
阿里发布Qwen3-Next:训练成本暴降90%,推理速度提升10倍的AI新巅峰!
阿里巴巴通义实验室开源Qwen3-Next基础模型架构及Qwen3-Next-80B-A3B系列模型。该架构采用混合注意力机制(75%线性注意力+25%门控注意力)与高稀疏MoE设计(800亿参数仅激活30亿),实现计算效率与性能的平衡。性能方面,指令模型媲美更大规模旗舰模型,推理模型优于谷歌Gemini-2.5-Flash,训练成本降低90%,推理速度提升10倍,支持百万级上下文输入。提供Ins
阿里巴巴通义实验室正式发布并开源了新一代基础模型架构——Qwen3-Next,以及基于该架构的Qwen3-Next-80B-A3B系列模型。这一突破性技术将大语言模型的效率推向了新的高度,被誉为AI领域的“性价比新标杆”

革命性架构:混合注意力机制+高稀疏MoE
Qwen3-Next架构的核心创新在于其混合注意力机制和高稀疏度MoE结构(混合专家系统)。这一设计完美平衡了计算效率与模型性能。

新架构中,75%的神经网络层采用Gated DeltaNet线性注意力机制,专门优化长文本处理,内存占用近似线性增长;其余25%则采用原创的门控注意力机制(Gated Attention),确保关键信息不丢失,提高了长文本生成的准确性。
这种混合设计解决了传统模型在长文本处理上面临的算力瓶颈,将计算复杂度从二次方降低至线性水平,在保持强大性能的同时大幅提升了效率。
Qwen3-Next采用了极高稀疏度的MoE架构:
-
总参数量达到800亿
-
每次推理仅激活约30亿参数
-
激活比达到惊人的1:50,创下业界新高
-
配备了512个专家模块,每次推理只动态路由少量专家
这种设计使得模型在保持强大能力的同时,计算效率显著提升,帮助用户实现“极致省钱”。
性能表现:媲美顶级旗舰模型
Qwen3-Next的性能表现令人惊叹:
-
指令模型(Instruct) 性能与参数规模更大的Qwen3-235B旗舰模型持平
-
推理模型(Thinking) 表现优于谷歌闭源模型Gemini-2.5-Flash-Thinking
-
在数学推理基准测试AIME25中取得了87.8分的高分
-
在编程能力评测LiveCodeBench v6中表现出色

效率提升:训练成本降90%,推理速度快10倍
Qwen3-Next在效率方面的提升更为惊人:
-
训练成本较密集模型Qwen3-32B降低90%以上
-
长文本推理吞吐量提升10倍以上
-
预训练仅需15T tokens,只需Qwen3-32B所用GPU计算资源的9.3%
-
支持百万级Tokens的超长上下文输入
特别是在32K以上长上下文处理中,新模型在预填充阶段吞吐量提升10倍以上,解码阶段也保持10倍以上的速度优势。
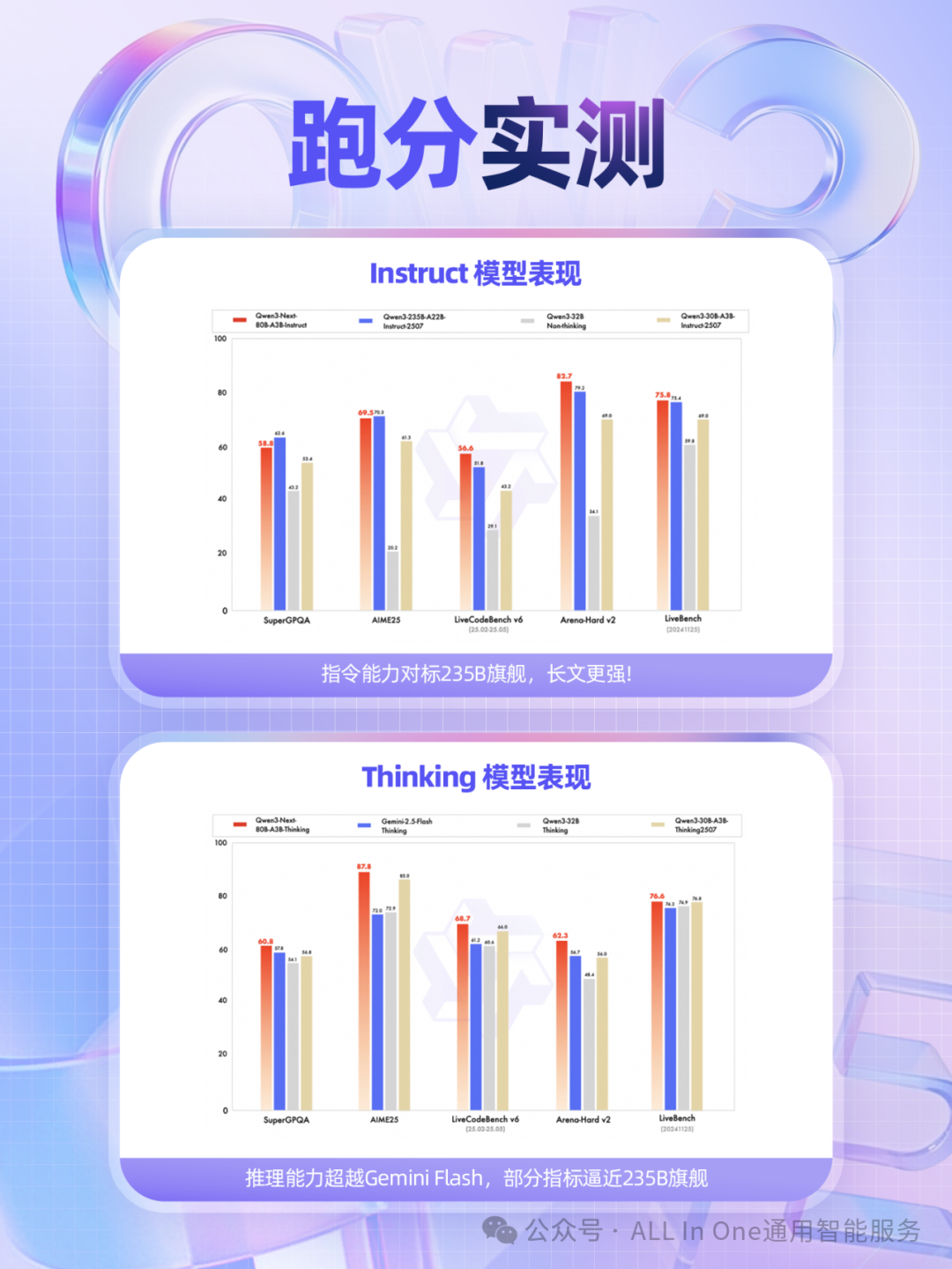
两个版本:Instruct与Thinking
Qwen3-Next提供了两个专门优化的版本:
-
Instruct版本:更擅长理解和执行指令,不输出思考轨迹,格式稳定,便于集成到产品化场景(如客服、表单生成、结构化输出)
-
Thinking版本:更擅长多步推理和深度思考,默认包含思考轨迹,在复杂逻辑、数学推导和编程任务中表现更佳
开发者可以根据实际需求选择适合的版本,甚至可以在RAG/Agent中按任务类型动态路由到不同版本。
技术创新的深远影响
Qwen3-Next的发布不仅仅是一个模型的升级,更代表了大模型技术发展的重要方向。它证明了通过架构创新可以在不增加计算负担的情况下大幅提升模型性能,为AI技术的普及和应用提供了新的可能性。
通义千问大模型负责人林俊旸表示,团队已经在混合模型和线性注意力机制上进行了大约一年的实验。Gated DeltaNet加混合是经过大量尝试和错误才实现的,而Gated Attention的实现就像是“免费的午餐”,可以获得额外好处。
Qwen3-Next的发布标志着大语言模型进入了一个新的发展阶段。它不仅在性能上取得了突破,更在实用性、可用性和可及性方面带来了重大进步。
随着AI技术的不断演进,Qwen3-Next这样的高效模型将为更多开发者和企业提供强大的AI能力,推动整个行业的创新与发展。

中科创新烁智(CSCITech)
更多推荐

 6
6 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)