
等 AI 回复太煎熬?试试刚开源的 LongCat:快到秒回,架构还革新
美团推出5600亿参数开源大模型LongCatAI,采用混合专家(MoE)架构实现高效推理。该模型通过动态选择专家子网络和零计算专家机制,平均仅激活270亿参数,在多项基准测试中表现优异。目前已获超1.2万GitHub星标,30+工具适配,未来计划扩展多模态能力和行业解决方案。
在大模型领域,“高算力、高成本” 一直是开发者和企业前进路上的 “拦路虎”。而如今,美团推出的 LongCat AI,以 5600 亿参数的混合专家(MoE)架构开源模型之姿,带来了一场颠覆性的效率革命,为行业注入全新活力。
一、LongCat 凭速度脱颖而出
在信息爆炸的时代,时间就是金钱,效率决定成败。LongCat 在速度方面的优势,使其在众多 AI 大模型中脱颖而出,成为追求高效的用户的首选。
1.实际应用中的快速响应
在智能客服场景中,用户的问题往往多种多样,需要模型能够迅速理解并给出准确回答。
LongCat 凭借其强大的处理能力,能够在极短的时间内对用户的问题进行分析和处理,快速给出满意的答复。
当用户咨询商品信息、售后服务等常见问题时,LongCat 可以瞬间给出答案,无需用户长时间等待。相比之下,其他一些模型可能需要较长时间来生成回复,导致用户体验不佳。
在文本生成任务中,如撰写新闻稿件、故事创作等,LongCat 也能快速完成任务。例如,给定一个新闻主题,LongCat 可以在短短几分钟内生成一篇结构完整、内容丰富的新闻稿件,大大提高了工作效率。而其他模型可能需要花费更多的时间来构思和组织语言,无法满足对速度要求较高的场景。
2.速度背后的技术支撑
LongCat 之所以能够实现如此快速的推理,离不开其背后强大的技术支撑。
在算法优化方面,LongCat 采用了先进的算法架构,能够对输入的数据进行高效处理。其独特的模型架构设计,使得模型在计算过程中能够更加快速地进行参数更新和推理计算,从而提高了整体的运行速度。LongCat 还对算法进行了针对性的优化,减少了不必要的计算步骤,进一步提升了计算效率。
在硬件适配方面,LongCat 充分利用了最新的硬件技术,与高性能的计算设备进行了深度适配。通过优化硬件资源的利用,LongCat 能够充分发挥硬件的性能优势,实现快速的推理计算。例如,在使用 GPU 进行计算时,LongCat 通过优化 GPU 的调度和并行计算策略,使得 GPU 的计算能力得到了充分发挥,从而大大提高了模型的推理速度。
二、ScMoE 与全流程训练的技术突破
1.全新架构解析
Ling-1T 在语言学习领域展现出了巨大的应用潜力。作为一个拥有20T+ toke
LongCat 采用了创新性的混合专家(Mixture-of-Experts,MoE)架构 ,总参数达 560 亿。在这个架构中,模型就像是一个拥有众多专业顾问的团队,每个顾问都是一个专家子网络,擅长处理特定类型的任务。当模型接收到输入时,它会根据输入的特点,动态地选择最合适的专家子网络来进行处理。这种动态选择机制,使得模型能够更加高效地利用计算资源,避免了不必要的计算浪费。
为了更直观地理解,我们来看一个简单的示意图:
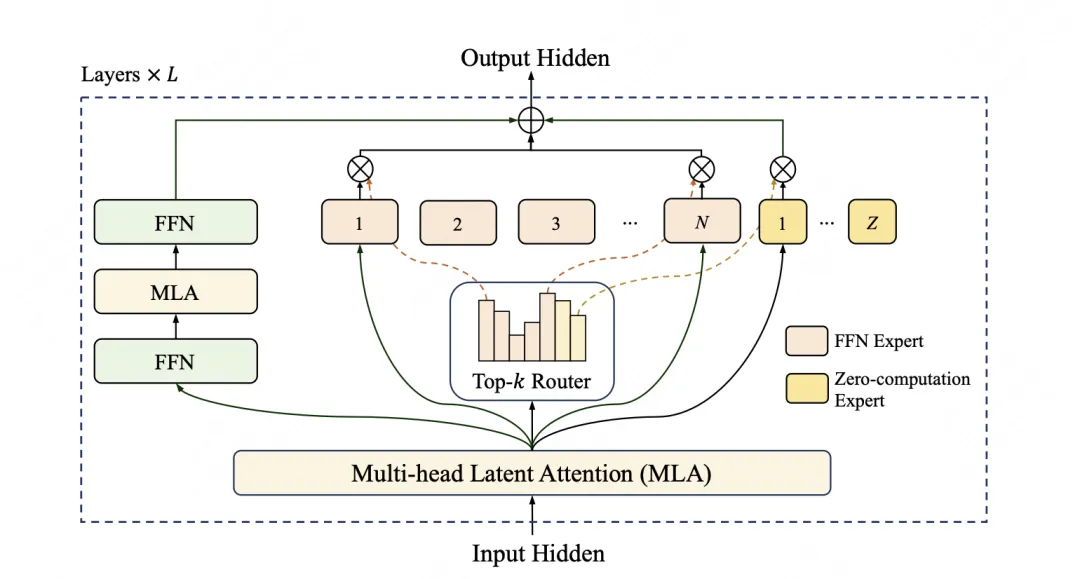
在图中,我们可以看到,输入文本首先经过一个路由器(Router),路由器会根据文本的特征,将其分配到不同的专家子网络(Expert 1、Expert 2、Expert 3 等)中进行处理。这些专家子网络会根据自己的专长,对输入文本进行分析和处理,然后将结果返回给路由器。路由器再将各个专家子网络的结果进行整合,最终输出模型的回答。
在这个架构中,还有一个关键的创新点 —— 零计算专家(Zero-computation Experts)机制 。这种机制能够智能判断输入内容的重要性,将计算量较小的任务,如常见词汇、简单标点等处理,分配给 “零计算” 专家。这个特殊的 “专家” 并不进行复杂运算,而是直接返回输入,从而极大程度地减少了不必要的算力消耗。在处理每个词元(token)时,模型仅需动态启动 186 亿至 313 亿参数,平均约 270 亿,巧妙地实现了性能与效率之间的精妙平衡。
2.基准测试中的性能印证
基准测试是检验模型实力的 “试金石”,LongCat AI 在各项测试中均展现出强劲实力。
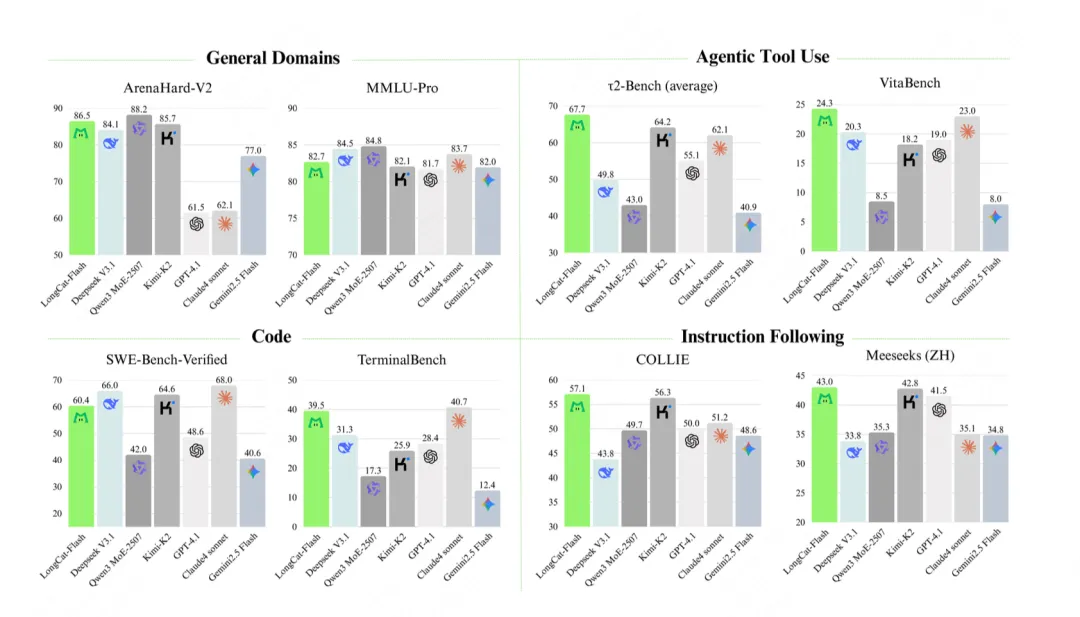
在通用能力的 MMLU 测试中,得分为 89.71,虽略低于 DeepSeek V3.1 的 90.96,但参数效率提升 40%;指令遵循的 IFEval 测试里,它以 89.65 的得分超越 DeepSeek V3.1 的 86.69,甚至超过 GPT-4.1 等主流模型;数学推理的 MATH500 测试中,96.40 的得分略高于 DeepSeek V3.1 的 96.08,复杂计算准确率领先;Agent 工具使用的 τ²-Bench (电信) 测试,73.68 的得分是 DeepSeek V3.1 38.50 得分的 1.6 倍;在中文指令的 COLLIE 测试中,57.10 的得分远超 DeepSeek V3.1 的 43.80,中文场景适配性位居第一。
三、当下热度与未来布局
从当前生态进展来看,LongCat AI 已展现出强劲的行业吸引力:开源仅 7 天,GitHub 星标数量就突破 1.2 万,成为同期开源大模型中关注度最高的项目之一;同时已有 30 + 第三方工具完成适配,涵盖微调框架(如 LoRA 微调工具)、可视化平台(模型性能监控面板)、部署插件等,开发者可直接基于现有工具快速上手,降低开发成本。
未来路线图更值得期待:美团计划在 2026 年 Q1 推出 LongCat AI 多模态版本,实现文本、图像、音频等多类型数据的协同处理;2026 年 Q2 将上下文长度扩展至 256K tokens,进一步提升长文本处理能力;此外还将接入工业级 API 工具库,覆盖金融、医疗、制造等垂直领域,推动大模型从 “通用工具” 向 “行业解决方案” 升级。


中科创新烁智(CSCITech)
更多推荐



 24
24 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)