关于 AWS DynamoDB 的 12 个常见误解
是 NoSQL 数据库所以不适合关系型数据
我经常听到的关于 DynamoDB 的一个常见误解是,因为它是 NoSQL,并且不像传统的关系数据库那样支持JOIN,所以它不适合关系数据。好吧,在 DynamoDB 中建模关系是完全可行的。
两种最常见的方法使用AWS Amplify,它提供所有 AWS 资源,包括表和解析器,以及单表设计,它仅使用一张表将所有数据实体放入一个容器和智能键组合中。虽然我强烈推荐前者入门和较小的项目,但后者更“专业”并且被 AWS 官方推荐。如果您想了解更多关于单表设计的信息,可以从Alex 的 DeBrie 关于 DynamoDB 的书中了解。
事实上,DynamoDB 适用于几乎所有类型的数据。它是一个完美的键值存储、元数据存储、关系数据库、事件存储(例如在事件溯源中)和事务数据存储——这要归功于事务支持。
DynamoDB 很慢
另一个论点是关于速度的。很多次我听说开发人员可以在不到 1 毫秒的时间内从他们的关系数据库中获取数据!和 DynamoDB?同样的操作需要10ms甚至20ms,太慢了吧?
并不真地。这些场景通常基于过于简化的设置,其中速度是通过索引字段获取一行来测量的,并且在没有流量、不稳定峰值和无数其他因素的强大机器上进行。现实往往更加混乱,尤其是在规模上。随着您的关系数据库开始获得越来越多的流量,您将遇到与其他操作和进程、连接池耗尽、事务冲突等导致的机器负载相关的减速。
在这种情况下,DynamoDB 怎么样?性能总是一样的。无论您是每秒发送 1 个请求,还是每秒发送 1,00,000 个请求,DynamoDB (如果数据模型的架构正确) 的表现都很好,有时在重负载下甚至更好。
[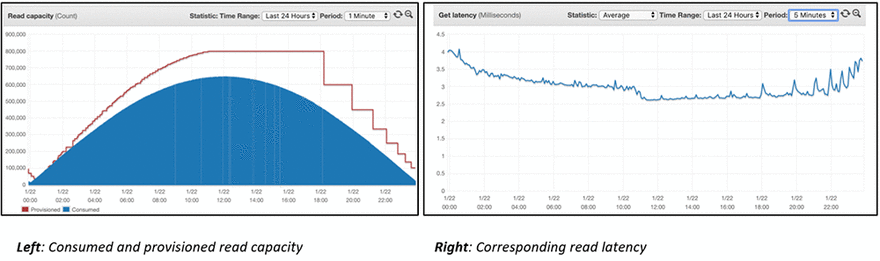 ](https://res.cloudinary.com/practicaldev/image/fetch/s----sXmLkW--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https:/ /d2908q01vomqb2.cloudfront.net/887309d048beef83ad3eabf2a79a64a389ab1c9f/2019/02/26/dynamodb-auto-scaling-5.gif)
](https://res.cloudinary.com/practicaldev/image/fetch/s----sXmLkW--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_66%2Cw_880/https:/ /d2908q01vomqb2.cloudfront.net/887309d048beef83ad3eabf2a79a64a389ab1c9f/2019/02/26/dynamodb-auto-scaling-5.gif)
来源:Amazon DynamoDB Auto Scaling:任何规模的性能和成本优化
DynamoDB 很贵
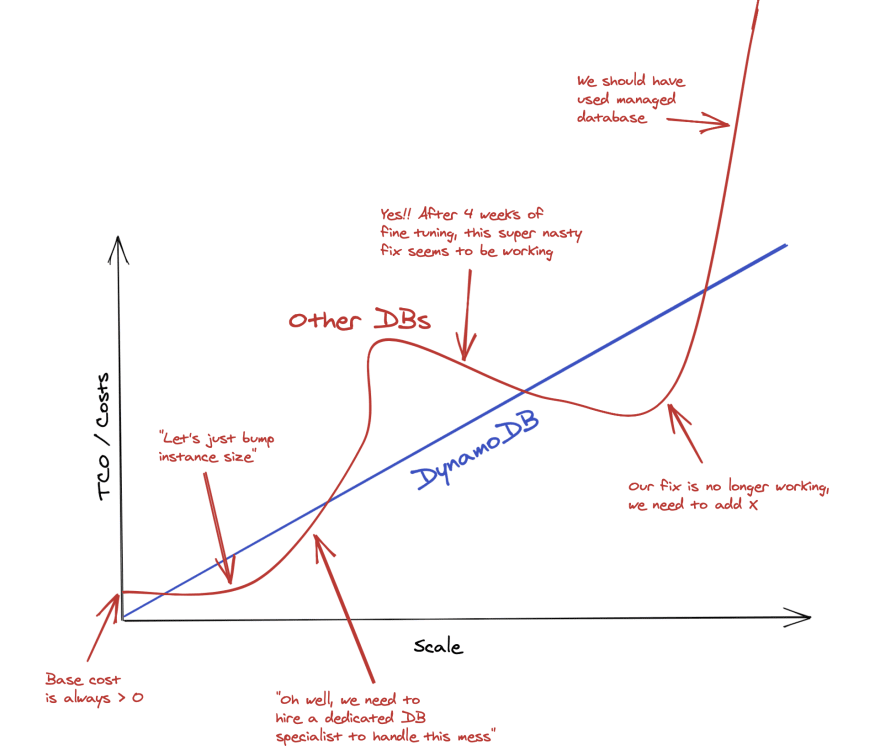
与传统的非托管数据库相比,扩展成本要低得多。实际上,DynamoDB 的成本是超级可预测的并且与使用量成正比。在传统的非托管数据库中,TCO(总拥有成本)更加非线性,并且具有许多乍一看可能不可见的隐藏成本:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--QR9U2l4Y--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dynobase-assets.s3-us-west-2.amazonaws.com/dynamodb-vs-traditional-dbs.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--QR9U2l4Y--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dynobase-assets.s3-us-west-2.amazonaws.com/dynamodb-vs-traditional-dbs.png)
一开始,在小范围内,DynamoDB 成本接近于零,因为如果没有流量,就没有成本。此外,AWS 提供了相当慷慨的免费套餐,因此您甚至可以以零数据库成本投入生产。在非托管数据库中,您需要配置至少具有 1 个 vCPU 的 VM/机器/实例。这是您无法跳过的硬成本,即使您的数据库完全未使用,您也要支付它。
稍后,您的预置数据库可能在成本方面优于 DynamoDB,但在某些时候您会遇到当前机器不够用的情况。你会发现自己在不断地挑战规范,调查瞬态和难以调试的问题,或者调整记录不太好的变量。在某些时候,您甚至可以考虑聘请一位高薪专职专家来为您处理这些问题。
同时,DynamoDB 需要零监督或微调。它很简单。虽然这有时看起来更贵,但您实际上可以节省大量资金(和时间!),因为您不必担心操作问题、管理备份以及具有恒定的吞吐量和99.99% SLA。
请记住,始终比较 TCO,而不仅仅是运行 VM/机器/容器的纯成本。
DynamoDB 是无模式的
这其实不是一个误解。尽管 DynamoDB 为用户提供了项目形状的自由——他们不必符合任何模式,因为 DynamoDB 是无模式的,但缺乏任何验证或约定可能会导致巨大的混乱。
但是,如果您要根据单表设计设计数据模型,那么您将拥有一组非常严格的可用_访问模式_,这基本上将成为您的模式。
DynamoDB 难用
每项技术都需要_一些_投资,DynamoDB 也不例外。但是,由于 DynamoDB API 非常少(DocumentClient 只有 11 个操作),因此与学习 PostgreSQL 或 Elasticsearch 相比,成为专家的材料范围可能要小得多。此外,还有一些关于运行和维护这两个数据库的书籍。在 DynamoDB 中,这个问题根本不存在。它由亚马逊为您运行,您无需担心。
您可能还会争辩说缺乏 SQL 支持是一个障碍。直到最近,在不支持 PartiQL 的情况下,这句话是正确的,但现在,您可以使用它。但是,如果您想使用原生查询语言,我们准备了一个可视化查询生成器可能会帮助您入门。
此外,DynamoDB 的生态系统还在不断发展壮大。越来越多的工具提供了有用的抽象,例如 Jeremy Daly 的DynamoDB Toolbox用于处理单表设计,Dynamoose用于类似 ORM 的体验,AWS Amplify对程序员完全隐藏了 DynamoDB 层, 或Dynobase,它可以帮助您在配置文件、区域、表格和探索数据集之间导航。
最后,DynamoDB 与 AWS 生态系统的其余部分无缝集成,从而减少了您需要创建的代码量。内置了TTL、时间点恢复、流式传输、全局复制等机制。你的责任只是使用它们,而不是创作它们。
无法将 SQL 与 DynamoDB 一起使用
直到前一段时间,这种说法都是正确的。最近,AWS 宣布PartiQL 支持 DynamoDB。借助 PartiQL(一种类似 SQL 的语言),您可以使用熟悉的语言与 DynamoDB 和 Athena 等其他 AWS 组件进行交互。
请记住,使用 SQL 并不能消除 DynamoDB 的技术限制。您仍然需要了解您的SELECT * FROM ...查询将被转换为扫描或查询,诸如UPDATE X WHERE Y之类的东西可能不起作用,或者COUNTing 也不允许。
仅适用于无服务器工作负载
DynamoDB 经常被组合成基于无服务器的架构。事实上,它是一个完美的匹配,因为就像 AWS Lambda、S3 和其他托管服务一样,它是根据它的实际使用量来计费的——按读/写操作量和表消耗的千兆字节磁盘空间。
话虽如此,它并没有阻止您将 DynamoDB 用于非无服务器工作负载。可以从任何环境访问表,包括 EC2 实例、CI/CD 系统、VM、容器、本地甚至您的本地计算机。您所要做的就是拥有一个有效的 AWS 身份,并在其范围内允许访问它。有了这些,您可以使用CLI或SDK与 DynamoDB 进行交互。
DynamoDB 难以管理
完全不真实。不,这一切都为您管理。在 AWS 控制台中单击“创建表”后,您将在几秒钟内获得一个高度可用、冗余、可扩展、静态和传输中加密、SOC、PCI 和 HIPAA 兼容的数据库。想象一下,使用本地软件实现相同的结果是多么困难。
但是,等等还有更多。使用 DynamoDB,您可以启用跨区域复制具有亚秒级延迟,启动流数据从它到其他数据源或数据处理器,或通过单个 API 调用启用 PITR(时间点恢复)。多么酷啊?再一次,使用非托管软件会有多困难?
从本质上讲,DynamoDB 允许您在巨人的肩膀上构建产品,让您专注于对您的业务重要的事情,专注于您的核心竞争力。朋友不要让朋友在实例/虚拟机/容器/本地运行数据库。
DynamoDB 默认是安全的
就像任何其他数据库或服务一样,DynamoDB 只是一个工具。虽然它的构建考虑了最佳安全原则,包括加密、IAM、工作备份,但如何使用它取决于您。责任共担模型是这里的关键。
尽管 Amazon 确保了最佳的_“云安全”,但您仍需对“云中的安全”_ 负责。没有人会阻止您以明文形式存储密码、使用通配符 IAM 策略、泄露您的 AWS 身份凭证或违反法律法规。
DynamoDB 实际上使您的数据库的安全性更容易。由于无需管理服务器、容器、虚拟机或集群,您不必担心正确限制网络访问、定期修补软件或更新最新漏洞。
DynamoDB 不能用于严肃的项目
这根本不是真的。有许多非常认真的公司在生产中使用 DynamoDB,包括在线学习网站 Duolingo,使用 DynamoDB 在其 Web 服务器上存储大约 310 亿个数据对象,Nike 放弃了 Cassandra 集群,转而使用 DynamoDB,或者 Disney 使用 DynamoDB存储数十亿客户操作的元数据。
DynamoDB 也是亚马逊内部的狗粮——它是一个Tier-0服务,为亚马逊的大部分业务提供支持。还强烈建议 Amazon 的所有新计划都使用 DynamoDB 作为数据库。
DynamoDB只适合大流量大项目
错误的!感谢免费套餐,您可以完全免费开始使用 DynamoDB。之后,使用成本随着您的使用而增加。您获得的客户越多,您赚的钱就越多,DynamoDB 的成本就越大,而且一切都是成正比的。此外,没有像其他非托管数据库那样的初始承诺,入口实例以 10 美元/月开始。
DynamoDB 不适合分析
最后一点有点复杂。确实,因为您不能对 DynamoDB 表运行任意查询(从技术上讲,您可以,但由于Scan的性质,效率极低),因此您无法对数据执行临时报告。那可能会令人失望。但是,有解决方案:
- 您可以将数据从 DynamoDB 流式传输到 Redshift 或其他为报告和分析目的而构建的关系数据库
2.您可以自己构建聚合函数。这些插入到DynamoDB Streams的函数将自动重新计算您的复合统计数据或汇总,始终提供某些聚合的最新状态。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35527条内容
已为社区贡献35527条内容

所有评论(0)