
如何DIY廉价云数据湖
介绍
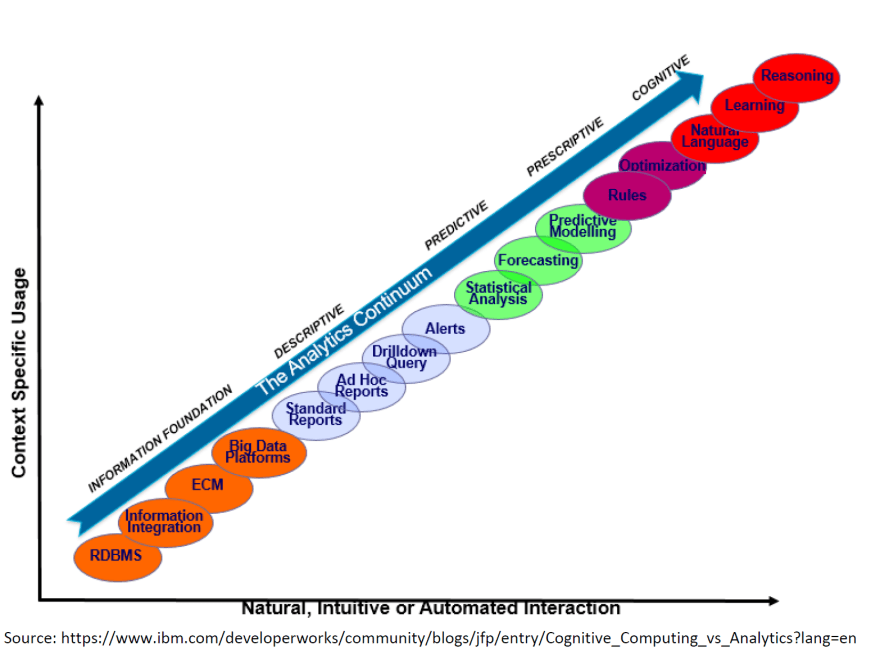
最近对数据驱动应用程序的兴趣激增导致我尝试在云上构建数据湖。我一直都是自己做事的人,也是开源又名 DIY 和开源的粉丝。数据科学就是关于人们如何使用这些收集的数据并“从中学习”。我将涵盖监督。无监督和强化学习 在另一篇文章中。公司积极使用数据有 5 个阶段(Analytics Continuum):
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--ES2xbEbd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/d8y0d0qecx5ilotdeukf.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--ES2xbEbd--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/d8y0d0qecx5ilotdeukf.png)
不要为此烦恼和失眠,数据科学家有酬劳,可以施展魔法,让认知涅槃阶段发挥作用。认知意味着机器像人类一样行为和思考。
数据湖
简而言之,这就是数据湖:
Zaloni 将其描述为:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--zE0v0QKB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/vd2kdva2hpjy04r5hnhd.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--zE0v0QKB--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/vd2kdva2hpjy04r5hnhd.png)
或者用更简单的术语说:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--HLH1RnsK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/jtmswy8zr8p18dx6l0d7.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--HLH1RnsK--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/jtmswy8zr8p18dx6l0d7.png)
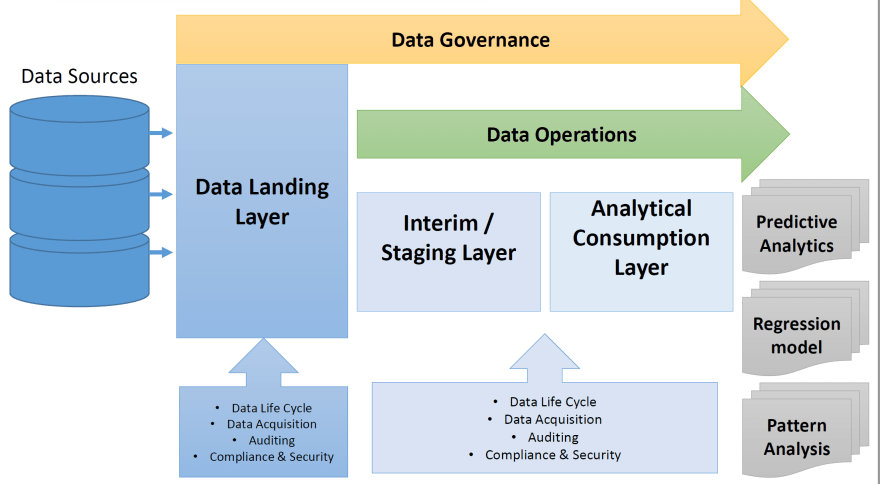
数据生命周期:摄取、ETL、建模和数据发布、内务管理和再培训。
- 摄取
在 Kubernetes 集群中安装一个 Apache NIFI 集群以从 MQTT 摄取数据,从 API Endpoints 拉取数据。此外,其他人接收数据需要 API Gateway。对于冷流,数据将保存在使用数据库、HDFS、ElasticSearch 实现的**STAGING** 区域中。对于 实时流,数据进入建模阶段(如果您使用 AWS Kinesis Analysis,可以将数据推送到 AWS Kinesis Stream)。
- ETL
在将数据移动到模型的输入之前,您可以安装和使用 Apache Airflow 来执行预填充的 Python 脚本。同样,在这里我们可以将处理后的数据存储在文档存储中,如 Mongo 或 Graph-store Neo4J。
- 型号
模型是一堆接受输入、应用数学并输出结果的代码。可以使用 Python Scikit-Learn 和实时流式传输 Apache Spark Graph 来实现模型(AWS Kinesis Analytics 是这里的替代方案)。这些模型的输出可以分为**预测分析、回归模型、模式分析。所有这些基本上都是数学。数学是有效的:算术、微积分和几何 (2d/3d)**。在 Kubernetes 集群中运行这些建模代码。
以下是各种建模技术:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--hA9uYCiZ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/l1acs9d0jfg3v5rtr5vc.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--hA9uYCiZ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/l1acs9d0jfg3v5rtr5vc.png)
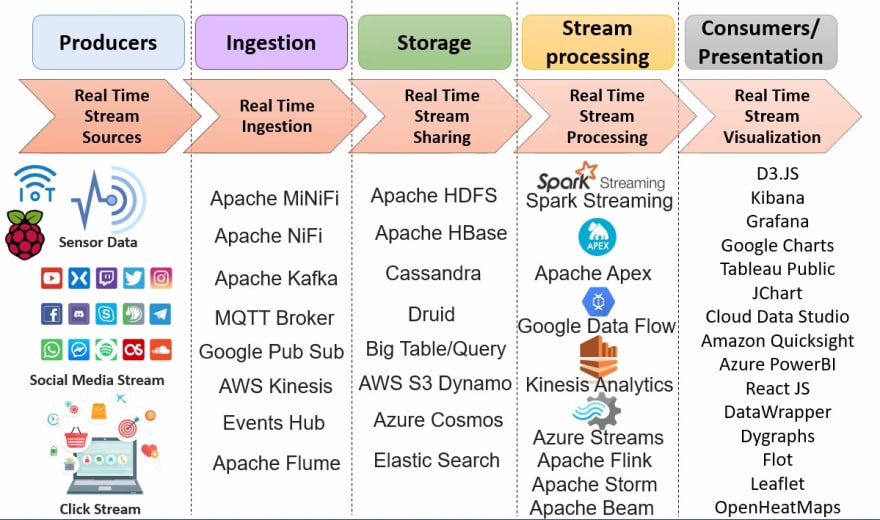
以下是实时流媒体平台:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--W3b2tROk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/aampwgfsh58t2xjej4uw.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--W3b2tROk--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/aampwgfsh58t2xjej4uw.png)
- 数据发布
实际上,模型输出的数据可以用于其他供应商或微服务。数据发布到 Apache Kafka 并保存在自我管理的 Mongo 中。
可以使用 API Gateway 从端点订阅 Insight Data。每个客户都将获得一个合法的访问密钥来访问端点。数据也可以显示在 Kibana 等仪表板中,供客户使用。我们可以在 Kubernetes 集群中设置一个 ELK 堆栈,或者您可以订阅 AWS OpenSearch 之类的服务。数据输出可以通过工作流程进行检查,例如,如果发现异常,则向利益相关者发送电子邮件警报。使用本机服务(AWS SES 和 AWS Lambda)是有意义的。
- 家政服务
必须使用在 cron-jobs 或 AWS Lambda 中运行的脚本清除数据>保留期。
- 再培训
进来的原始数据必须存储在某个地方以重新训练模型。在这种情况下,我们可以使用 EBS、EFS、Blob Storage 之类的存储。对于模型的重新训练和重新部署 (CI/CD),我们可以使用 Apache MLFlow 之类的工具。
下一步是什么
- 数据治理
在完成基础管道之后,下一阶段是实施数据治理。我们可以使用开源**Apache Altas**。 Talend Data Governance Platform 是一个更企业化的平台。
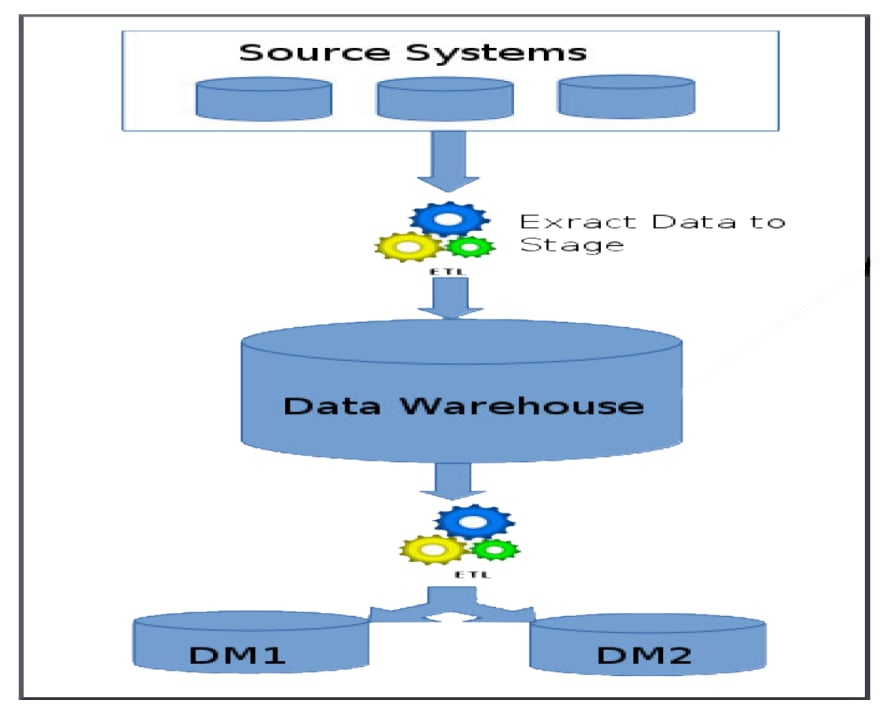
- 数据仓库
然后可以将数据湖的输出存储在结构化的 data 仓库 (AWS Redshift) 中并创建 data-mart。 Snowflake 云数据平台 是这里的热门选择。
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--x6_C9kZq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/jmmmihoaklla3akel88a.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--x6_C9kZq--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/uploads/articles/jmmmihoaklla3akel88a.png)

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20427条内容
已为社区贡献20427条内容

所有评论(0)