
文档处理的 “像素魔法”!Deepseek-OCR 开源:视觉压缩到底牛在哪?
DeepSeek团队开源了革命性的OCR模型DeepSeek-OCR,由Haoran Wei等研究者开发。该模型采用"视觉-文本压缩"创新思路,通过双塔融合架构(DeepEncoder视觉编码器和DeepSeek3B-MoE解码器)实现16倍下采样压缩,仅需100个视觉Token即可超越传统OCR的识别效果。其突破性技术包括:支持10倍压缩下97%的识别精度、复杂内容解析(化学
2025 年 10 月 20 日,DeepSeek 团队在 GitHub 上悄然开源了一款革命性的 OCR 模型 ——DeepSeek-OCR。

该项目由DeepSeek三位研究员 Haoran Wei、Yaofeng Sun、Yukun Li 共同完成。
其中一作 Haoran Wei (Github主页:https://github.com/Ucas-HaoranWei )
(学术主页:https://scholar.google.com/citations?user=J4naK0MAAAAJ )
现身为DeepSeek研究员。他的主要研究方向包括计算机视觉、多模态、AIGC 等,曾就职于阶跃星辰,在2024年9月发表的论文中,身为论文一作的他所处单位为阶跃。他主导开发了旨在实现“第二代OCR”的GOT-OCR2.0系统,该项目在GitHub收获了超7800star。目前他在DeepSeek主导OCR项目,DeepSeekOCR的工作延续了GOT-OCR2.0的技术路径,致力于通过端到端模型解决复杂文档解析问题。
这款仅有 3B 参数量的模型,却在技术圈掀起了一场关于 "视觉 - 文本压缩" 的讨论风暴。当传统 OCR 还在为提高字符识别率而努力时,DeepSeek-OCR 却另辟蹊径,将整页文字渲染成图像,再让模型去 "读" 这些图像,从而高效提取文字信息。
这种被称为 "上下文光学压缩"(Contexts Optical Compression)的创新思路,不仅是对传统 OCR 技术的颠覆,更可能成为解决大语言模型长上下文处理难题的关键突破口。
DeepSeek 团队在其官方论文中明确指出,他们的目标是 "探索视觉 - 文本压缩边界",而非简单的字符识别。这一理念的提出,标志着 OCR 技术正从" 识别字符 "向" 理解文档 " 的方向演进。
本文将深入剖析 DeepSeek-OCR 的技术创新、应用价值和未来前景。
一、视觉压缩重新定义文档处理
1. 核心架构:双塔融合的创新设计
DeepSeek-OCR 的技术架构核心由两大组件构成:DeepEncoder 视觉编码器 和 DeepSeek3B-MoE 解码器
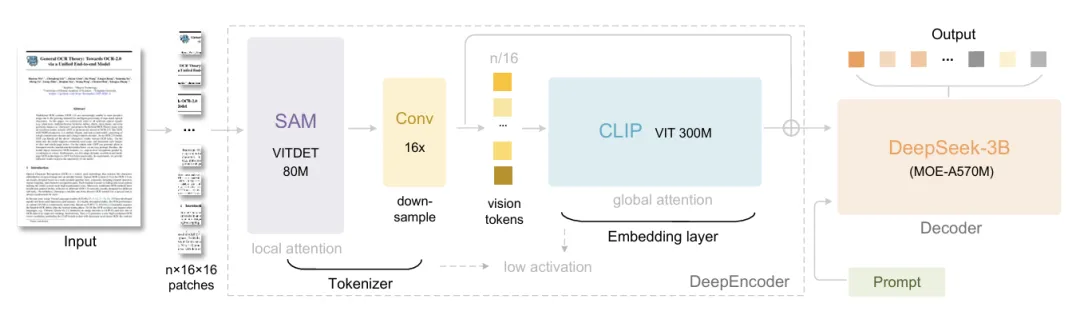
DeepEncoder 视觉编码器负责图像特征提取和压缩,采用了独特的双塔融合设计。底层的 SAM-base 模型(80M 参数)采用窗口注意力机制,像精密的显微镜一样捕捉文本的局部特征,在处理 512×512 高分辨率输入时仍能保持极低内存占用。顶层的 CLIP-large 模型(300M 参数)则通过全局注意力把握整体语义。
DeepSeek3B-MoE 解码器负责从压缩后的视觉 Token 中重建文本,仅需 570M 激活参数就能实现视觉令牌到文本的精准翻译。这种设计的巧妙之处在于,它将 n 个视觉令牌通过非线性映射转化为 N 个文本令牌,在处理压缩数据时反而提升了语义理解能力。
2.压缩技术:16 倍下采样的 "魔法"
DeepSeek-OCR 最具创新性的技术是其 16 倍下采样压缩机制 。在 SAM 和 CLIP 双模块之间,DeepSeek 团队加入了 2 层卷积模块,将 SAM 输出的 4096 个 patch token 压缩至 256 个,大幅降低全局注意力计算的内存开销。
这种压缩技术的效果令人惊叹:
• 传统方法每页产生数千个 Token
• DeepSeek-OCR 在一般文档中只需64 至 400 个视觉 Token
•实现了7-20 倍的压缩比
更重要的是,这种压缩并非简单的信息丢弃,而是通过视觉模态的高效编码实现了信息的智能压缩。DeepSeek-OCR 在 10 倍压缩比下可实现97% 的解码精度,即使在 20 倍压缩率下,OCR 准确率仍可保持在约60%。
3.多分辨率支持:灵活应对不同场景
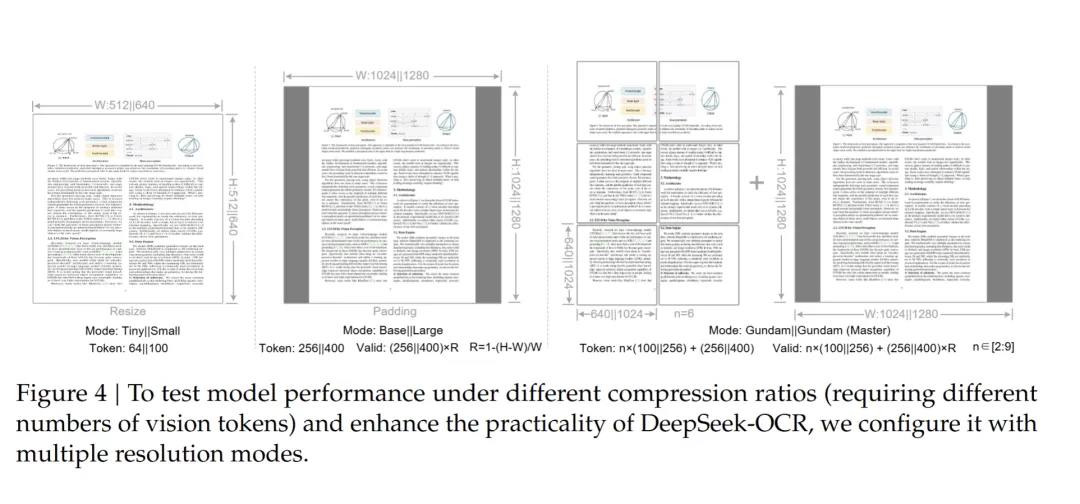 DeepSeek-OCR 提供了丰富的分辨率选择,满足不同场景需求:
DeepSeek-OCR 提供了丰富的分辨率选择,满足不同场景需求:
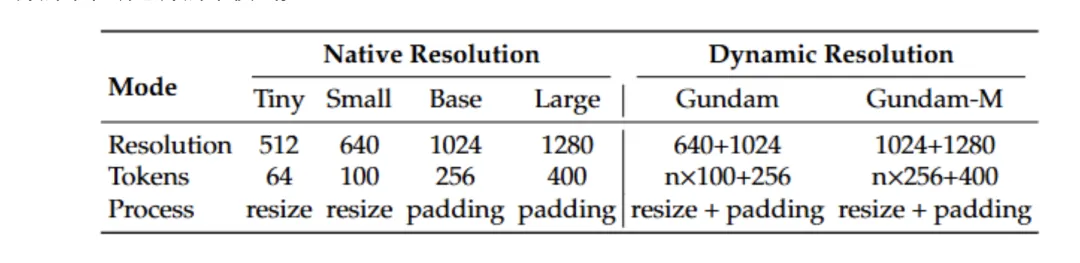
其中,Gundam 动态分辨率模式 最为独特,它采用 "n×640×640 + 1×1024×1024" 的组合策略,能够根据文档内容智能分配计算资源,在保证精度的同时最大化效率。
4.复杂内容解析:超越字符识别的理解能力
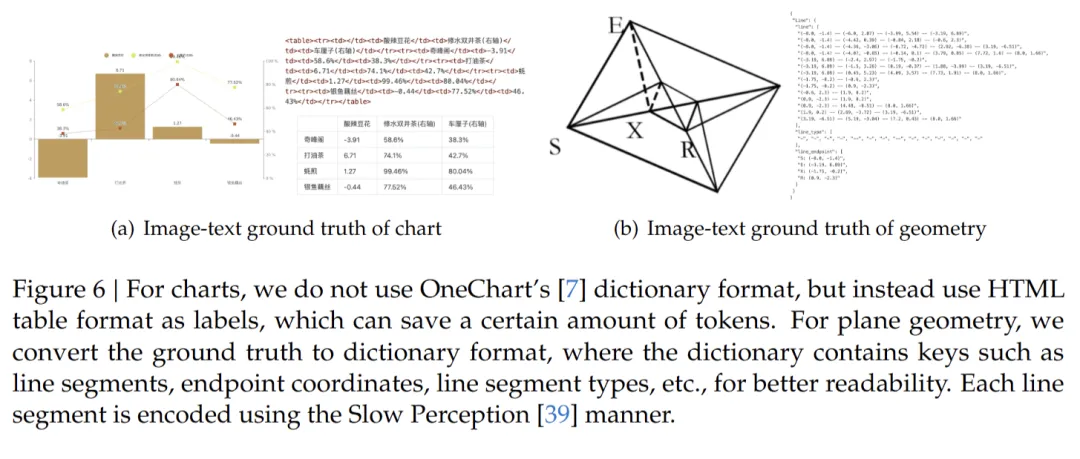
与传统 OCR 相比,DeepSeek-OCR 的一大优势是其强大的复杂内容解析能力:
化学公式识别:能解析化学分子结构式,并将其转化为 SMILES 格式

几何图形处理:支持平面几何图形的复制和结构化解析
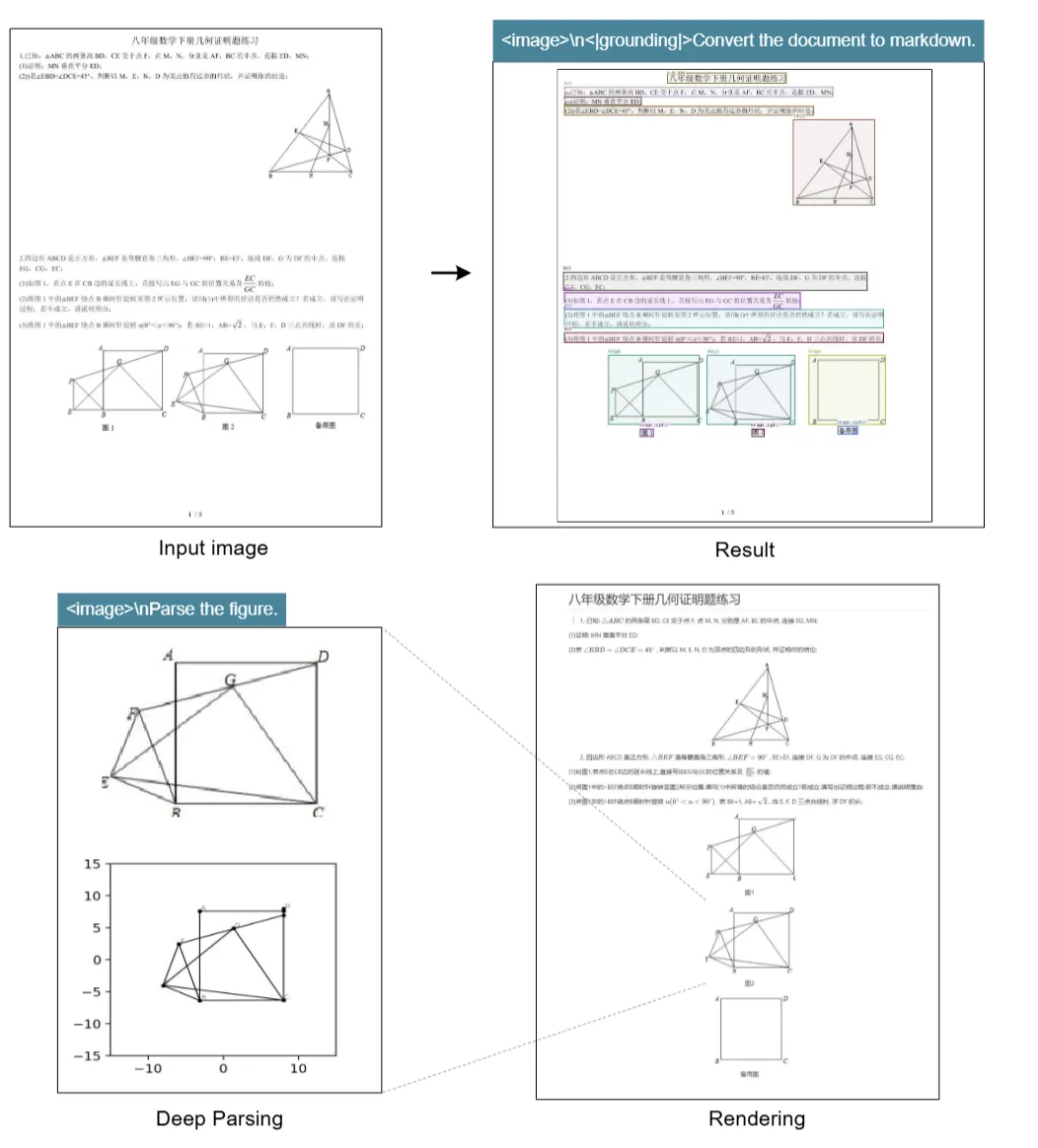
表格识别:在 MIT 学术论文测试集上,公式识别准确率达到89%,远超行业 75% 的平均水平
二、效率与精度的完美平衡
1.压缩效率:100 个 Token 超越 6000 个的奇迹
DeepSeek-OCR 在 Token 效率上创造了惊人的成绩:
仅用100 个视觉 tokens就超过了 GOT-OCR2.0(256 tokens)
用不到800 个 tokens就超越了需要 6000 多 tokens 的 MinerU2.0
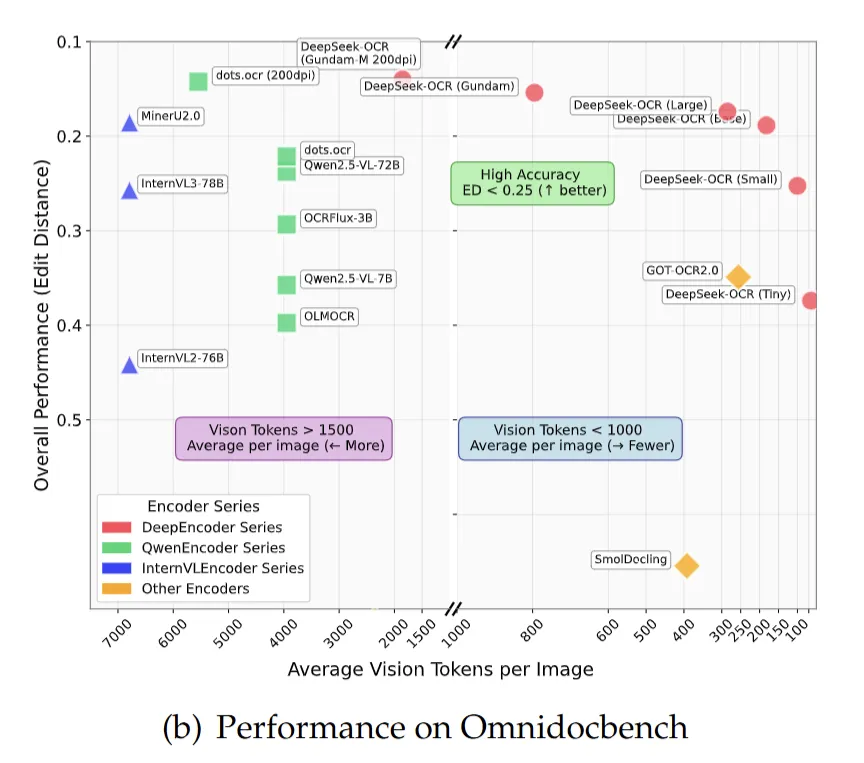
这种效率提升的意义在于,它从根本上解决了大语言模型处理长文本时的内存瓶颈问题。传统模型处理千页级文档时,常因上下文累积导致内存溢出或精度衰减,而 DeepSeek-OCR 通过视觉压缩,将内存需求降低到原来的1/16。
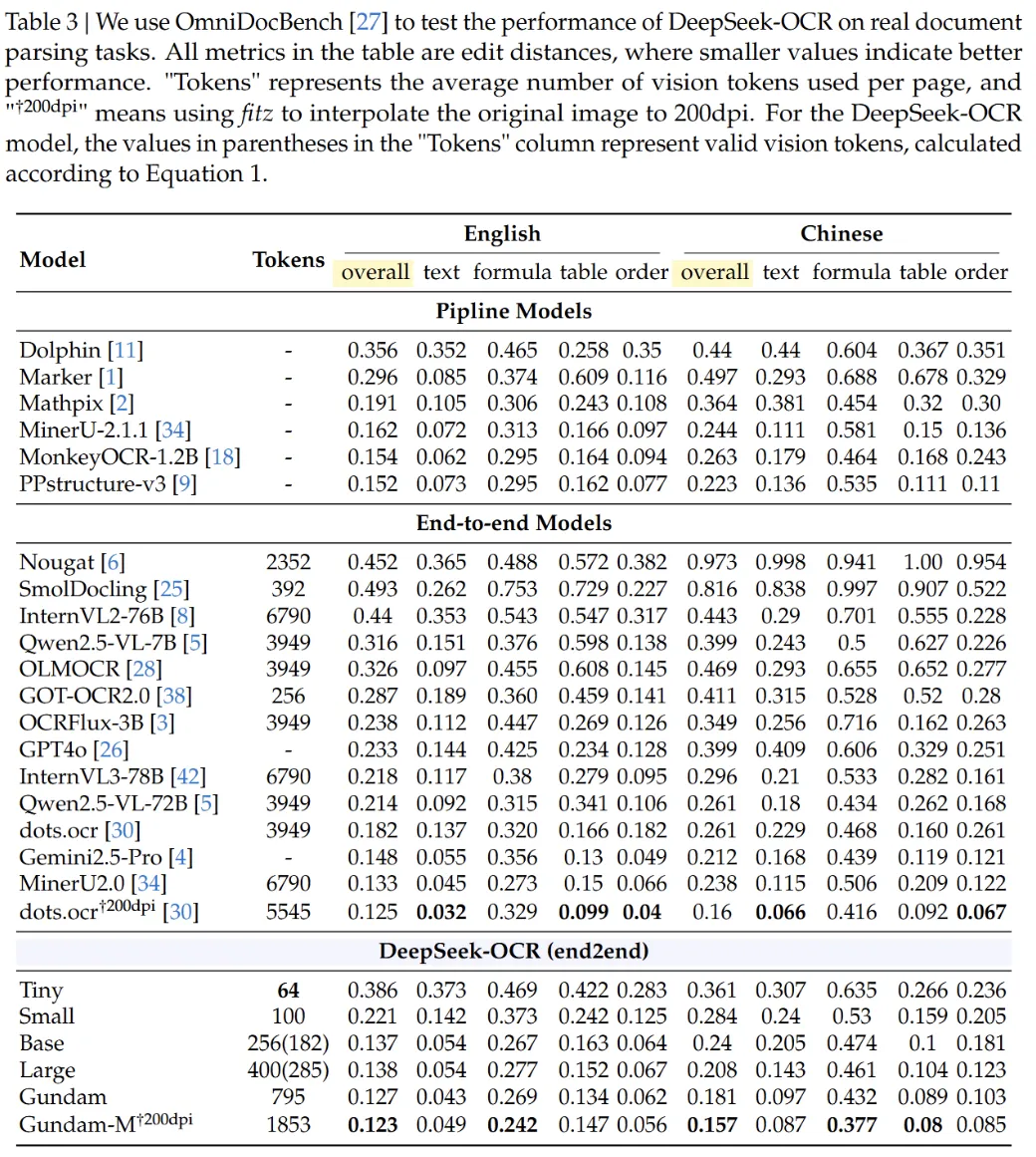
2.识别精度:多维度超越传统方案
在实际应用中,DeepSeek-OCR 展现出了卓越的识别精度:
三、快速掌握 DeepSeek-OCR
1.环境准备:软硬件要求
在开始使用 DeepSeek-OCR 之前,需要准备以下环境:
硬件要求:
GPU:建议使用 NVIDIA GPU(支持 CUDA),最低要求 GTX 1060 或以上,显存至少 4GB,推荐 8GB 或以上(用于处理高分辨率文档)
内存:至少 16GB,推荐 32GB 或以上
软件要求:
操作系统:Linux(推荐)或 Windows 10/11
CUDA:11.8 或以上版本
Python:3.12.9 或以上版本
其他依赖:torch 2.6.0、vllm 0.8.5、flash-attn 2.7.3 等
2.安装步骤:简单三步即可开始
安装 DeepSeek-OCR 非常简单,按照以下步骤操作即可:
1. 克隆 GitHub 仓库:
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git2. 创建 conda 环境:
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr3. 安装依赖包:
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolation
3.模型下载:多种方式任选
下载 DeepSeek-OCR 模型有多种方式:
1. 使用 ModelScope(推荐):
import os
from modelscope import snapshot_download
target_dir = os.path.join(os.getcwd(), 'models')
os.makedirs(target_dir, exist_ok=True)
snapshot_download('deepseek-ai/DeepSeek-OCR', cache_dir=target_dir)2. 直接从 Hugging Face 下载:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('deepseek-ai/DeepSeek-OCR')
3. 从 GitHub 下载:
直接从 DeepSeek-OCR 的 GitHub 仓库下载模型文件
四、开启视觉-文本压缩的新时代
DeepSeek-OCR 的诞生标志着 OCR 技术进入了一个全新的时代。它不仅是一个性能卓越的文字识别工具,更是一种革命性的信息处理范式。通过将文本转化为视觉模态进行压缩和处理,DeepSeek-OCR 为解决大语言模型时代的长文本处理难题提供了优雅的解决方案。
从技术角度看,DeepSeek-OCR 实现了多项突破:16 倍的下采样压缩、10 倍压缩下 97% 的识别精度、复杂内容的智能解析,这些成就使其在众多 OCR 方案中脱颖而出。更重要的是,它证明了 "视觉优先" 的设计理念在信息处理中的巨大潜力。
展望未来,DeepSeek-OCR 的影响将远超 OCR 领域本身。它正在推动整个 AI 产业向 "视觉 - 文本融合" 的新范式演进,为通用人工智能的实现提供了重要的技术路径。对于开发者和企业而言,现在正是拥抱这一技术变革的最佳时机。
正如 DeepSeek 团队在论文中所言,他们的目标是 "探索视觉 - 文本压缩边界"。而我们有理由相信,这个边界将不断被突破,最终实现人类对信息处理效率的终极追求。在这个视觉压缩的新时代,每一个人都可能成为技术进步的受益者和推动者。

中科创新烁智(CSCITech)
更多推荐



 16
16 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)