ElasticSearch:从零到英雄的 12 个命令
开始使用 ElasticSearch 相对容易。但是随着我们的用例变得更加具体,我们发现缺少文档。这个引导式备忘单将执行 12 个命令:从设置 ES 索引到进行高级 ES 查询以支持高级(但常见)用例。
12 个命令按顺序执行。我将解释它们中的每一个,但自己尝试仍然是最好的。
这篇文章是关于 ElasticSearch 的更广泛系列的一部分,该系列将在未来几周内发布:
-
开始使用 ES 所需的引导式 ElasticSearch 备忘单 - 你在这里
-
使用 DynamoDB + ElasticSearch 处理 prod 工作负载 - 即将推出
-
以及如何创建 DynamoDB Streams 以异步同步从 DynamoDB 到 ES 的数据更改 - 即将推出
0 |先决条件
使用这个官方 ES 指南安装 Elasticsearch。然后,开启 ES 服务器on localhost:9200
为了方便测试,必须安装像Postman这样的 API 平台。
A |设置索引
在 ElasticSearch 中,我们将数据存储在索引中(类似于 MySQL 数据库中的表)。我们用文档填充索引(类似于行)。我们将在后续命令中创建并设置您的第一个索引。
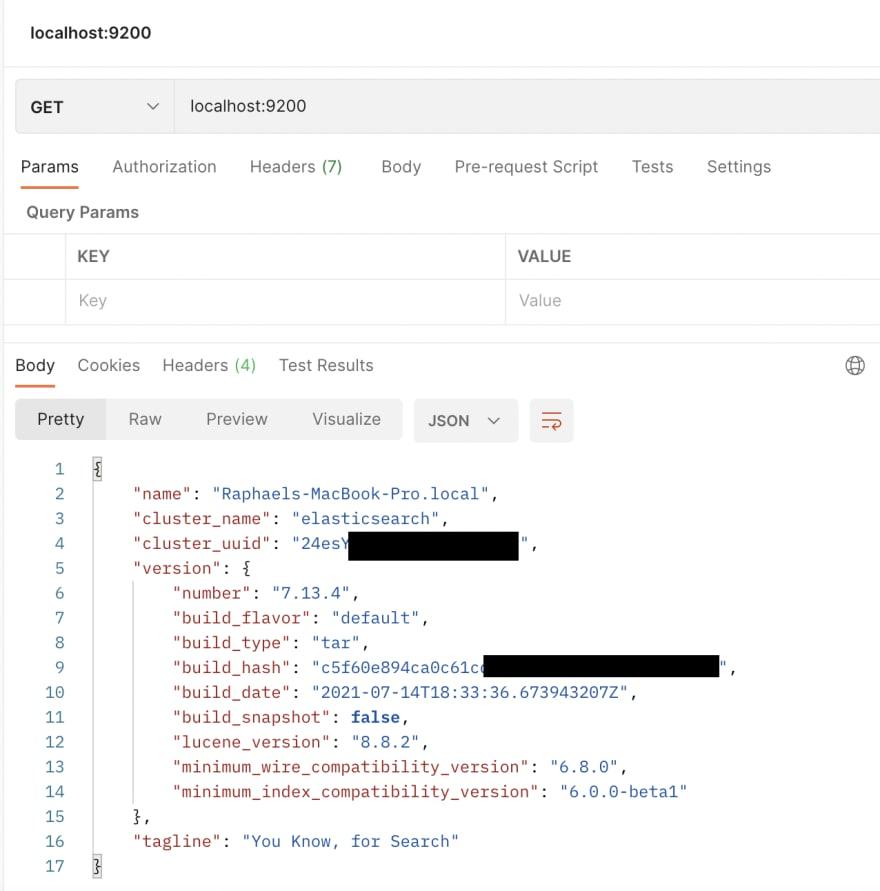
[1] 验证ES集群是否可访问
GET localhost:9200
进入全屏模式 退出全屏模式
首先,确保您的本地 ES 服务器在线,并且您的 Postman 已打开。创建一个指向 localhost:9200 的新 GET 请求。您应该看到如下内容:
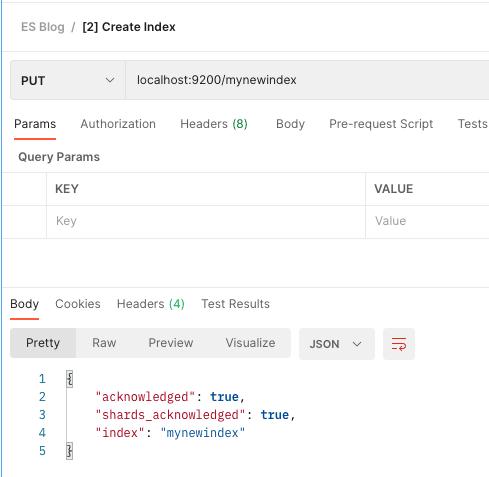
[2] 创建索引
PUT localhost:9200/mynewindex
进入全屏模式 退出全屏模式
现在,让我们创建我们的第一个索引。索引存储我们的数据。相当于在关系数据库中创建表。
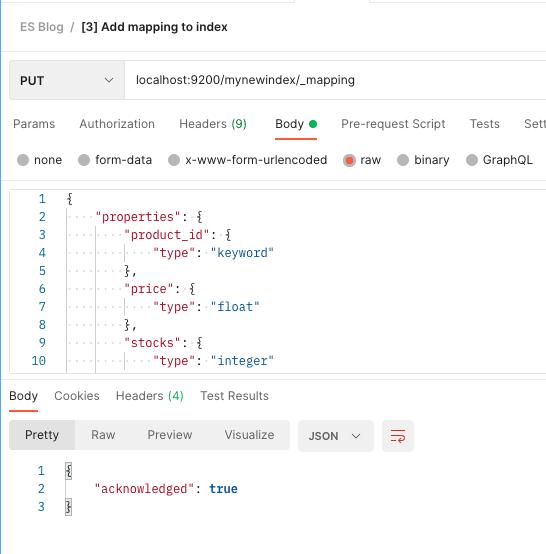
[3] 为索引创建映射
我们刚刚创建的索引没有映射。映射类似于 SQL 数据库中的模式。它规定了我们的索引将摄取的文档的形式。一旦定义,索引将拒绝接受不适合此映射的文档(即,我们将股票定义为下面的整数。如果我们尝试插入带有 stocku003d"none" 的行,则操作将不会继续)。
您会注意到 ES 的一件事是这些映射在默认情况下是允许的。如果我添加一个新属性“perishable”u003d true 的行,当我将文档推送到 ES 时,模式将添加该属性并推断其数据类型。在这种情况下,它将在数据类型为“布尔”的“易腐烂”的映射中添加一个新属性。
您可以在创建索引时添加一些选项,以仅允许在索引映射中定义的属性,仅此而已。
在此命令中,我们为新创建的索引创建映射。
PUT localhost:9200/mynewindex/_mapping
{
"properties": {
"product_id": {
"type": "keyword"
},
"price": {
"type": "float"
},
"stocks": {
"type": "integer"
},
"published": {
"type": "boolean"
},
"title": {
"type": "text"
},
"sortable_title": {
"type": "text"
},
"tags": {
"type": "text"
}
}
}
进入全屏模式 退出全屏模式
大多数数据类型都很简单,除了文本和关键字。这篇文章清楚地解释了差异。
但是 TLDR, Text 允许您在字段内查询单词(即查询“Burger”将显示产品“Cheese Burger with Fries”)。它通过将文本中的每个单词视为可以搜索的单个标记来做到这一点:“cheese”、“burger”、“with”、“fries”。
另一方面,Keyword 将字段的内容视为一个,因此如果您想获取带有薯条的芝士汉堡,则必须对其进行查询:“芝士汉堡薯条”。查询“burger”不会返回任何内容。
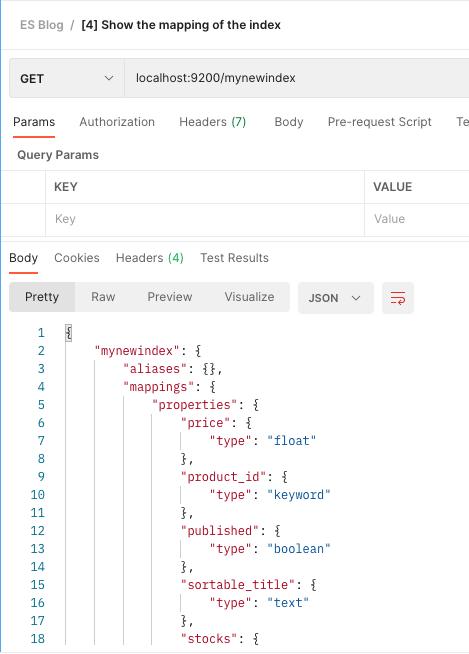
[4] 显示索引的映射
让我们通过发送 GET 请求来验证我们是否成功地为索引创建了映射。
GET localhost:9200/mynewindex
进入全屏模式 退出全屏模式
B |使用我们的 ES 索引进行数据操作
随着我们的索引已经建立,让我们添加数据并切入更令人兴奋的 ES 位!
[5] 为索引创建数据
对于本节,让我们发送三个连续的 post 请求,每个请求具有不同的请求正文。这会在我们的 Elasticsearch 索引中添加 3 个“行”。
POST localhost:9200/mynewindex/_doc
{
"product_id": "123",
"price": 99.75,
"stocks": 10,
"published": true,
"sortable_title": "Kenny Rogers Chicken Sauce",
"title": "Kenny Rogers Chicken Sauce",
"tags": "chicken sauce poultry cooked party"
}
POST localhost:9200/mynewindex/_doc
{
"product_id": "456",
"price": 200.75,
"stocks": 0,
"published": true,
"sortable_title": "Best Selling Beer Flavor",
"title": "Best Selling Beer Flavor",
"tags": "beer best-seller party"
}
POST localhost:9200/mynewindex/_doc
{
"product_id": "789",
"price": 350.5,
"stocks": 200,
"published": false,
"sortable_title": "Female Lotion",
"title": "Female Lotion",
"tags": "lotion female"
}
进入全屏模式 退出全屏模式
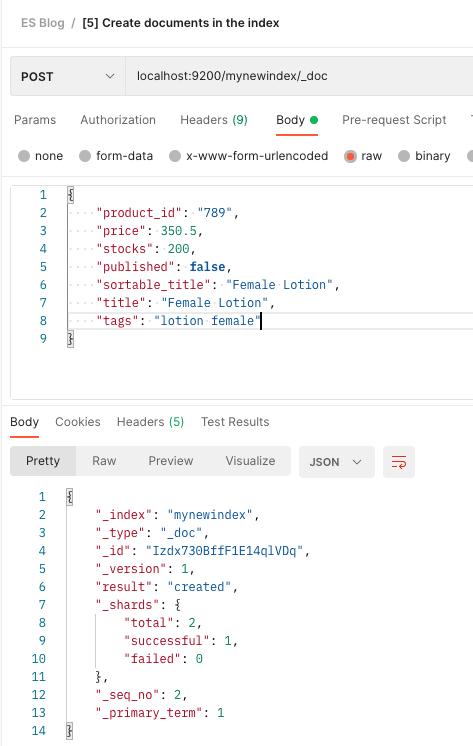
[6] 显示所有数据
现在,让我们看看我们通过命令#5 插入的三个文档是否进入了我们的索引。此命令显示索引中的所有文档:
POST localhost:9200/mynewindex/_search
{
"query": {
"match_all": {}
}
}
进入全屏模式 退出全屏模式
确实如此!
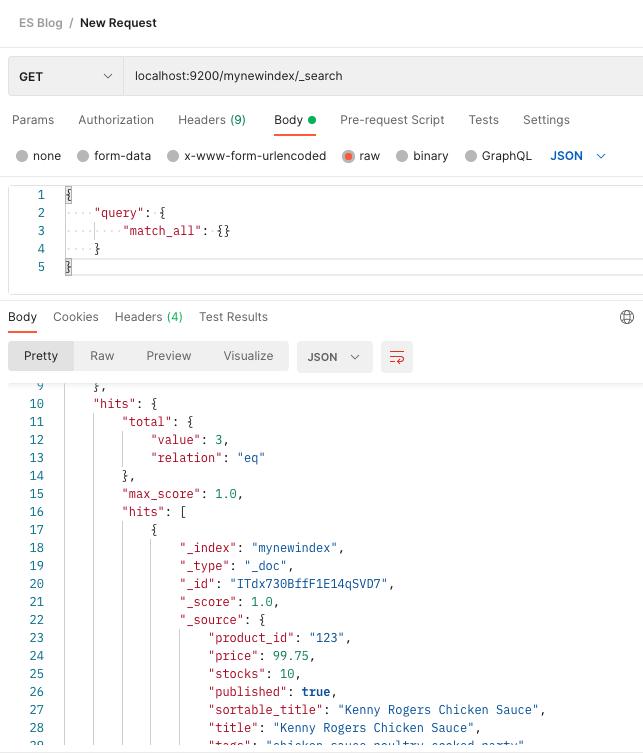
[7] 使用产品 ID 精确搜索
现在,让我们从一个简单的搜索开始。让我们按产品 ID 搜索。
POST localhost:9200/mynewindex/_search
{
"query": {
"term": {
"product_id": "456"
}
}
}
进入全屏模式 退出全屏模式
在上面的命令中,我们使用“术语查询”,因为我们正在寻找具有“product_id”_与_字符串“456”完全匹配的产品。术语查询有效,因为“产品_id”的数据类型是“关键字”。
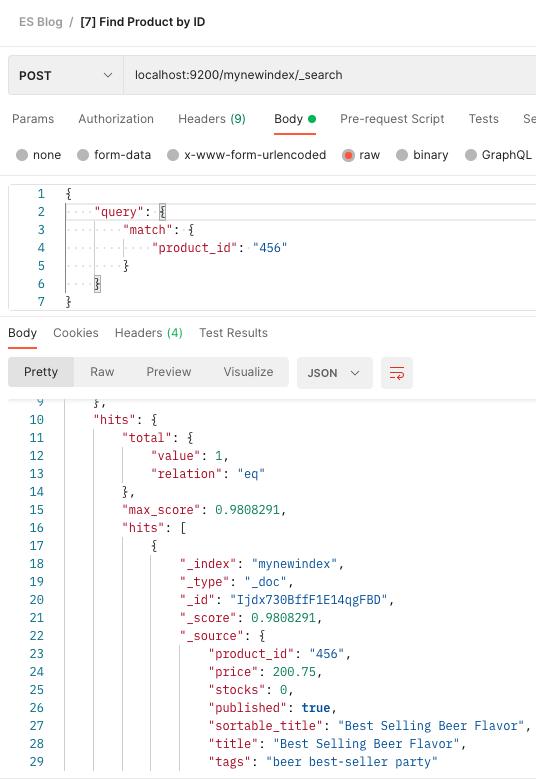
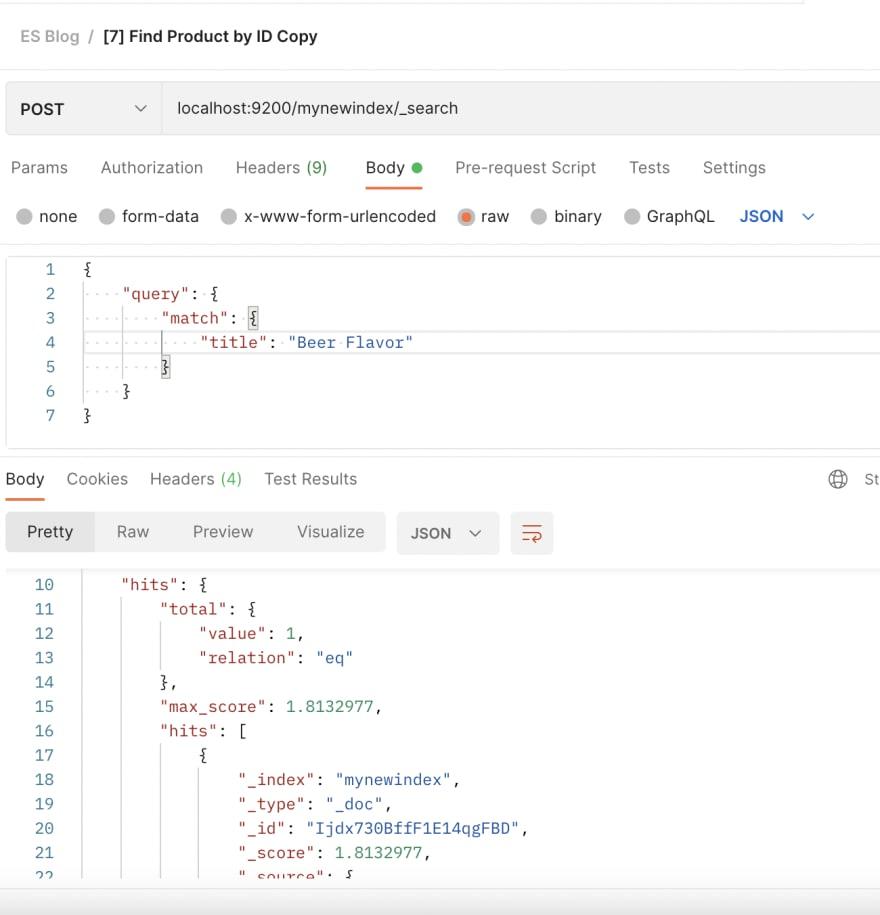
[8] 带标题的模糊搜索
现在,进入更令人兴奋的部分。
ES 以其全面的搜索能力而闻名。让我们通过创建我们的第一个模糊搜索来进行示例。模糊搜索允许我们通过输入几个单词而不是整个字段的文本来搜索产品。客户不必输入产品名称的全名(即 Incredible Tuna Mayo Jumbo 250),而只需搜索他召回的产品部分(即 Tuna Mayo)。
POST localhost:9200/mynewindex/_search
{
"query": {
"match": {
"title": "Beer Flavor"
}
}
}
进入全屏模式 退出全屏模式
在默认设置下,即使我们不完整的查询“啤酒口味”,我们也可以获得产品“畅销啤酒口味”。还有其他设置允许我们容忍拼写错误或不完整的单词来显示结果(即 Bee Flavo)
另外,请仔细注意,我们现在使用“匹配查询”而不是“术语查询”,因为我们希望即使没有输入完整的产品名称也能够获得结果。匹配查询有效,因为标题字段的类型为“文本”。
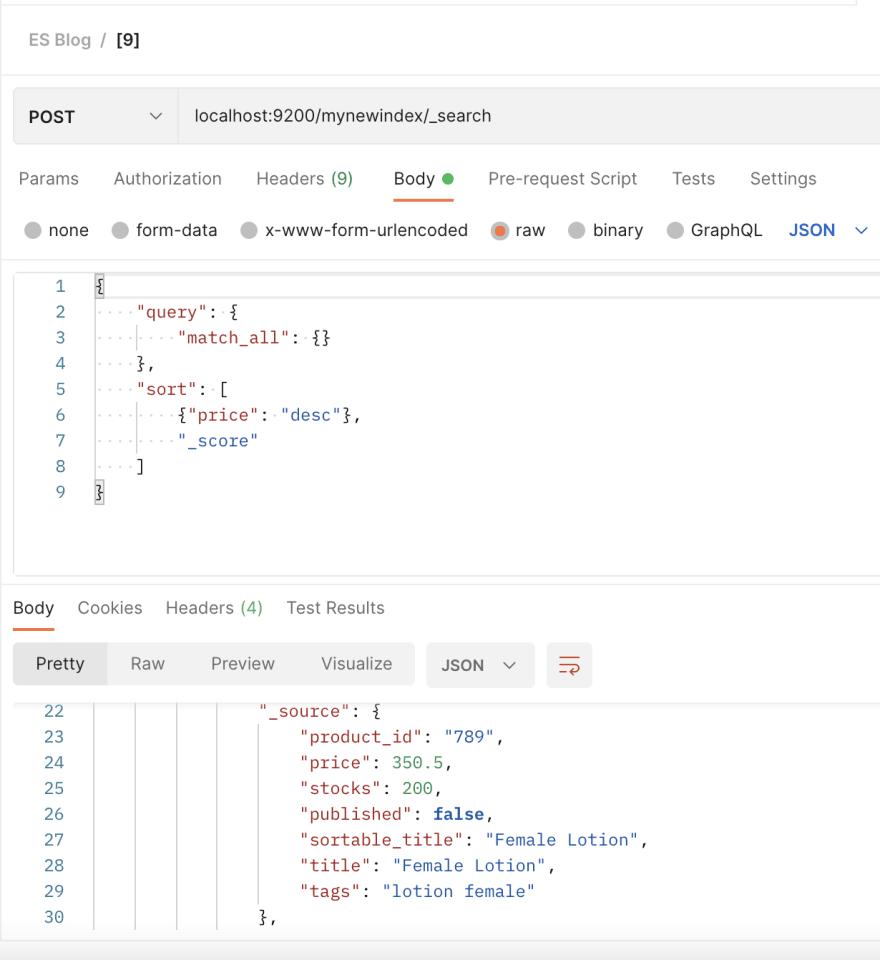
[9] 按价格排序
我们通常与电子商务网站做的另一件事是按价格或评级等特定类别对产品进行排序:
POST localhost:9200/mynewindex/_search
{
"query": {
"match_all": {}
},
"sort": [
{"price": "desc"},
"_score"
]
}
进入全屏模式 退出全屏模式
通过上面的查询,我们返回所有按最贵到最便宜排序的产品。请注意,sort 参数是一个列表,它允许我们添加多个排序条件。我们还添加了“_score”,这是一个用于搜索相关性的弹性搜索关键字。我们将在后面的示例中更深入地探讨这个概念。
[10] 搜索所有已发布且有库存的“啤酒”产品。按最便宜到最贵排序
为了让事情更有趣,让我们再添加几个啤酒产品。我们通过三次发送 POST 请求来做到这一点,每次使用不同的请求正文。
POST localhost:9200/mynewindex/_doc
{
"product_id": "111",
"price": 350.55,
"stocks": 10,
"published": true,
"sortable_title": "Tudor Beer Lights",
"title": "Tudor Beer Lights",
"tags": "beer tudor party"
}
POST localhost:9200/mynewindex/_doc
{
"product_id": "222",
"price": 700.50,
"stocks": 500,
"published": false,
"sortable_title": "Stella Beer 6pack",
"title": "Stella Beer 6pack",
"tags": "beer stella party"
}
POST localhost:9200/mynewindex/_doc
{
"product_id": "333",
"price": 340,
"stocks": 500,
"published": true,
"sortable_title": "Kampai Beer 6pack",
"title": "Kampai Beer 6pack",
"tags": "beer kampai party"
}
进入全屏模式 退出全屏模式
有了索引中的更多文档,我们现在可以进行查询了。这是一个复杂的查询,必须满足三个条件。我们分析下面的查询。
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "Beer"
}
},
{
"term": {
"published": true
}
},
{
"range": {
"stocks": {
"gt": 0
}
}
}
]
}
},
"sort": [
{"price": "asc"},
"_score"
]
}
进入全屏模式 退出全屏模式
在我们最近添加的产品中,有四种带有啤酒一词的产品:
-
456:畅销啤酒味
-
111:帝舵啤酒灯
-
222:斯特拉啤酒 6 包
-
333: Kampai 啤酒 6 包
由于我们过滤掉了库存为零(或以下)的项目,因此我们从列表中删除了产品 456。另一个过滤器是产品必须已发布(已发布 u003d true)。使用此过滤器,产品 222 被移除。我们剩下以下 2 种产品。它们必须按从最便宜到最贵的顺序排序,如下所示:
-
333:Kampai 啤酒 6 包(价格 u003d 340)
-
111:帝舵啤酒灯(价格u003d350.55)
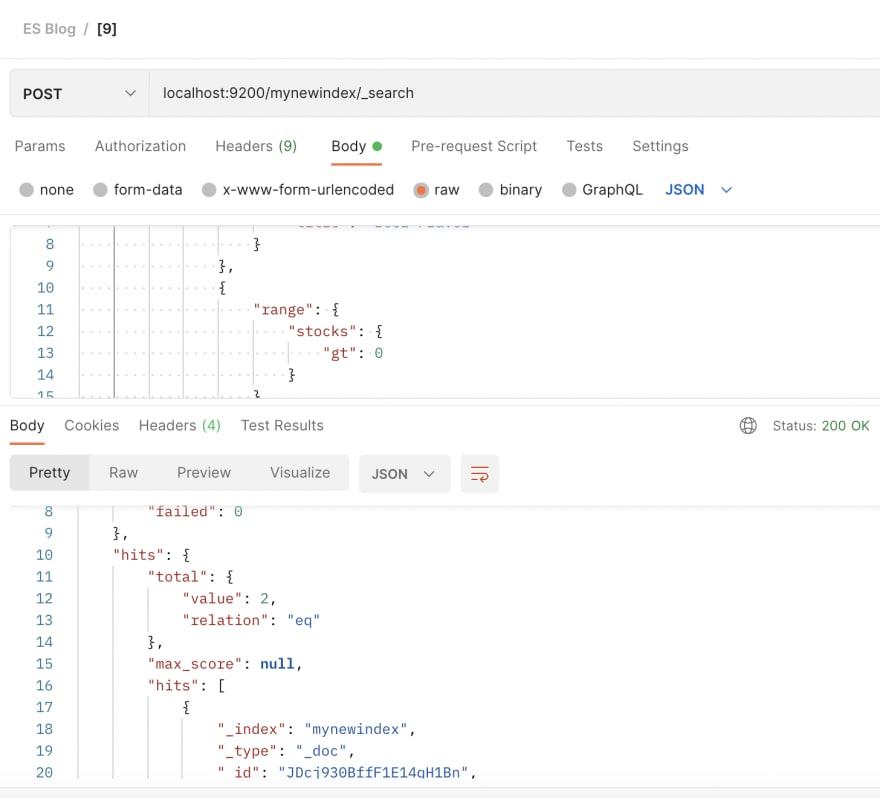
在此示例中,使用了键“必须”,并以列表作为其值。该列表包含必须同时满足的条件才能满足查询要求。在这个例子中,它的“标题必须有单词'beer'”和“published 属性等于true”和“stocks 大于零”。
[11] 搜索所有具有以下标签 ['家禽、'kampai'、'best-seller'] 至少 1 个、已发布且有库存的产品。按最便宜到最贵排序
我们之前的查询只涉及三个必须为 ALL TRUE 才能成立的条件。这相当于“A and B and C”。
在这个查询中,我们仍然有三个条件必须全部为真,但是如果第一个条件是“家禽”、“kampai”或“畅销书”,则将其标记为真。在这个例子中,我们介绍了“或”的语法:
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"tags": "poultry"
}
},
{
"match": {
"tags": "kampai"
}
},
{
"match": {
"tags": "best-seller"
}
}
],
"minimum_should_match": 1
}
},
{
"term": {
"published": true
}
},
{
"range": {
"stocks": {
"gt": 0
}
}
}
]
}
},
"sort": [
{
"price": "asc"
},
"_score"
]
}
进入全屏模式 退出全屏模式
在这个查询中,我们仍然有一个“must”关键字,但它的第一个包含一个“should”关键字。整个查询等价于:(A or B or C)AND D AND E。“应该”意味着只要满足一个条件,(A or B or C)语句就返回true。
我们可以做的一个调整是调整“minimum_should_match”(msm)参数,因此我们可以要求满足两个或三个或 N 个条件才能使语句为真。在我们的示例中,如果 msmu003d2,则意味着产品必须有两个匹配的标签才能被认为是真实的(即产品必须同时是家禽和 kampai)。
我们分析下面的查询:
-
产品应该至少有以下 1 个标签:家禽、kampai、畅销书
-
这匹配 3 个产品:家禽 (pid: 123)、kampai (pid: 333) 和畅销产品 (pid: 456)
-
即发布
-
上一步中的所有 3 个 PID 均已发布。所以没有变化。
-
应该有库存
-
由于 pid 456 没有库存,我们只剩下 pid 123 和 pid 333
-
按价格排序
-
pid 333 是 340 比索
-
pid 123 是 99.75 比索
-
因此,顺序应该是 pid 123 u003d> pid 323
[12] 搜索所有具有以下标签 ['poultry, 'kampai', 'best-seller'] 中至少 1 个且有货的产品。价格应该在 0 到 300 之间。按最便宜到最贵排序
此查询类似于 #11,但我们添加了另一个条件,即返回的产品价格只能在 0 到 300 之间。
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"tags": "poultry"
}
},
{
"match": {
"tags": "kampai"
}
},
{
"match": {
"tags": "best-seller"
}
}
],
"minimum_should_match": 1
}
},
{
"term": {
"published": true
}
},
{
"range": {
"stocks": {
"gt": 0
}
}
},
{
"range": {
"price": {
"gt": 0,
"lt": 300
}
}
}
]
}
},
"sort": [
{
"price": "asc"
},
"_score"
]
}
进入全屏模式 退出全屏模式
此查询引入了“范围”关键字,它允许我们过滤与特定范围值匹配的项目。对于价格,我们设置了价格在 0 到 300 之间的条件。对于股票,我们只设置价格大于零。
我们来分析查询:
-
从 #11 的结果中,我们有 pid 333 (340pesos) 和 pid 123 (99.75pesos)
-
使用 0-300 价格过滤器,我们唯一的结果将是 pid 123 (99.75 比索)
结论
开始使用 ElasticSearch 很简单!但随着业务需求的增长,您的搜索需求可能会变得更加复杂。此备忘单可帮助您驾驭这种复杂性。
在此级别学习 ES 语法的替代方法是使用用于 Elasticsearch 的DSL 库“抽象” Elasticsearch 的长格式语法。它是 ES 通用用途的强大工具。但是,随着您的查询需求增长,学习该 DSL 下的语法将使您了解可以添加的选项以使您的搜索更丰富。
你呢?您还想学习其他 ElasticSearch 语法吗?
也许我能帮上忙!在评论中输入它,我将尝试将其添加到文章中。
照片由TKonUnsplash

欢迎大家访问Elastic 中国社区。由Elastic 资深布道师,Elastic 认证工程师,认证分析师,认证可观测性工程师运营管理。
更多推荐
 0
0 0
0- 0



 已为社区贡献13405条内容
已为社区贡献13405条内容

所有评论(0)