong>开始时间:</strong> {self.start_time}</p>
<p><strong>结束时间:</strong> {self.end_time}</p>
<p><strong>耗时:</strong> {self.end_time - self.start_time}</p>
<h2>构建日志</h2>
<pre>
{"<br>".join(self.log)}
</pre>
"""
# 创建邮件
msg = MIMEMultipart()
msg['From'] = sender
msg['To'] = ", ".join(recipients)
msg['Subject'] = subject
msg.attach(MIMEText(body, 'html'))
try:
# 发送邮件
server = smtplib.SMTP(smtp_server, smtp_port)
server.starttls()
server.login(sender, password)
server.send_message(msg)
server.quit()
self.log_step("通知", f"已发送通知邮件到 {', '.join(recipients)}")
return True
except Exception as e:
self.log_step("通知", f"发送邮件失败: {str(e)}")
return False
def run_pipeline(self, deploy_script=None):
"""运行完整的CI/CD流水线"""
self.start_time = datetime.datetime.now()
self.log_step("开始", f"开始构建 {self.repo_url} 的 {self.branch} 分支")
try:
# 检出代码
if not self.checkout():
self.status = "检出失败"
return False
# 安装依赖
if not self.install_dependencies():
self.status = "依赖安装失败"
return False
# 运行测试
if not self.run_tests():
self.status = "测试失败"
return False
# 构建项目
if not self.build():
self.status = "构建失败"
return False
# 部署项目
if not self.deploy(deploy_script):
self.status = "部署失败"
return False
self.status = "成功"
return True
except Exception as e:
self.log_step("错误", f"流水线执行出错: {str(e)}")
self.status = "执行出错"
return False
finally:
self.end_time = datetime.datetime.now()
self.log_step("结束", f"构建结束,状态: {self.status},耗时: {self.end_time - self.start_time}")
# 使用示例
if __name__ == "__main__":
# 创建CI流水线
pipeline = CIPipeline(
repo_url="https://github.com/username/repo.git",
branch="main",
work_dir="./my_project"
)
# 运行流水线
pipeline.run_pipeline(deploy_script="deploy.py")
# 发送通知
if pipeline.status != "成功":
pipeline.send_notification(
recipients=["admin@example.com"],
smtp_server="smtp.example.com",
smtp_port=587,
sender="ci@example.com",
password="password"
)
07 监控与日志
监控和日志收集是DevOps的重要组成部分,它们帮助我们了解系统的运行状况和问题。
使用Python进行系统监控
import psutil
import time
import json
import os
from datetime import datetime
class SystemMonitor:
def __init__(self, output_dir="./logs", interval=5):
self.output_dir = output_dir
self.interval = interval
# 创建输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
def collect_metrics(self):
"""收集系统指标"""
metrics = {
"timestamp": datetime.now().isoformat(),
"cpu": {
"usage_percent": psutil.cpu_percent(interval=1),
"count": psutil.cpu_count(),
"load_avg": psutil.getloadavg()
},
"memory": {
"total": psutil.virtual_memory().total,
"available": psutil.virtual_memory().available,
"used": psutil.virtual_memory().used,
"percent": psutil.virtual_memory().percent
},
"disk": {
"total": psutil.disk_usage('/').total,
"used": psutil.disk_usage('/').used,
"free": psutil.disk_usage('/').free,
"percent": psutil.disk_usage('/').percent
},
"network": {
"bytes_sent": psutil.net_io_counters().bytes_sent,
"bytes_recv": psutil.net_io_counters().bytes_recv
},
"processes": {
"count": len(psutil.pids())
}
}
return metrics
def save_metrics(self, metrics):
"""保存指标到文件"""
date_str = datetime.now().strftime("%Y-%m-%d")
file_path = os.path.join(self.output_dir, f"metrics_{date_str}.json")
# 检查文件是否存在
if os.path.exists(file_path):
# 读取现有数据
with open(file_path, 'r') as f:
try:
data = json.load(f)
except json.JSONDecodeError:
data = []
else:
data = []
# 添加新指标
data.append(metrics)
# 保存数据
with open(file_path, 'w') as f:
json.dump(data, f, indent=2)
def print_metrics(self, metrics):
"""打印指标"""
print(f"\n系统监控 - {metrics['timestamp']}")
print("-" * 50)
print(f"CPU使用率: {metrics['cpu']['usage_percent']}%")
print(f"内存使用率: {metrics['memory']['percent']}%")
print(f"磁盘使用率: {metrics['disk']['percent']}%")
print(f"网络发送: {metrics['network']['bytes_sent'] / (1024*1024):.2f} MB")
print(f"网络接收: {metrics['network']['bytes_recv'] / (1024*1024):.2f} MB")
print(f"进程数: {metrics['processes']['count']}")
print("-" * 50)
def check_alerts(self, metrics):
"""检查是否需要发出警报"""
alerts = []
# CPU使用率超过80%
if metrics['cpu']['usage_percent'] > 80:
alerts.append(f"警告: CPU使用率过高 ({metrics['cpu']['usage_percent']}%)")
# 内存使用率超过90%
if metrics['memory']['percent'] > 90:
alerts.append(f"警告: 内存使用率过高 ({metrics['memory']['percent']}%)")
# 磁盘使用率超过85%
if metrics['disk']['percent'] > 85:
alerts.append(f"警告: 磁盘使用率过高 ({metrics['disk']['percent']}%)")
return alerts
def start_monitoring(self, duration=None):
"""开始监控"""
print(f"开始系统监控,间隔 {self.interval} 秒")
count = 0
try:
while True:
# 收集指标
metrics = self.collect_metrics()
# 保存指标
self.save_metrics(metrics)
# 打印指标
self.print_metrics(metrics)
# 检查警报
alerts = self.check_alerts(metrics)
for alert in alerts:
print(f"\033[91m{alert}\033[0m") # 红色输出警报
# 检查是否达到指定的监控时长
count += 1
if duration and count >= duration / self.interval:
break
# 等待下一次收集
time.sleep(self.interval)
except KeyboardInterrupt:
print("\n监控已停止")
# 使用示例
if __name__ == "__main__":
monitor = SystemMonitor(interval=10)
monitor.start_monitoring()
08 实战案例:自动化部署Web应用
让我们创建一个自动化部署Web应用的脚本,它将执行以下步骤:
-
从Git仓库拉取最新代码
-
构建Docker镜像
-
使用Docker Compose部署应用
-
监控应用状态
import os
import subprocess
import time
import requests
import yaml
import logging
from datetime import datetime
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("deployment.log"),
logging.StreamHandler()
]
)
class WebAppDeployer:
def __init__(self, repo_url, branch="main", work_dir="./webapp"):
self.repo_url = repo_url
self.branch = branch
self.work_dir = work_dir
self.start_time = None
self.end_time = None
def run_command(self, command):
"""运行命令并返回结果"""
logging.info(f"执行命令: {command}")
try:
result = subprocess.run(
command,
shell=True,
check=True,
text=True,
capture_output=True
)
if result.stdout:
logging.info(f"命令输出:\n{result.stdout}")
return True, result.stdout
except subprocess.CalledProcessError as e:
logging.error(f"命令执行失败: {e}")
if e.stdout:
logging.info(f"标准输出:\n{e.stdout}")
if e.stderr:
logging.error(f"错误输出:\n{e.stderr}")
return False, e.stderr
def checkout_code(self):
"""检出代码"""
logging.info(f"开始检出代码: {self.repo_url} 分支: {self.branch}")
if not os.path.exists(self.work_dir):
os.makedirs(self.work_dir)
logging.info(f"创建工作目录: {self.work_dir}")
# 克隆仓库
success, _ = self.run_command(f"git clone {self.repo_url} {self.work_dir}")
if not success:
return False
# 切换到工作目录
os.chdir(self.work_dir)
# 拉取最新代码
success, _ = self.run_command("git fetch --all")
if not success:
return False
# 切换到指定分支
success, _ = self.run_command(f"git checkout {self.branch}")
if not success:
return False
# 拉取最新变更
success, _ = self.run_command(f"git pull origin {self.branch}")
if not success:
return False
logging.info("代码检出成功")
return True
def build_docker_image(self, image_name, dockerfile="Dockerfile"):
"""构建Docker镜像"""
logging.info(f"开始构建Docker镜像: {image_name}")
if not os.path.exists(dockerfile):
logging.error(f"Dockerfile不存在: {dockerfile}")
return False
# 构建镜像
success, _ = self.run_command(f"docker build -t {image_name} -f {dockerfile} .")
if not success:
return False
logging.info(f"Docker镜像构建成功: {image_name}")
return True
def generate_compose_file(self, services, output_file="docker-compose.yml"):
"""生成Docker Compose配置文件"""
logging.info("生成Docker Compose配置文件")
compose_config = {
"version": "3",
"services": services
}
with open(output_file, "w") as f:
yaml.dump(compose_config, f, default_flow_style=False)
logging.info(f"Docker Compose配置已保存到 {output_file}")
return True
def deploy_with_compose(self, compose_file="docker-compose.yml"):
"""使用Docker Compose部署应用"""
logging.info("开始使用Docker Compose部署应用")
if not os.path.exists(compose_file):
logging.error(f"Docker Compose配置文件不存在: {compose_file}")
return False
# 停止并删除现有容器
self.run_command(f"docker-compose -f {compose_file} down")
# 启动新容器
success, _ = self.run_command(f"docker-compose -f {compose_file} up -d")
if not success:
return False
logging.info("应用部署成功")
return True
def check_application_health(self, url, max_retries=10, retry_interval=5):
"""检查应用健康状态"""
logging.info(f"开始检查应用健康状态: {url}")
for i in range(max_retries):
try:
logging.info(f"健康检查尝试 {i+1}/{max_retries}")
response = requests.get(url, timeout=10)
if response.status_code == 200:
logging.info(f"应用健康检查成功: {response.status_code}")
return True
else:
logging.warning(f"应用返回非200状态码: {response.status_code}")
except requests.RequestException as e:
logging.warning(f"健康检查请求失败: {str(e)}")
time.sleep(retry_interval)
logging.error(f"应用健康检查失败,达到最大重试次数: {max_retries}")
return False
def deploy(self, image_name, app_url, app_port=8000, db_port=5432):
"""执行完整的部署流程"""
self.start_time = datetime.now()
logging.info(f"开始部署流程: {self.start_time}")
try:
# 检出代码
if not self.checkout_code():
return False
# 构建Docker镜像
if not self.build_docker_image(image_name):
return False
# 定义服务
services = {
"web": {
"image": image_name,
"ports": [f"{app_port}:8000"],
"environment": ["DEBUG=False", "DB_HOST=db"],
"depends_on": ["db"]
},
"db": {
"image": "postgres:13",
"volumes": ["postgres_data:/var/lib/postgresql/data"],
"ports": [f"{db_port}:5432"],
"environment": [
"POSTGRES_PASSWORD=example",
"POSTGRES_DB=webapp"
]
}
}
# 生成Docker Compose文件
if not self.generate_compose_file(services):
return False
# 部署应用
if not self.deploy_with_compose():
return False
# 检查应用健康状态
if not self.check_application_health(app_url):
logging.warning("应用健康检查失败,但部署过程已完成")
return True
except Exception as e:
logging.error(f"部署过程出错: {str(e)}")
return False
finally:
self.end_time = datetime.now()
duration = self.end_time - self.start_time
logging.info(f"部署流程结束: {self.end_time}, 耗时: {duration}")
# 使用示例
if __name__ == "__main__":
deployer = WebAppDeployer(
repo_url="https://github.com/username/webapp.git",
branch="main",
work_dir="./my_webapp"
)
success = deployer.deploy(
image_name="my-webapp:latest",
app_url="http://localhost:8000/health",
app_port=8000,
db_port=5432
)
if success:
print("部署成功!")
else:
print("部署失败,请查看日志了解详情。")
结语
在本文中,我们学习了Python在DevOps与自动化运维中的应用:
-
容器化与Docker:使用Python操作Docker和Docker Compose
-
持续集成/持续交付(CI/CD):使用Python构建简单的CI/CD流水线
-
监控与日志:使用Python进行系统监控
-
实战案例:自动化部署Web应用
Python在DevOps领域有着广泛的应用,它可以帮助我们自动化部署和管理应用程序,提高开发和运维的效率。在下一篇文章中,我们将学习Python与大数据,包括Hadoop生态系统、Spark与PySpark等内容。
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
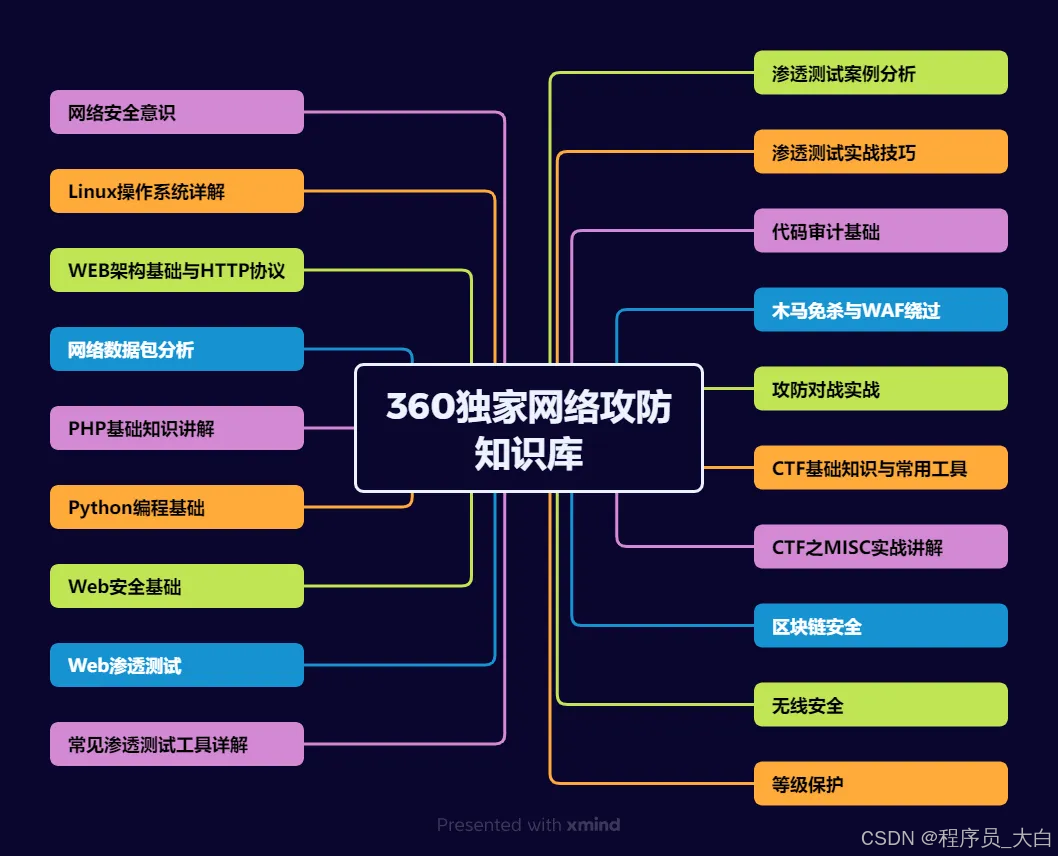
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧
7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)