
Python 和 Pandas 中的数据整理:处理和准备数据以供分析
在这篇文章中,我将介绍一些可以使用 Python 和 Pandas 进行的基本数据整理技术。其实这里我也会介绍一下优秀的Python包dfply。
什么是数据整理,为什么它是 Python 中的一项重要技术?
数据处理称为数据整理、数据整理、数据、垃圾处理或数据准备过程。处理数据的目的是格式化信息,以便以后对其进行分析。这一步非常重要,因为大部分工作时间通常用于处理数据。通常,大多数分析代码(例如,在 Python 中)将关注数据处理,即处理数据。因此,以有效和稳健的方式学习这一点非常重要。毫无疑问,选择数据的行和列是最基本的两个任务。此外,添加新变量(例如,Pandas 数据框的列)或修改变量也是两个基本任务的示例。
因此,重要的是要从例如R 和 Python 教程和Pandas 教程中学习,比如这个。
今天,有所有必要的功能来处理数据。然而不幸的是,这些特性通常难以使用或导致代码难以阅读。 R 社区的开发人员和数据科学家很早就注意到了这一点,并提出了几个库来进行数据整理。我最喜欢的库之一无疑是 dplyr,它是 tidyverse 库的一部分,而 dplyr 可能是最具革命性的库,因为它引入了一种全新的数据处理方式。在 dplyr 中,简洁是重点;具有少量功能,其中一些简单易用,可实现强大的数据处理。 Python 社区观察到 dplyr 变得非常流行,正因为如此,有等效的 Pyton 包。事实上,Python 共有三个包:dfply、pandas-ply 和 plython。在这篇文章中,我将举例说明这些软件包之一的强大和简单;飞行。我想说,这使得 Pandas(和 dfply)成为数据科学](https://dev.to/marsja/essential-python-libraries-for-data-science-machine-learning-and-statistics-5175)的[个基本 Python 包之一。
安装Python包
如果您需要安装 Pandas 和 dfply,以下是使用 pip 安装它们的方法:
pip install pandas dfply
在 Python 中使用 Pandas 导入数据
现在,在我们继续了解如何使用 Python 处理数据之前,我们需要一些示例数据。在这里,您将从 URL 导入数据集(来自 .csv 文件):
import pandas as pd
df = pd.read_csv('https://vincentarelbundock.github.io/Rdatasets/csv/Ecdat/Earnings.csv',
index_col=0)
可以使用 head() 方法检查数据集的前五行:
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--WA1oEFdG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/mnrkdrefsehc5r645yf3.JPG)
](https://res.cloudinary.com/practicaldev/image/fetch/s--WA1oEFdG--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev- to-uploads.s3.amazonaws.com/i/mnrkdrefsehc5r645yf3.JPG)
在 Python 中使用 Pandas 和 dfply 处理数据
在本节中,您将学习如何使用 dfply 重命名 Pandas 数据帧中的列。在此之后,您将学习如何计算简单的描述性统计数据。
使用 dlfply 更改 Pandas 数据框中的列名
以下是更改数据框中的列名是多么容易。首先,我们导入 dlfply:
from dlfply import *
这是通过使用函数 from 来完成的,后跟一个 *,它将激活 Python 库中可用的所有函数,我们不必编写“dfply”。在我们要使用的每一个功能前面。
其次,我们使用管道和 rename() 方法:
df = df >> rename(Wage='y',
Age='age')
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--Hm_0juOU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/i/6wpd5eecnfkrk2nvmd12.JPG)
](https://res.cloudinary.com/practicaldev/image/fetch/s--Hm_0juOU--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev -to-uploads.s3.amazonaws.com/i/6wpd5eecnfkrk2nvmd12.JPG)
请注意,我们如何使用 >> 来创建事件链。在上面的简单示例代码中,它的真正威力可能并不明显。但是,使用这种方法使我们能够在一行代码中执行大量数据整理任务。
使用 dlfply(和 Pandas)在 Python 中汇总统计数据
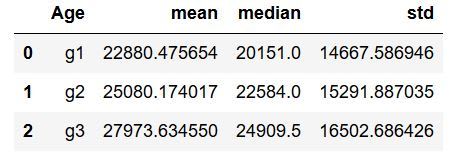
以下是使用 dlfply 计算描述性统计数据(按组)是多么容易:
df >> group_by('Age') >> summarize(mean=X.Wage.mean(),
meadian=X.Wage.median(),
std=X.Wage.std())
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--JnLKZAkp--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/i/m71rlnv9ffzvrmsjrdkj.JPG)
](https://res.cloudinary.com/practicaldev/image/fetch/s--JnLKZAkp--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://dev-to- uploads.s3.amazonaws.com/i/m71rlnv9ffzvrmsjrdkj.JPG)
同样,代码以“df >> group_by('Age')开头,解释为“以df开头,然后按年龄组分组df”。这意味着将在Age上执行以下功能组(从列中)。然后,我们继续总结(meanu003dX.Wage.mean(),这意味着我们描述了它;包括平均值、中位数和工资的标准差。请注意,我们确实使用X 告诉 Python Wage 是从我们以 (df) 开始的同一个数据帧派生的。
希望你学到了一些东西,如果你学到了,请分享!

华为、百度、京东云现已入驻,来创建你的专属开发者社区吧!
更多推荐
 0
0 0
0- 0



 已为社区贡献20426条内容
已为社区贡献20426条内容

所有评论(0)