
ETL com Apache Airflow、Web Scraping、AWS S3、Apache Spark e Redshift |第 1 部分
在这篇文章中,我将向您展示如何使用最著名的流管理工具之一 Apache Airflow 来自动化提取、转换和加载 (ETL) 流。为了更好地解决该项目所涉及的主题,它分为两个部分,将产生两个出版物。
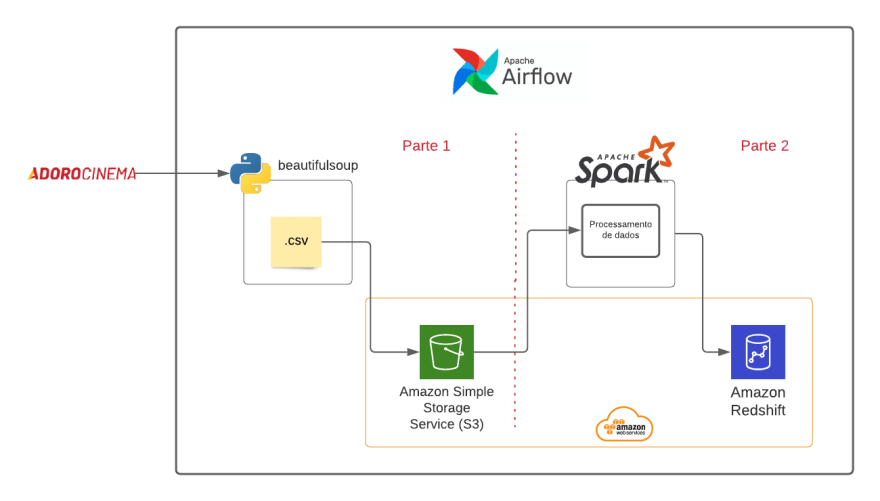
在第一部分中,我将向您展示如何使用 Airflow 开发 ETL 流程的开始。我们将使用 BeautifulSoup 构建一个 Web Scraper,从网站AdoroCinema中提取电影评分信息,我们将使用获得的数据编写一个 .csv 文件并将其发送到 AWS S3。在本项目的第二部分,我们将 Airflow 与 Apache Spark 集成,对发送到 AWS S3 的文件进行一些处理,然后将处理结果存储在 Amazon Redshift 中。
项目代码在此处可用。
气流
这是 Aibnb 公司开发团队内部开发的一个项目,它是作为解决该部门发现的随着公司数据环境日益复杂的问题而出现的工具。 Airflow 于 2014 年底出现,并于 2015 年在 Airbnb 博客](https://medium.com/airbnb-engineering/airflow-a-workflow-management-platform-46318b977fd8)上出现[,此后在数据工程社区中流行起来。最后,在一段时间后,该项目被割让给今天负责维护该项目的 Apache,今天该项目被称为Apache Airflow。
初始项目设置
对于这个发展阶段,有必要提供:
-
docker 和 docker-compose 在你的机器上。
-
AWS 账户。
-
aws cli 安装在您的机器上。
-
已配置存储桶 S3。
使用的 docker 映像是puckel/docker-airflow,我在其中添加了 BeautifulSoup 作为在我的机器上创建映像的依赖项。
Docker 容器中 Airflow 使用的 AWS 凭证设置取自您在 bash 中运行以下命令时生成的本地 .aws 文件:
$ aws configure
进入全屏模式 退出全屏模式
待实施流程
该项目将包括两个阶段,在第一次发布中,我们将实施第 1 部分的流程。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--TrtH699j--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/5tj8vipcy05ar43k2011.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--TrtH699j--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/5tj8vipcy05ar43k2011.png)
Web Scraping com BeautifulSoup
Web Scraping 是自动获取 Internet 上可用信息的过程。要执行此过程,首先我们需要更好地了解我们将要探索的网页,检查页面的 HTML 是一个非常重要的步骤,以便能够了解您在构建过程中会寻找哪些属性网络刮刀。为此,您可以使用浏览器中的 Developer Tools 功能并探索您想要获取的信息的 HTML 结构。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--w6Y-YjhG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/f0c7s5x1mvkv7swf4k5k.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--w6Y-YjhG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/f0c7s5x1mvkv7swf4k5k.png)
对于我的收藏,我选择了有关标题、类型、海报照片网址、概要概要、发行日期、完整概要、可用评级和有关给定电影的 adoracinema 出版链接的信息。完整的概要是从发布链接获得的,因为完整的概要未显示在此列表页面上。有时浏览链接以组合答案是必要的,因为信息可能不会完全显示在您开始搜索的页面上。
此外,我考虑的另一个主题是收视率,我想获得所有可用的收视率,重要的是要注意有 3 个收视率评级:AdoroCinema、Press 和 Readers,对于某些电影,收视率或更高可能没有评级。为此,需要在选择正确的 HTML 组件时进行处理,对于没有分类的评估器,我以空信息完成,因为将来我可以应用一些数据清洗技术。
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
def scraping_avaliacao_adoro_cinema(page = 1):
URL = f"http://www.adorocinema.com/filmes/todos-filmes/notas-espectadores/?page={page}"
html_doc = urlopen(URL).read()
soup = BeautifulSoup(html_doc, "html.parser")
data = []
for dataBox in soup.find_all("div", class_="data_box"):
titleObj = dataBox.find("a", class_="no_underline")
imgObj = dataBox.find(class_="img_side_content").find_all(class_="acLnk")[0]
sinopseObj = dataBox.find("div", class_="content").find_all("p")[0]
dateObj = dataBox.find("div", class_="content").find("div", class_="oflow_a")
movieLinkObj = dataBox.find(class_="img_side_content").find_all("a")[0]
generoObj = dataBox.find("div", class_="content").find_all('li')[3].find('div',class_="oflow_a")
detailsLink = 'http://www.adorocinema.com' + movieLinkObj.attrs['href']
avaliacoesMeios = dataBox.find("div", class_="margin_10v").find_all('span', class_="acLnk")
avaliacoesNotas = dataBox.find("div", class_="margin_10v").find_all('span', class_="note")
# tratar a lista de avaliações
avaliadores = [ elem.text.strip() for elem in avaliacoesMeios if elem.text.strip() != "" ]
# vincular com notas
avaliacoesValores = {"AdoroCinema" : None, "Leitores" : None, "Imprensa" : None}
for index, avaliador in enumerate(avaliadores):
avaliacoesValores[avaliador] = avaliacoesNotas[index].text.strip()
#Carregar a sinopse completa
htmldocMovieDetail = urlopen(detailsLink).read()
soupMovieDetail = BeautifulSoup(htmldocMovieDetail, "html.parser")
fullSinopse = soupMovieDetail.find(class_="content-txt")
fullImgObj = soupMovieDetail.find("meta", property="og:image")
data.append({'titulo': titleObj.text.strip(),
'genero': generoObj.text.replace('\n','').strip(),
'poster' : fullImgObj["content"],
'sinopse' : sinopseObj.text.strip(),
'data' : dateObj.text[0:11].strip(),
'link' : detailsLink,
'avaliacoes' : avaliacoesValores,
'sinopseFull': fullSinopse.text})
return data
进入全屏模式 退出全屏模式
这里你可以查看一篇非常完整的文章,解释了 BeautifulSoup 的使用。
天
Airflow 使用一种称为 DAG - Directed Acyclic Graph 的结构,它通常是一个非循环图,其中要执行的所有任务都是结构化的,反映了它们的依赖关系和关系。可以进行许多配置,例如应用使用条件,例如仅当前一个节点成功时才运行节点等,可以配置超时、重启时间等。
默认情况下,Aifrlow 将项目的 DAG 标识为存储在 dags 文件夹中的每个 python 文件,但如果您想更改 DAG 的位置,可以覆盖此设置。
创建一个有向无环图
要创建 DAG,我们需要定义一些初始属性,例如 dag_id、schedule_interval 和一些 args。
-
dag_id:是流的唯一标识,这里我们称之为'etl_movie_review'。
-
schedule_interval:表示任务执行的周期。
-
default_args:是将反映在DAG的所有节点中的信息。
from airflow import DAG
from datetime import datetime, timedelta
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from etl_scripts.load_to_s3 import local_to_s3
from etl_scripts.web_scraping import collect_adoro_cinema_data
from etl_scripts.remove_local_file import remove_local_file
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": datetime(2021, 1, 1),
"retries": 0,
}
with DAG(
"etl_movie_review",
schedule_interval=timedelta(minutes=1),
catchup=False,
default_args=default_args
) as dag:
(...)
进入全屏模式 退出全屏模式
创建 DAG 任务
为了构建我们的节点,Airflow 使用了 Operators,它们是封装了为某些类型的连接执行工作的逻辑的类。在我们的项目中,我们现在将仅使用 PythonOperator 和 DummyOperator, 来分别进行 Python 代码执行调用并指示流程的开始和结束。除了这些还有其他一些,您可以在此处找到运营商的列表。
(...)
# Inicio do Pipeline
start_of_data_pipeline = DummyOperator(task_id='start_of_data_pipeline', dag=dag)
# Definindo a tarefa para realização de web scrapping
movie_review_web_scraping_stage = PythonOperator(
task_id='movie_review_web_scraping_stage',
python_callable=collect_adoro_cinema_data,
op_kwargs={
'quantidade_paginas': 1,
},
)
# definindo a tarefa para enviar o arquivo csv para S3.
movie_review_to_s3_stage = PythonOperator(
task_id='movie_review_to_s3_stage',
python_callable=local_to_s3,
op_kwargs={
'bucket_name': '<nome-do-seu-bucket>'
},
)
movie_review_remove_local = PythonOperator(
task_id='movie_review_remove_local',
python_callable=remove_local_file,
)
# Fim da Pipeline
end_of_data_pipeline = DummyOperator(task_id='end_of_data_pipeline', dag=dag)
进入全屏模式 退出全屏模式
所以,我们准备好了 DAG,它有 2 个 Dummy 任务,即仅用于表示流程的开始和结束,以及 3 个在 Python 代码中执行功能的任务。创建的每个任务也有一个唯一的 ID 用于识别,重要的是这些 ID 也是唯一的,否则 Airflow 将返回一个错误,说明循环的创建已被识别。
最后,我们需要创建任务之间的链接并定义执行顺序,Airflow 允许一些方式来声明这个顺序,对于本教程,我们将遵循最简单的格式。
start_of_data_pipeline >> movie_review_web_scraping_stage >> movie_review_to_s3_stage >> movie_review_remove_local >> end_of_data_pipeline
进入全屏模式 退出全屏模式
在我们的 PythonOperator 任务中,我们调用了 3 个 Python 函数:collect_adoro_cinema_data、local_to_s3 和 remove_local_file。第一个封装了Web Scraper,将采集到的数据写入到一个临时文件夹中的.csv文件中,第二个和第三个是负责与S3集成并发送文件,然后从磁盘中删除.csv文件的函数。
import os
import glob
from airflow.hooks.S3_hook import S3Hook
def local_to_s3(bucket_name, filepath='./dags/data/*.csv'):
s3 = S3Hook()
for f in glob.glob(filepath):
key = 'movie_review/'+f.split('/')[-1]
s3.load_file(filename=f, bucket_name=bucket_name,
replace=True, key=key)
def remove_local_file(filepath='./dags/data/*.csv'):
files = glob.glob(filepath)
for f in files:
os.remove(f)
进入全屏模式 退出全屏模式
从面板运行 DAG
在 Airflow 的初始屏幕上,我们将看到应用程序中标识的所有 DAG 的列表,要运行它们,只需将 OFF 按钮拖到 ON.
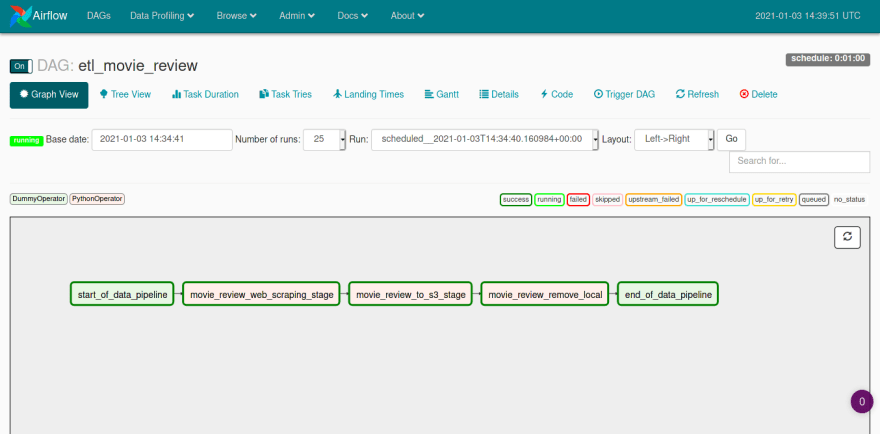
我们可以进入 Graph 视图模式并检查我们的任务及其关系,它们会根据执行状态改变颜色,当成功完成执行时,它们的边框会变为绿色。在面板中,您还可以识别流中使用的运算符类型。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--i-Rw5aHl--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/hmzflm7jjg9n9juj3e91.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--i-Rw5aHl--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/hmzflm7jjg9n9juj3e91.png)
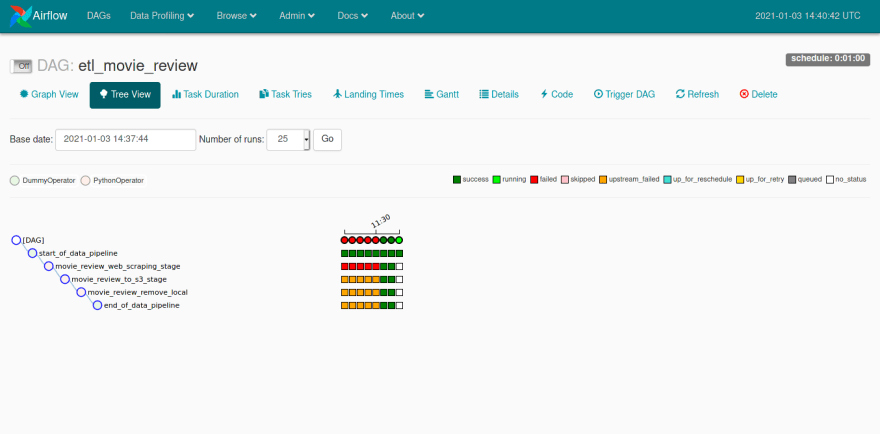
Airflow 提供了许多可视化流程运行的方法,您可以在树视图模式下跟踪每次运行的成功和失败程度,也可以按照其他类型的图表显示运行信息。您还可以访问每个任务的执行日志,以及访问 DAG 代码,这是一个非常完整的面板,可以监控创建的任务。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--xA-53ZwD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/ttkbhind0noawfp9l62t.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--xA-53ZwD--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https:// dev-to-uploads.s3.amazonaws.com/i/ttkbhind0noawfp9l62t.png)
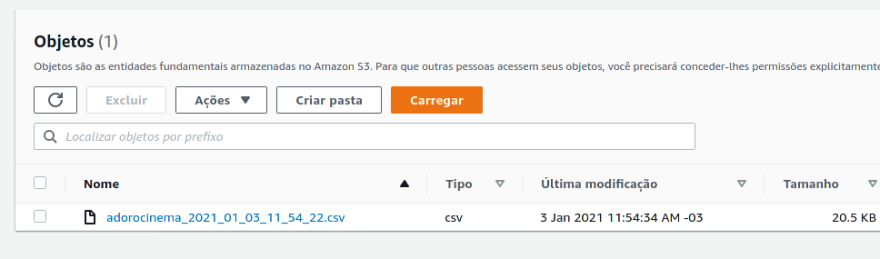
最后,在任务执行结束时,我们使用从 AdoroCinema 获得的电影信息生成了一个 .csv 文件,并将其发送到配置的 S3 存储桶。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--246ZZ0n3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/wq019n62mi3j66f5bb0v.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--246ZZ0n3--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/wq019n62mi3j66f5bb0v.png)
结论
最后,我们完成了项目的第一阶段,现在我们有关于从 AdoroCinema 网站收集到的互联网上有关电影的 S3 信息。在下一步中,我们将从 S3 读取此文件并使用 Apache Spark 对此数据进行一些处理,然后我们将能够在 Amazon Redshift 上的数据仓库中提供此处理的结果。
希望大家喜欢,有什么问题可以在评论区留言。到下一个!

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20424条内容
已为社区贡献20424条内容

所有评论(0)