Dify条件分支节点全解析|10大典型应用场景配置方案详解|
本文将展开介绍Dify平台的条件分支节点,包括:核心功能与作用;关键配置项详解;10种条件分支节点的典型应用场景:金融风控、医疗健康助手、电商智能客服、内容审核平台、智能硬件IOT平台、智能招聘、K12教育、供应链管理、AIGC内容创作平台、智慧农业。
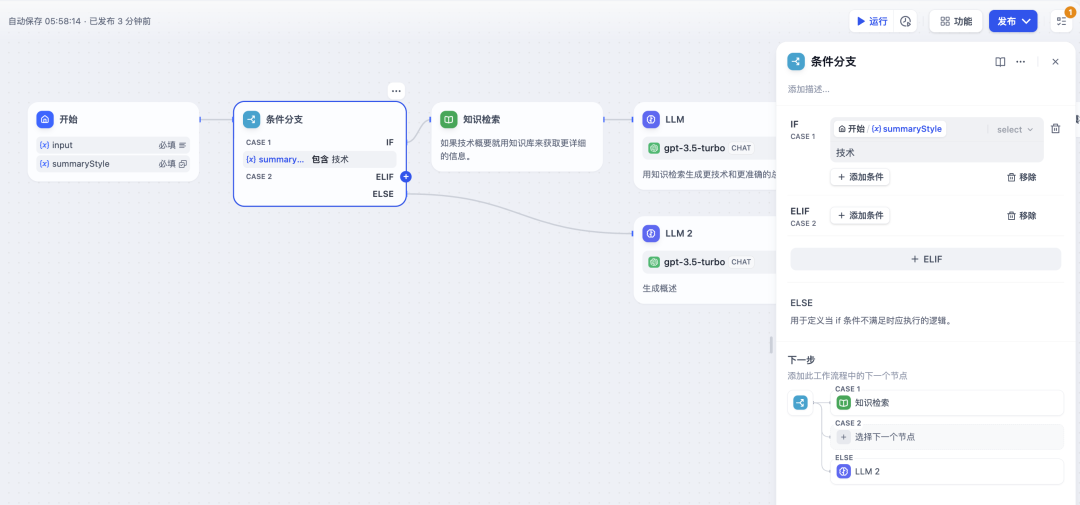
Dify的条件分支节点就像一个智能路由器或决策点。它基于自定义的规则(条件表达式),评估工作流中传递过来的数据(变量)。根据评估结果是 True (真) 还是 False (假),决定工作流接下来执行哪个分支。
本文将展开介绍Dify平台的条件分支节点,包括:核心功能与作用;关键配置项详解;10种条件分支节点的典型应用场景:金融风控、医疗健康助手、电商智能客服、内容审核平台、智能硬件IOT平台、智能招聘、K12教育、供应链管理、AIGC内容创作平台、智慧农业。
一、 核心功能与作用
-
动态分支:
这是最主要的功能。它允许工作流根据输入数据、模型输出、API 响应或其他节点的结果,选择不同的后续处理路径。
-
个性化响应:
实现针对不同用户、不同输入或不同情境提供定制化的处理逻辑和输出。
-
流程控制:
简化复杂逻辑,避免将所有规则硬编码到单个提示词或代码中,提高可维护性和可视性。
-
错误处理/兜底逻辑:
判断某个操作(如 API 调用)是否成功,失败时执行备用方案。
-
数据过滤/路由:
根据数据内容将其发送到不同的处理模块(如不同的模型、不同的数据库查询)。
二、 配置详解
Dify的可视化工作流中,条件分支节点会涉及条件表达式设置、输出分支链接2项关键配置内容:
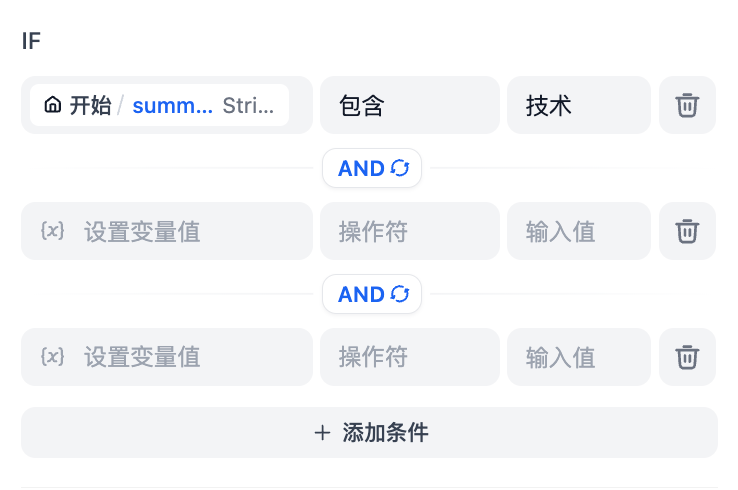
设置条件表达式:
变量注入:使用{{ }} 语法引用工作流中上游节点输出的变量。例如:
-
{{input}}(引用用户原始输入)
-
{{model_output}}(引用前面某个 LLM 节点的输出结果)
-
{{api_response.status}}(引用某个 API 调用节点返回数据中的
status字段) -
{{extracted_data.category}}(引用某个数据处理节点提取的
category字段)
运算符:作用于诸如变量上的具体逻辑。包括:
-
比较运算符:
==(等于),
!=(不等于),>(大于),<(小于),>=(大于等于),<=(小于等于) -
逻辑运算符:
AND(逻辑与 - 所有条件都需满足),
OR(逻辑或 - 任一条件满足即可),NOT(逻辑非 - 取反) -
字符串运算符:
contains(包含),
startsWith(以…开头),endsWith(以…结尾) (注意:这些可能需要特定语法或函数,Dify 界面通常有提示或选择器) -
存在性检查:
is defined,
is not defined,is empty,is not empty(检查变量是否存在或为空)
值:与引用的变量进行比较的具体值(字符串、数字、布尔值true/false)。字符串通常需要用引号括起来。
-
{{user_query}} contains "价格"(用户查询包含“价格”)
-
{{sentiment_analysis.result}} == "negative"(情感分析结果是“负面”)
-
{{order_amount}} > 1000(订单金额大于 1000)
-
{{user_input}} is not empty AND {{user_input}} != "你好"(用户输入非空且不等于“你好”)
-
{{api_response.status_code}} == 200(API 调用返回状态码为 200 成功)
-
{{user_info.vip_level}} >= 3(用户 VIP 等级大于等于 3)
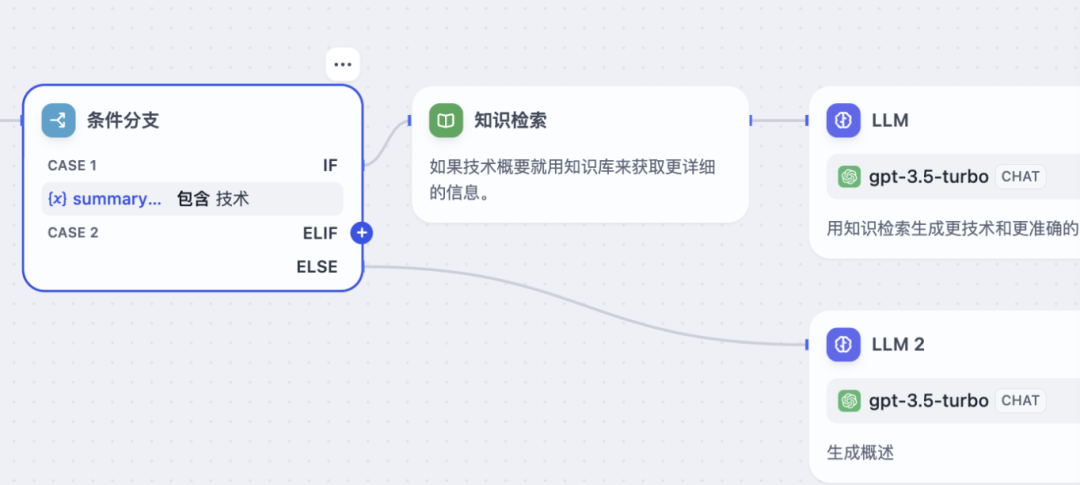
配置输出分支:
-
True分支:当条件表达式评估结果为
True时,工作流将沿着此分支继续执行。你需要将后续的节点(如另一个 LLM 调用、API 调用、发送消息、结束节点等)连接到这个分支上。 -
False分支:当条件表达式评估结果为
False时,工作流将沿着此分支继续执行。同样,连接后续节点到此分支。 -
Default分支 (可选,取决于版本和配置):一些高级配置或特定节点类型可能支持一个默认分支,用于处理所有未匹配到特定
True条件的情况(类似于编程中的else或default)。但在基本的二元判断中,False分支通常就充当了默认分支的角色。 -
多分支判断 (常见于企业版或高级功能):
更复杂的条件节点可能支持配置多个条件分支(类似于
if-else if-else或switch-case)。你需要为每个分支定义独立的表达式,并连接对应的后续节点。节点会按顺序评估这些条件,执行第一个匹配 (True) 的分支。
三、10大典型应用场景
场景一:金融风控 - 贷款申请自动化审批 (多层嵌套条件)
-
业务痛点:
手动审批贷款效率低、标准不统一、难以实时响应。
-
工作流目标:
基于用户提交数据(收入、负债、信用分、职业等)和外部数据(征信报告 API 结果),自动化做出初步审批决策(通过、拒绝、转人工审核)。
-
工作流设计及条件判断应用:
-
输入节点:
接收用户贷款申请表单数据 (
application_data)。 -
API 调用节点:
调用外部征信系统 API (
credit_report = get_credit_report(application_data.id_number))。 -
条件判断节点 1 (核心风控):
- 表达式:
{{credit_report.
score
}} >=
700
AND
{{application_data.
monthly_income
}} / {{application_data.
monthly_debt
}} >=
3
AND
{{application_data.
job_stability
}} >
2
// 例如 1=不稳定, 5=非常稳定
-
True分支:连接到 “条件判断节点 2” (进一步细化)。
-
False分支:连接到 “拒绝申请”节点 (发送标准化拒绝通知)。
- d. 条件判断节点 2 (金额分级):
- 表达式:
{{application_data.loan_amount}} <= 50000
-
True分支:连接到 “自动批准”节点 (生成合同、发送通知)。
-
False分支:连接到 “转人工审核”节点 (将申请信息和风控评分推送给人工审核员系统)。
-
e. 条件判断节点 3 (处理征信报告异常 - 可选):
在调用征信 API 后立即判断:
- 表达式:
{{credit_report.status}} !=
"success"
OR {{credit_report.error_code}}
is
defined
-
True分支:连接到 “请求用户补充信息”节点 或 “转人工审核(注明征信获取失败)”节点。
-
False分支:正常进入 “条件判断节点 1”。
*** 条件分支的价值:**
-
高效筛选:
快速拒绝明显不符合硬性标准的申请。
-
风险分层:
对符合基本标准的申请进行金额分级,小金额自动化,大金额人工介入。
-
异常处理:
确保外部服务故障不影响核心流程,优雅降级。
-
合规透明:
决策逻辑清晰可见(通过条件表达式),便于审计和解释。
场景二:医疗健康助手 - 智能症状分诊与导流 (多条件分支)
-
业务痛点:
患者在线咨询时难以准确判断自身病情严重程度和应就诊的科室;避免轻症占用急诊资源,重症得到及时响应。
-
工作流目标:
基于患者描述的症状、持续时间、严重程度、基础疾病等信息,给出初步的风险评估(低/中/高)和就诊建议(自我观察、预约门诊、立即急诊、推荐特定科室)。
-
工作流设计及条件判断应用:
-
输入节点:
患者填写结构化症状问卷 (
symptom_data- 包含症状列表、持续时间、疼痛等级、是否有发烧/呼吸困难/胸痛等关键症状、基础病史)。 -
LLM 节点 (可选 - 信息标准化):
将患者可能的自由文本补充描述标准化为结构化标签 (
standardized_symptoms = extract_and_standardize({{input.additional_notes}})),合并到symptom_data。 -
条件判断节点 (风险评级引擎):**这是核心,通常需要配置多个条件分支(类似
switch-case):**
- 分支 1 (高风险 - 需立即急诊):
- 条件:
{{symptom_data.
symptoms
}} contains
"严重胸痛"
OR
{{symptom_data.
symptoms
}} contains
"呼吸困难"
OR
{{symptom_data.
symptoms
}} contains
"意识模糊"
OR
{{symptom_data.
bleeding
}} ==
"uncontrolled"
// 无法控制的出血
-
动作:
连接到 “发送紧急警报”节点 (提示立即拨打急救电话或前往最近急诊) + “记录高风险事件”节点。
- 分支 2 (中风险 - 建议尽快门诊):
- 条件:
({{symptom_data.
fever
}} >
39
OR
{{symptom_data.
duration
}} >
7
)
AND
{{symptom_data.
has_chronic_disease
}} ==
true
// 例如有糖尿病、心脏病史
-
动作:
连接到 “推荐科室 & 预约建议”节点 (根据其他症状如
symptom_data.symptoms判断推荐内科/外科等) + “生成护理建议”节点 (如多休息、多喝水)。
- 分支 3 (低风险 - 自我观察或线上问诊):
- 条件:
{{symptom_data.pain_level}} <=
3
AND
{{symptom_data.duration}} <
3
AND
NOT
({{symptom_data.symptoms}} contains any [
"高烧"
,
"呕吐不止"
,
"严重外伤"
])
-
动作:
连接到 “生成家庭护理指南”节点 (LLM 根据症状生成) + “建议观察期”节点 (如症状持续或加重再就医)。
- 默认分支 (无法明确判断):
-
条件:
(上述分支均未匹配)
-
动作:
连接到 “转人工分诊”节点 (将信息推送给在线护士/医生) 或 “建议线下全科门诊”节点。
-
条件判断的价值:
-
生命安全优先:
快速识别并优先处理可能危及生命的紧急症状。
-
资源优化:
合理分流患者,避免急诊拥堵,引导轻症患者使用更合适的资源。
-
个性化建议:
结合基础病史等个体差异提供更精准的建议。
-
标准化流程:
确保分诊逻辑符合医学指南,减少人为判断差异。
场景三:电商智能客服 - 动态优惠券发放与挽单 (状态追踪与条件组合)
-
业务痛点:
购物车弃单率高;用户对价格敏感;希望精准营销提升转化。
-
工作流目标:
实时监控用户行为(浏览商品、加购、离开),在特定时机(如弃单时、浏览高价商品犹豫时)自动触发个性化的优惠券发放策略进行挽单或促购。
-
工作流设计及条件判断应用 (结合事件触发):
-
事件监听节点:
监听用户行为事件流 (
user_event- 包含event_type[“view_item”, “add_to_cart”, “remove_from_cart”, “begin_checkout”, “abandon_cart”],user_id,item_id,item_price,cart_value等)。 -
条件判断节点 1 (识别高价值弃单):
-
触发:
当
event_type == "abandon_cart"。 -
表达式:
{{user_event.
cart_value
}} >
200
AND
// 弃单金额高
{{user_info.
loyalty_level
}} >=
"silver"
AND
// 用户是忠诚会员
{{user_event.
time_since_last_view
}} <
30
// 弃单后短时间内(如30分钟)
-
True分支:连接到 “发放高价值优惠券”节点 (如 8折券或无门槛券)。
-
False分支:进入 “条件判断节点 2”。
- 条件判断节点 2 (识别犹豫高价商品):
-
触发:
当
event_type == "view_item"且item_price > 1000。 -
表达式:
{{user_session.
view_count
}} >
3
AND
// 短时间内多次查看同一商品
{{user_info.
cart_value_history_avg
}} <
500
// 用户历史平均订单金额较低,表明此商品对其较贵
-
True分支:连接到 “发放品类/商品专属券”节点 (如该商品9折券)。
-
False分支:不做动作或进入更通用的营销流程。
- 条件判断节点 3 (避免过度营销):
-
位置:
在决定发放优惠券的任何分支之前。
-
表达式:
{{user_info.
coupons_received_today
}} <
2
AND
// 今日已发券数少于2张
{{user_info.
last_coupon_received_time
}} >
24
// 距离上次发券超过24小时
-
True分支:允许执行后续的发券逻辑。
-
False分支:连接到 “记录但不发券”节点 (避免骚扰用户)。
- 条件判断的价值:
-
提升转化率:
在用户最可能转化的关键时刻(弃单、犹豫)精准介入。
-
个性化营销:
基于用户价值、商品价格、行为模式定制优惠券力度和类型。
-
控制成本:
避免对低价值用户或已享受优惠的用户过度补贴;设置发券频率上限。
-
自动化运营:
7x24 小时自动执行挽单和促购策略,解放人力。
场景四:内容审核平台 - 敏感信息自动拦截 (多级审核流)
-
业务痛点:
UGC (用户生成内容) 海量增长,人工审核成本高、效率低、易漏判。
-
工作流目标:
对用户提交的文本、图片、视频进行多级自动化审核,识别违法违规、低俗、广告、侵权等内容,并采取不同措施(直接拦截、转人工复审、放行)。
-
工作流设计及条件判断应用:
-
输入节点:
接收用户提交内容 (
content- 包含文本、图片/视频 URL、用户 ID)。 -
API 调用节点 1 (文本审核):
调用文本敏感词/语义审核 API (
text_result = moderate_text({{content.text}})- 返回risk_level[“high”, “medium”, “low”],flagged_categories[“violence”, “porn”, “ad”, “political”] 等)。 -
条件判断节点 1 (文本高风险):
- 表达式:
{{text_result.
risk_level
}} ==
"high"
OR
{{text_result.
flagged_categories
}} contains
"terrorism"
-
True分支:连接到 “立即拦截 & 封禁用户”节点 (严重违规零容忍)。
-
False分支:进入 “条件判断节点 2”。
-
API 调用节点 2 (图片/视频审核):
调用视觉内容审核 API (
image_result = moderate_image({{content.image_url}})- 返回类似结构)。 -
条件判断节点 2 (视觉内容风险):
- 表达式:
{{image_result.
risk_level
}} ==
"high"
OR
{{image_result.
risk_level
}} ==
"medium"
-
True分支:连接到 “转人工复审”节点 (机器不确定或有中等风险)。
-
False分支:进入 “条件判断节点 3”。
- 条件判断节点 3 (综合决策 & 低风险):
- 表达式:
({{text_result.risk_level}} ==
"low"
AND {{image_result.risk_level}} ==
"low"
) OR
({{text_result.risk_level}} ==
"medium"
AND {{image_result.risk_level}} ==
"low"
AND
NOT
({{text_result.flagged_categories}} contains
"ad_spam"
)
)
// 中等风险文本但非垃圾广告,且图片安全,可考虑放行
-
True分支:连接到 “自动通过 & 发布”节点。
-
False分支:默认进入 “转人工复审”节点 (兜底逻辑)。
- 条件判断的价值:
-
效率倍增:
自动化处理绝大多数低风险和明确的高风险内容。
-
降低成本:
大幅减少需要人工审核的内容量。
-
分级处理:
对不同风险等级采取不同措施(自动拦截、人工复审、自动放行)。
-
规则明确:
审核规则通过条件表达式固化,确保一致性和可追溯性。
-
快速迭代:
当出现新的违规类型时,可快速在条件判断节点中添加新的规则。
场景五:智能硬件 IoT 平台 - 设备异常告警联动 (实时数据处理)
-
业务痛点:
海量 IoT 设备实时上传数据,需要即时发现异常状态并触发告警或自动修复动作,防止故障扩大。
-
工作流目标:
分析设备传感器数据流,根据预设规则识别异常(如温度过高、压力骤变、离线超时),并动态触发不同级别的告警(通知、派单、紧急停机)。
-
工作流设计及条件判断应用:
-
输入节点 (流式):
持续接收来自 IoT 设备的时序数据 (
sensor_data- 包含device_id,timestamp,temperature,pressure,vibration,status[“online”, “offline”] 等)。 -
数据聚合节点 (可选):
对短时间内同一设备的数据做简单聚合(如计算平均温度、检测状态变化)。
-
条件判断节点 1 (关键状态 - 离线检测):
- 表达式:
{{sensor_data.
status
}} ==
"offline"
AND
{{time_since_last_online}} >
300
// 离线超过5分钟
-
True分支:连接到 “发送设备离线告警”节点 (通知运维人员)。
-
False分支:进入 “条件判断节点 2”。
- 条件判断节点 2 (阈值告警 - 温度过高):
- 表达式:
{{sensor_data.
temperature
}} > {{device_type.
max_safe_temp
}}
// 超过该设备型号的安全温度阈值
-
True分支:连接到 “条件判断节点 2.1” (判断严重程度)。
- 条件判断节点 2.1 (温度过高严重性分级):
- 表达式:
{{sensor_data.
temperature
}} > {{device_type.
critical_temp
}}
// 达到危险临界温度
-
True分支:连接到 “触发紧急停机”节点 (通过控制 API 远程停机) + “发送高危告警”节点 (电话/短信通知)。
-
False分支:连接到 “发送高温预警”节点 (邮件/APP 通知) + “启动风扇指令”节点 (尝试自动降温)。
- 条件判断节点 3 (趋势异常 - 压力骤降):
- 表达式 (需要结合历史数据):
({{current_pressure}} / {{average_pressure_last_5min}}) <
0.7
// 当前压力相比前5分钟均值下降超过30%
-
True分支:连接到 “发送压力异常告警 & 建议检查泄漏”节点。
- 条件判断的价值:
-
实时响应:
毫秒级识别设备异常,避免小问题酿成大事故。
-
精准告警:
根据异常类型和严重程度分级告警,减少误报干扰。
-
自动处置:
对高危情况能自动执行停机等保护操作,为人工介入争取时间。
-
降低运维成本:
自动化监控海量设备,解放人力聚焦复杂问题。
场景六:智能招聘 - 简历自动筛选与分级 (复杂规则引擎)
-
业务痛点:
HR 手动筛选海量简历效率低下、易遗漏优质候选人、筛选标准难以统一。
-
工作流目标:
根据职位要求(JD),自动解析上传的简历,基于硬性条件(学历、经验年限、技能)和软性条件(关键词匹配度、项目经验相关性)对候选人进行分级(A-优先面试、B-可储备、C-不合适),并触发不同后续动作。
-
工作流设计及条件判断应用:
-
输入节点:
接收候选人上传的简历文件 (
resume_file) 和目标职位ID (job_id)。 -
LLM/解析节点:
解析简历内容,结构化输出关键字段 (
candidate_data),包括:
-
education(学历:[“本科”, “硕士”, “博士”…])
-
experience_years(相关工作经验年数)
-
skills(技能列表:[“Python”, “项目管理”, “机器学习”…])
-
projects(项目经验列表,含描述)
-
school_tier(学校等级:[“985”, “211”, “海外名校”, “其他”]) - 可能需额外信息或模型判断
-
API 调用节点:
根据
job_id查询职位要求 (job_requirements)。 -
条件判断节点 1 (硬性门槛过滤 - C级):
- 表达式:
// 不满足硬性最低要求
{{candidate_data.education}} < {{job_requirements.min_education}} OR
// 如要求硕士,本科则小于
{{candidate_data.experience_years}} < {{job_requirements.min_experience}} OR
NOT
({{candidate_data.skills}} contains all {{job_requirements.mandatory_skills}})
// 缺少任一必备技能
-
True分支:连接到 “标记为C级-不合适”节点 (发送礼貌拒信/存入人才库备选) + “结束流程”节点。
-
False分支:进入 “条件判断节点 2” (评估潜力)。
- 条件判断节点 2 (核心能力与潜力评估 - A/B级):
- 表达式:
// A级:远超要求或具备稀缺价值
({{candidate_data.experience_years}} >= {{job_requirements.min_experience}} +
3
)
OR
({{candidate_data.skills}} contains any {{job_requirements.premium_skills}}) OR
// 具备如“大模型优化”等稀缺技能
({{candidate_data.school_tier}} ==
"顶级"
AND {{candidate_data.projects}} contains
"国家级项目"
)
-
True分支:连接到 “标记为A级-优先面试”节点 (自动发送面试邀请、通知HR加急处理)。
-
False分支:进入 “条件判断节点 3” (B级评估)。
- 条件判断节点 3 (良好匹配 - B级):
- 表达式:(默认分支,满足硬性条件但未达A级)
true
// 或更精细的条件,如:{{candidate_data.skills_match_score}} > 70 // 假设有LLM生成的匹配度分数
-
True分支:连接到 “标记为B级-人才储备”节点 (发送感谢信、存入待面试池,按流程排队)。
- 条件判断的价值:
-
效率革命:
秒级完成初筛,释放 HR 生产力聚焦高价值面试。
-
标准统一:
确保所有候选人按同一套客观标准评估,减少偏见。
-
人才分级:
精准识别高潜力 (A级) 和合格 (B级) 候选人,优化招聘漏斗。
-
体验提升:
快速响应候选人(尤其是拒绝的C级),提升雇主品牌。
场景七:教育科技 - 自适应学习路径推荐 (动态学习者画像)
-
业务痛点:
传统在线课程“一刀切”,无法适应不同学习者的知识水平、学习速度和风格偏好,导致学习效果差或动力不足。
-
工作流目标:
基于学习者的测验结果、互动行为(视频观看完成率、答题耗时、错题类型)、自评问卷,动态判断其当前状态(新手/进阶/精通、视觉型/听觉型/实践型、受挫/自信),实时推荐最适合的学习资源(视频、文章、练习题、项目)和路径。
-
工作流设计及条件判断应用:
-
输入节点:
接收学习者事件 (
learning_event),可能来自:
- 测验提交 (
event_type: "quiz_submit",score,time_spent,weak_topics) - 视频观看 (
event_type: "video_progress",completion_rate,playback_speed) - 自评问卷 (
event_type: "self_assessment",confidence_level,preferred_style)
-
状态追踪节点:
维护和更新学习者的动态画像 (
learner_profile):
-
knowledge_level(基于历史测验:[“novice”, “intermediate”, “advanced”])
-
learning_style(基于行为和问卷:[“visual”, “auditory”, “kinesthetic”, “mixed”])
-
engagement_state(基于互动:[“struggling”, “on_track”, “bored”])
- **条件判断节点 (核心 - 资源与路径推荐):**这是一个典型的多分支条件节点 (类似 switch-case),根据
learner_profile组合状态判断
- 分支 1 (新手+视觉型+受挫):
- 条件:
{{learner_profile.
knowledge_level
}} ==
"novice"
AND
{{learner_profile.
learning_style
}} ==
"visual"
AND
{{learner_profile.
engagement_state
}} ==
"struggling"
-
动作:
连接到 “推荐基础图解视频+简单概念题”节点 (降低认知负荷,建立信心)。
- 分支 2 (进阶+实践型+正常):
- 条件:
{{learner_profile.
knowledge_level
}} ==
"intermediate"
AND
{{learner_profile.
learning_style
}} ==
"kinesthetic"
AND
{{learner_profile.
engagement_state
}} ==
"on_track"
-
动作:
连接到 “推荐动手实验/小项目+中等难度挑战题”节点。
- 分支 3 (精通+听觉型+厌倦):
- 条件:
{{learner_profile.
knowledge_level
}} ==
"advanced"
AND
{{learner_profile.
learning_style
}} ==
"auditory"
AND
{{learner_profile.
engagement_state
}} ==
"bored"
-
动作:
连接到 “推荐专家访谈播客+开放式研究问题或教学任务”节点 (提供深度和挑战)。
- 分支 4 (检测知识漏洞 - 独立于风格/状态):
-
条件:
{{learning_event.weak_topics}} is not empty(当有测验事件且识别到弱点主题时)
-
动作:
连接到 “优先推荐针对弱点主题的专项复习材料”节点 (覆盖到所有分支的补救逻辑)。
-
默认分支:
使用平台通用推荐策略。
- 条件判断的价值:
-
真正个性化:
实现“千人千面”的学习体验,最大化学习效果和效率。
-
动态调整:
随学习者进步实时更新推荐,始终保持挑战与能力的平衡区。
-
提升动机:
根据学习状态(受挫/厌倦)调整内容难度和形式,维持学习兴趣。
-
数据驱动教学:
将教学法原则(如因材施教)转化为可执行的自动化规则。
场景八:供应链管理 - 智能库存补货与风险预警 (多因素决策)
-
业务痛点:
库存积压与缺货并存;供应商风险(延迟、断供)难以及时响应;补货决策依赖经验,缺乏数据支撑。
-
工作流目标:
实时监控库存水平 (
inventory_level)、销售预测 (sales_forecast)、在途货物 (in_transit)、供应商状态 (supplier_status),自动计算补货需求,并根据风险等级触发不同的采购策略(常规下单、加急下单、寻找备选供应商)。 -
工作流设计及条件判断应用:
-
数据输入节点:
汇聚实时数据:
- 当前库存 (
sku_inventory) - 未来N天销售预测 (
sales_forecast) - 供应商交货准时率 (
supplier_otd) 和 状态 (supplier_status: [“normal”, “delayed”, “at_risk”]) - 在途货物预计到达时间 (
in_transit_eta)
-
计算节点:
计算关键指标:
-
days_of_supply=
{{sku_inventory}} / {{average_daily_sales}}(库存可售天数) -
coverage_gap=
{{sales_forecast}} - ({{sku_inventory}} + {{in_transit_qty}})(预测需求与总供给的缺口) -
risk_score(基于
supplier_otd,supplier_status, 外部新闻舆情等)
- 条件判断节点 1 (判断补货紧迫性):
- 表达式:
{{days_of_supply}} < {{safety_stock_days}}
OR
// 低于安全库存天数
{{coverage_gap}} > {{critical_gap_threshold}}
// 缺口超过临界阈值
-
True分支:进入 “条件判断节点 2” (评估风险)。
-
False分支:连接到 “无需立即补货,继续监控”节点。
- 条件判断节点 2 (评估供应商风险):
- 表达式:
{{supplier_status}} ==
"at_risk"
OR
{{risk_score}} >
8
// 高风险供应商
-
True分支:连接到 “启动备选供应商采购流程”节点 (询价、加急下单) + “发送高风险告警”节点。
-
False分支:进入 “条件判断节点 3” (常规/加急下单)。
- 条件判断节点 3 (判断订单紧急程度):
- 表达式:
{{days_of_supply}} < {{emergency_stock_days}}
OR
// 库存即将耗尽
{{supplier_status}} ==
"delayed"
// 主供应商已延迟,需加急补货
-
True分支:连接到 “创建加急采购订单”节点 (支付溢价运费/选择更快物流)。
-
False分支:连接到 “创建常规采购订单”节点。
- 条件判断节点 4 (预测性补货 - 可选):
-
触发:
周期性运行或预测到需求激增(如促销、季节性高峰)。
-
表达式:
{{sales_forecast_growth_rate}} >
50
AND
// 预测销量暴涨
{{lead_time}} >
30
// 且供应商交货周期长
-
True分支:连接到 “启动预防性批量补货”节点 (即使当前库存充足)。
- 条件判断的价值:
-
避免缺货损失:
及时识别库存不足并触发补货,保障销售。
-
降低库存成本:
只在必要时按需(甚至按紧急程度)补货,减少资金占用。
-
管理供应链风险:
主动应对供应商问题,快速切换备选方案,增强韧性。
-
自动化决策:
将复杂的补货规则(库存水平+销售预测+供应商状态)系统化、自动化。
场景九:AIGC 内容创作平台 - 版权合规与伦理审查 (多层过滤)
-
业务痛点:
用户利用平台生成的文本、图像、音乐可能涉及侵权、抄袭、伦理问题(暴力、偏见、虚假信息),平台需履行审查责任,规避法律风险。
-
工作流目标:
在用户提交生成请求 (
prompt) 和获取生成结果 (output) 两个关键点设置检查,根据风险等级采取不同措施(拦截请求、过滤输出、添加免责水印、人工复核)。 -
工作流设计及条件判断应用:
-
输入节点 (生成前 - 请求拦截):
接收用户生成请求 (
generation_request:prompt,style_reference,moderation_settings)。 -
条件判断节点 1 (高危Prompt检测):
- 表达式:
{{generation_request.prompt}} contains any [
"名人姓名"
,
"知名品牌LOGO描述"
] OR
// 可能侵犯肖像权/商标权
{{generation_request.prompt}} contains any [
"暴力指令"
,
"仇恨言论"
,
"犯罪方法"
] OR
// 违反内容政策
{{generation_request.style_reference}} is_copyrighted_image
// 检测参考图是否受版权保护
-
True分支:连接到 “立即拒绝请求”节点 (明确告知违规原因) + “记录高风险事件”节点。
-
False分支:进入 “执行生成任务”节点。
-
LLM/AIGC 节点:
生成内容 (
text_output/image_output/audio_output)。 -
API 调用节点 (生成后 - 输出审核):
调用多模态审核 API (
moderation_result = moderate_content({{output}})- 返回侵权风险、伦理风险分数及类别)。 -
条件判断节点 2 (高侵权/高风险输出):
- 表达式:
{{moderation_result.
copyright_risk
}} >
0.9
OR
// 极高版权侵权概率
{{moderation_result.
ethical_risk_category
}} contains [
"child_exploitation"
,
"extreme_violence"
]
// 包含绝对禁止内容
-
True分支:连接到 “完全屏蔽输出”节点 (不返回给用户) + “封禁用户”节点 (严重违规) + “安全团队报警”节点。
-
False分支:进入 “条件判断节点 3” (中等风险处理)。
- 条件判断节点 3 (中等风险/模糊地带):
- 表达式:
{{moderation_result
.copyright_risk
}} >
0.6
OR
{{moderation_result
.ethical_risk_category
}} contains
[
"nudity"
,
"political_sensitivity"
,
"misinformation"
]
-
True分支:连接到 “添加显著免责水印/警告标签”节点 + “转人工复核队列”节点 (输出暂缓发布,等待人工确认)。
-
False分支:进入 “条件判断节点 4” (低风险放行)。
- 条件判断节点 4 (低风险/可信创作):
-
表达式:
{{moderation_result.overall_risk}} < 0.3(或更精细的组合条件)
-
True分支:连接到 “直接返回生成结果给用户”节点。
-
False分支:默认进入 “转人工复核”节点 (兜底)。
- 条件判断的价值:
-
法律风险防控:
在请求和输出双环节拦截高危侵权和违法内容,保护平台。
-
内容安全合规:
自动化执行平台内容政策,营造健康生态。
-
责任分级:
对风险分级处理(完全屏蔽、加水印人工审、直接放行),平衡安全与效率。
-
用户教育:
通过拒绝理由和水印,引导用户合规创作。
场景十:智慧农业 - 精准灌溉与施肥决策 (环境因素融合)
-
业务痛点:
传统农业灌溉施肥粗放,浪费资源(水、肥)、成本高、且可能影响作物品质和环境。
-
工作流目标:
基于实时田间传感器数据(土壤湿度、温度、光照、养分含量)、作物生长阶段模型、天气预报,自动判断是否需要灌溉/施肥,以及精确的计算施用量和时机。
-
工作流设计及条件判断应用:
-
输入节点 (实时监测):
接收传感器网络数据 (
field_data):
-
soil_moisture(土壤湿度)
-
soil_temperature -
soil_npk(氮磷钾含量)
-
air_temp,
humidity,solar_radiation -
crop_growth_stage([“seedling”, “vegetative”, “flowering”, “ripening”])
-
API 调用节点:
获取未来 24-48 小时精准天气预报 (
weather_forecast:precipitation_prob,precipitation_amount,temperature_high/low,sun_hours)。 -
计算节点:
计算作物需水量 (
crop_water_demand- 基于作物类型、生长阶段、气象数据) 和 需肥量 (crop_nutrient_demand)。 -
条件判断节点 1 (灌溉决策):
- 表达式:
{{field_data.
soil_moisture
}} < {{crop_water_demand.
min_threshold
}}
AND
// 土壤太干
{{weather_forecast.
precipitation_prob
}} <
30
AND
// 且未来下雨概率低
NOT
({{weather_forecast.
temperature_high
}} >
35
)
// 避免高温时段灌溉(可选)
-
True分支:进入 “计算灌溉量 & 启动灌溉”节点 (根据
crop_water_demand和field_data计算精确水量)。 -
False分支:不灌溉。
- 条件判断节点 2 (施肥决策):
- 表达式:
{{field_data.
soil_npk
.
n
}} < {{crop_nutrient_demand.
n
}} *
0.8
OR
// 氮含量不足需求80%
{{crop_growth_stage}} ==
"flowering"
// 或在关键需肥阶段(如开花)
-
True分支:进入 “条件判断节点 2.1” (判断施肥类型/方式)。
- 条件判断节点 2.1 (施肥策略):
- 表达式:
{{field_data.
soil_moisture
}} >
60
AND
// 土壤湿度足够适合施肥
{{weather_forecast.
precipitation_prob
}} <
50
// 未来几小时不大雨冲刷
-
True分支:连接到 “启动根部施肥”节点 (计算并执行精确施肥量)。
-
False分支:连接到 “启动叶面喷施”节点 (或延迟到条件满足)。
- 条件判断节点 3 (极端天气预警):
- 表达式:
{{weather_forecast.
temperature_high
}} >
38
OR
{{weather_forecast.
frost_warning
}} ==
true
OR
{{weather_forecast.
hail_prob
}} >
70
-
True分支:连接到 “触发防灾预案”节点 (如启动遮阳网、防霜冻设备、发送告警给农场主)。
- 条件判断的价值:
-
资源高效利用:
只在作物需要且环境允许时精准施用水肥,大幅节约成本。
-
提升产量与品质:
满足作物关键生长阶段需求,优化生长环境。
-
环境保护:
减少化肥农药随水流失造成的土壤和水体污染。
-
防灾减损:
提前预警并自动响应极端天气,保护农作物。
-
自动化管理:
减少农场主日常巡查负担,实现规模化精细种植。
关键总结与设计要点
-
深入理解业务规则:
将复杂的业务逻辑(风控策略、分诊指南、审核规则、设备参数)精确地转化为可执行的布尔表达式是成功的关键。
-
善用数据源:
条件判断依赖高质量的数据输入。确保你能获取到必要的变量(用户输入、模型输出、API 结果、数据库查询结果、设备状态)。
-
拥抱嵌套与分层:
单一条件判断往往不够。利用嵌套条件节点和多分支条件节点构建复杂的决策树。
-
重视异常与兜底:
总是为条件分支设置明确的
False或Default路径,处理意料之外的情况或数据缺失,确保工作流不会卡死。 -
考虑性能与实时性:
对于高频或实时场景(如 IoT),优化条件表达式复杂度,避免不必要的嵌套或计算。
-
持续迭代与监控:
业务规则会变。定期 Review 工作流中的条件判断逻辑,利用 Dify 的调试和日志功能监控其决策是否符合预期。
总结
Dify 工作流中的 条件分支节点 是实现智能应用动态行为的关键。通过灵活配置基于变量的条件表达式,并将其连接到不同的 True/False(或多条件)分支,可以构建出能够适应各种输入和场景的复杂、健壮且个性化的 AI 应用流程。熟练掌握它,可以极大提升开发的 AI Agent 或应用的智能化水平和实用性。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)