使用 IoT Core、Kinesis 和 ElastiCache 在 AWS 上处理传感器数据
这篇博文是我的 AWS 系列的一部分:
-
基础设施即代码 - 使用 Terraform 管理 AWS
-
使用 Lambda 和 API 网关在 AWS 上部署 HTTP API
-
使用 Elastic Beanstalk 在 AWS 上部署 HTTP API
-
部署 AWS RDS MySQL 实例并对其进行基准测试
-
在 AWS 中使用 SNS、SQS 和 Lambda 处理事件
-
使用 Terraform 和 Travis CI 在 AWS 上持续交付
-
使用 IoT Core、Kinesis 和 ElastiCache 在 AWS 上处理传感器数据
-
使用 CloudWatch 监控 AWS Lambda 函数
简介
物联网 (IoT) 成为近年来的热门话题。公司预测未来几年将有数十亿的连接设备。物联网应用程序具有与传统软件项目不同的特征。应用程序在受限硬件上运行,网络连接不可靠,来自许多不同传感器的数据需要近乎实时地可用。
随着廉价且可用的微处理器和微控制器(如Rasperry Pi和Arduino产品)的兴起,物联网产品的进入门槛已大大降低。而且软件和开发工具栈也成熟了。
2015 年 12 月,AWS IoT 全面上市。 AWS IoT 是一组用于管理 IoT 设备并将其连接到云的产品。其IoT Core产品作为入口点。 IoT Core 通过MQTT接受数据,然后根据预先配置的规则处理并转发到其他 AWS 服务。
在这篇博文中,我们希望构建一个由 IoT Core、Kinesis、Lambda、ElastiCache、Elastic Beanstalk 和 S3 提供支持的示例性传感器数据后端。目标是接受传感器数据,将其保存在 S3 存储桶中,同时在 Web 上显示实时提要。该架构应该是可扩展的,因此我们可以在以后添加更多功能,例如分析或通知。
该职位的其余部分结构如下。首先,我们将介绍架构概述。之后,我们将深入研究实现。我们将省略有关 VPC 和网络部分以及 Elastic Beanstalk 部署的详细信息,因为这已在之前的帖子中讨论过。我们将关闭讨论主要发现的博客文章。
架构
[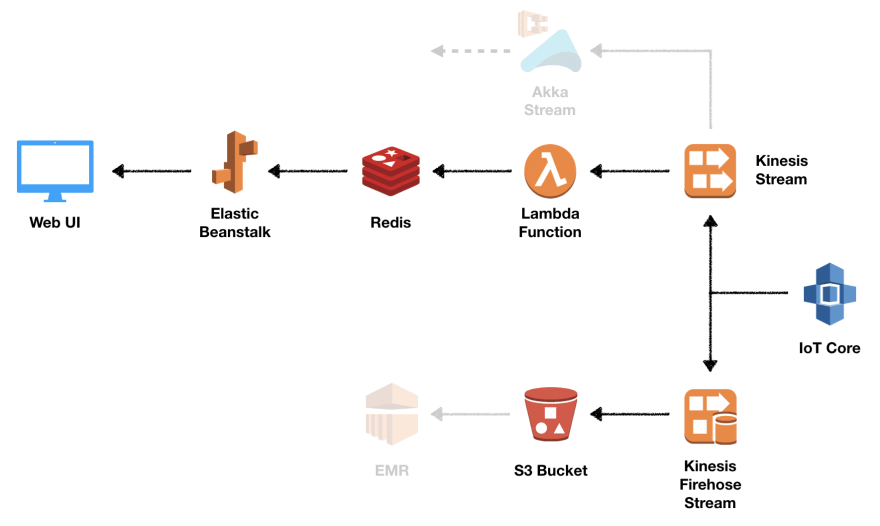 ](https://res.cloudinary.com/practicaldev/image/fetch/s--DQk3izBA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3。 amazonaws.com/i/1zm11u6uwpo9vi3gureo.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--DQk3izBA--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3。 amazonaws.com/i/1zm11u6uwpo9vi3gureo.png)
IoT Core 充当 MQTT 消息代理。它使用主题将消息从发布者路由到订阅者。每当消息发布到主题时,所有订阅者都会收到有关该消息的通知。 IoT 核心允许我们使用 rules 有效地将消息发送到其他 AWS 服务。规则对应于定义何时触发它的 SQL 选择语句,例如对于来自某个主题的所有消息。
每个规则可以有多个与之关联的操作。一个动作定义了所选消息应该发生的事情。有许多不同的动作支持,但在本文的过程中我们只会使用 Firehose 和 Kinesis 动作。
Firehose 操作将消息转发到Kinesis Firehose 传输流。 Firehose 会在配置的时间内或直到达到某个批量大小之前收集消息,并将其保存到指定位置。在我们的例子中,我们希望将消息作为小批量保存在 S3 存储桶中。
Kinesis 数据流用于将处理逻辑与数据摄取分离。这使我们能够通过多个独立的消费者异步消费来自流的消息。由于消息偏移量可以由每个消费者单独管理,我们还可以决定在下游失败的情况下重播某些消息。
主要的数据处理发生在我们的 Lambda 函数中。使用 Lambda 函数处理 Kinesis 数据流的一种便捷方法是将流配置为事件源。我们将使用这种基于流的模型,因为 Lambda 会为您轮询流,并在检测到新记录时调用您的函数,并将新记录作为参数传递。可以向数据流添加更多消费者,例如,Akka Streams应用程序允许更精细地控制消息消化。
Lambda 函数将更新由ElastiCache管理的 Redis 实例。在我们的示例中,我们将为每条记录增加一个消息计数器,并存储收到的最后一条消息。我们正在使用 Redis 的Pub/Sub功能来通知我们的 Web 应用程序,该应用程序通过 WebSocket 连接更新所有客户端。
我们将使用 IoT 核心中内置的 MQTT 测试客户端向我们的主题发布消息。作为展望,请在下面找到最终结果的动画。让我们在下一节中逐步研究实现。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--4H-A2dVi--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/lr6mq7pw22ol3r7enzhw.gif)
](https://res.cloudinary.com/practicaldev/image/fetch/s--4H-A2dVi--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/lr6mq7pw22ol3r7enzhw.gif)
执行
开发工具栈
为了开发解决方案,我们使用以下工具:
-
Terraform v0.11.7
-
SBT 1.0.4
-
斯卡拉 2.12.6
-
IntelliJ + Scala 插件 + Terraform 插件
源代码可在 GitHub 上找到。现在让我们看看每个组件的实现细节。
物联网核心
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--PBhPMsH1--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3。 amazonaws.com/i/m38hfkc6svlxssfrt3yf.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--PBhPMsH1--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3。 amazonaws.com/i/m38hfkc6svlxssfrt3yf.png)
使用 IoT 核心时,无需设置。每个 AWS 账户都可以将 MQTT 代理用作开箱即用的完全托管服务。因此,我们唯一需要做的就是配置我们的主题规则以及将消息转发到 Kinesis 和 Firehose 的相应操作。
resource "aws_iot_topic_rule" "rule" {
name = "${local.project_name}Kinesis"
description = "Kinesis Rule"
enabled = true
sql = "SELECT * FROM 'topic/${local.iot_topic}'"
sql_version = "2015-10-08"
kinesis {
role_arn = "${aws_iam_role.iot.arn}"
stream_name = "${aws_kinesis_stream.sensors.name}"
partition_key = "$${newuuid()}"
}
firehose {
delivery_stream_name = "${aws_kinesis_firehose_delivery_stream.sensors.name}"
role_arn = "${aws_iam_role.iot.arn}"
}
}
进入全屏模式 退出全屏模式
该规则将针对topic/sensors主题中的所有消息触发。使用newuuid()作为 Kinesis 的分区键对于我们的演示来说很好,因为无论如何我们将只有一个分片。在生产场景中,您应该考虑以适合您要求的方式选择分区键。
使用的执行角色需要分别允许kinesis:PutRecord和firehose:PutRecord操作。在这里,我们两次使用相同的角色,但我建议设置两个具有尽可能少的权限的角色。
现在我们已经配置了规则,接下来让我们创建 Firehose 传输流和 Kinesis 数据流。
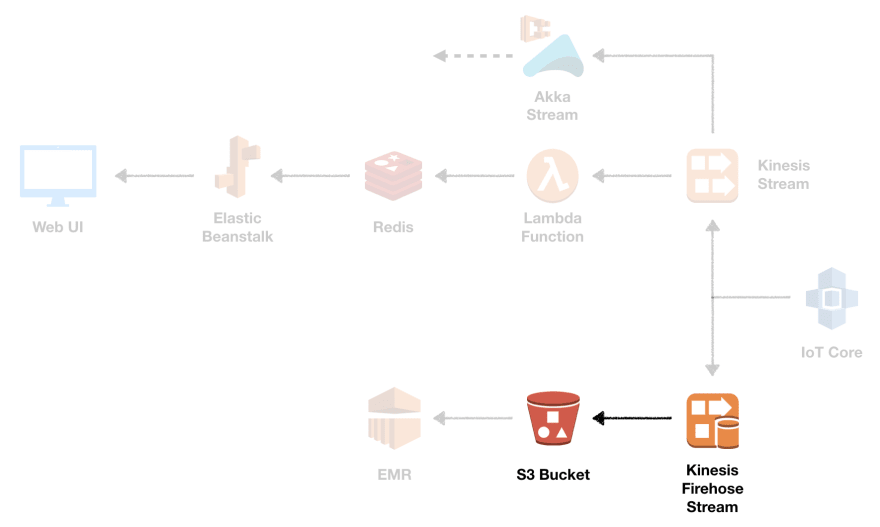
消防软管输送流
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--5IP2TiuH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/2ekzesfjh5wmpi0zjqr8.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--5IP2TiuH--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/2ekzesfjh5wmpi0zjqr8.png)
要设置 Firehose 传输流,我们指定目标类型 (s3) 并进行相应配置。由于我们在本系列中多次创建 S3 存储桶,因此我们将在此处省略存储桶资源。两个参数buffer_size(MB) 和buffer_interval(s) 控制在将分区持久化到 S3 之前等待新数据到达的时间。
resource "aws_kinesis_firehose_delivery_stream" "sensors" {
name = "${local.project_name}-s3"
destination = "s3"
s3_configuration {
role_arn = "${aws_iam_role.firehose.arn}"
bucket_arn = "${aws_s3_bucket.sensor_storage.arn}"
buffer_size = 5
buffer_interval = 60
}
}
进入全屏模式 退出全屏模式
执行角色需要具有访问 S3 存储桶以及 Kinesis 流的权限。请在下面找到使用的政策文件。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"${aws_s3_bucket.sensor_storage.arn}",
"${aws_s3_bucket.sensor_storage.arn}/*"
]
},
{
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords"
],
"Resource": "${aws_kinesis_stream.sensors.arn}"
}
]
}
进入全屏模式 退出全屏模式
这应该涵盖了我们的原始数据持久层。所有传入的消息都将转储到 S3。接下来让我们看一下对数据处理很重要的 Kinesis 数据流。
Kinesis 数据流
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--_8oN9JLs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/36arcez7baeptkfyfmn5.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--_8oN9JLs--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/36arcez7baeptkfyfmn5.png)
Kinesis 数据流将只有一个分片,保留期为 24 小时。每个分片都支持一定的读写吞吐量,每次请求的数量和大小都有限制。您可以通过向流中添加更多分片并选择适当的分区键来扩展。我们会将数据保留 24 小时,这包含在基本价格中。
resource "aws_kinesis_stream" "sensors" {
name = "${local.project_name}"
shard_count = 1
retention_period = 24
}
进入全屏模式 退出全屏模式
接下来,让我们仔细看看我们的 Lambda 函数。
拉姆达
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--1700QiHi--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/3mqzq5puoe1uxyqlizcd.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--1700QiHi--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/3mqzq5puoe1uxyqlizcd.png)
到目前为止,您应该已经熟悉如何创建 Lambda 处理程序。这次我们将使用一个额外的库,它允许 AWS 自动处理KinesisEvent输入的反序列化:aws-lambda-java-events。我们还必须包括amazon-kinesis-client和aws-java-sdk-kinesis。
与 Redis 的连接是使用net.debasishg.redisclient包完成的。让我们先看代码,然后逐步进行。
class Handler extends RequestHandler[KinesisEvent, Void] {
val port = System.getenv("redis_port").toInt
val url = System.getenv("redis_url")
override def handleRequest(input: KinesisEvent, context: Context): Void = {
val logger = context.getLogger
val redis = new RedisClient(url, port)
val recordsWritten = input.getRecords.asScala.map { record =>
val data = new String(record.getKinesis.getData.array())
redis.set("sensorLatest", data)
redis.incr("sensorCount")
}
redis.publish(
channel = "sensors",
msg = "updated"
)
val successAndFailure = recordsWritten.groupBy(_.isDefined).mapValues(_.length)
logger.log(s"Successfully processed: ${successAndFailure.getOrElse(true, 0)}")
logger.log(s"Failed: ${successAndFailure.getOrElse(false, 0)}")
null
}
}
进入全屏模式 退出全屏模式
这是发生的事情:
-
读取
$redis_url和$redis_port环境变量(省略错误处理) -
对于每个传入的
KinesisEvent,将调用 Lambda 函数。该事件包含自上次调用以来的记录列表。稍后我们将看到如何控制这部分。 -
连接到 ElastiCache Redis 实例。通过在请求处理方法之外设置连接来重用连接可能是有意义的。我不确定线程安全以及 AWS Lambda 如何处理对象创建。
-
对于每条消息,更新最新消息值并增加计数器。在 Lambda 中本地聚合所有记录并使用整个批次的结果更新 Redis 会更有效,但我懒得这样做。
-
向
sensors频道发布新数据已到达,以便通知所有客户端。
像往常一样,我们必须定义我们的 Lambda 资源。 Redis 连接详细信息将通过环境变量传递。
resource "aws_lambda_function" "kinesis" {
function_name = "${local.project_name}"
filename = "${local.lambda_artifact}"
source_code_hash = "${base64sha256(file(local.lambda_artifact))}"
handler = "de.frosner.aws.iot.Handler"
runtime = "java8"
role = "${aws_iam_role.lambda_exec.arn}"
memory_size = 1024
timeout = 5
environment {
variables {
redis_port = "${aws_elasticache_cluster.sensors.port}"
redis_url = "${aws_elasticache_cluster.sensors.cache_nodes.0.address}"
}
}
}
进入全屏模式 退出全屏模式
最后但同样重要的是,我们告诉 Lambda 监听 Kinesis 事件,使其轮询新消息。我们选择LATEST分片迭代器,它对应于总是将偏移量移动到最新的数据,每条消息只消费一次。我们还可以决定使用所有记录(TRIM_HORIZON)或从给定的时间戳(AT_TIMESTAMP)开始。
批处理大小控制一个 Lambda 调用处理的最大消息量。增加它对吞吐量有积极影响,而另一方面,小批量可能会导致更好的延迟。这是我们的事件源映射的 Terraform 资源定义。
resource "aws_lambda_event_source_mapping" "event_source_mapping" {
batch_size = 10
event_source_arn = "${aws_kinesis_stream.sensors.arn}"
enabled = true
function_name = "${aws_lambda_function.kinesis.id}"
starting_position = "LATEST"
}
进入全屏模式 退出全屏模式
为了将数据推送到 Web 层,我们将在下一节中创建 ElastiCache Redis 实例。
ElastiCache Redis
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--sGjmNAHu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/ucfuhkcnitkw0gvd4d6h.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--sGjmNAHu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/ucfuhkcnitkw0gvd4d6h.png)
我们将使用运行 Redis 4.0 的单个cache.t2.micro实例。与 RDS 类似,我们也可以通过apply_immediately标志来强制更新,即使在维护窗口之外。
resource "aws_elasticache_cluster" "sensors" {
cluster_id = "${local.project_name}"
engine = "redis"
node_type = "cache.t2.micro"
num_cache_nodes = 1
parameter_group_name = "default.redis4.0"
port = "${var.redis_port}"
security_group_ids = ["${aws_security_group.all.id}"]
subnet_group_name = "${aws_elasticache_subnet_group.private.name}"
apply_immediately = true
}
进入全屏模式 退出全屏模式
而已!剩下的只是用于 UI 的 Elastic Beanstalk 应用程序。
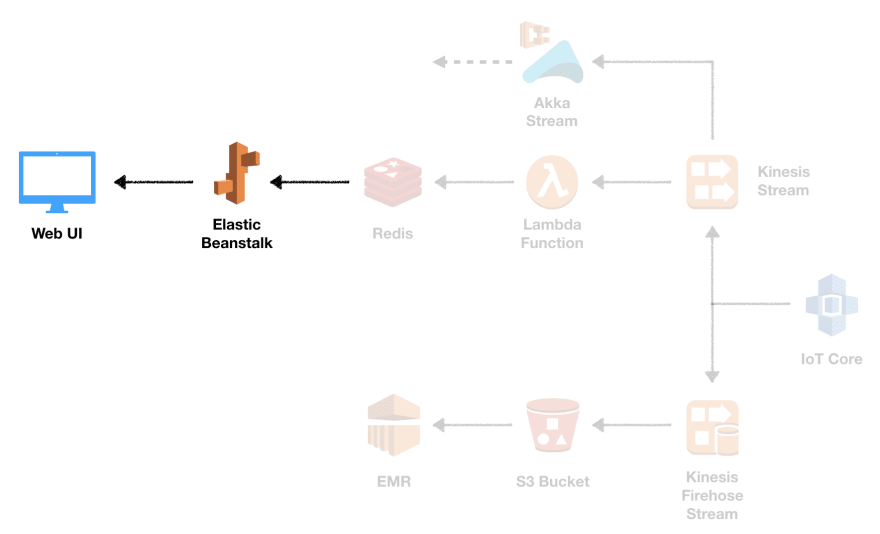
Elastic Beanstalk Web UI
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--j2UXLNWX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev。 s3.amazonaws.com/i/a7nsvbk85ro58kcy8l1u.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--j2UXLNWX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev。 s3.amazonaws.com/i/a7nsvbk85ro58kcy8l1u.png)
Elastic Beanstalk 应用程序由前端和后端组成。前端是带有 JavaScript 和 CSS 的单个 HTML 文件的形式。那里没什么好看的。后端是用 Scala 编写的,并利用我们已经在 Lambda 函数中使用的相同 Redis 库,以及用于提供静态文件和处理 WebSocket 连接的 Akka HTTP。
前端
前端将具有三个输出:消息计数、最后一条消息以及从服务器接收到最后更新的时间。您将在下面找到 UI 和 HTML 代码的屏幕截图。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--RUmW2XlB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/6plgk0br1ii2xacktrbm.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--RUmW2XlB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://thepracticaldev.s3.amazonaws .com/i/6plgk0br1ii2xacktrbm.png)
<html>
<head>
<title>Sensor Data Example</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<script src="http://fargo.io/code/jquery-1.9.1.min.js"></script>
<link href="http://fargo.io/code/ubuntuFont.css" rel="stylesheet" type="text/css">
<script src="main.js"></script>
</head>
<body>
<div>
<p>Message count: <span id="messageCount"></span></p>
<p>Last message: <span id="lastMessage"></span></p>
<p>Last update: <span id="lastUpdate"></span></p>
</div>
<script>
$(document).ready(WebSocketTest);
</script>
</body>
</html>
进入全屏模式 退出全屏模式
JavaScript 部分也相当简单。我们将使用内置的 WebSocket 支持并为onopen、onmessage和onclose事件提供处理程序。onmessage事件将解析接收到的数据并填写适当的文本字段。请注意,我们必须使用window.location构建 WebSocket URL,因为它必须是我所知道的所有浏览器中的绝对 URL。
var loc = window.location, protocol;
if (loc.protocol === "https:") {
protocol = "wss:";
} else {
protocol = "ws:";
}
var socketUrl = protocol + "//" + loc.host + loc.pathname + "ws";
function WebSocketTest() {
if ("WebSocket" in window) {
console.log("Connecting to " + socketUrl);
var ws = new WebSocket(socketUrl);
ws.onopen = function() {
console.log("Connection established");
};
ws.onmessage = function (evt) {
var msg = JSON.parse(evt.data);
console.log("Message received: " + msg);
$("#lastUpdate").text(new Date());
$("#lastMessage").text(msg.latest);
$("#messageCount").text(msg.count);
};
ws.onclose = function() {
console.log("Connection closed");
};
} else {
console.error("WebSocket not supported by your browser!");
}
}
进入全屏模式 退出全屏模式
后端
后端由一个 Akka HTTP Web 服务器和两个 Redis 连接组成。我们必须在这里使用两个连接,因为 Redis 不允许同时对 Pub/Sub 和普通键值操作使用相同的连接。
让我们看一下代码。与往常一样,如果需要,您需要有一个参与者系统、参与者物化器和执行上下文。出于简洁的原因,我们将省略这一点。下面的清单说明了设置支持 WebSocket 的 HTTP 服务器。我们正在路由两条路径,一条用于 WebSocket 连接,一条用于静态 HTML 文件,其中包含所有 JavaScript 和 CSS 内联。我们忽略所有传入的消息,并将来自 Redis 的消息转发给所有客户端。接口和端口都将由 Elastic Beanstalk 传递。
val route =
path("ws") {
extractUpgradeToWebSocket { upgrade =>
complete(upgrade.handleMessagesWithSinkSource(Sink.ignore, redisSource))
}
} ~ path("") {
getFromResource("index.html")
}
val interface = Option(System.getenv("INTERFACE")).getOrElse("0.0.0.0")
val port = System.getenv("PORT").toInt
val bindingFuture = Http().bindAndHandle(route, interface, port)
进入全屏模式 退出全屏模式
下一个任务是定义 Redis 源。 Redis Pub/Sub API 需要为订阅频道中的每条消息调用的回调函数。这与开箱即用的 Akka Streams 不兼容,因此我们必须使用一个小技巧将我们的 Redis 消息转换为Source对象。以下清单说明了 Redis 源的创建以及频道订阅。
val redis_port = System.getenv("redis_port").toInt
val redis_url = System.getenv("redis_url")
val redis = new RedisClient(redis_url, redis_port)
val redisPubSub = new RedisClient(redis_url, redis_port)
val (redisActor, redisSource) =
Source.actorRef[String](1000, OverflowStrategy.dropTail)
.map(s => TextMessage(s))
.toMat(BroadcastHub.sink[TextMessage])(Keep.both)
.run()
redisPubSub.subscribe("sensors") {
case M(channel, message) =>
val latest = redis.get("sensorLatest")
val count = redis.get("sensorCount")
redisActor ! s"""{ "latest": "${latest.getOrElse("0")}", "count": "${count.getOrElse("0")}" }"""
case S(channel, noSubscribed) => println(s"Successfully subscribed to channel $channel")
case other => println(s"Ignoring message from redis: $other")
}
进入全屏模式 退出全屏模式
创建 Redis 源是使用Source.actorRef和BroadcastHub.sink的组合来完成的。源 Actor 会将它接收到的每条消息发送到流中。我们将缓冲区大小配置为 1000 条消息并丢弃最年轻的元素,以便在溢出的情况下为新元素腾出空间。在订阅回调中,我们可以查询 Redis 以获取最新数据,然后将 JSON 对象发送给 Redis Actor。
广播集线器接收器发出一个源,我们可以将其插入 WebSocket 接收器以生成将处理传入 WebSocket 消息的流。由于我们需要演员和来源,我们将保留这两个物化值。
现在我们可以构建我们的 fat jar 并将其上传到 S3。由于它与Elastic Beanstalk 后中的过程基本相同,因此我们现在不打算详细介绍。接下来让我们看看 Terraform 资源。
地形
首先,我们必须引用 S3 存储桶内的 fat jar。因为在我们使用 SBT 发布 jar 之前必须存在存储桶,所以 Terraform 部署需要分两个阶段进行。首先我们只创建工件存储桶并运行sbt webui/publish,然后我们部署剩余的基础设施。
resource "aws_s3_bucket" "webui" {
bucket = "${local.project_name}-webui-artifacts"
acl = "private"
force_destroy = true
}
data "aws_s3_bucket_object" "application-jar" {
bucket = "${aws_s3_bucket.webui.id}"
key = "de/frosner/${local.webui_project_name}_2.12/${var.webui_version}/${local.webui_project_name}_2.12-${var.webui_version}-assembly.jar"
}
进入全屏模式 退出全屏模式
接下来,我们可以定义 Elastic Beanstalk 应用程序、环境和版本。此时我们将省略所有与网络和执行相关的设置。 Redis 连接详细信息将作为环境变量传递。要通过负载均衡器启用 WebSocket 通信,我们必须使用LoadBalancerPortProtocol设置将协议从 HTTP 切换到 TCP。在正确的设置中,您还必须调整nginx 配置因为否则连接可能会不规则地终止。
resource "aws_elastic_beanstalk_application" "webui" {
name = "${local.project_name}"
}
resource "aws_elastic_beanstalk_environment" "webui" {
name = "${local.project_name}"
application = "${aws_elastic_beanstalk_application.webui.id}"
solution_stack_name = "64bit Amazon Linux 2018.03 v2.7.1 running Java 8"
setting {
namespace = "aws:elasticbeanstalk:application:environment"
name = "redis_url"
value = "${aws_elasticache_cluster.sensors.cache_nodes.0.address}"
}
setting {
namespace = "aws:elasticbeanstalk:application:environment"
name = "redis_port"
value = "${aws_elasticache_cluster.sensors.port}"
}
setting {
namespace = "aws:elb:loadbalancer"
name = "LoadBalancerPortProtocol"
value = "TCP"
}
}
resource "aws_elastic_beanstalk_application_version" "default" {
name = "${local.webui_assembly_prefix}"
application = "${aws_elastic_beanstalk_application.webui.name}"
description = "application version created by terraform"
bucket = "${aws_s3_bucket.webui.id}"
key = "${data.aws_s3_bucket_object.application-jar.key}"
}
output "aws_command" {
value = "aws elasticbeanstalk update-environment --application-name ${aws_elastic_beanstalk_application.webui.name} --version-label ${aws_elastic_beanstalk_application_version.default.name} --environment-name ${aws_elastic_beanstalk_environment.webui.name}"
}
进入全屏模式 退出全屏模式
而已!现在我们已经定义了所有必需的资源,除了我们有意跳过的网络部分。请注意,您不能使用默认 VPC 以及子网和安全组,否则 Lambda 和 Elastic Beanstalk EC2 实例都无法连接到 ElastiCache。接下来让我们看看我们的宝宝在行动吧!
部署和使用
如前所述,部署是通过多个步骤完成的。首先,我们只创建用于上传 Elastic Beanstalk 工件的 S3 存储桶。然后我们提供剩余的基础设施。由于此时 Terraform 不支持部署 Elastic Beanstalk 应用程序版本,我们将在之后执行生成的 AWS CLI 命令。
cd terraform && terraform apply -auto-approve -target=aws_s3_bucket.webui; cd -
sbt kinesis/assembly && sbt webui/publish && cd terraform && terraform apply -auto-approve; cd -
cd terraform && $(terraform output | grep 'aws_command' | cut -d'=' -f2) && cd -
进入全屏模式 退出全屏模式
完成后,我们可以打开 Elastic Beanstalk 环境 URL 以查看 UI。如果我们分配了一个 DNS 名称,我们可以使用该名称。然后我们在另一个浏览器选项卡中打开 AWS IoT 控制台并导航到 Test 页面。在那里我们滚动到 Publish 部分,输入topic/sensors作为主题,然后可以开始发布 MQTT 消息。
[](https://res.cloudinary.com/practicaldev/image/fetch/s--4H-A2dVi--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https://thepracticaldev.s3 .amazonaws.com/i/lr6mq7pw22ol3r7enzhw.gif)
结论
在这篇博文中,我们了解了如何使用 IoT Core 规则将 MQTT 消息路由到 Kinesis 流。 Kinesis Firehose 传输流是一种自动批量保存数据流的便捷方式。作为 Lambda 事件源的 Kinesis 数据流可以更精细地控制如何处理数据。使用 ElastiCache Redis 作为中间存储层和通知服务,我们使客户能够获得传感器的近实时更新。
查看我们构建的示例解决方案,我们可以做一些不同的事情。不必同时为 Firehose 传输流和 Kinesis 数据流付费,我们只能使用数据流并添加一个自定义轮询消费者来批量保存数据,这可能会执行一些基本的格式转换,比如写入压缩文件列式存储格式。
虽然将 Kinesis 配置为 Lambda 的事件源效果很好,但如果 Lambda 函数不断运行,它可能会变得有点昂贵。在这种情况下,例如,使用部署在 ECS EC2 中的自定义使用者可能会有所回报。
使用 Redis 作为中间存储层只是众多选择中的一种。为您的问题选择正确的数据存储并非易事。 Redis 速度很快,因为它是在内存中的。如果您需要更持久和可扩展的数据库,DynamoDB 也是一种选择。客户端可以通过DynamoDB 流订阅 DynamoDB 表中的更改。也许您还想添加ElasticSearch或Graphite作为消费者。
你怎么看?您是否已经将 AWS IoT 用于您的一个项目?您是否还设法使用 Terraform 自动化设备管理?请在下方评论!
由 Wilgengebroed 在 Flickr 上拍摄的封面图片 - 已从作者签名的物联网中裁剪和签名删除。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献35528条内容
已为社区贡献35528条内容

所有评论(0)