
1小时真机RL微调成功率破95%!HIL-ResRL:即插即用的VLA“外挂”神器
在具身智能的浪潮中,视觉-语言-动作(VLA)模型展现出了惊人的泛化能力。然而,当你真正尝试把这些模型部署到真实物理世界或工业产线上时,往往会被现实狠狠“打脸”。
为什么?因为目前的 VLA 模型主要依赖于模仿学习(Imitation Learning, 尤其是行为克隆 BC)。这种范式存在一个致命的硬伤:误差累积和分布偏移。在实验室里,机械臂抓取可能十拿九稳;但如果在产线上,目标物体的位置稍微偏离了演示数据的分布,机器人就会“懵圈”甚至做出危险动作。
虽然大家都在尝试用真实世界强化学习(Real-world RL,如近期的 π0.6∗)来让机器人“自我纠错”,但这些方法往往计算代价极其高昂,且与特定的模型架构深度绑定。对于追求快速部署的柔性制造业来说,这显然不够灵活。
今天我们要介绍的这篇来自华为云CloudRobo团队的论文,提出了一种优雅的解决方案——HIL-ResRL(基于人机协同残差强化学习的模型无关微调适配器)。它把基础 VLA 模型当成黑盒,不仅不挑模型,而且仅需1小时真机在线训练,就能让任务成功率突破95%!
💡 核心思路:大模型负责“打底”,残差策略负责“纠偏”
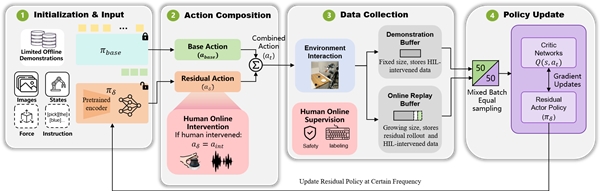
面对复杂的工业级 VLA 模型,HIL-ResRL 并没有选择从头再训练或者整体微调,而是采用了一种极其轻量化的残差策略(Residual Policy)**结合人机协同的哲学,整体框图如下:
为了更形象地理解,我们可以打个比方——这就如同大人教小孩骑自行车:
基础动作(小孩已有的平衡能力 = Base Policy): 小孩在学习骑自行车的时候,其实已经是有一定的运动能力和平衡能力的。这就像框架中冻结的预训练 VLA 模型(如 Diffusion Policy 或 π0.5)。它们通过大量离线模仿学习,掌握了抓取移动等基础动作先验,负责输出一个基础动作方向 abase。分布偏移与误差累积(刚上车的摔跤 = OOD): 但是,小孩刚上自行车放到一个新的场景时,很容易因为扶不稳把手导致摔跤。这对应着 VLA 模型在真实世界面临的分布偏移(Distribution Shift)与误差累积。刚预训练好的 VLA 模型放到新场景就会有一定的失败率,一旦偏离原本演示数据的分布,模型就会开始“胡乱抖动”或轨迹发散。残差干预(大人的“扶一把” = Residual Action + HIL): 传统的做法是让小孩自己摔成百上千次直到学会,但这极不安全。HIL-ResRL 的做法是:大人(操作员)可以跟在小孩身边待命,在手把手歪掉的危急时刻轻轻扶一下,给出一个微小的修正。在框架中,这相当于训练一个极轻量的残差网络输出修正动作 ares,并在必要时引入大人的干预信号 aint。机器人最终执行的动作是基础动作加上修正:at=abase+ares。极速收敛(数次纠正学会骑车 = ResRL): 就像小孩能在大人数次纠正的肌肉记忆中迅速学会骑自行车一样,机器人的残差网络会将人类的修正动作记录下来,只需学习“特定时刻怎么微调纠偏”,局部动力学修正的难度极低,从而通过离策略强化学习(SAC)实现极速收敛。
这种即插即用(Plug-and-play)的设计意味着它可以无缝集成到任何现成的 VLA 模型中,而无需获取其内部的权重或生成范式(无论是 Diffusion 还是 Flow Matching)。
人机协同(HIL):安全探索的终极保障
如果仅仅是加上残差网络让机器人自己去“试错”,不仅样本效率极低,而且随机探索很容易损坏昂贵的机械臂硬件。HIL-ResRL 的真正杀手锏在于将人类在环(Human-in-the-loop, HIL)深度融入到了强化学习的训练循环中,扮演着时刻护航的“大人”角色。
在执行过程中,人类操作员手里拿着一个 3D SpaceMouse 随时待命。当遇到以下情况时,人类会直接介入:
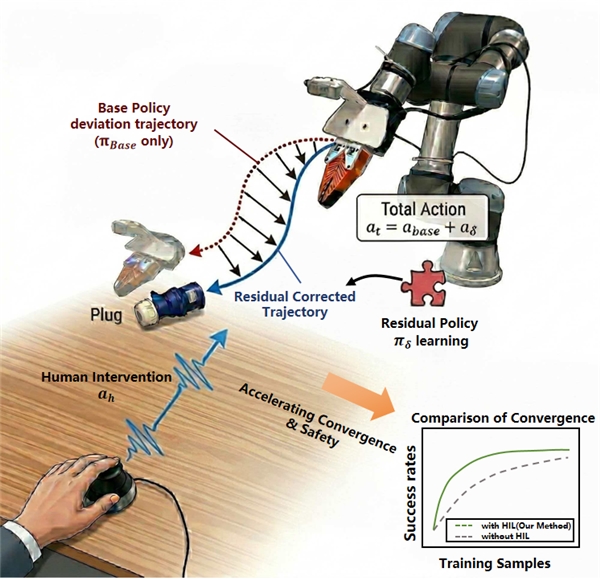
应对分布外(OOD)状态的“神级救场”: 当基础模型走到演示数据稀疏的区域开始“胡乱抖动”时,人类操作员只需给出一个微小的干预信号 aint,就能把机器人“拽”回正确的状态分布中。这种干预不需要人类重新演示完整的轨迹,极大地减轻了工作量。最权威的“裁判”与紧急刹车: 对于工业级的高精度操作(例如插头插座的遮挡情况),纯视觉分类器很难判断是否真正插紧,人类可以直接提供最准确的“成功/失败”标签。同时,一旦机器人进入危险死锁状态,人类可以触发紧急重置,坚决防止策略从危险状态中学习。聚焦困难样本(Hard-negative mining): 通过分析人类介入的数据,框架可以针对那些高失败率、被遮挡的极具挑战性的区域进行重点学习。
这些介入数据会和残差网络自我探索的数据混合在一起(采用 50/50 的相等比例采样),通过 SAC(Soft Actor-Critic)算法进行高效的强化学习优化。
真机实验:效率与精度的双重震撼
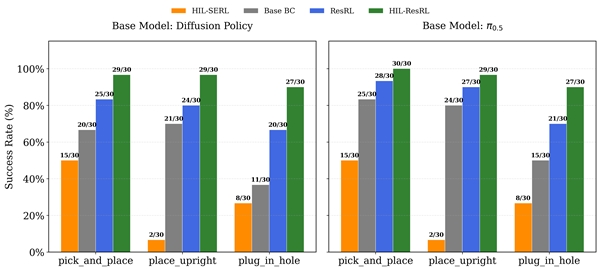
为了验证 HIL-ResRL 的威力,研究团队在真实的 UR5e 机械臂上进行了测试,选取了三种典型的工业任务:抓取放置(Pick and Place)、垂直放置(Place Upright)以及高精度的多孔插网线/插头任务(Multiple Plug-in-Hole),实验结果非常令人振奋:
成功率飙升,打破性能瓶颈: 无论是使用 Diffusion Policy 还是 π0.5 作为基础模型,原本因为瓶颈状态只有 50%-80% 的成功率在经过 HIL-ResRL 短短 40 到 90 分钟的真机在线训练后,全部飙升至 90% 甚至 95% 以上!吊打从头学习的RL基线: 与当前顶级的真机强化学习框架 HIL-SERL 相比,HIL-SERL 在需要同时控制位置和姿态的复杂任务(如垂直放置、插头任务)上极难收敛,而 HIL-ResRL 因为利用了基础模型的“动作先验”,只需要进行局部动力学修正,展现出了断层式的领先优势。极高的安全性: 在“插网线”这种高接触任务中,纯自主的强化学习(ResRL)在一小时内触发了 15次 紧急急停,而 HIL-ResRL 在人类的适时护航下,仅触发了 2次!
彩蛋:多模态触觉/力觉反馈的无缝接入
对于“把插头精确插进插座”这种容易被机械爪严重遮挡视觉的高精度任务(Contact-rich tasks),HIL-ResRL 还展现了强大的扩展性。通过将六轴力/力矩传感器的信号作为多模态输入喂给残差网络,该任务的成功率从仅靠视觉的 50% 瞬间拔高到了惊人的 93%!残差策略学会了“通过触觉摸索”来纠正微小的错位,这正是工业装配梦寐以求的能力。
结语
在制造业向着“多品种、小批量、短周期”的柔性制造(Flexible Manufacturing)转型的大背景下,机器人模型的快速部署和适配能力变得至关重要。
HIL-ResRL 用一种“轻量、安全、高效”的姿态证明了:我们不需要每次都动辄用成百上千张显卡去微调庞大的VLA基座模型,只需赋予它一个懂得“自我参考与人类协作”的小脑(残差策略),它就能在短短1小时内蜕变为工业级的满分特种兵。
相信在未来,这种兼顾大模型泛化性与底层残差控制精准度的架构,将成为具身智能真机落地的一条重要破局之路!
「免责声明」:以上页面展示信息由第三方发布,目的在于传播更多信息,与本网站立场无关。我们不保证该信息(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担,以上网页呈现的图片均为自发上传,如发生图片侵权行为与我们无关,如有请直接微信联系g1002718958。
更多推荐

 0
0 0
0- 0



 已为社区贡献4666条内容
已为社区贡献4666条内容

所有评论(0)