
BigQuery ML新特性:时间序列和非时间序列数据的无监督异常检测

在异常检测方面,主要挑战是难以定义异常。例如,我们如何定义和预测异常的网络入侵、系统缺陷和安全欺诈?如果已知异常数据已被标记,我们可以从 BigQuery ML 支持的各种类型的监督机器学习模型中进行选择(详见下方链接)。但是如果我们不知道会发生异常并且没有标记数据怎么办?与使用监督学习的典型预测技术不同,我们此时可能需要能够在没有标记数据的情况下检测异常。
机器学习模型:https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create#create_model_syntax
7 月初,谷歌宣布将公开预览 BigQuery ML 中的新异常检测功能,该功能使用无监督机器学习来帮助检测异常,而无需标记数据。根据训练数据是否为时间序列,用户现在可以使用新的 ml.detect_ 异常函数使用以下模型来检测训练数据或新输入数据中的异常:
-
自动编码器型号,内测中;
-
K-means模型,已对外开放;
-
ARIMA_PLUS时间序列模型已对外开放。
如何使用 ML.DETECT_ANOMALIES 模型进行异常检测?
要检测非时间序列数据中的异常,我们可以使用:
K-means 聚类模型:当使用 K-means 模型时,根据每个输入数据点与其最近聚类之间的归一化距离来识别异常。如果距离超过用户提供的污染值确定的阈值,则认为数据点异常。
Autoencoder模型:使用autoencoder模型时,会根据每个数据点的重构误差来识别异常。如果误差超过污染值确定的阈值,则认为是异常。
要检测时间序列数据中的异常,您可以使用:
ARIMA_PLUS时间序列模型:使用Arima_plus模型时,会根据时间戳的置信区间识别异常。如果时间戳中的数据点出现在预测区间之外的概率超过用户提供的概率阈值,则将该数据点识别为异常。
让我们一一展示BigQuery}ML中异常检测的代码示例在每个场景中。
创建模型`mydataset.my_kmeans_model`OPTIONS(模型_TYPE u003d 'kmeans',NUM_CLUSTERS u003d 8,KMEANS_INIT_METHOD u003d 'kmeans++')ASSELECT * 除了(时间,类)来自`bigquery-public-data.ml_datasets.ulb_fraud_detection`;
训练 K-means 聚类模型后,运行 ML.DETECT_ANOMALIES 以检测训练数据或新输入数据中的异常。需要 Ml.detect_ Anomalies 与训练期间使用的数据相同:
SELECT *FROM ML.DETECT_ANOMALIES(模型 `mydataset.my_kmeans_model`, STRUCT(0.02 AS 污染), 表 `bigquery-public-data.ml_datasets.ulb_fraud_detection`);
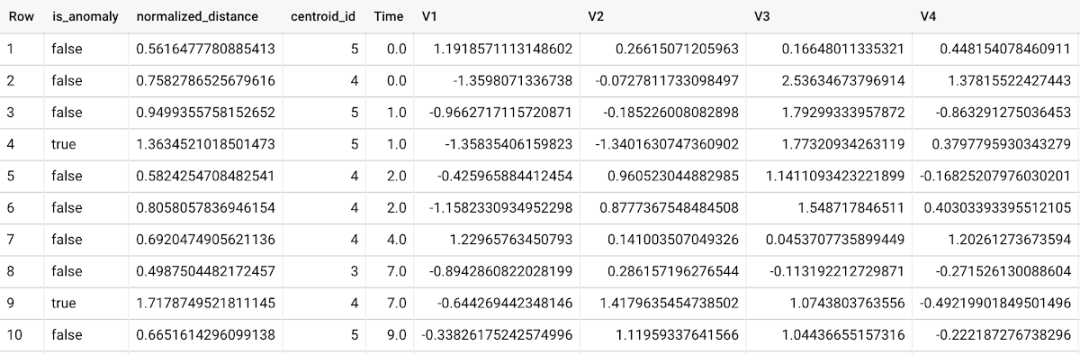
Ml.detect 也是必需的_异常并提供新数据作为输入:
SELECT *FROM ML.DETECT_ANOMALIES(型号 `mydataset.my_kmeans_model`, STRUCT(0.02 AS 污染), (SELECT * FROM `mydataset.newdata`));

K-means 聚类模型的异常检测如何工作?
根据从每个输入数据点到其最近聚类的归一化距离值来识别异常。如果超过污染值确定的阈值,则被识别为异常。以 K-means 模型和数据为输入,ML.DETECT_ANOMALIES 首先计算每个输入数据点到模型中所有簇的质心的绝对距离,然后通过它们各自的簇半径(定义为到所有簇的绝对距离)簇中的点指向质心)。对于每个数据点,ML.DETECT_ANOMALIES 根据归一化_distance 返回最近的质心_id,如上面的屏幕截图所示。用户指定的污染值决定了数据点是否被认为异常的阈值。例如,污染值 0.1 意味着从训练数据降序排列的归一化距离的前 10% 将用作截止阈值。如果数据点的归一化距离超过阈值,则将其识别为异常。设置合适的污染高度取决于用户或企业的要求。
有关使用 K-means 聚类进行异常检测的更多信息,请阅读:
https://translate.google.com/translate?hl=en&sl=auto&tl=zh&u=https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-detect-anomalies#kmeans_model_example
使用自动编码器模型进行异常检测
使用自动编码器模型,运行 ML.DETECT_ANOMALIES 以检测训练数据或新输入数据中的异常。
首先,创建一个 Autoencoder 模型:
创建模型`mydataset.my_autoencoder_model`OPTIONS(模型_typeu003d'autoencoder', activation_fnu003d'relu', batch_sizeu003d8, dropoutu003d0.2, hidden_unitsu003d[32, 16, 4, 16, 32], learn_rateu003d0.001, l1_reg_activationu003d0.0001, max_iterationsu003d10, optimizeru003d'adam' ) AS SELECT * EXCEPT(Time, Class) FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection`;
要检测训练数据中的异常,需要 ml.detect_ Anomalies 与训练期间使用的数据相同:
选择*从 ML.DETECT_ANOMALIES(模型 `mydataset.my_autoencoder_model`,结构(0.02 作为污染),表 `bigquery-public-data.ml_datasets.ulb_fraud_detection`)
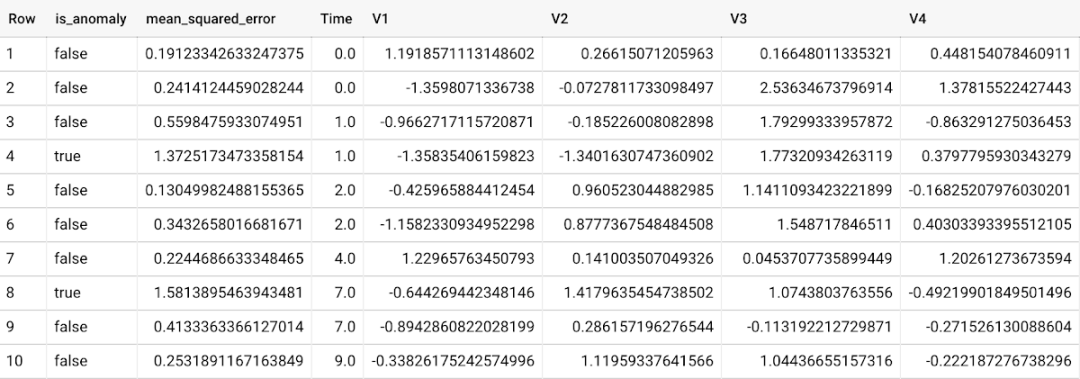
要检测新数据中的异常,请使用 ML.DETECT_ANOMALIES 并提供新数据作为输入:
SELECT *FROM ML.DETECT_ANOMALIES(MODEL `mydataset.my_autoencoder_model`, STRUCT(0.02 AS 污染), (SELECT * FROM `mydataset.newdata`));

Autoencoder 模型的异常检测如何工作?
根据每个输入数据点的重构误差值识别异常。如果超过污染值确定的阈值,则被识别为异常。使用 Autoencoder 模型和数据作为输入,ML.DETECT_ANOMALIES 首先计算每个数据点的原始值和重建值之间的均值_ 平方_ 误差。用户指定的污染值决定了数据点是否被认为异常的阈值。例如,污染值为 0.1 意味着训练数据下降误差的前 10% 将用作截止阈值。设置合适的污染高度取决于用户或企业的要求。
有关使用 Autoencoder 模型进行异常检测的更多信息,您可以阅读文档:
https://translate.google.com/translate?hl=en&sl=auto&tl=zh&u=https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-detect-anomalies#autoencoder_model_example
使用 ARIMA_PLUS 时间序列模型进行异常检测
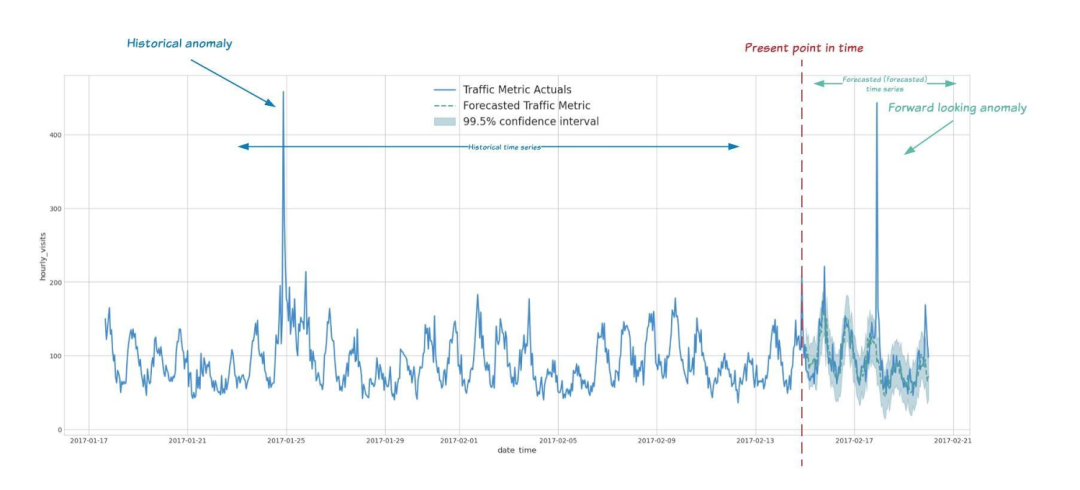
我们现在可以使用 Arima_plus 时间序列模型检测(历史)训练数据或新输入数据中的异常。以下是一些场景下检测时序数据异常的示例:
检测历史数据中的异常:
出于预测和建模目的清理数据,例如在使用历史时间序列训练 ML 模型之前对其进行预处理。
例如,当有大量的零售需求时间序列(邮政编码有数百家商店或数千种产品)时,我们可能希望快速确定哪些商店和产品类别存在异常的销售模式,然后进行更深入的分析。深入分析异常的原因。
前瞻性异常检测:
尽早发现消费者行为和定价异常:例如,如果特定产品页面上的流量突然突然激增,则可能由于定价过程中的错误导致价格异常低。
当有大量的零售需求时间序列(邮编上百家店铺或上千种商品)时,我们可以根据预测判断哪些店铺和商品品类有异常的销售模式,以便快速应对突发事件高峰或低谷。
那么如何使用 ARIMA_PLUS 检测异常呢?首先创建一个 ARIMA_PLUS 时间序列模型:
创建或替换模型 mydataset.my_arima_plus_modelOPTIONS( MODEL_TYPEu003d'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COLu003d'date', TIME_SERIES_DATA_COLu003d'total_amount\ _sold', IME_SERIES_ID_COLu003d'item_name', HOLIDAY_REGIONu003d'US' ) ASSELECT date, item_description AS item_name, SUM(bottles_sold) AS total_amount_soldFROM `bigquery-public-data.iowa_liquor_sales.sales`GROUP BY date, item_nameHAVING date BETWEEN DATE('2016-01-04') AND DATE('2017-06-01') AND item_name IN ("Black Velvet", "Captain Morgan Spiced Rum", "Hawkeye Vodka ”、“五点钟伏特加”、“火球肉桂威士忌”)
要检测训练数据中的异常,还需要对上面得到的模型使用ml.detect_ANOMALIES
选择 * 从 ML.DETECT_ANOMALIES(模型 `mydataset.my_arima_plus_model`, STRUCT(0.8 AS anomaly_prob_threshold));
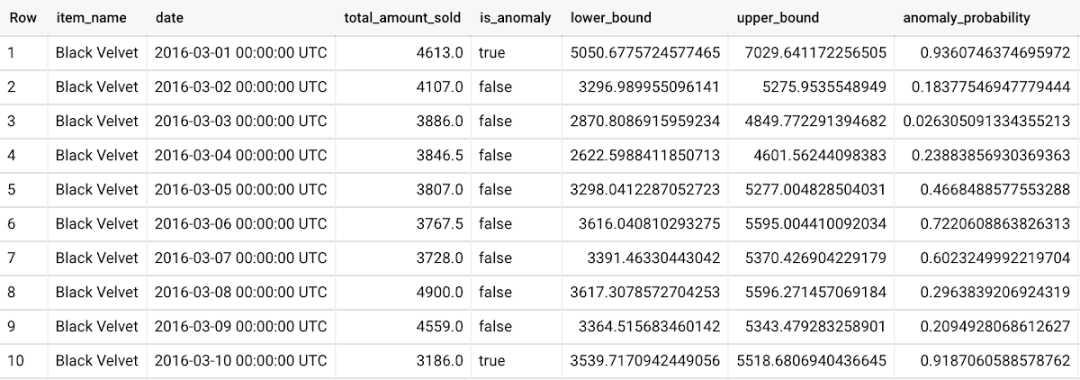
此外,我们还使用 ML.DETECT_ANOMALIES 并提供新数据作为输入:
WITH new_data AS (SELECT date, item_description AS item_name, SUM(bottles_sold) AS total_amount_sold FROM `bigquery-public-data.iowa_liquor_sales.sales`GROUP BY date, item_name HAVING date BETWEEN DATE('2017-06- 02') AND DATE('2017-10-01') AND item_name IN ('Black Velvet', 'Captain Morgan Spiced Rum', 'Hawkeye Vodka', "Five O'Clock Vodka", 'Fireball Cinnamon Whiskey' ) )SELECT *FROM ML.DETECT_ANOMALIES(MODEL `mydataset.my_arima_plus_model`, STRUCT(0.8 AS anomaly_prob_threshold), (SELECT * FROM new_data));
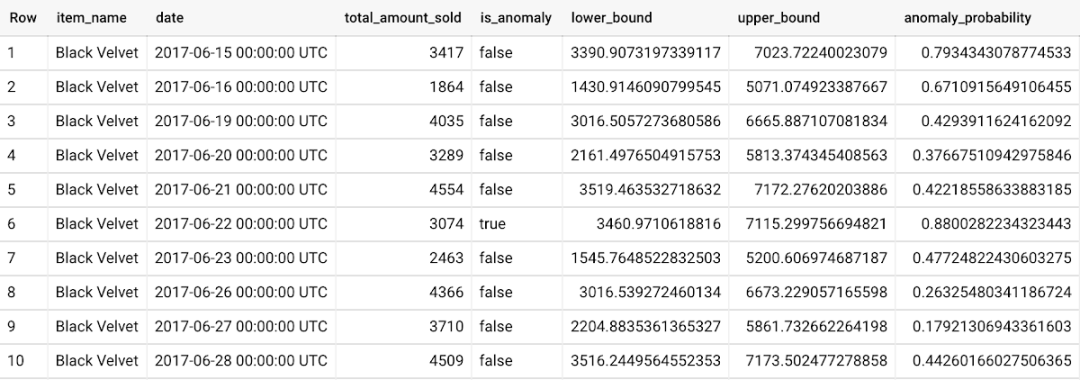
最后,关于使用Arima_关于使用plus时间序列模型进行异常检测的更多信息,请参考文档:https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax -检测异常#arima_plus_model_example_without_specified_settings
编译自:bigquery ml 的新增功能:时间序列和非时间序列数据的无监督异常检测

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20422条内容
已为社区贡献20422条内容

所有评论(0)