AWS CDK 项目蓝图 - 建模和组织(第 1/2 部分)
作为系统/软件工程师,学习新工具或框架有时并不是我们“技术生活”中最难的部分。我们可能需要习惯一些关于这个工具/框架的新概念和术语,当然,还要学习如何使用它。我们通常会很快完成这部分。但是,在那之后,我们开始想......好吧,现在我知道如何使用它了,它涉及到......如何使用这个新工具组织我的项目?我应该使用这个还是那个结构?是否已经有一些实践/模式?
总而言之,在我们的背景下,在我们的现实中,如何充分利用这个工具,使它的帮助多于造成的问题?
所以,别无他法,还有更多工作要做......开始研究,检查社区经验、实践(好的和坏的)、建议、结果,一切!收集数据和处理以适应我们的需求(上下文),我们开始构建自己的方式来使用这个“新”工具/框架。
这就是我对这个两部分文章系列的目标:构建一个蓝图模型来展示如何使用 AWS-CDK 框架对我们的基础设施即代码项目进行建模、组织和构建。所以,让我们从第一部分开始。
AWS 云开发工具包 (AWS CDK) 简介
它是一组库,被视为一个框架,用于在代码中定义基础设施并通过 AWS CloudFormation 对其进行预置。 AWS CDK 最吸引人的优势之一是您可以使用(您的)“真实”语言,利用循环、函数、条件、参数、类、继承、组合......我们通常用于构建软件的所有内容,我们都可以用于构建我们的基础设施。此外,您可以选择最适合您的编程语言,AWS CDK 有:TypeScript、JavaScript、Python、Java、C#/.Net 和 Go(后面是jsii) - 它带来了 AWS CDK具有相同源代码提供多语言库的能力)。在这里,我们将使用 Python。
我们可以设计称为构造的可重用组件,然后定义我们的基础架构,将它们组合成堆栈和应用程序。这里的目标是构建我们的 AWS CDK 蓝图模型,因此,非常快速和简短地介绍了一些涉及 AWS CDK 的概念:
-
Constructs:AWS CDK 应用程序的基本构建块,它代表了一个“云组件”,其中包含要由 AWS CloudFormation 创建的资源/服务。 AWS CDK 包含它们的集合,用于每个 AWS 服务(称为AWS 构造库)。此外,请查看Construct Hub,这是帮助您发现来自 AWS、第三方和开源 CDK 社区的其他构造的好地方。
-
Stacks:它们是部署单元,Stack 中的所有资源都作为一个单元进行配置。
-
App:它代表整个CDK应用程序(也被认为是一个Construct),通常是应用程序的根构造。
-
阶段:抽象应用程序建模的表示,它将由应一起部署的堆栈组成。然后,我们多次创建此阶段的实例,每次都由我们部署应用程序所需的不同环境创建。
好的,我同意只是阅读这有点无聊,在我们完成我们的蓝图示例项目,动手部分之后,这些概念会更加清晰。
解决方案、建模和组织
该解决方案称为 AWS 技能映射,它显示了专业人员在每项 AWS 服务中的经验水平:
我们这里有两个项目,一个是简单的 AngularJS 项目(应用程序 - 以前的图像),另一个是 AWS CDK Python 项目(基础设施即代码 - IaC)。 AWS CDK 项目将负责为要部署和运行的这个 AngularJS 应用程序构建环境。除了创建 AWS Cloud 所需的资源和服务外,AWS CDK 项目还将为应用程序部署创建 CI/CD 管道(CodePipeline、Codebuild)。
AWS CDK 项目建模
这是我们 IaC AWS CDK 项目的设计模型。我们已经定义了三个逻辑单元,它们在分离的云组件(构造)中组成我们的应用程序:API、数据库和网站。然后,我们创建一个 Stage(一个抽象应用程序),我们将其拆分为两个独立的 Stack:Stateful 和 Stateless。通过这种方式,我们可以将我们可能关心的数据组件、有状态的(例如 s3、数据库)与另一个可能更容易重现的组件(例如 api、mq、sns、lambda)分开。
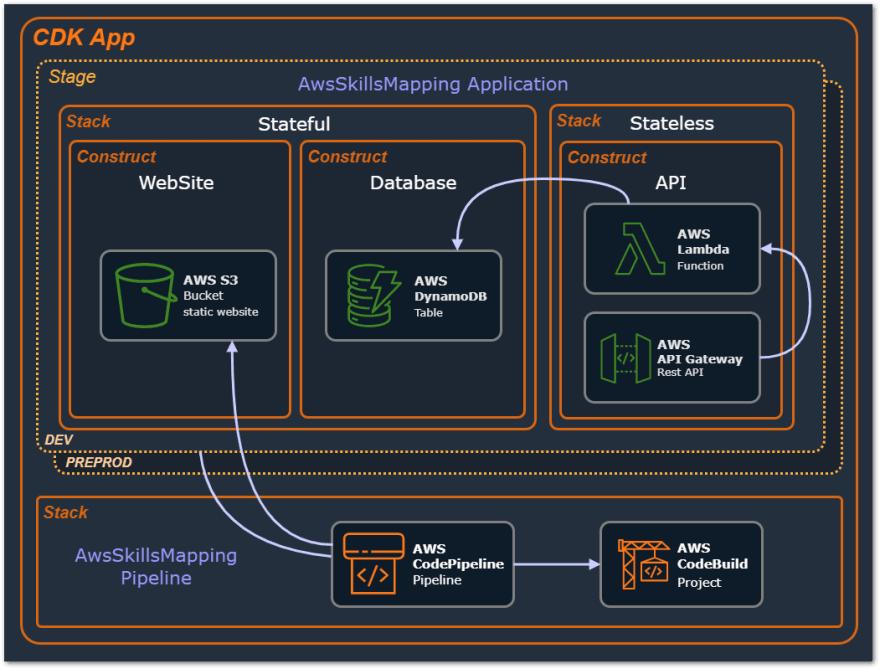
Stage(继承 aws_cdk.Stage 和两个 aws_cdk.Stacks:Stateful 和 Stateless 的 Python 类)将被实例化,并为每个不同的 Stage 加载不同的配置/环境信息:Dev 和 Preprod。
AWS CDK项目结构
让我们看一下我们的 AWS CDK 项目的结构和组织,它将遵循我们已经看到的定义的设计模型。
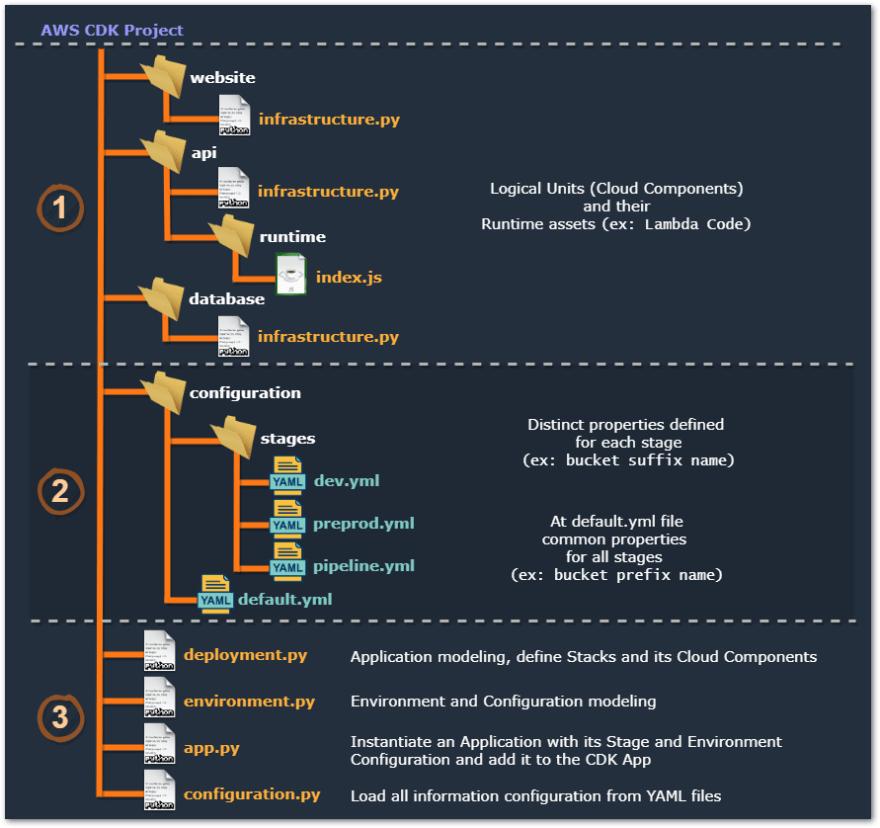
结构中最相关的部分在上图中分为三个部分。在第一部分 (1) 中,我们拥有为应用程序的每个逻辑单元实际构建所需的云组件、资源和服务的代码。例如,在 API 文件夹(API 逻辑单元)中,我们有我们的 aws_cdk.Construct(一个名为 ApiAwsSkillsMapping 的 Python 类),它创建了一个已经互连的 API 网关和 Lambda 函数,这样我们创建了一个由以下组成的更高级别的 Construct另外两个。此外,在运行时子文件夹中,我们保留了此 LU 的必要资产,即 Lambda 函数代码。
在第二部分 (2) 中,我们将每个信息配置都外部化在 YAML 文件中,按阶段拆分,并为管道额外配置一个。以下是它们的内容示例:
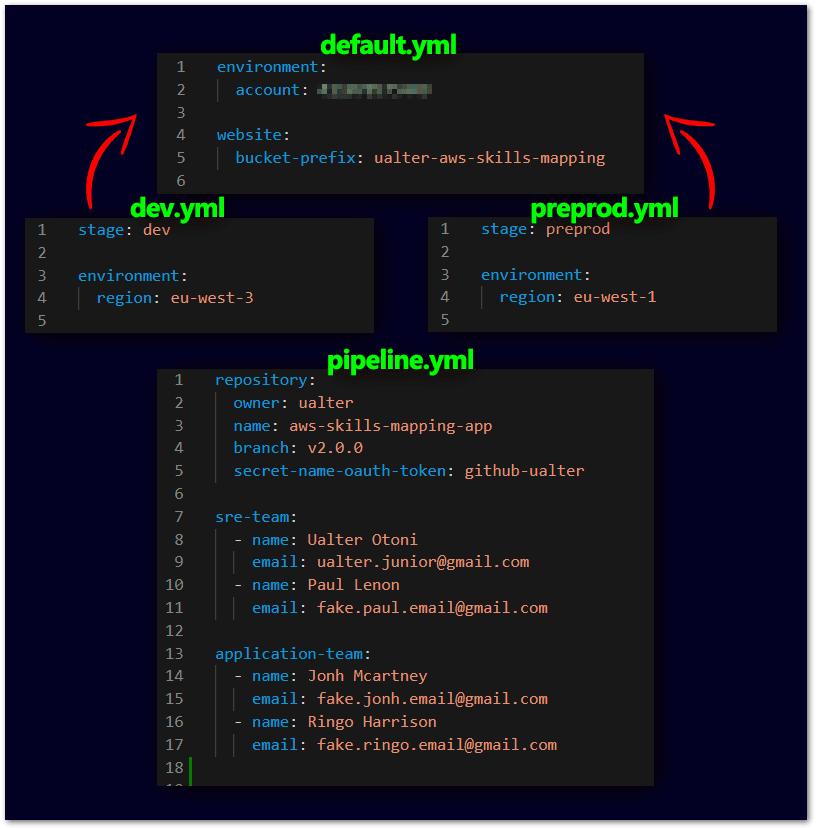
在 default.yml 文件中,我们保留所有常用值(如 bucket-prefix),以及 Stage 的特定值(如 bucket-suffix-name)。稍后,在我们的实际操作中,我们将在不同的 AWS 区域(Dev/eu-west-3/Paris 和 Preprod/eu-west-1/Ireland)部署 Stages Dev 和 Preprod 到同一个 AWS 账户)。在为 AngularJS 应用程序 CI/CD 创建管道时,让我们在 Dev 中的部署之后、Preprod 中的部署之前创建一个 Approval 步骤。 pipeline.yml 文件中会通知需要批准 Preprod 部署的团队和电子邮件。
最后,在我们项目结构的第三部分 (3) 中,我们对一些最相关的 Python 类进行了简短描述,这些类是实际构成 AWS CDK 项目的所有代码的一部分。
AWS跨区域依赖
对于同一 AWS 账户/区域中的堆栈之间的依赖关系,CDK 会识别它们的存在并能够自行处理它们。例如,查看我们的 AWS CDK 项目的设计模型,我们可以看到 DynamoDB 和 Lambda 在不同的 Stacks 中(DynamoDB 处于 Stateful 和 Lambda 处于无状态),我们需要授予 Lambda 函数读取权限DynamoDB 表。
在这种情况下,我们可以直接在代码中引用它们,或者使用 aws_cdk.CfnOutput("NAME") 导出到一个堆栈中,然后 cdk.Fn.import_value("NAME") 到在另一个堆栈中导入。回想一下,对于每个 AWS 账户,导出名称在一个区域内必须是唯一的。
现在,在另一个更棘手的情况下,我们需要采用不同的策略。在我们的示例中,问题是......在管道堆栈中,在创建 Codebuild 项目时,我们需要为每个阶段生成 API 网关 URL (https://{restapi_id}...) (Dev 和 Preprod),为了正确构建 AngularJS 应用程序(见下面的附注)。
注意! 我们使用 S3 静态网站来托管我们的 AngularJS 示例项目,我们没有在运行时使用“注入”环境变量的选项,因为 S3 是静态对象存储,而不是动态内容服务器,所以没有像“服务器运行时”这样的东西(在这种情况下)。这就是为什么我们必须为每个环境都有一个构建阶段的原因,要为每个环境设置不同的变量值,我们必须在“构建时”配置它们。此外,请记住,AngularJS 是纯粹的客户端代码(它在浏览器中运行)。
对于 Preprod,具有 API 网关的堆栈位于 eu-west-1(爱尔兰),具有管道的堆栈位于 eu-west-3(巴黎)AWS 区域。 那么,我们如何在不同 AWS 区域的两个堆栈之间共享此信息? 对于这种情况,我们使用 AWS Systems Managers 的服务参数存储(见下图)。首先 (1),在第一个 Stack(具有依赖源的堆栈)中,我们将该信息保存在其自己 AWS 区域的 Parameter Store 中,然后 (2),在另一个 Stack (依赖它的那个)我们在存储它的 AWS 区域的 Parameter Store 中读取它。
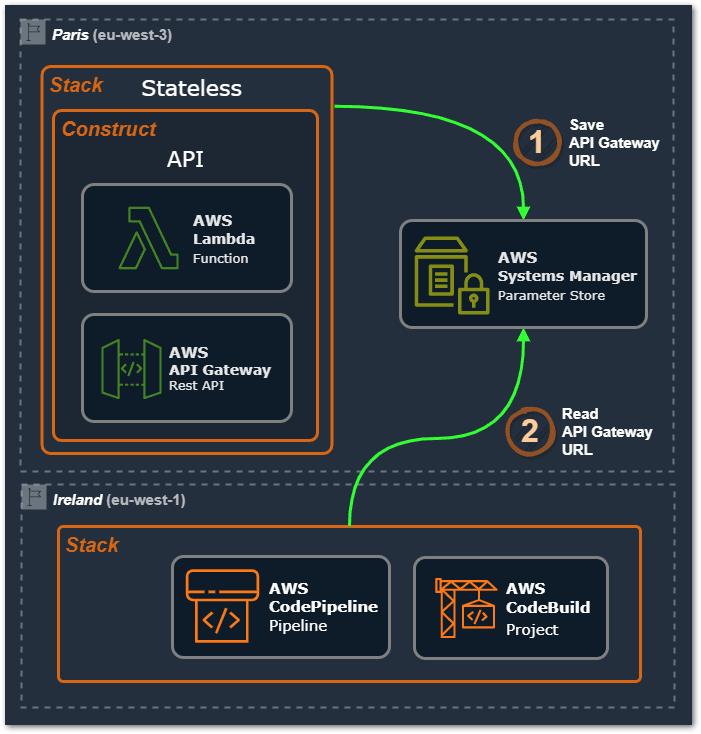
请注意,在这种情况下,显然,我们需要注意部署堆栈的顺序,以正确的顺序处理它们,首先是创建参数的顺序,然后是读取参数的顺序。
结论(第 1 部分)
好的,到此为止,回想一下,到目前为止,我们已经遇到了示例应用程序,看到了我们的 AWS CDK 项目的设计模型,并且知道了在这个 AWS CDK 项目中实现的结构、组织和外部配置。此外,我们还详细了解了我们如何处理位于不同 AWS 区域的 AWS CDK 堆栈之间的依赖关系。
在本文的下一部分(也是最后一部分)中,有趣的部分来了,我们将亲自动手,部署所有资源,并在 Dev 和 Preprod 两个阶段查看 AngularJS 应用程序的启动和运行。再见。
当然,源代码也将在那里可用。


CI/CD社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献13070条内容
已为社区贡献13070条内容

所有评论(0)