
Claude Opus 4.7:版本号只涨0.1,但真实提升在哪
Opus4.7版本在性能上有所提升,主要改进包括:软件工程能力(SWE-bench得分提升6.8%)、视觉推理能力(XBOW测试从54.5%跃升至98.5%)和多学科推理能力。新版本采用新tokenizer,输入token数增加1.0-1.35倍,但价格不变。新增xhigh档位和/ultrareview命令,优化了成本控制和代码审查。虽然部分测试如AgenticSearch得分略有下降,但整体性能

先说结论:Opus 4.性能确实有提升,但体感没有从4.5到4.6那次来得猛。不过,Opus 4.6已经非常好用,4.7能在已有高度上再进一步——当模型在某个benchmark上已经很高时,每一点提升都意味着能解决更多"corner case",这反而是最珍贵的地方。
另外Opus 4.7换用了新的tokenizer。价格没变(仍是输入$5/百万token,输出$25/百万token),但同样的输入内容,token数会增加1.0~1.35倍,具体取决于内容类型。再加上4.7在高effort下思考得更多——官方称"low-effort 4.7 roughly equivalent to medium-effort 4.6"——整体输出token也会增加。官方测试结论是净效应为正(花更少钱做更多事),但如果你是API重度用户,切换前建议在自己的真实traffic上跑一下A/B对比。此外,高分辨率图像也会消耗更多token,官方建议不需要高精度细节的场景可以下采样后再发送至于为什么这次只给了0.1的版本号,官方发布页自己承认了:Opus 4.7的能力不如Mythos Preview。而Mythos因为某些能力(cyber)太强,目前只通过Project Glasswing限量发布。版本号0.1的潜台词很明确:底牌还没出
(官方发布页:Introducing Claude Opus 4.7 \ Anthropic)
核心能力:官方划了四个重点
软件工程能力:
SWE-bench Verified得分从4.6的80.8%跃升至87.6%。这一点和你上次观察到的"4.6在SWE-bench Verified上几乎原地踏步"形成鲜明对比——4.6 vs 4.5基本没动,但4.7一下子涨了6.8个百分点。
官方自己统计,Opus 4.7在其内部93项编码任务测试中,整体解决率比Opus 4.6提升了13%,其中有四项任务是4.6和Sonnet 4.6都解决不了的。
Cursor的评测更具参考价值:Cursor自家开发的CursorBench测试集上,4.7得分突破70%,而4.6只有58%。这不是合成benchmark,是直接反映真实IDE使用体验的数据。

视觉推理能力(爆发式增长):
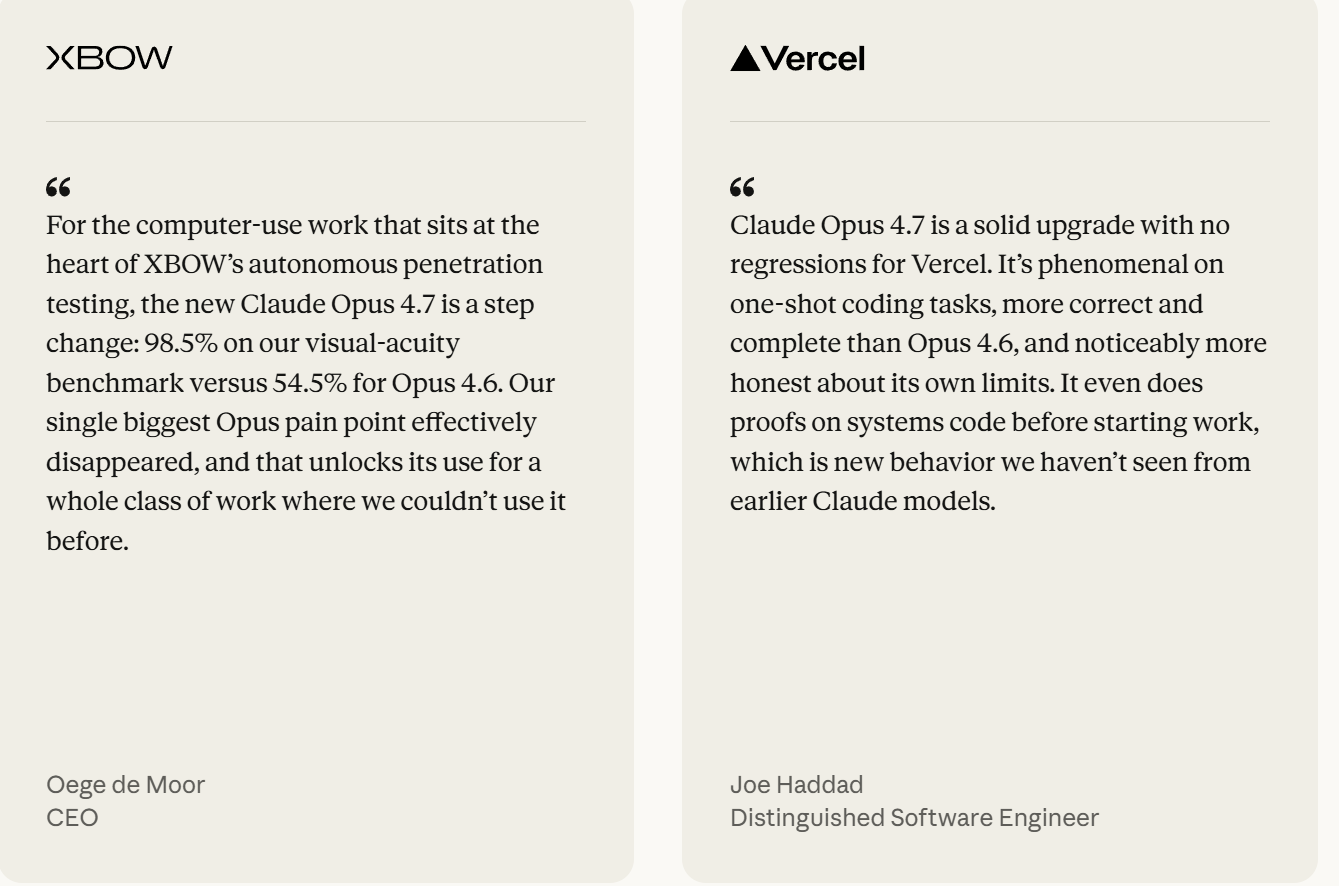
这是4.7改进最明显的方向。XBOW的视觉敏锐度(visual-acuity)测试中,4.7得分为98.5%,而4.6仅为54.5%。从官方发布页的早期测试者反馈来看,Vercel团队的评价是"our single biggest Opus pain point effectively disappeared"(我们最大的Opus痛点彻底消失了)。
多学科推理:
实际可用性方面,Opus 4.7支持长边达2576像素的图像输入,分辨率是此前Claude模型的三倍以上。这意味着AI代理可以阅读密密麻麻的屏幕截图、从复杂图表中精准提取数据,甚至做"像素级"精确校对。
官方在Humanity‘s Last Exam等测试中,4.7在高基数上保持了稳定增长。在内部研究代理基准测试中,4.7的综合得分为0.715,与最高分并列。
安全可靠性:
一个不太被普通用户注意到但很重要的点:Opus 4.7是Project Glasswing框架下第一个搭载新型网络安全护栏的模型,会自动检测并拦截高风险网络安全请求。同时Anthropic推出了Cyber Verification Program,允许安全专业人员申请将Opus 4.7用于合法的漏洞研究等用途。(项目地址:Real-time cyber safeguards on Claude | Claude Help Centerr)

合作方实测:27家评测的关键数据
Anthropic发布前通常会邀请合作方提前评测,官方发布页引用了多家反馈。以下是几个值得注意的:
-
Notion:多步工作流上,Opus 4.7比4.6好14%,token用量更少,tool错误仅为4.6的三分之一。Notion的评价是"the reliability jump that makes Notion Agent feel like a true teammate"。
-
CodeRabbit:代码审查工作负载中,Opus 4.7解决的正式任务数量是4.6的三倍,代码质量和测试质量均有两位数提升。
-
Harvey:在BigLaw Bench法律推理测试中,高effort模式下得分90.9%,在法律表格推理和歧义文档编辑任务上表现更智能。
-
Databricks:在OfficeQA Pro文档推理测试中,比4.6的错误率降低21%。
两个值得关注的更新:xhigh和/ultrareview
xhigh effort档位
这次发布附带了一个重要产品更新:在原有high和max之间插入了一个新档位xhigh(extra high),让用户在推理深度和延迟之间获得更精细的控制。
你的原话很准:"之前high和max之间差一档,high有时不够用,max又太烧钱。现在xhigh补了这个缝。"Claude Code中已将默认effort设为xhigh。
官方建议:编码和agentic用例,从high或xhigh开始测试;max只留给最难的、愿意为边际收益买单的场景。
Task budgets(公测)
同步上线的还有任务预算(task budgets)公测版,开发者可以引导Claude的token开销,使其在较长运行周期中合理分配工作。对做long-running Agent的人来说,成本可控性好了不少。
/ultrareview命令(Claude Code)
Claude Code新增了/ultrareview斜杠命令,会专门跑一次深度代码审查,找一个认真reviewer才能发现的bug和设计问题。Auto mode也扩展到了Max用户——执行长任务时,Claude可以自主决定部分授权,不用每一步都卡一下。

(详细内容参考:https://www.anthropic.com/news/claude-opus-4-7)
小结:哪些变了,哪些没变
提升明显的:
-
SWE-bench Verified:80.8% → 87.6%(+6.8%)——这是4.7最大的亮点
-
视觉推理:54.5% → 98.5%(XBOW测试)——爆发式增长
-
CursorBench:58% → 70%——真实IDE体验的反映
-
多步工作流效率:token更少,tool errors减少2/3
需要关注的点:
-
新tokenizer导致同内容token增加1.0~1.35倍
-
高effort下输出token增多,需实测成本变化
关于Agentic Search的争议:
你提到的BrowseComp得分从4.6的83.7%掉到4.7的79.3%,这一点确实存在。这可能是4.7在搜索策略上变得更"审慎"了,也可能是测试集标准有变化。如果你重度依赖Agentic Search,建议先实测。
下个大版本更值得期待: Opus 4.7是为Mythos的护栏测试铺路的——等Mythos正式版出来,那才是真正的"王炸"。
等上班后在真实项目里跑一跑,有翻车或惊喜再来更新

ALL IN ONE 通用智能(AGI)服务
行业领先的AI服务供应商
探索智能边界
发现无限可能

中科创新烁智(CSCITech)
更多推荐


 7
7 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)