
在 Amazon SageMaker 上构建、训练和部署 TensorFlow 深度学习模型:完整的工作流程指南。
简介
机器学习 (ML) 项目大多遵循涉及生成示例数据、训练模型和部署模型的工作流程。
这些步骤具有子任务并且是迭代的。
ML 工程师和数据科学家通常需要一个可以更快地试验和原型化想法的环境。
在原型设计之后,部署和扩展机器学习模型也是一个鲜为人知的谜。
如果没有任何烦人的设置,ML 工程师和数据科学家可以轻松地从实验或原型设计到部署生产就绪和可扩展的 ML 模型,这将是理想和方便的。这就是 Amazon SageMaker 的用武之地。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Tcz1ICXT--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn- images-1.medium.com/max/2000/0%2AeH3exQLyFHE8Swdp.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Tcz1ICXT--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn- images-1.medium.com/max/2000/0%2AeH3exQLyFHE8Swdp.png)
什么是 Amazon SageMaker:
Sagemaker 旨在提供一个平台来支持机器学习模型的开发和部署。
引用自官网:
Amazon SageMaker 是一项完全托管的服务,可为每位开发人员和数据科学家提供快速构建、训练和部署机器学习 (ML) 模型的能力。 SageMaker 消除了机器学习过程中每个步骤的繁重工作,使开发高质量模型变得更加容易。
传统的机器学习开发是一个复杂、昂贵、迭代的过程,因为没有用于整个机器学习工作流程的集成工具,因此变得更加困难。您需要将工具和工作流程拼接在一起,这既耗时又容易出错。 SageMaker 通过在单个工具集中提供用于机器学习的所有组件来解决这一挑战,从而使模型以更少的工作量和更低的成本更快地投入生产。
来源:https://aws.amazon.com/sagemaker/
Amazon SageMaker 的特点:
-
Sagemaker 提供可定制的 Amazon ML 实例以及预加载了 ML 框架和库的开发人员友好的笔记本环境。
-
与 AWS 存储服务无缝集成,例如(s3、RDS DynamoDB、Redshift 等)进行分析。
-
SageMaker 提供 15+ 最常用的ML 算法并且还支持构建自定义算法。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--iWu40eB7--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2000/1%2AJgyk2EiCrwtl2FSzCPNs6w.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--iWu40eB7--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2000/1%2AJgyk2EiCrwtl2FSzCPNs6w.png)
SageMaker 的工作原理
[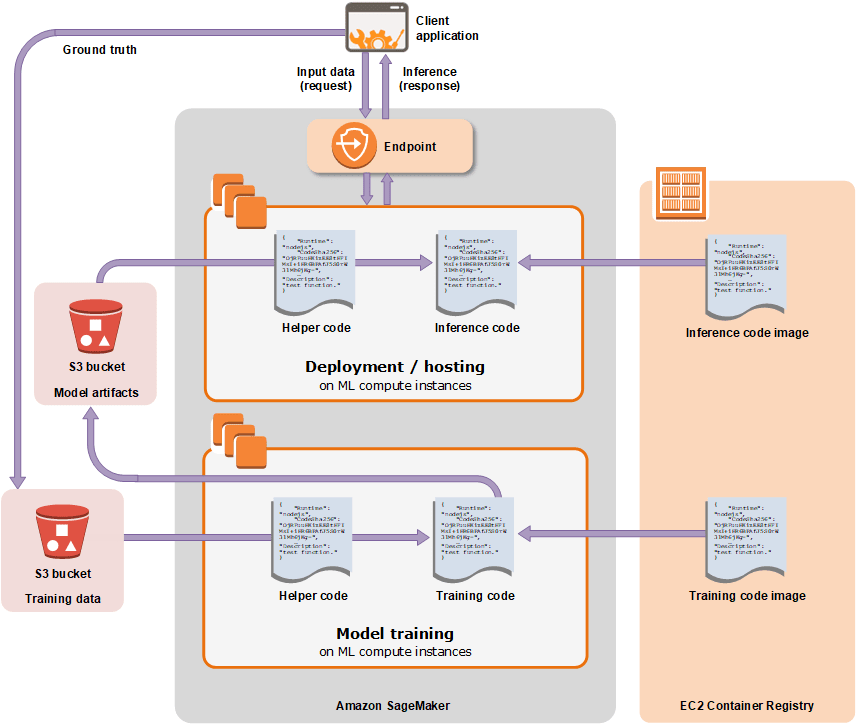 ](https://res.cloudinary.com/practicaldev/image/fetch/s--pKKhUNPg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2000/0%2AgXfeKtFap01dpxVk.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--pKKhUNPg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2000/0%2AgXfeKtFap01dpxVk.png)
要在 sagemaker 上训练模型,您必须通过指定 s3 上训练数据的路径、训练脚本或内置算法以及用于训练的 EC2 容器来创建训练作业。
训练后,模型工件被上传到 s3。通过这个工件,可以在 EC2 容器上创建和部署模型,并使用端点配置进行预测或推理。
我们将建造什么
在本教程中,我们将构建一个机器学习模型来预测文本的情绪。
处理数据和建立模型的细节在我之前的教程中有很好的解释。我们将专注于在 Amazon Sagemaker 上训练和部署模型。
或者,我在本教程中附带了一个完整的笔记本以上传到您的 Sagemaker 笔记本实例中,以便根据需要与本教程一起运行。
我们正在构建一个自定义模型,使用sagemaker python SDK来训练和部署模型要方便得多。
使用 sagemaker 的 Web UI 可以完成相同的任务,主要是在使用内置算法时。
步骤:
-
步骤 1:创建 Amazon S3 存储桶
-
步骤 2:创建 Amazon SageMaker 笔记本实例
-
第 3 步:创建 Jupyter Notebook
-
第 4 步:下载、探索和转换训练数据(参考之前的教程)
-
第 5 步:训练模型
-
步骤 6:将模型部署到 Amazon SageMaker
-
第 7 步:验证模型
-
步骤 8:将 Amazon SageMaker 终端节点集成到面向 Internet 的应用程序中
-
第 9 步:清理
创建 Amazon s3 存储桶:
首先,我们创建一个 s3 存储桶。这是我们将存储训练数据的地方,也是稍后保存模型工件的地方。
创建一个名为 tensorflow_sentiment_analysis 的存储桶
创建 Amazon SageMaker 笔记本实例:
在左侧面板的 AWS 控制台中转到 Sagemaker,单击 Notebook instance (1) *,然后单击 create *Notebook instance (2)。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--rf2uwaTm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/3472/1%2AcG8NIywcetTbjk0l9HCMbQ.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--rf2uwaTm--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/3472/1%2AcG8NIywcetTbjk0l9HCMbQ.png)
在下一页上输入笔记本的名称,您选择的任何名称都可以使用。出于本教程的目的,您可以将其余部分保留为默认值。之后点击创建笔记本实例

将创建笔记本并且状态将在短时间内挂起,然后将切换到 InService。在这个阶段,你可以点击打开 Jupyter 或 Open Jupyter lab。两者的区别在于UI的不同。
我更喜欢使用 Jupyter 实验室,因为它具有文件资源管理器并支持打开文件的多个选项卡,而且感觉更像是 IDE
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--WmPMxSaP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/3280/1%2AU5sP3Hq5HHFNkMRFUeYCDA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--WmPMxSaP--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/3280/1%2AU5sP3Hq5HHFNkMRFUeYCDA.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--O_VrYLvL--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2768/1%2AluUaJwx-zMUONyL1_8DXbA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--O_VrYLvL--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2768/1%2AluUaJwx-zMUONyL1_8DXbA.png)
下载、探索和转换训练数据
下载数据集并将其上传到您的笔记本实例。关于数据的探索和转换的解释请参考这个教程。
数据被转换并保存到 s3 中。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--_xi3lg1q--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2000/1%2A-iMWq64MDPbe3w28dGoCxg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--_xi3lg1q--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2000/1%2A-iMWq64MDPbe3w28dGoCxg.png)
在您可以使用 sagemaker SDK API 之前,您必须创建一个会话,
然后您使用数据名称和键前缀(即 s3 存储桶的路径)调用 upload_data。
这将返回数据文件的完整 s3 路径。如上图,您可以查询验证。
训练模型
要训练 TensorFlow 模型,您必须使用 sagemaker SDK 中的 TensorFlow 估算器
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--7sqxfaV6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2000/1%2AFnbw0g2aBwHda-E7HcWuMg.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--7sqxfaV6--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2000/1%2AFnbw0g2aBwHda-E7HcWuMg.png)
**entry_point: **这是定义和训练模型的脚本。该脚本将在容器中运行。 (稍后会详细介绍)
role: 分配给正在运行的笔记本的角色。你可以通过运行 coderole u003d sagemaker.get_execution_role()
train_instance_count:为训练模型而启动的容器实例数。
train_instance_type:实例类型用于训练模型的容器。
framwork_version: 训练脚本中使用的 TensorFlow 版本。你可以通过运行 tf_version u003d tf.version
py_version: 使用的 Python 版本。
script_mode: 如果设置为 True,估计器将使用脚本模式容器(默认值:False)。如果 py_version 设置为“py3”,这将被忽略。
这允许在容器中运行任意脚本代码。
hyperparameters:运行训练脚本所需的参数。
既然您知道了每个参数的含义,那么我们来了解一下训练脚本的内容。
%%writefile train.py
import argparse
import os
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM,Dense
from tensorflow.keras.layers import Embedding, Dropout
import pandas as pd
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# hyperparameters sent by the client are passed as command-line arguments to the script.
parser.add_argument(‘--pochs’, type=int, default=10)
parser.add_argument(‘--batch-size’, type=int, default=100)
parser.add_argument(’--learning-rate’, type=float, default=0.1)
parser.add_argument(‘--gpu-count’, type=int,
default=os.environ['SM_NUM_GPUS'])
# input data and model directories
parser.add_argument(‘--model-dir’, type=str,
default=os.environ['SM_MODEL_DIR'])
parser.add_argument(‘--train’, type=str,
default=os.environ['SM_CHANNEL_TRAIN'])
args, _ = parser.parse_known_args()
epochs = args.epochs
lr = args.learning_rate
batch_size = args.batch_size
gpu_count = args.gpu_count
model_dir = args.model_dir
training_dir = args.train
training_data = pd.read_csv(training_dir+’/train.csv’,sep=’,’)
tweet = training_data.text.values
labels = training_data.airline_sentiment.values
num_of_words = 5000
token = Tokenizer(num_words=num_of_words)
token.fit_on_texts(tweet)
vocab_size = len(token.word_index) + 1 # 1 is added due to 0 index
tweet_sequence = token.texts_to_sequences(tweet)
max_len = 200
padded_tweet_sequence = pad_sequences(tweet_sequence,
maxlen=max_len)
# Build the model
embedding_vector_length = 32
model = Sequential()
model.add(Embedding(vocab_size, embedding_vector_length,
input_length=max_len))
model.add(Dropout(0.2))
model.add(LSTM(100))
model.add(Dropout(0.2))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’,optimizer=’adam’,
metrics=[‘accuracy’])
model.fit(padded_tweet_sequence,labels,validation_split=0.3,
epochs=epochs, batch_size=batch_size, verbose=2)
tf.saved_model.simple_save(
tf.keras.backend.get_session(),
os.path.join(model_dir, ‘1’),
inputs={‘inputs’: model.input},
outputs={t.name: t for t in model.outputs})
第一行是将单元格的内容写入文件 train.py 的命令。
由于 SageMaker 会导入您的训练脚本,因此您应该将训练代码放在主保护中(如果 name\u003du003d'main':),以便 SageMaker 不会无意中在错误的位置运行您的训练代码在执行中。
所有超参数都作为命令行参数传递给脚本。
训练脚本还可以访问训练容器实例中的环境变量。比如下面的
-
SM_MODEL_DIR:一个字符串,表示训练作业将模型工件写入的路径。训练后,此目录中的工件将上传到 S3 以进行模型托管。
-
SM_NUM_GPUS:一个整数,表示主机可用的GPU数量。
-
SM_CHANNEL_XXXX:一个字符串,表示包含指定通道的输入数据的目录的路径。例如,如果您在 Tensorflow 估计器的 fit 调用中指定两个输入通道,名为“train”和“test”,则设置环境变量 SM_CHANNEL_TRAIN 和 SM_CHANNEL_TEST。
脚本的中间部分是通常的模型定义和训练。
最后一部分将模型工件保存到提供的 s3 路径。注意路径是如何通过附加数字来创建的。
要开始训练,请调用 fit 方法并将训练数据路径传递给它以开始训练。这会在 sagemaker 上创建一个培训工作。您可以查看培训作业部分以查看创建的作业。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--1haMJuq0--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2000/1%2Amgs7iiVBzGxe6XAhkzcIyA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--1haMJuq0--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images- 1.medium.com/max/2000/1%2Amgs7iiVBzGxe6XAhkzcIyA.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--oWjz02vX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn- images-1.medium.com/max/3838/1%2ABNhyQdBA9eFBvGY9ETx_fA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--oWjz02vX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn- images-1.medium.com/max/3838/1%2ABNhyQdBA9eFBvGY9ETx_fA.png)
如果一切顺利,您应该在输出日志的最后一部分看到下面的输出。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--niVJMvWW--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2494/1%2AEDdEkvMRDAJJNCi0gmzqAQ.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--niVJMvWW--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2494/1%2AEDdEkvMRDAJJNCi0gmzqAQ.png)
将模型部署到 Amazon SageMaker
要部署,我们通过传递以下参数调用估算器上的部署方法。
initial_instance_count: 午餐推理实例的初始数量。
如果请求负载增加,这可以扩大。
instance_type: 推理容器的实例类型。
endpoint_name: 模型端点的唯一名称。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--mquPkawX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2000/1%2AIp00HazJKdG8V5_LeT-OHA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--mquPkawX--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2000/1%2AIp00HazJKdG8V5_LeT-OHA.png)
验证模型
调用 deploy 方法后,返回模型的端点,这可用于使用测试数据验证模型,如下所示。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--G8x80aCS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2106/1%2AkdSGr6FcXXnf512Yr1FSMQ.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--G8x80aCS--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2106/1%2AkdSGr6FcXXnf512Yr1FSMQ.png)
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--ldR0Ryko--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2380/1%2A1IpefzCURpeOPdKJtDbeWA.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--ldR0Ryko--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1。 medium.com/max/2380/1%2A1IpefzCURpeOPdKJtDbeWA.png)
将 Amazon SageMaker 终端节点集成到面向 Internet 的应用程序中。
ML 模型的最终用途是让应用程序向其发送请求以进行推理/预测。这可以使用 API 网关和 lambda 函数来完成。

应用程序将向 API 端点发出请求,这将触发一个 lambda 函数,该 lambda 函数会将数据预处理为输入模型所期望的。即将文本输入转换为数字表示,然后将其发送到模型进行预测。
预测结果由 lambda 函数接收,然后返回 API 网关发送给用户。
清理
确保调用 end_point.delete_endpoint() 删除模型端点。
继续从您的 s3 存储桶中删除 sagemaker 上传的所有文件。
结论
在本教程中,您学习了如何在 Amazon Sagemaker 上训练和部署深度学习模型。
这是完整笔记本的链接。
资源
-
https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html
-
https://www.tensorflow.org/tfx/serving/serving_basic
-
https://sagemaker.readthedocs.io/en/stable/index.html#
-
https://medium.com/r/?urlu003dhttps%3A%2F%2Fwww.kaggle.com%2Fcrowdflower%2Ftwitter-airline-sentiment
-
https://medium.com/datadriveninvestor/deep-learning-lstm-for-sentiment-analysis-in-tensorflow-with-keras-api-92e62cde7626

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20422条内容
已为社区贡献20422条内容

所有评论(0)