
80 亿参数干翻 GPT-4o?快手开源 Keye-VL-1.5,视频 AI 终于 “看得懂、抓得准、想得透”!
快手开源多模态模型Keye-VL-1.5突破视频AI三大瓶颈:128K超长上下文处理数小时视频、0.1秒级精准时序定位、跨模态逻辑推理能力。该模型通过Slow-Fast双路编码、3DRoPE定位等技术,在视频理解专项测试中超越GPT-4o,同时具备图文理解等通用能力。应用场景覆盖短视频精准推荐、智能剪辑,以及教育、医疗、安防等领域。尽管当前仍存在音频理解等提升空间,其开源标志着视频AI进入&quo
刷短视频时,有没有过这些糟心时刻?
推荐的内容总踩不到兴趣点,
明明刷的是美食,却推来一堆游戏;
想剪一段高光片段,翻遍 10 分钟视频才找到 3 秒亮点;
平台审核半天,却漏过明显的违规画面……

这些问题的根源,其实是传统视频 AI “看不懂” 视频 —— 要么抓不住长视频的上下文,要么定不准关键画面的时间,更别说分析画面背后的逻辑。但现在,快手刚开源的多模态模型 Keye-VL-1.5,直接把视频 AI 的能力拉到了新高度:128K 超长上下文(能啃下几小时长视频)、0.1 秒级时序定位(精准到小数点后一位)、还能像人一样 “推理” 画面逻辑。
今天就带大家拆解这款 “视频理解新标杆”,看看它到底强在哪,又能给我们的生活带来哪些改变。
1.短视频爆发的 “痛点”,终于被破局了?
先说说行业现状:现在每天有上亿条短视频被上传、消费,但视频 AI 的能力却没跟上。
传统模型要么只能处理静态图片,面对动态视频的 “时间维度” 直接懵;要么上下文窗口太小,超过 10 分钟的视频就 “记不住” 细节;更头疼的是,短视频信息密度极高,一秒一个镜头,模型根本来不及捕捉关键信息。
就算是近年的多模态大模型(比如 GPT-4o、Gemini),在视频理解上也有短板:要么时序定位模糊(只能说 “在第 20 秒左右”),要么推理能力弱(只能描述画面,说不出 “为什么”)。
而快手的 Keye-VL-1.5,一出手就解决了这三大核心问题:
128K 上下文:能处理长达数小时的视频,比如一部电影、一场直播全程
0.1 秒级定位:26 秒短视频里,能精准找出 “包出现的时间是 22.3-23.8 秒”
跨模态推理:看宠物视频时,不仅能看到 “大狗咬小狗耳朵”,还能分析 “这是狗爸在纠正小狗的不当行为”。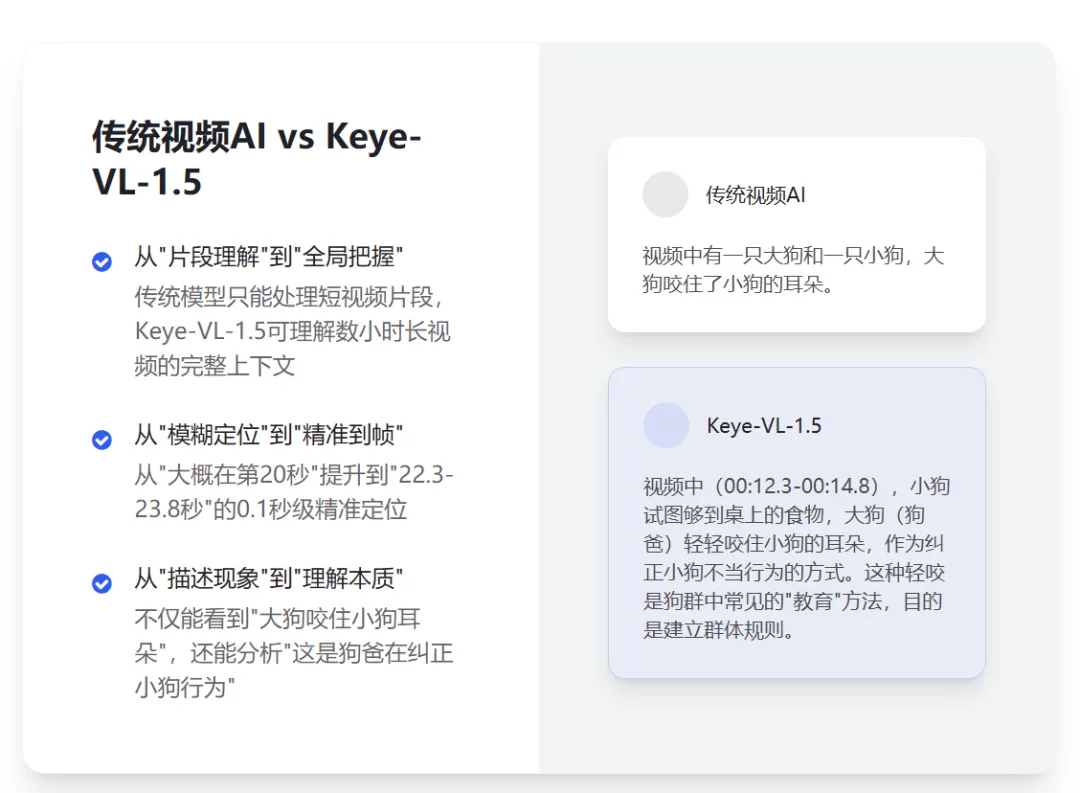
更关键的是,它还开源了!开发者、创作者都能免费用上这款 “视频理解神器”。
2.3 大技术创新:让 AI 从 “看视频” 到 “懂视频”
Keye-VL-1.5 的厉害,不是靠堆参数(仅 80 亿参数,比很多大模型小一圈),而是靠精准的技术设计。其中最核心的,是这 3 个 “黑科技”:
a.Slow-Fast 双路编码:长视频也能 “省内存还抓细节”
看长视频时,最大的问题是 “帧太多,处理不过来”—— 如果每帧都用高分辨率分析,内存直接爆掉;如果压缩分辨率,又会漏掉细节。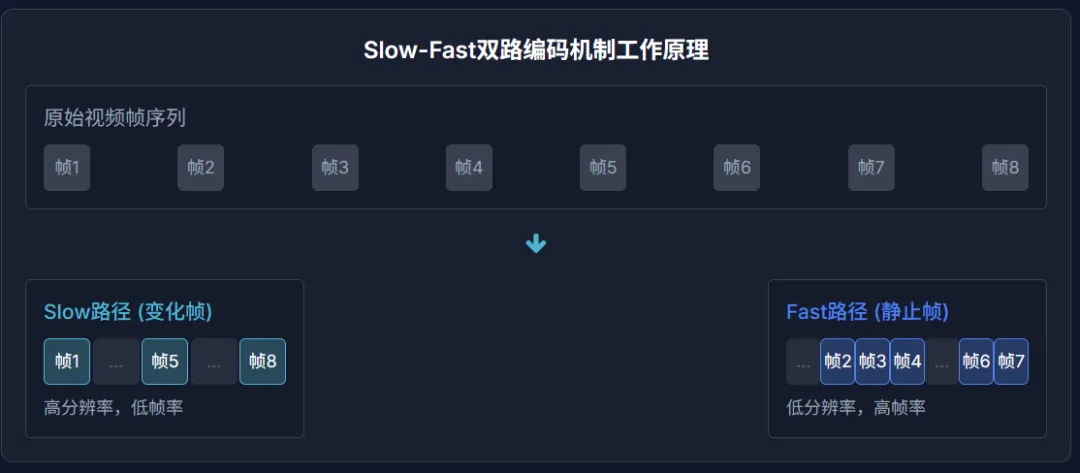
Keye-VL-1.5 的解法很聪明:把视频帧分成 “慢帧” 和 “快帧”。
慢帧:画面变化大的帧(比如镜头切换、人物动作),保留高分辨率,重点分析。
快帧:画面几乎不变的帧(比如静态背景),只用 30% 的 “计算预算”,快速过一遍。
同时还会插入 “时间戳”,确保帧的顺序不混乱。
这样一来,既能处理 128K tokens 的超长上下文(相当于几小时视频),又不会牺牲细节,计算效率直接拉满。
b.0.1 秒级时序定位:精准到 “帧” 的 “视频放大镜”
以前的模型定位画面,最多精确到 “秒”,比如 “包在 22-23 秒出现”。但 Keye-VL-1.5 能做到小数点后一位 ——22.3-23.8 秒。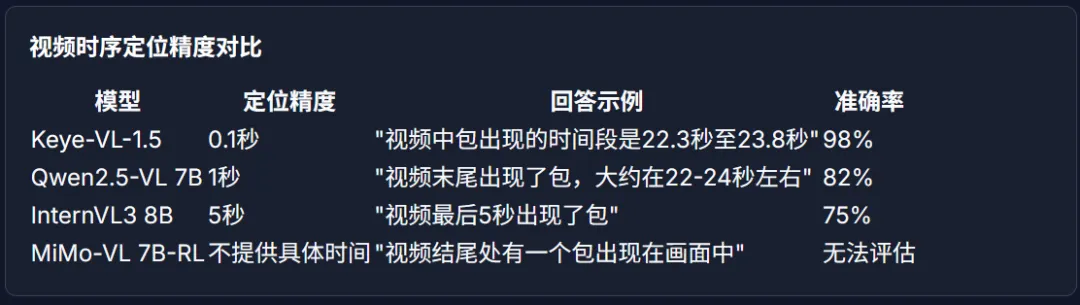
这背后靠的是 “3DRoPE 编码”:给传统的 “空间位置”(比如画面里包的坐标)加了一个 “时间维度”,让文字描述和视频帧能按时间精准对齐。
举个测试案例:一段 26 秒的短视频,问 “包出现的时间段”,其他模型要么说 “22-23 秒”(不准),要么只描述画面(不说时间),只有 Keye-VL-1.5 给出了 “22.3-23.8 秒” 的精准答案。
c.跨模态推理:AI 不仅 “看得懂”,还能 “想明白”
最让人惊艳的是它的推理能力。普通模型看视频,只能 “复述” 画面:“大狗咬住了小狗的耳朵”。但 Keye-VL-1.5 能分析背后的逻辑:
“视频中,小狗试图够到桌上的食物,大狗(狗爸)轻轻咬住小狗的耳朵,作为纠正小狗不当行为的方式。这种轻咬是狗群中常见的‘教育’方法……”
这能力不是天生的,而是靠三阶段训练 “练” 出来的:
先用 7.5 万组问答数据打基础,再用 “强化学习” 让模型学会判断 “答案好不好”,最后针对 “指令理解、安全、逻辑” 做专项优化。
甚至对复杂问题,还会用 “5 级提示”(从概念到完整答案)逐步引导,确保推理不跑偏。
3.性能有多能打?80 亿参数硬刚 GPT-4o
光说技术不够,得看实际表现。Keye-VL-1.5 在多个权威测试里,都交出了 “碾压级” 答卷:
a.视频理解专项:领先开源模型
在视频领域最核心的测试(Video-MME)里,它拿了 73.0 分 —— 不仅远超同参数的 Qwen2.5-VL(65.1 分)、MiMo-VL(68.9 分),甚至超过了闭源的 GPT-4o(71.9 分)。
另一项长视频测试(LongVideoBench),它也以 66.0 分领先,证明 “处理长视频” 的能力是真的强。
b.通用多模态:不偏科的 “全能选手”
不仅视频强,在图文理解、数学推理这些 “通用题” 上,它也很能打: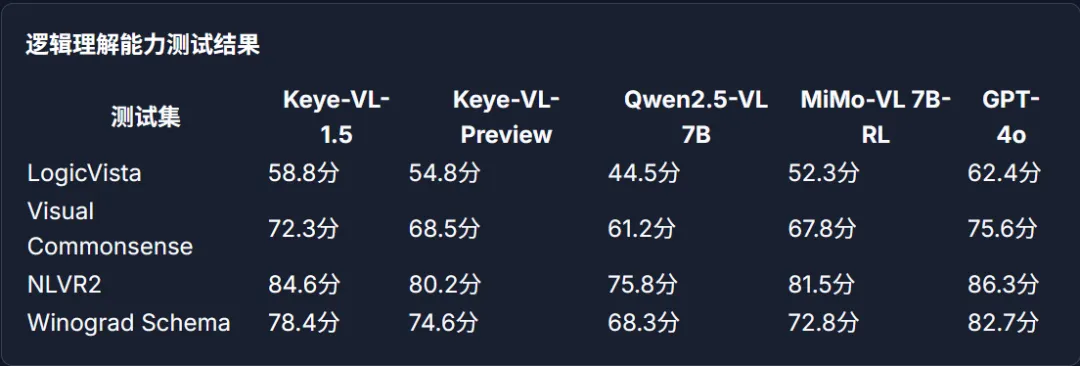
OpenCompass 测试(综合多模态能力):79.5%,超过 GPT-4o(72.0%)、Claude 3.7(70.1%);
AI2D 测试(二维推理):86.7%,远超 GPT-4o 的 82.6%;
数学测试(MathVistaMINI):81.2 分,比 Qwen2.5-VL(66.8 分)高了 14 分多。
要知道,它只有 80 亿参数,却能在 “专项” 和 “通用” 上同时打赢更大规模的模型,性价比直接拉满。
4.能用来做什么?从短视频到多行业的 “AI 助手”
Keye-VL-1.5 的开源,不是 “技术炫技”,而是真的能落地到我们的生活里。
a.短视频平台:刷得更爽、剪得更快
推荐更精准:模型能深度理解视频内容,比如你喜欢 “露营 + 美食”,就不会推 “纯露营” 或 “纯美食”。
创作更轻松:自动生成吸睛标题(比如 “22 秒教你做露营版三明治”)、智能剪辑高光片段(直接提取 3 秒煎蛋特写)。
审核更高效:0.1 秒定位违规画面(比如一闪而过的不良标识),减少人工成本。
b.跨行业:从教育到安防的 “多面手”
教育:自动分析教学视频,提取知识点(比如 “第 5.2-7.8 秒讲勾股定理应用”),生成学习大纲。
医疗:辅助分析医学影像视频(比如 CT 动态影像),帮医生定位异常区域。
安防:实时监控视频里,精准识别 “有人翻越围墙” 的时间(比如 18:05:22.3-22.8 秒),快速预警。
5.未来会更好吗?还有这些 “小目标”
虽然 Keye-VL-1.5 已经很强,但快手团队也说了,还有进步空间:
补全 “音频理解”:现在主要看画面,未来会加入音频分析(比如识别视频里的哭声、警报声)。
升级 “生成能力”:不仅能 “看懂” 视频,还能 “生成” 视频(比如根据文字描述自动做短视频)。
挑战 “更长视频”:现在能处理几小时,未来目标是 “几天的视频”(比如全程监控录像)。
最后:AI 懂视频,到底意味着什么?
Keye-VL-1.5 的开源,不止是一款模型的发布,更是给整个行业开了个好头 —— 它证明 “视频 AI” 不用靠堆参数,靠精准的技术设计和落地导向,也能做到 “又强又实用”。
对我们普通人来说,未来可能会更爽:刷短视频更对味,剪视频不用熬夜,甚至看病、学习时,AI 都能帮我们 “精准抓重点”。
你觉得 AI “看懂视频” 后,最有用的功能是什么?是自动剪视频,还是精准推荐?评论区聊聊你的想法~


中科创新烁智(CSCITech)
更多推荐

 12
12 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)