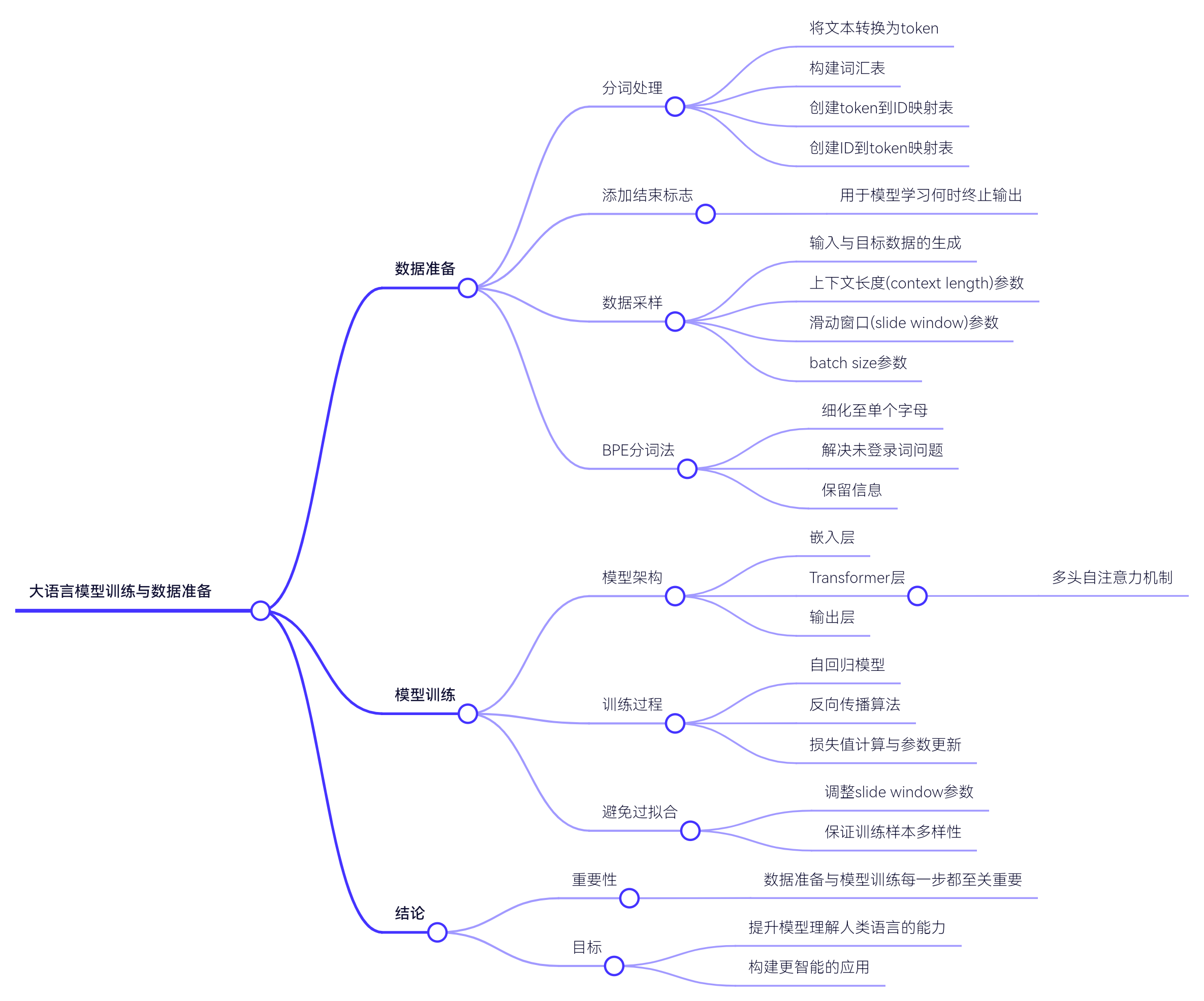
深度讲解LLM:微调技术(一篇好文)
微调的本质是 **“迁移学习” 的实践 **:预训练模型(如 BERT、GPT、ResNet 等)已从海量数据中学习到通用特征(如语言规律、图像边缘特征),微调通过在特定任务数据上调整模型参数,让通用特征与任务特性结合,实现 “通用知识向专项能力” 的迁移。例如,在罕见病 “阵发性睡眠性血红蛋白尿症(PNH)” 识别任务中,研究人员用 50 例病例数据微调提示向量,使模型对 PNH 的鉴别准确率从
目录
2. 参数高效微调(Parameter-Efficient Fine-Tuning, PFT)
3. 知识蒸馏(Knowledge Distillation)
在自然语言处理(NLP)领域,微调(Fine-Tuning)是将预训练模型适应特定下游任务的关键步骤。随着研究的深入,出现了许多高效的微调方法,这些方法在不同的应用场景中各有优势。
微调的本质是 **“迁移学习” 的实践 **:预训练模型(如 BERT、GPT、ResNet 等)已从海量数据中学习到通用特征(如语言规律、图像边缘特征),微调通过在特定任务数据上调整模型参数,让通用特征与任务特性结合,实现 “通用知识向专项能力” 的迁移。
对比预训练与微调:
预训练:用大规模通用数据训练,目标是学习普适性规律(如语言模型学习语法、语义)。微调:用小规模任务数据训练,目标是调整参数以适配具体任务(如用特定领域文本微调 BERT 做情感分析)。
以下是几种常用的微调方法:
1. 全参数微调(Full Fine-Tuning)
简介
全参数微调是最直接的方法,即对预训练模型的所有参数进行微调。这种方法在计算资源充足的情况下,通常能获得最佳性能。
优点
- 性能最佳:能够充分利用预训练模型的所有参数,适应下游任务。
- 灵活性高:适用于各种任务和数据集。
缺点
- 计算成本高:需要大量的计算资源和时间。
- 过拟合风险:在小数据集上容易过拟合。
适用场景
- 资源充足:适用于有足够计算资源和数据量的场景。
- 高精度需求:对模型性能要求极高的任务。
举例子
在医疗影像诊断领域,某三甲医院利用 30 万张标注影像数据,对一个预训练模型进行全参数微调,耗时 4 周完成训练。经过全参数微调后,模型能够精准捕捉影像中的细微特征,最终模型诊断准确率达到 98.7%,展现了全参数微调在高精度要求场景下的强大能力。
2. 参数高效微调(Parameter-Efficient Fine-Tuning, PFT)
参数高效微调方法通过只训练模型的一小部分参数,显著降低了计算和存储成本。以下是几种常见的参数高效微调方法:
2.1 LoRA(Low-Rank Adaptation)
LoRA 是一种通过在模型的关键层中插入低秩矩阵来实现微调的方法。它通过分解权重矩阵为两个低秩矩阵的乘积,仅训练这两个低秩矩阵。
- 优点:计算和存储成本低,性能接近全参数微调。
- 缺点:需要选择合适的低秩矩阵秩(r)和目标模块。
- 适用场景:资源受限的环境,如消费级 GPU。
2.2 Adapter Tuning
Adapter Tuning 在模型的每一层中插入一个小型的适配器模块(通常是一个前馈网络),仅训练这些适配器模块的参数。
- 优点:参数数量少,训练速度快。
- 缺点:适配器模块的设计和训练需要一定的技巧。
- 适用场景:多任务学习和跨语言任务。
2.3 Prompt Tuning
Prompt Tuning 通过在输入中添加提示(prompt)来引导模型的输出,而不改变模型的权重。基于通用医学模型,使用Prompt Tuning(提示微调) 技术,通过设计医疗领域专属提示模板(如 “患者症状:[症状],可能的罕见病:”),仅微调提示向量(约数千参数)。
举例子
例如,在罕见病 “阵发性睡眠性血红蛋白尿症(PNH)” 识别任务中,研究人员用 50 例病例数据微调提示向量,使模型对 PNH 的鉴别准确率从基线的 62% 提升至 85%,且训练过程仅需 1 小时(相比全参数微调的 3 天)。
- 优点:无需训练模型参数,适合零样本和少样本学习。
- 缺点:对提示的设计要求较高。
- 适用场景:零样本学习和少样本学习任务。
2.4 BitFit
BitFit 是一种仅对模型的偏置项(bias)进行微调的方法。
- 优点:参数数量极少,训练速度快。
- 缺点:性能提升可能有限。
- 适用场景:资源极度受限的环境。
2.5 Prefix Tuning
Prefix Tuning 在模型的输入中添加一个可学习的前缀(prefix),通过优化前缀来调整模型的输出。基于预训练的医疗语言模型(如 BioBERT、Med-PaLM),使用Prefix Tuning(前缀微调) 或Adapter技术,在各医院本地微调少量任务专属参数,实现 “模型共享、参数私有”。
举例子
例如,美国某医疗联盟为实现多中心糖尿病风险预测,先在通用医疗文本上预训练基础模型,再让各医院用本地 EHR 数据微调前缀参数(仅原模型参数的 0.5%)。各机构仅需上传微调后的少量参数,无需共享原始病历,最终联合模型的预测准确率(AUC 0.89)优于单中心模型,同时满足隐私保护要求。
- 优点:无需训练模型参数,适合少样本学习。
- 缺点:对前缀的设计和训练要求较高。
- 适用场景:少样本学习和多任务学习。
3. 知识蒸馏(Knowledge Distillation)
知识蒸馏是一种通过训练一个较小的“学生模型”来模仿较大“教师模型”的方法。学生模型通过学习教师模型的输出或中间层特征,达到类似的效果。
优点
- 模型压缩:学生模型更小、更高效。
- 性能提升:学生模型可以继承教师模型的知识。
缺点
- 训练复杂:需要同时训练教师和学生模型。
- 性能瓶颈:学生模型的性能可能受限于其规模。
适用场景
- 模型部署:需要在资源受限的设备上运行模型。
- 快速推理:对推理速度要求较高的场景。
4. 量化(Quantization)
量化是通过将模型的权重和激活值从浮点数转换为低精度格式(如 INT8)来减少模型的存储和计算成本。量化(Quantization)是深度学习中一种模型压缩与加速技术,通过将模型权重、激活值从高精度浮点数(如 32 位浮点数,FP32)转换为低精度数值(如 16 位、8 位、4 位甚至 1 位整数),在保证模型性能基本不变的前提下,大幅降低计算资源消耗和存储成本。
优点
- 模型压缩:显著减少模型大小。
- 加速推理:推理速度更快。
缺点
- 精度损失:可能会影响模型性能。
- 训练复杂:需要平衡量化精度和模型性能。
适用场景
- 边缘设备:需要在移动设备或嵌入式系统上运行模型。
- 实时应用:对推理速度要求极高的场景。
5. 混合微调(Hybrid Fine-Tuning)
混合微调结合了全参数微调和参数高效微调的优点,例如同时使用 LoRA 和全参数微调,或者在不同阶段使用不同的微调方法。
优点
- 灵活性高:可以根据任务需求选择合适的微调策略。
- 性能平衡:在计算成本和模型性能之间取得平衡。
缺点
- 复杂度高:需要设计和管理多种微调方法。
- 资源要求:可能需要一定的计算资源。
适用场景
- 复杂任务:需要在不同阶段或不同模块上应用不同的微调策略。
- 多任务学习:需要同时优化多个任务的场景。
6.关键挑战与解决方案
过拟合:
原因:任务数据量小、模型参数过多、训练轮次过多。
解决:采用部分参数微调 / PEFT、添加正则化(如 Dropout)、数据增强、早停策略。
领域偏移(Domain Shift):
原因:预训练数据与任务数据的领域差异大(如用通用文本预训练的模型微调法律文本任务)。
解决:先在任务领域的无标注数据上做 “领域自适应预训练(Domain-Adaptive Pretraining)”,再进行微调。
计算成本:
超大规模模型(如 GPT-3)全参数微调成本极高,可采用 PEFT 方法(如 LoRA)降低资源需求。

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)