
深度学习模型的服务化高并发部署--以Nginx+gunicorn+flask为例的docker部署方案
机器学习模型的服务化高并发部署--以Nginx+gunicorn+flask的docker部署方案欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰
机器学习模型的服务化高并发部署--以Nginx+gunicorn+flask为例的docker部署方案
0.前言
机器学习模型训练完成后如何让其他人使用是一个工程化的问题,也许我们的用户是没有一点机器学习的基础,我们让他们独自完成模型的部署是十分困难的,这时候我们可以考虑为他们提供一种服务,他们并不需要关心怎么实现的,只需要简单的调用我们提供的服务接口便可以实现自己的需求,这便是模型服务化的部署过程。
机器学习模型部署是一个复杂的工程化问题,本部分为了简单化模型的部署过程,主要介绍简单的Nginx+gunicorn+flask的docker部署方案。
1. flask部署机器学习模型
flask介绍
Python 现阶段有三大主流Web框架,分别是Django、Tornado、Flask :
- Django主要特点是大而全,集成了很多组件,例如: Models Admin Form 等等, 不管你用得到用不到,反正它全都有,属于全能型框架;
- Torando主要特点是原生异步非阻塞,在IO密集型应用和多任务处理上占据绝对性的优势,属于专注型框架;
- Flask主要特点小而轻,原生组件几乎为0, 三方提供的组件请参考Django 非常全面,属于短小精悍型框架。
在这里我们选用的是flask,这里主要介绍一下flask:
Flask 是一个 web 框架,也就是说 Flask 为你提供工具、库和技术来允许你构建一个 web 应用程序。这个 wdb 应用程序可以使一些 web 页面、博客、wiki、基于 web 的日历应用或商业网站。
Flask 属于微框架(micro-framework)这一类别,微架构通常是很小的不依赖于外部库的框架。这既有优点也有缺点,优点是框架很轻量,更新时依赖少,并且专注安全方面的 bug,缺点是你不得不自己做更多的工作,或通过添加插件增加自己的依赖列表,但是简单的部署服务也是可行的。
安装依赖
在模型flask部署的过程中,主要需要以下的python依赖包:
Flask
numpy
torch
torchvision
pillow
模型推理
这里以resnet模型为例进行介绍,可以使用这个训练好的模型权重(权重网址(k9rb),如下式使用该模型进行推理的代码:
# -*- encoding: utf-8 -*-
import json
import torch
import numpy as np
from PIL import Image
from torchvision import transforms, models
data_trans = transforms.Compose([transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
def thresh_sort(x, thresh):
idx, = np.where(x > thresh)
return idx[np.argsort(x[idx])]
# 加载模型部分
def init_model():
resnet = models.resnet50()
num_ftrs = resnet.fc.in_features
resnet.fc = torch.nn.Linear(num_ftrs, 20)
resnet.load_state_dict(torch.load('model.pth',
map_location='cpu'))
for param in resnet.parameters():
param.requires_grad = False
resnet.eval()
return resnet
def make_prediction(path):
img = Image.open(path)
img_trans = data_trans(img).unsqueeze(0)
output = model(img_trans)
output = output[0].numpy().ravel()
labels = thresh_sort(output, 0.5)
if len(labels) == 0 :
label_array = "No Categories"
status = 0
else:
label_array = [cat_to_name[str(i)] for i in labels]
status = 1
return label_array, status
if __name__ == '__main__':
# 初始化,预加载完成模型
model = init_model()
# 类别信息
with open('class_name.json', 'r') as f:
cat_to_name = json.load(f)
path = "path/image"
label, status = make_prediction(path)
print(label, status)
在上述的代码中class_name.json的文件内容为:
{"0": "Aeroplane", "1": "Bicycle", "2": "Bird", "3": "Boat", "4": "Bottle", "5": "Bus", "6": "Car", "7": "Cat", "8": "Chair", "9": "Cow", "10": "Dining Table", "11": "Dog", "12": "Horse", "13": "Motorbike", "14": "Person", "15": "Potted Plant", "16": "Sheep", "17": "Sofa", "18": "Train", "19": "TV Monitor"}
flask服务化部署模型
如上是常用的模型推理的代码,现将模型改为flask方式实现模型服务化,如下所示:
# -*- encoding: utf-8 -*-
'''
@File : deploy.py
@Time : 2021/11/07 16:05:22
@Author : xx Xianqin
@Version : 1.0
@Contact : xianqin.xx@163.com
@License : (C)Copyright 2017-2021
@Desc : None
'''
import json
import torch
import numpy as np
from PIL import Image
from torchvision import transforms, models
from flask import Flask, request
app = Flask(__name__)
app.config["data_trans"] = transforms.Compose([transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
def thresh_sort(x, thresh):
idx, = np.where(x > thresh)
return idx[np.argsort(x[idx])]
# 加载模型部分
def init_model():
resnet = models.resnet50()
num_ftrs = resnet.fc.in_features
resnet.fc = torch.nn.Linear(num_ftrs, 20)
resnet.load_state_dict(torch.load('model.pth', map_location='cpu'))
for param in resnet.parameters():
param.requires_grad = False
resnet.eval()
return resnet
# 调用服务执行的内容
@app.route('/model_predict', methods=['POST'])
def make_prediction():
if request.method == 'POST':
file_data = request.files.get('image')
img = Image.open(file_data)
img_trans = app.config["data_trans"](img).unsqueeze(0)
output = app.config["model"](img_trans)
output = output[0].numpy().ravel()
labels = thresh_sort(output, 0.5)
if len(labels) == 0 :
label_array = "No Categories"
status = 0
else:
label_array = [app.config["name"][str(i)] for i in labels]
status = 1
return json.dumps({"result": label_array, "status":status})
if __name__ == '__main__':
# 初始化,预加载完成模型
app.config["model"] = init_model()
# 类别信息
with open('class_name.json', 'r') as f:
app.config["name"] = json.load(f)
# 启动模型的flask服务
app.run(host='0.0.0.0', port=10086, debug=True)
对比两个段代码可以看出,使用flask部署模型可以很简单的实现,仅需要修改较少的代码就可以,其他的模型参照类似的方式实现。
启动flask服务
若上述项目的python文件名为model_flask.py,则启动flask服务执行如下命令:
python model_flask.py
在进行测试时,建议选用postman(点击进入官网下载)进行测试,如下图是针对本项目启动的flask进行测试的配置页面:

如上图,由于我们选用的是post方式,按照本图中的相关内容进行配置即可进行测试。
注意这里是 flask 代码启动了 app.run(), 尤其注意这是用 flask 自带的服务器启动 的app服务,后边会介绍这一问题。
2. gunicorn部署flask项目
flask直接生产环境部署的问题
在启动上述的flask项目时,会出现“WARNING: Do not use the development server in a production environment.”的警告提示;这是提示不要在生产环境直接部署flask服务。
Flask的web框架内部已经有了一个 WSGI server用来接受请求,但是因为其自带的server在处理并发等情况时不够优秀,并且存在响应慢等问题,出现这种情况也是由于flask框架的重点都放在了WSGI applicaiton的层面上,因为flask只是一个web框架,并不是一个web server的容器,flask自带的werkzeug只能用于开发环境,不能用于生产环境。此外如果直接通过nginx进行反向代理,也会经常无法响应请求。因此在生产环境下,flask 自带的服务器是无法满足性能要求的。
有两个可以在生产环境中使用、性能良好且支持Flask程序的服务器,分别是Gunicorn和uWSGI,但是这两个模块不提供对window的支持。因此本部分主要介绍gunicorn部署flask服务。
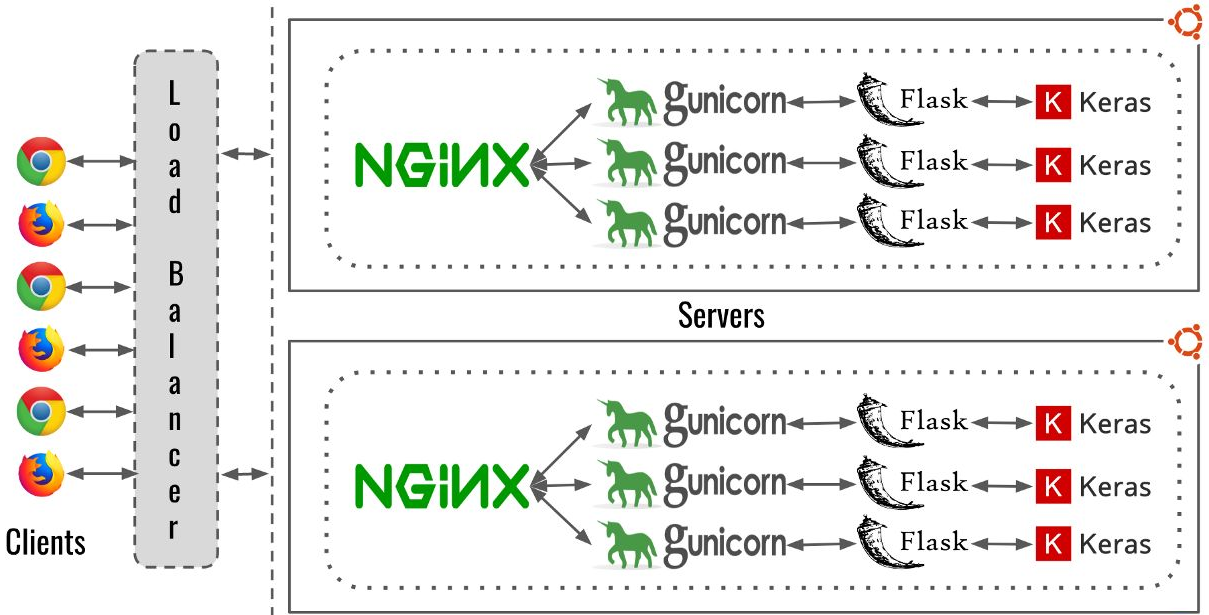
常见的客户请求模式下图所示,因此主要是介绍下图模式的部署方案实现:

gunicorn介绍
gunicorn是一个python Wsgi http server(其中WSGI为Web Server Gateway Interface,服务器网关接口),只支持在Unix系统上运行,来源于Ruby的unicorn项目。Gunicorn使用prefork master-worker模型(在gunicorn中,master被称为arbiter),能够与各种wsgi web框架协作。
Gunicorn很容易配置,轻量级对cpu的消耗很少,且兼容性好,具有高性能,并支持了很多Worker模式,推荐的模式有以下几种:
同步Worker:也是默认模式Sync,也就是一次只处理一个请求。
异步Worker:通过Eventlet、Gevent实现的异步模式。
异步IO Worker:目前支持gthread和gaiohttp两种类型。
gunicorn依赖环境
gunicorn
supervisor
gunicorn部署flask
在安装好 gunicorn 后,需要用 gunicorn 启动 flask(不需要启动上一步的flask,不然会造成gunicorn端口号冲突),使用了 gunicorn启动flask服务,则这一过程中model_flask.py 就等同于一个库文件,被 gunicorn 调用。
启动flask(在终端输入如下命令)
gunicron -w 4 -k gevent -b 0.0.0.0:10086 model_flask:app
上述参数介绍:
-b 绑定应用的ip(0.0.0.0是任何服务器都可以访问,127.0.0.1是只能本机访问)和端口
-w work的数量,也就是同时启动的模型进程数量,官方说可以有:核心数*+1个,若是部署的机器学习模型,这样设置可能存在问题,后续会介绍。
worker_class
-k STRTING, --worker-class STRTING要使用的工作模式,默认为sync。可引用以下常见类型“字符串”作为捆绑类,主要有以下几种:
sync
eventlet:需要下载eventlet>=0.9.7
gevent:需要下载gevent>=0.13
tornado:需要下载tornado>=0.2
gthread
gaiohttp:需要python 3.4和aiohttp>=0.21.5
他们的区别可以参考这个链接
model_flask:app是前边部署的flask文件model_flask.py的名字和固定的app
gunicorn有较多的参数,其他的参数介绍可以参考官方文档。
若要结束 gunicorn 需执行 pkill gunicorn,有时需要利用ps -ef | grep gunicorn查找到 pid 进程号才能 kill。
这样的操作有些繁琐,因此出现了supervisor,这是专门用来管理进程的工具,还可以管理系统的工具进程。
在这里我们主要利用supervisor管理gunicorn,将其当作自己的子进程启动;当gunicorn由于异常等停止运行后,supervisor可以自动重启gunicorn
supervisord启动成功后,可以通过supervisorctl客户端控制进程,启动、停止、重启
具体的使用步骤如下:
- 安装supervisor文件
pip install supervisor
- 生成supervisor的配置文件
echo_supervisord_conf > supervisor.conf
注意:可能echo_supervisord_conf不在你的环境变量目录下,可能要查找,通常在python环境的bin目录下,如果不在可以去这个目录查找。利用命令find / -name echo_supervisord_conf查找到echo_supervisord_conf路径,使用绝对路径执行上述命令
3.修改配置文件
vi supervisor.conf
在配置文件的最后添加相关的gunicorn内容
[program:our_app]
directory=/工程文件/model_flask.py/所在的绝对路径/
command=gunicorn -w 4 -k gevent -b 0.0.0.0:10086 model_flask:app
保存上述内容即可,可以看出与终端执行gunicorn是基本一致的。
- 启动supervisor
以下两种方式都可以启动我们的应用:
supervisorctl start our_app
或者
supervisord -c supervisor.conf
其中一定要注意our_app与supervisor.conf中的[program:our_app]是相一致的。
其他supervisor的基本使用命令:
supervisord -c supervisor.conf 通过配置文件启动supervisor
supervisorctl -c supervisor.conf status 察看supervisor的状态
supervisorctl -c supervisor.conf reload 重新载入 配置文件
supervisorctl -c supervisor.conf start [all]|[appname] 启动指定/所有 supervisor管理的程序进程
supervisorctl -c supervisor.conf stop [all]|[appname] 关闭指定/所有 supervisor管理的程序进程
现在访问http://IP:10086/model_predict就是利用gunicorn进行flask服务调用了,方法与前边介绍的postman测试一致。
3. Nginx部署
Nginx介绍
Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
Nginx安装
系统安装nginx安装包
ubuntu安装nginx
sudo apt install nginx
centos安装nginx,可以参考这个。
Nginx配置
以Ubuntu系统下的nginx为例进行介绍:
sudo vi /etc/nginx/nginx.conf
如下是该配置文件的内容:
user nginx; # 设置使用用户nginx,保持不变即可
worker_processes 2; # nginx要开启的进程数,若不设置默认为1,一般情况下不用修改,但考虑到实际情况,可以修改这个数值,以提高性能,上限为主机的CPU核数;nginx开启太多的进程,会影响主进程调度,所以占用的cpu会增高,因此该数值要适量设置,个人建议1-4即可。
error_log /var/log/nginx/error.log; # 出现错误存放的日志文件路径,保持不变即可
pid /run/nginx.pid; # 进程号的PID存在该路径中
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {# 工作模式与连接数上限
worker_connections 1024; # 单个进程的最大连接数
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"'; # 连接日志的保存格式
access_log /var/log/nginx/access.log main; # 日志的存放路径
sendfile on; # 使用sendfile系统调用来传输文件,保持该默认即可
tcp_nopush on; # 激活tcp_nopush参数可以允许把http response header和文件的开始放在一个文件里发布,作用是减少网络报文段的数量
tcp_nodelay on; # 激活tcp_nodelay,内核会等待将更多的字节组成一个数据包,从而提高I/O性能
keepalive_timeout 65; # 长连接超时时间,单位是秒
types_hash_max_size 4096; # 为了快速处理静态数据集,例如服务器名称, 映射指令的值,MIME类型,请求头字符串的名称,nginx使用哈希表
include /etc/nginx/mime.types; # 文件扩展名与类型映射表
default_type application/octet-stream; # 默认文件类型
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
# 加载模块化配置文件
include /etc/nginx/conf.d/*.conf;
server {
listen 8999; # 监听端口,为nginx的开放端口内容,默认81
#server_name 192.168.10.88; # 域名,没有可以为空
location / { # 对“/”启用反向代理
proxy_pass http://0.0.0.0:10086;
proxy_redirect off;
proxy_set_header Host $host:8999 ; # 若listen的端口号不是81,此处一定要
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
上述配置文件中主要添加了server部分,其中listen 是nginx的代理端口号,默认为81,可以修改为其他的;proxy_pass 处的内容为flask的地址和端口号,proxy_set_header 处为要与listen处一致,若为81可以写成【 Host $host;】,但是若listen不为81,必须写成【Host $host:8999 ;】,与listen处一致。
启动nginx
在终端执行
sudo service nginx start
现在访问http://IP:8999/model_predict就是利用nginx代理的flask服务调用方式了了,与前边介绍的postman测试一致。注意端口号需要改成listen处的接口。
4. docker镜像内部署nginx+gunicorn+flask的实现方案
本项目的目录结构如下:

具体的dockerfile文件内容如下:
#基于的基础镜像
FROM python:3.7
RUN mkdir /code
COPY app /code
#并发相关配置文件
RUN apt-get install nginx -y
COPY supervisor.conf /code
COPY nginx.conf /etc/nginx/
#安装python相关环境
RUN pip install -r /code/requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/ -f https://download.pytorch.org/whl/torch_stable.html
WORKDIR /code
#建立相关软连接配置
RUN ln -s /opt/python37/bin/gunicorn /usr/bin/ && ln -s /opt/python37/bin/supervisorctl /usr/bin && ln -s /opt/python37/bin/supervisord /usr/bin
RUN useradd -s /sbin/nologin -M nginx
#启动容器执行的命令,依次是启动gunicorn、启动nginx && service nginx start
# nginx -g 'daemon off;'关闭nginx的后台,
# nginx默认是以后台模式启动的,Docker未执行自定义的CMD之前,nginx的pid是1,执行到CMD之后,nginx就在后台运行,bash或sh脚本的pid变成了1。所以一旦执行完自定义CMD,nginx容器也就退出了。为了保持nginx的容器不退出,应该关闭nginx后台运行
ENTRYPOINT ["/bin/bash", "-c", "supervisord -c /code/supervisor.conf && nginx -g 'daemon off;'"]
#端口号为Nginx反向代理的接口,与nginx.conf中的listen设置保持一致
EXPOSE 8999
依据上边工程目录结构执行dockerfile即可生成镜像。
5. 此方案问题
- gunicorn的-w是对应的启动服务的进程数:
对于机器学习模型来说,尤其是深度学习模型通常比较大,启动多个进程便是加载多次模型到内存中,此处必须要考虑服务器的显存,否则会出现out of memory。例如:我们有一张显存为12G的卡,若是单个模型加载到显存内占用的显存空间为3G,若设置-w为4(需要注意-w的数量是子进程的数量,并不包括主进程,因此-w为1,则实际有2个进程),则此时刚好3G×5=15G,此时变会出现内存溢出。所以再设置gunicorn的-w时需要考虑部署的环境问题。
此方案有不妥之处欢迎大佬们多多指教!
若在部署过程中遇到问题,可以随时留言沟通,亦或者发送邮件maxianqin1112@163.com,在看到后我会第一时间回复,一起加油!
此内容可以任意转载,但请注明出处!

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)