对全局端点的需求
在这篇文章中,我将探讨全局端点的概念,并就构建多区域应用程序所需的内容分享我的观点。
作为系列多区域道路的一部分,您可以查看其他部分:
-
第 1 部分- 反思在开始多区域架构之前要考虑的事项。
-
第 2 部分- CloudFront 故障转移配置。
-
第 3 部分- Amazon API Gateway HTTP API 故障转移和延迟配置。
-
第 4 部分- Amazon DynamoDB 全局表。
部署噩梦
在构建多区域应用程序时,要考虑的事情很多,这里我不是告诉你它很简单。尽管如此,一些服务促进了架构,在这个系列中,我已经使用了一些,但老实说,AWS 不会让它变得更容易,特别是如果你想部署它们。
如果我想在最终用户附近缓存,Amazon CloudFront 就是服务。它带有故障转移标准,我可以在其中添加一系列区域,并且根据错误,CloudFront 将命中关联的自定义源。
OriginGroups:
Items:
- Id: Failover
FailoverCriteria:
StatusCodes:
Items:
- 502 # Bad Gateway Exception
- 503 # Service Unavailable Exception
- 504 # Endpoint Request Timed-out Exception
Quantity: 3
Members:
Items:
- OriginId: region1
- OriginId: region2
- OriginId: region3
Quantity: 3
Quantity: 1
Origins:
- Id: Region1
DomainName: !Ref Region1OriginEndpoint
....
- Id: Region2
DomainName: !Ref Region2OriginEndpoint
....
- Id: Region3
DomainName: !Ref Region3OriginEndpoint
....
每个源点都指向某个东西,它很容易成为这样的微服务:

这个由 Amazon API Gateway 和 AWS Lambda 组成的微服务必须在每个区域的 Amazon CloudFront 之前部署。想象一下在所有 +20 个地区都这样做。

每个微服务部署都必须有一个必须动态传递给 Amazon CloudFront 模板的导出名称。换句话说,我必须加载导出名称并将它们作为覆盖参数传递:
- REGION1_ORIGIN_ENDPOINT=$(aws cloudformation list-exports --region $AWS_REGION1 --o text --query "Exports[?Name=='${MY_MICROSERVICE_STACKNAME}-ApiDomainName'].Value")
- REGION2_ORIGIN_ENDPOINT=$(aws cloudformation list-exports --region $AWS_REGION2 --o text --query "Exports[?Name=='${MY_MICROSERVICE_STACKNAME}-ApiDomainName'].Value")
- sam deploy --template-file template.yml
--stack-name ${STACK_NAME}
--parameter-overrides Region1OriginEndpoint=${REGION1_ORIGIN_ENDPOINT} Region2OriginEndpoint=${REGION2_ORIGIN_ENDPOINT}
--capabilities CAPABILITY_NAMED_IAM
--no-confirm-changeset
--no-fail-on-empty-changeset
--resolve-s3
--debug
...
如果您想使用 Amazon Route 53,这同样适用。同样,我必须在每个区域中部署所有 Amazon API Gateway 或 Application Load Balancer 引用,并将引用传递给 Amazon Route 53。
AWS Lambda 和 Amazon DynamoDB 全局表呢?
我们必须将表名称传递给 Lambda,以允许 AWS Lambda 函数和 Amazon DynamoDB 之间的连接。
Policies:
- AWSLambdaBasicExecutionRole
- Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- dynamodb:GetItem
Resource: !Sub arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/${MyTableName}
Environment:
Variables:
MY_TABLE_NAME: !Sub ${MyTableName}
使用 Amazon DynamoDB 全局表在部署方面并没有真正的帮助:
MyTable:
Type: AWS::DynamoDB::GlobalTable
Properties:
...
Replicas:
- Region: region1
- Region: region2
- Region: region3
Outputs:
MyTableName:
Value: !Ref MyTable
Export:
Name: !Sub ${AWS::StackName}-MyTableName
当我部署一个全局服务时,我必须选择一个区域,并且输出参数只存在于该区域中。所以为了获得这个全球价值,我必须指向一个特定的地区。
不完美的全球时代
AWS 并未让构建者更轻松地部署多区域应用程序。例如,我们有全球服务,但他们需要使用区域参考。
到目前为止,还没有办法在多个区域中自动部署 Amazon API Gateway、AWS Lambda、Amazon SQS、Amazon SNS、AWS Step Functions 等服务。所以我所做的,例如,使用 GitLab 是使用并行选项在单个管道中并行运行多个作业,并使用一个矩阵为每个作业实例传递不同的变量值:
.rust:service: &deployMyService
stage: myStage
needs:
- build:rust
script:
# Switch to proper AWS role
- ...
# Go to yml folder
- ...
# Import global table name
- MY_TABLE_NAME=$(aws cloudformation list-exports --region $AWS_REGION_GERMANY --o text --query "Exports[?Name=='${STACK_NAME_DYNAMO}-MyExportName'].Value")
- sam deploy --template-file template.yml
--stack-name ${STACK_NAME}
--parameter-overrides StageName=${STAGE} MyTableName=${MY_TABLE_NAME}
--capabilities CAPABILITY_NAMED_IAM
--no-confirm-changeset
--no-fail-on-empty-changeset
--resolve-s3
--region $AWS_REGION
parallel:
matrix:
- AWS_REGION:
- eu-west-1
- eu-central-1
- eu-west-2
这简化了多区域部署的自动化,直到 Too Many SAM Deploys in Parallel 导致速率限制。
事情正在发生变化,我们不仅有 Amazon DynamoDB 全局表,还有S3 多区域访问点,它们提供了一个全局端点来访问跨不同 AWS 区域中多个 S3 存储桶的数据集,这允许跨 AWS 区域将客户端请求动态路由到延迟最低的 S3 存储桶。
最近,AWS 还为 Amazon EventBridge](https://aws.amazon.com/blogs/compute/introducing-global-endpoints-for-amazon-eventbridge/)添加了[全局端点,允许在服务中断期间将事件摄取自动故障转移到辅助区域。但是,它并不是真正的全球服务,而是两个区域之间的故障转移配置。可以在ServerlessLand上找到完整的工作示例。
Amazon EventBridge 的全局终端节点的问题如下:
-
只能从 Lambda 中使用
-
我不能和APIGW或者其他服务一起使用
因为我无法自动将 EventBridge 全球端点连接到任何东西,我需要在特定区域部署总线并完成所有管道以将其连接到 SQS、Lambda 等服务。同时,我希望成为所有隐藏并将全局端点配置到服务。
我的愿望
我希望将所有服务配置为全局:
-
地区列表
-
故障转移顺序条件
例如:
MyApi:
Type: AWS::Serverless::GlobalApi
Properties:
Regions:
- eu-central-1
- eu-central-2
- eu-west-1
- eu-west-2
- eu-west-3
FailoverOrder:
- eu-central-1
- eu-west-1
- eu-central-2
- eu-west-3
- eu-west-2
MyFunction:
Type: AWS::Serverless::GlobalFunction
Properties:
Regions:
- eu-central-1
- eu-central-2
- eu-west-1
- eu-west-2
- eu-west-3
FailoverOrder:
- eu-central-1
- eu-west-1
- eu-central-2
- eu-west-3
- eu-west-2
Events:
ApiEvents:
Type: Api
Properties:
Path: /something
Method: GET
RestApiId: !Ref MyApi
Outputs:
ApiDomainName:
Description: The domain name of the endpoint.
Value: !Sub "${MyApi}.execute-api.${AWS::Region}.amazonaws.com"
Export:
Name: DomainName
为什么
使用上面的代码片段,我在多区域部署了一次,而不是 N 次,并且我声明了 AWS 网络应该处理的顺序,可能是某个区域的故障,或者可能将流量路由到提供最佳延迟的区域。如果 AWS 追求卓越,将允许基于以下条件创建标准:
-
故障转移路由策略
-
地理位置路由策略
-
加权路由策略等
与亚马逊 Route 53完全相同
部署堆栈应自动部署在每个区域中,CloudFormation 必须了解如何获取同一区域中的引用。现在使用内部函数 Fn::ImportValue 返回另一个堆栈或新堆栈导出的输出值 Fn:GlobalValue,CloudFormation 可以变得如此简单:
Origins:
- Id: Region1
DomainName: !ImportValue DomainName
....
- Id: Region2
DomainName: !ImportValue DomainName
....
- Id: Region3
DomainName: !ImportValue DomainName
....
这就是为什么需要全球到全球整合的原因:
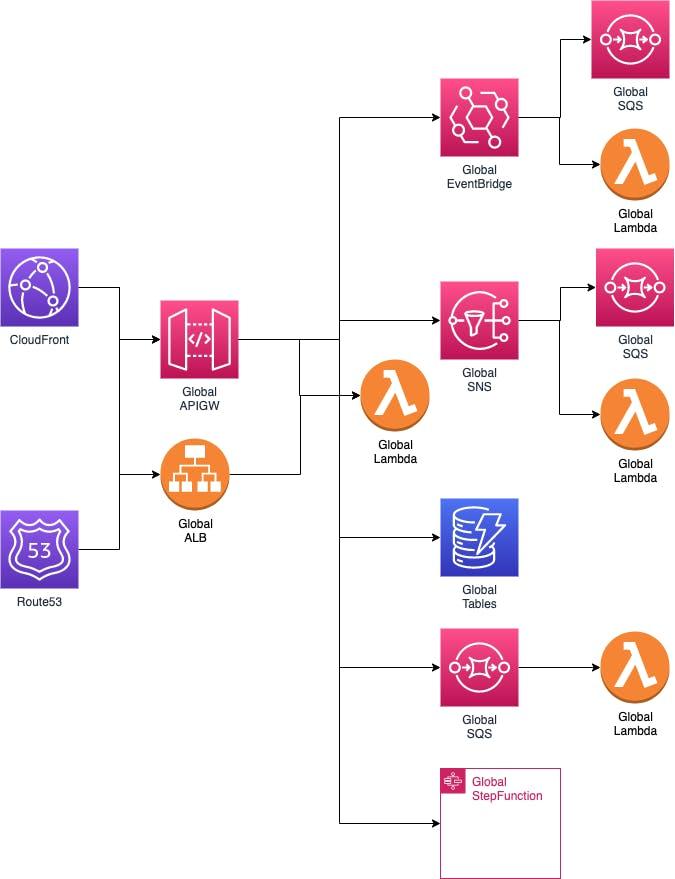
考虑到我可以将许多服务相互集成,我也应该能够在不使用 Lambda 的情况下使用 Global 服务做很多事情。 CloudFormation 或 AWS SAM 应该完成整个工作。我为特定区域配置一次,添加全局终端节点之间的引用,然后让 AWS 创建多区域部署所需的区域资源和引用。
结论
目前,我的愿望无法满足,因为 Global All 概念不存在,而且很可能需要一些。比如云计算六大优势之一是分钟走向全球。就本地的一切而言,这相对容易,但一旦进入云端,就不是那么容易了。
假设 AWS 计划为我们提供以下 Global Endpoints,例如 SQS 或 SNS、APIGW、Lambda 等。在这种情况下,我希望彼此开箱即用的集成以及更简单的部署方式。
遗憾的是,我认为如果没有更好的 CloudFormation 或对这项基本服务进行重大更改,真正的在几分钟内走向全球仍然很遥远。在那之前,多区域部署将是繁琐而复杂的,但我将感谢任何即将推出的新全球服务,这将使我的生活更轻松地构建多区域应用程序。

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献35526条内容
已为社区贡献35526条内容

所有评论(0)