CPLD与FPGA
CPLD与FPGA如同数字世界的“瑞士军刀”与“超级计算机”——前者以简洁可靠应对控制挑战,后者以澎湃算力征服数据洪流。在边缘计算爆发的今天,明智的工程师会为温度传感器选择$1的CPLD管理I2C,同时用$1000的FPGA加速神经网络,让每分预算都迸发极致效能。由可编程与阵列(AND Plane)+ 固定或阵列(OR Plane)构成,逻辑深度通常≤20级。:I/O资源占比高达60-80%(如X
一、CPLD(复杂可编程逻辑器件)的核心特性
1. 架构本质
-
基于乘积项(Product-Term)结构:
由可编程与阵列(AND Plane)+ 固定或阵列(OR Plane)构成,逻辑深度通常≤20级。
逻辑函数实现:F = Σ(Product_Terms) -
非易失存储:采用EEPROM/Flash工艺,断电配置不丢失,上电纳秒级启动。
-
I/O密集型:I/O资源占比高达60-80%(如Xilinx XC9500系列)。
2. 性能特点
| 参数 | 典型值 | 优势场景 |
|---|---|---|
| 延迟确定性 | ±0.1ns抖动 | 实时控制(如电机驱动) |
| 功耗 | 静态0.1-1W,动态微瓦级 | 电池供电设备 |
| 逻辑容量 | 数十至数千宏单元 | 胶合逻辑(Glue Logic) |
| 工作温度 | -40℃~125℃(工业级) | 汽车/航天恶劣环境 |
3. 核心作用
-
接口转换:UART转SPI、电平移位(3.3V↔5V)
-
状态机控制:实现<100状态的有限状态机(FSM)
-
上电时序管理:多电源轨排序(Power Sequencing)
二、FPGA(现场可编程门阵列)的核心特性
1. 架构本质
-
基于查找表(LUT)结构:
N输入LUT实现任意N变量逻辑函数,逻辑深度可超100级。
函数容量:M = 2^N(4-LUT=16种组合) -
易失存储:采用SRAM工艺,需外部配置芯片,上电启动时间约100ms。
-
逻辑密集型:包含可编程逻辑单元(CLB)、DSP块、BRAM等异构资源。
2. 性能特点
| 参数 | 典型值 | 优势场景 |
|---|---|---|
| 逻辑规模 | 1K~10M+逻辑单元 | 高速算法加速(FFT/CNN) |
| 时钟频率 | >500MHz(高端器件) | 低延迟数据处理 |
| 并行能力 | 支持千级并行流水线 | 视频编解码/雷达信号处理 |
| 动态重构 | 部分区域运行时重配置 | 软件定义无线电(SDR) |
3. 核心作用
-
算法加速:CNN推理加速(TOPS算力)、加密运算
-
高速接口:PCIe Gen4/5、100G以太网MAC
-
原型验证:ASIC功能验证(RTL级兼容)
三、CPLD与FPGA的架构对比
1. 逻辑实现原理
| 特性 | CPLD | FPGA |
|---|---|---|
| 基本单元 | 宏单元(Macrocell) | 可配置逻辑块(CLB) |
| 组合逻辑 | 乘积项(AND-OR阵列) | 查找表(LUT)+ 寄存器 |
| 时序逻辑 | 触发器集成在宏单元内 | 每个LUT配套1-8个触发器 |
| 布线资源 | 连续式(总线结构) | 分段式(Switch Boxes) |
2. 存储与配置差异
| 特性 | CPLD | FPGA |
|---|---|---|
| 配置存储 | 片内Flash/EEPROM | 外挂SPI Flash或专用配置芯片 |
| 启动时间 | <10ms | 50ms~1s |
| 加密能力 | 位流加密(AES-256) | 配置比特流加密(可选) |
3. 资源分布特性
CPLD资源模型: 逻辑资源: 10% I/O资源: 70% 布线资源: 20% FPGA资源模型(如Xilinx UltraScale+): 逻辑资源: 40% I/O资源: 15% DSP/BRAM: 30% 布线资源: 15%
四、应用场景对比与选型依据
1. CPLD的典型应用
-
工业控制:
PLC逻辑控制(<5000门电路),响应延迟<10ns -
接口扩展:
扩展CPU的I2C/SPI接口,解决GPIO不足问题 -
电源时序控制:
多路电源使能信号排序(t_rise=1ms精度)
2. FPGA的典型应用
-
通信系统:
5G基带处理(毫米波波束成形) -
AI边缘计算:
目标检测YOLOv3加速(100FPS@1080p) -
高速数据采集:
14位ADC @ 1GSPS实时压缩存储
3. 选型决策树
图表
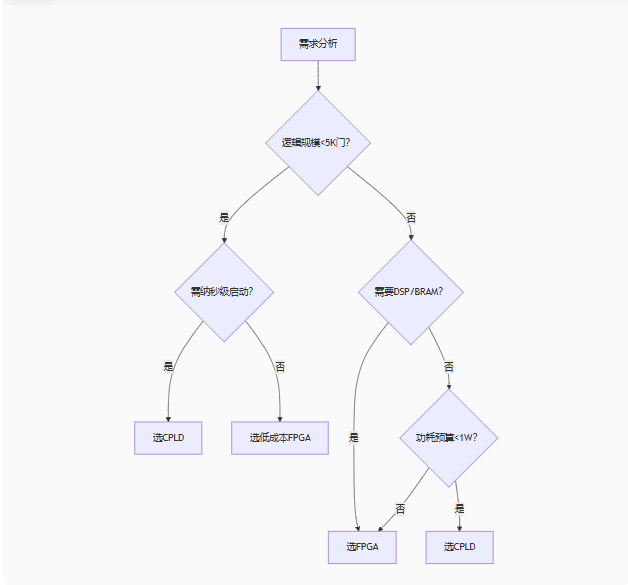
五、设计挑战与解决方案
1. CPLD的设计局限与突破
-
逻辑规模限制:
解决方案:多片级联(如PCIe Switch中4片CPLD协同) -
时序收敛难:
优化策略:约束关键路径在8级逻辑内(tPD<8ns)
2. FPGA的设计挑战
-
功耗控制:
动态功耗公式:P_dyn = C × V² × f × α
优化方法:-
电压调节(0.9V→0.8V,功耗降36%)
-
时钟门控(减少翻转率α)
-
-
时序收敛:
工具:Vivado时序引擎(支持多周期路径约束)
六、技术演进趋势
1. CPLD的智能化升级
-
集成硬核MCU:
Lattice MachXO3D集成ARM Cortex-M3,实现“CPLD+MCU”单芯片方案 -
安全增强:
物理不可克隆功能(PUF)防克隆攻击
2. FPGA的异构融合
-
3D堆叠:
Xilinx Versal ACAP集成AI引擎(AIE),算力达100TOPS -
Chiplet集成:
Intel Agilex采用EMIB技术融合FPGA+Optane内存
3. 工具链革新
-
AI辅助设计:
Xilinx Vitis AI自动优化神经网络IP布局 -
高层次综合(HLS):
C++代码直接生成RTL,开发效率提升5倍
七、总结:CPLD与FPGA的选型铁律
-
架构本质决定应用边界:
-
CPLD:I/O中心化,确定性延迟,适合控制密集型任务
-
FPGA:逻辑中心化,高算力密度,适合计算密集型任务
-
-
关键参数对比:
参数 CPLD优势场景 FPGA优势场景 逻辑规模 <10K等效门 >50K逻辑单元 启动时间 <10ms >50ms 功耗效率 静态功耗μW级 动态性能>500MHz 开发成本 工具链免费/低成本 工具链授权费>10万美元 -
未来融合趋势:
-
FPGA的CPLD化:Artix-7等小规模FPGA侵蚀CPLD市场
-
CPLD的智能化:集成MCU硬核拓展应用场景
-
设计箴言:CPLD与FPGA如同数字世界的“瑞士军刀”与“超级计算机”——前者以简洁可靠应对控制挑战,后者以澎湃算力征服数据洪流。在边缘计算爆发的今天,明智的工程师会为温度传感器选择$1的CPLD管理I2C,同时用$1000的FPGA加速神经网络,让每分预算都迸发极致效能。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)