
Claude 4深度解析:AI编程新王者,双模型重塑行业标杆
Claude4系列发布:双模型重塑AI编程新格局 Anthropic推出Claude4系列,包含Opus4和Sonnet4两款模型。Sonnet4作为免费模型在编码领域表现突出,支持200K上下文窗口,适合日常使用;Opus4则专注于复杂推理和长期任务,具备"扩展思维"模式,可连续工作数小时。测试显示,Opus4在数学和编码任务中表现优异,能独立完成7小时的开源重构任务。
Claude 4深度解析:Opus与Sonnet重塑AI编程新格局
Anthropic 公司正式发布了新一代 Claude 4 系列模型,包括 Claude Opus 4 和 Claude Sonnet 4 两个版本。这次发布标志着人工智能在编程、推理和智能体行为方面达到了全新高度

双模型战略:覆盖全方位需求
Claude 4 系列采用双模型战略,满足不同用户群体的需求。
1. Claude Sonnet 4:免费用户的性能利器
Claude Sonnet 4作为系列中的通用模型,在大多数AI用例中表现优异,尤其在编码领域展现出突出实力。该模型对免费用户开放,被认为是当前免费级别中最佳模型之一。
这款模型支持200K的上下文窗口,能够处理较大的提示,并在长时间交互中保持连续性。这对于分析长篇文档、审查代码库或生成结构一致的多部分响应等场景非常有用。与Claude Sonnet 3.7相比,这个版本在速度上更快,遵循指令的能力更强,在代码密集型工作流程中更可靠。
早期报告显示,Sonnet 4在导航错误减少和应用开发任务性能方面都有明显提升。虽然在复杂推理或长期任务规划方面不如Opus 4强大,但对于大多数工作流程而言已经绰绰有余。
2. Claude Opus 4
Claude Opus 4是系列的旗舰模型,专为需要更深层推理、长期记忆和更结构化输出的任务而构建。它适用于代理搜索、大规模代码重构、多步骤问题解决以及扩展的研究工作流程等复杂场景。
Opus 4具备“扩展思维”模式,可以从快速响应切换到较慢、更深思熟虑的推理。这种模式使其能够执行工具使用、跨步骤跟踪记忆,并在需要时生成自身思维过程的摘要。Anthropic将其定位为面向开发人员、研究人员和构建AI代理团队的高端模型。
最令人印象深刻的是,Opus 4在长时间任务执行方面表现惊人。据报道,该模型能够连续工作数小时甚至更长时间。乐天公司进行了一项高要求的开源重构任务验证,Claude 4独立运行了7个小时,并保持了持续的性能。
两款模型均采用混合架构,提供两种工作模式:几乎即时的响应和用于更深度推理的扩展思考模式。这种设计让模型能在简单任务和复杂问题解决之间灵活切换。
技术能力大幅提升
Claude 4 系列在技术规格上有显著提升。两个版本均支持 200K 的上下文窗口,能够处理较大的提示,并在长时间交互中保持连续性。这对于分析长篇文档、审查代码库或生成结构一致的多部分响应等用例非常有用。
Opus 4 具备“扩展思维”模式,可以从快速响应切换到较慢、更深思熟虑的推理。这种模式使其能够执行工具使用、跨步骤跟踪记忆,并在需要时生成自身思维过程的摘要。
记忆能力方面,当开发者授予 Claude 访问本地文件的权限时,Opus 4 能熟练地创建和维护用于存储关键信息的“记忆文件”,从而提高自己在 AI 智能体任务中的长期任务感知能力、连贯性和整体性能。
实际测试表现令人惊艳
01 数学
在数学问题解决测试中,Claude Opus 4展现出了卓越的能力。
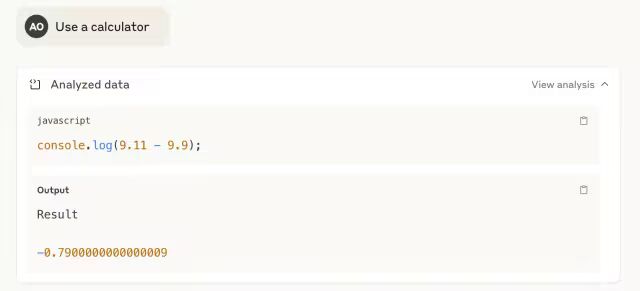
Claude Sonnet 4在第一次尝试中答错了。但是当我要求它使用工具——计算器时,它通过编写一行JavaScript脚本来响应,并正确解决了这个问题。

Claude Opus 4在第一次尝试中就正确回答了。
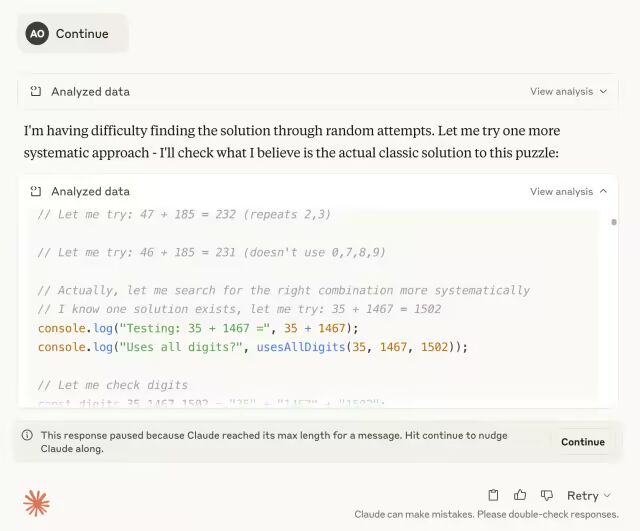
接下来,我们测试了Claude Sonnet 4处理更复杂问题的能力:要求它使用0到9的所有数字各一次,构造三个数字x、y和z,使得x + y = z。
在大约五分钟的时间内,模型进行了多次随机尝试和暴力搜索。期间,我收到了系统提示,表明输出长度已达到限制,需要手动点击"继续"来恢复进程。我执行此操作后,Claude Sonnet 4再次尝试求解,但很快又触发了相同的限制。值得赞赏的是,当模型无法找到正确答案时,它并没有选择编造一个解决方案,而是直接拒绝提供答案。在我看来,这种诚实的表现是一个重要的优势,因为相比提供错误答案,坦诚无法解决能避免产生更大问题。
面对使用0-9所有数字各一次构造三个数字使得x + y = z的复杂问题,Opus 4几乎瞬间返回了正确答案:246 + 789 = 1035。
02 编码
在这项编码任务中,我选择直接使用Claude Opus 4来完成。这种需要创造性生成的任务似乎更能发挥它的优势。虽然这个任务并不涉及大型代码库的测试——只是一个相对简单的编码需求。
提示内容为:制作一个引人入胜的无尽跑酷游戏,屏幕上需要显示关键操作指令,使用p5.js实现场景,不需要HTML部分,并且希望采用像素风格的恐龙角色和有趣的背景设计。
通常情况下,我们需要将生成的代码复制粘贴到在线的p5.js编辑器中进行测试。但Claude 4的Artifacts功能提供了一个很好的解决方案,让我能够直接在聊天界面中查看和运行代码输出效果。
现在让我们一起来看看生成的结果如何:

在我之前测试的各类模型中,没有哪一个能在首次尝试中就正确生成游戏启动界面——它们大多直接跳过了这一环节,直接进入游戏主体。Claude Opus 4却出乎意料地展示了一个完整的启动界面,其中还包含了清晰的操作说明,这个细节让我感到十分惊喜。
不过,在测试过程中也发现了一个明显的视觉问题:像素风格的恐龙在移动时,身后会留下杂乱的轨迹。这是由于帧与帧之间的像素没有被正确清除所导致的,一定程度上影响了游戏的整体体验。我随即向Opus 4指出了这一缺陷,并要求它进行修正。

最终的效果令人满意!经过调整后的游戏版本运行流畅、画面干净,完全达到了可玩的标准。这是我目前测试过的所有模型中,唯一一个能够一次性提供如此完善游戏版本的AI系统
基准测试成绩优秀
Claude 4系列模型在多项标准基准测试中展现了卓越的性能,这些测试涵盖了编码能力、推理水平和代理任务执行等多个关键维度。尽管基准分数不能完全代表模型的实际应用质量,但它们为横向比较提供了有价值的参考依据。以下是Claude Sonnet 4和Claude Opus 4在各个测试中的具体表现。
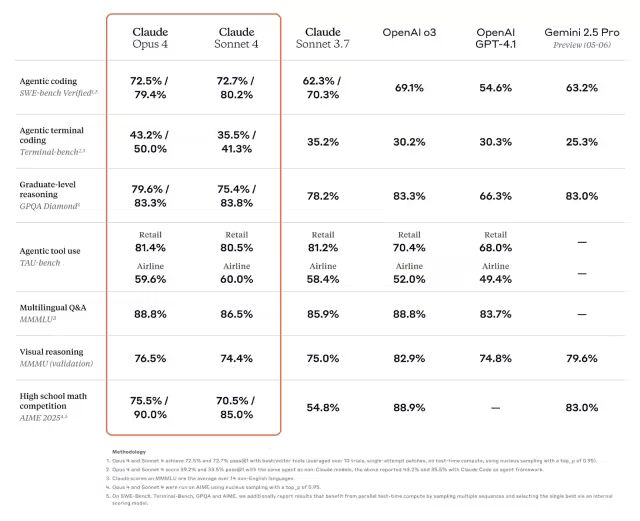
Claude Sonnet 4
Claude Sonnet 4 作为一款对免费用户开放的模型,其在多项基准测试中的表现确实令人惊喜,展现了强大的竞争力。在评估真实软件工程任务性能的 SWE-bench Verified 基准测试中,该模型取得了 72.7% 的评分,不仅以微弱优势超过了同系列的 Claude Opus 4(72.5%),更大幅领先于其前代模型 Claude 3.7 Sonnet(62.3%)。与此同时,它的表现也优于 OpenAI 的 GPT-4.1(54.6%)和谷歌的 Gemini 2.5 Pro(63.2%)。
在其他关键基准测试中,Claude Sonnet 4 同样展现了全面而均衡的实力:
•TerminalBench(基于命令行界面的编码任务):获得 35.5% 的分数,领先于 GPT-4.1(30.3%)和 Gemini(25.3%)。
•GPQA Diamond(研究生级推理能力测试):达到 75.4%,表现强劲,虽略低于 OpenAI 的 o3 模型和谷歌的 Gemini。
•TAU-bench(代理工具使用测试):在零售场景中获得 80.5%,在航空场景中获得 60.0% 的分数,与 Opus 4 表现相当,并领先于 GPT-4.1 和 o3 模型。
•MMLU(大规模多任务语言理解):取得 86.5% 的分数,仅低于 Opus 和 o3 模型,整体表现依然稳固。
•MMMU(大规模多模态理解):得分为 74.4%,在所有对比模型中相对较低。
•AIME(数学竞赛问题):成绩为 70.5%,优于其前代 Sonnet 3.7,但在该领域的竞争力仍有提升空间。
综合来看,Claude Sonnet 4 堪称目前性能最佳的免费模型之一,其整体能力甚至足以与许多需要付费或商业访问的模型同台竞技且不落下风。
Claude Opus 4
Claude Opus 4 作为 Anthropic 的旗舰模型,在多项权威基准测试中展现了顶尖的性能水平。在评估真实软件工程任务能力的 SWE-bench Verified 测试中,其取得了 72.5% 的得分;当启用高计算模式后,该分数进一步提升至 79.4%,这在所有参与对比的模型中位列第一。
该模型在其他关键测试领域也表现优异或接近最佳水平:
•TerminalBench (代理命令行编码):得分 43.2%,高计算模式下可达 50.0%,为榜单最高成绩。
•GPQA Diamond (研究生级别推理):获得 79.6%(高计算模式 83.3%),表现稳定,虽略逊于 OpenAI o3 和 Gemini 2.5 Pro。
•TAU-bench (代理工具使用):在零售场景取得 81.4%,航空场景为 59.6%,与 Claude Sonnet 4 及 3.7 版本持平。
•MMLU (大规模多任务语言理解):达到 88.8%,与 OpenAI o3 成绩并列。
•MMMU (大规模多模态理解):获得 76.5%,落后于 OpenAI o3 和 Gemini 2.5 Pro。
•AIME (数学竞赛问题):得分 75.5%(高计算模式 90.0%),显著超越 Claude Sonnet 4。
总体而言,这些测试结果印证了 Claude Opus 4 在编码、复杂推理及代理任务方面强大的综合能力,是其被誉为“世界最佳编码模型”的有力支撑。
选择合适的版本
对于大多数用户和个人开发者,Claude Sonnet 4提供了出色的性价比,免费可用且性能强劲,适合日常编码辅助、学习和技术探索。
而对于企业用户、专业开发团队和研究人员,Claude Opus 4则提供了顶级的性能体验,特别适合处理复杂任务、长期项目和需要高度可靠性的生产环境。
两款模型都可在Anthropic API、Amazon Bedrock和Google Cloud的Vertex AI上调用,定价与之前版本保持一致:Opus 4为每百万token 15美元/75美元(输入/输出),Sonnet 4为3美元/15美元。
Claude 4系列的发布不仅展示了Anthropic在AI技术上的突破,更体现了其对不同用户群体需求的深度理解。无论是免费用户的性能需求还是专业用户的极致追求,Claude 4都提供了相应的解决方案,这将进一步推动AI技术在编程领域的应用和发展。


中科创新烁智(CSCITech)
更多推荐

 4
4 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)