
AI 从来没有真正「听过」你说话|Qwen3.5-Omni 评测
摘要:阿里通义千问最新发布的Qwen3.5-Omni突破了传统AI"伪听觉"局限,实现原生全模态理解。该模型采用Thinker-Talker双核架构,支持113种语言识别,能同时处理音视频、文本等多模态输入,并保持256K tokens长上下文能力。通过四大极限测试验证,其具备复杂叙事理解、商业逻辑推理、口述编程等创新功能,在215项评测中取得SOTA成绩。Qwen3.5-Om
AI 从来没有真正「听过」你说话|Qwen3.5-Omni 评测
摘要:过去的大模型能"看懂"图片、"读懂"文字,却从未真正"听懂"人话。阿里通义千问最新发布的 Qwen3.5-Omni,以原生全模态架构打破这一僵局——它不仅能听懂 113 种语言,更能理解语气、情绪、背景音,甚至"边看视频边听指令"写代码。本文通过 4 个极限测试场景,带你看看什么才是真正的「全模态 AI」。
关键词:Qwen3.5-Omni, 全模态大模型, 通义千问, 音视频理解, Vibe Coding, 实时语音交互, 多模态 AI
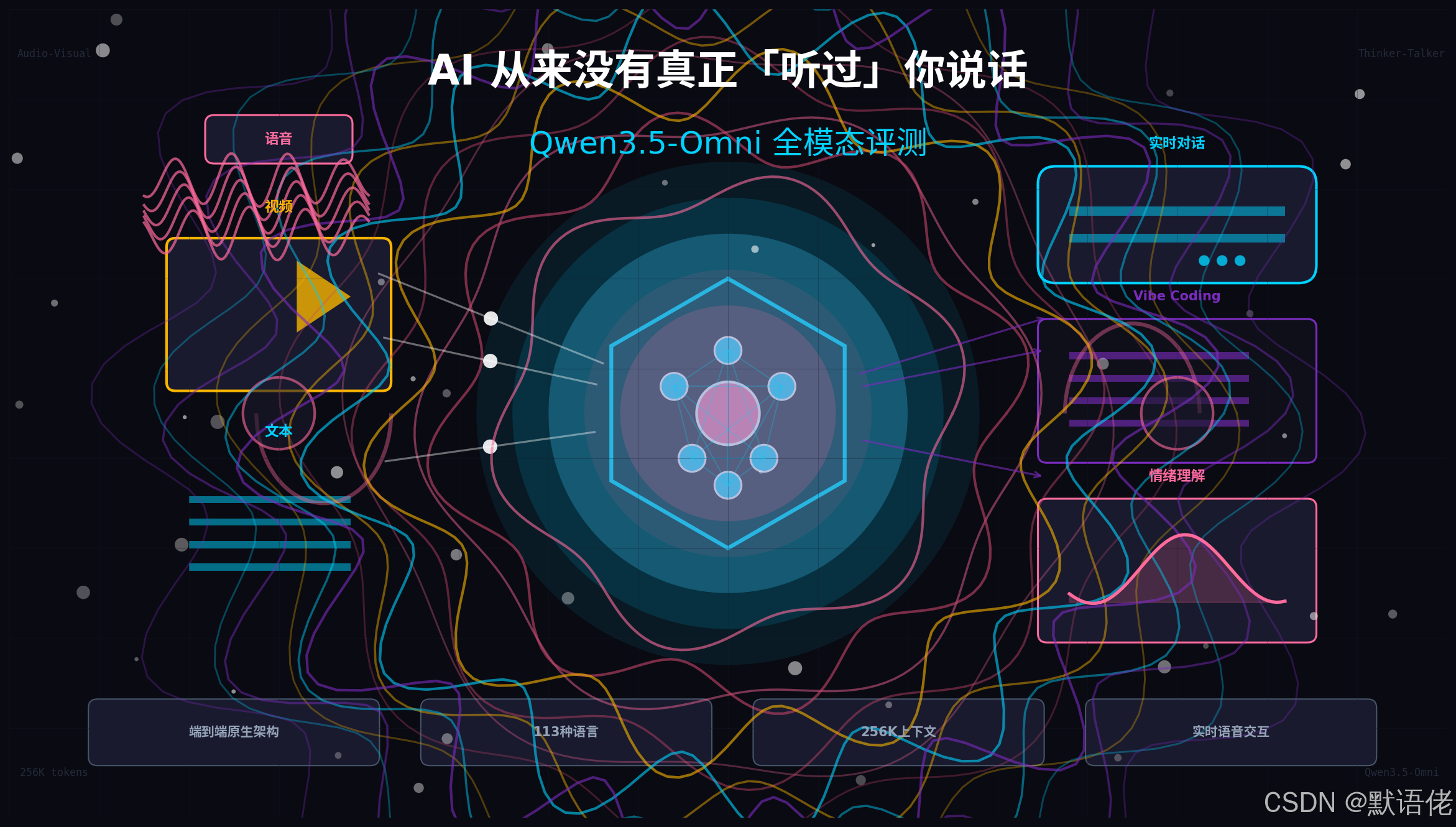
一、一个被忽视的真相:AI 其实不会「听」
过去两年,我们见证了 GPT-4V 的"看图说话"、Sora 的"文生视频"、Claude 的"长文本理解"。但有一个能力始终被忽视——真正的「听觉」。
现有方案的缺陷显而易见:
- 语音转文字再理解:丢失语气、情绪、停顿、背景音
- 拼接式多模态:视觉模型+语音模型+语言模型各干各的,信息在传递中损耗
- 无法处理复杂场景:多人对话、背景音乐、环境噪音混在一起就"聋"了
正如一位开发者吐槽:“我让 AI 分析一段客服录音,它转文字后完全get不到客户生气了的语气,还给出’客户满意度良好’的结论。”
Qwen3.5-Omni 的出现,就是为了终结这种「伪听觉」时代 。
二、Qwen3.5-Omni 是什么:原生全模态的代际跃迁
Qwen3.5-Omni 是阿里通义千问团队于 2026 年 3 月 30 日发布的新一代全模态大模型 。与行业常见的"拼接式"方案不同,它采用原生端到端架构,直接打通文本、图像、音频、视频的底层语义逻辑 。
2.1 核心规格一览
| 能力维度 | 参数规格 | 行业意义 |
|---|---|---|
| 上下文窗口 | 256K tokens | 可处理 10 小时音频或 1 小时视频 |
| 音视频输入 | 400 秒 720P (1 FPS) | 支持带时间戳的细粒度理解 |
| 语言支持 | 113 种语音识别 + 36 种语音生成 | 覆盖毛利语、海南方言等小语种 |
| 训练数据 | 超 1 亿小时音视频 + 海量文本/视觉数据 | 原生多模态预训练,非拼接 |
| 模型版本 | Plus / Flash / Light | 覆盖高性能到高效率全场景 |
2.2 Thinker-Talker 架构升级
Qwen3.5-Omni 延续并强化了Thinker-Talker双核架构 :
- Thinker(思考者):采用 Hybrid-Attention MoE 架构,通过 Vision Encoder 与 AuT 接收视觉与音频信号,负责全模态理解与文本输出
- Talker(说话者):同样采用 MoE 架构,接收 Thinker 的多模态输入进行上下文感知语音生成,使用 RVQ 编码替代繁重的 DiT 运算
关键创新在于TMRoPE 位置编码技术——它能让音视频信号通过 interleave 交织处理,并配合 chunk-wise 流式输入实现真正的实时交互 。
三、四大极限测试:它真的「听懂」了吗?
为了验证 Qwen3.5-Omni 是否具备真正的"听觉理解"能力,我们设计了四个递进式测试场景。
测试 1:《沙丘》预告片拆解——复杂叙事的结构化理解
任务:上传 2 分 30 秒的《沙丘 2》预告片,要求分析叙事结构、角色关系、镜头语言,并生成复刻分镜脚本。
结果:
- ✅ 按时间戳输出结构化分析(00:12 主角出场,00:45 冲突升级…)
- ✅ 推理出角色间的隐含权力关系
- ✅ 识别背景音乐的情绪转折节点
- ✅ 生成包含调色建议、节奏设计的完整分镜脚本
关键突破:它不仅"看到"了画面,更"听懂"了背景音乐如何配合叙事节奏,这是纯视觉模型无法做到的。
测试 2:TikTok 带货视频复盘——商业逻辑的跨模态推理
任务:分析一条 3 分钟的爆款带货视频,拆解转化逻辑并输出可迁移的脚本模板。
结果:
- ✅ 识别出主播话术中的 5 个"钩子点"及对应的时间戳
- ✅ 分析背景音乐与话术的配合策略
- ✅ 拆解视觉呈现(产品特写、使用场景)与听觉刺激(音效、语速变化)的协同逻辑
- ✅ 输出可直接套用到其他行业的 5 步脚本模板
关键突破:它将视觉信息(画面)、听觉信息(话术、音乐)、商业逻辑(转化漏斗)进行了跨模态统一推理。
测试 3:口述+草图写代码——Audio-Visual Vibe Coding
任务:对着一张手绘草图口述需求:“我要一个待办事项应用,顶部是进度环,中间是任务列表,底部是添加按钮,整体用紫色主题。”
结果:
- ✅ 第一轮生成可运行的 React 页面
- ✅ 继续口述"把进度环改成蓝色,添加按钮加动画"
- ✅ 第二轮迭代保持上下文连贯,准确修改指定元素
- ✅ 第三轮口述"添加任务完成时的音效",模型在代码中嵌入了音频逻辑
关键突破:这是未经专门训练自然涌现的Audio-Visual Vibe Coding能力——模型能同时理解视觉(草图)、听觉(口述)、文本(需求描述)三种输入,并生成可执行代码 。
测试 4:24 小时 AI 新闻编辑部——超长音视频处理
任务:处理 50 分钟国际新闻发布会音频,完成信息提取、双语稿件生成、语音播报。
结果:
- ✅ 准确区分不同发言人的声音
- ✅ 提取关键信息并生成带时间戳的结构化摘要
- ✅ 自动翻译成中文并生成新闻稿
- ✅ 使用 TTS 生成自然的中文语音播报
关键突破:10 小时音频输入能力让"长视频转写+分析"从理论变为实用 。
四、实时交互体验:更像真人的对话
Qwen3.5-Omni 在实时交互层面做了三项关键升级 :
4.1 语义打断(Semantic Interruption)
传统语音助手需要等你说完才能响应,而 Qwen3.5-Omni 能高情商区分有效回应和随口附和:
- 你说"等一下"——它暂停倾听
- 你说"嗯嗯、好的"——它继续说完
- 你说"不对,我是说…"——它立即切换上下文
4.2 音色克隆与语音控制
- 音色克隆:仅需 10 秒音频样本即可克隆特定音色
- 语音控制:支持"大声点"“开心一点”"慢一点"等实时指令调节
4.3 ARIA 技术:告别"机器人腔"
ARIA(Adaptive Rhythm and Intonation Adjustment)技术解决了语音生成中的漏字、数字念不清、语调生硬等问题,使合成语音更接近真人表达 。
五、性能对比:215 项 SOTA 意味着什么?
Qwen3.5-Omni-Plus 在音频/音视频理解、推理、交互任务上共取得 **215 项 SOTA(State of the Art)**成绩 :
| 评测维度 | 对比对象 | 结果 |
|---|---|---|
| 通用音频理解 | Gemini-3.1 Pro | 全面超越 |
| 音视频理解 | Gemini-3.1 Pro | 总体持平 |
| 语音识别(嘈杂环境) | Gemini-3.1 Pro | 错误率显著更低 |
| 多语言语音生成 | Gemini-2.5-Pro-TTS | 显著优于 |
| 文本能力 | 同尺寸 Qwen3.5 | 持平 |
| 视觉能力 | 同尺寸 Qwen3.5 | 持平 |
关键洞察:它实现了行业长期难以突破的**“全模态不降智”**——音视频能力增强的同时,文本和视觉能力没有衰减 。
六、应用场景:从"玩具"到"生产力工具"
6.1 视频内容工业化
- 自动切片:根据内容逻辑自动划分章节并打时间戳
- 内容审核:识别敏感画面、违规音频、不当言论
- 二创辅助:生成可用于混剪的结构化素材库
6.2 智能客服与质检
- 情绪轨迹分析:识别客户情绪变化曲线
- 话术评分:分析客服响应是否及时、专业
- 多语言支持:113 种语言覆盖跨境客服场景
6.3 无障碍辅助
- 实时字幕:为听障人士提供带说话人识别的字幕
- 视频摘要:为视障人士提供详细的音频描述
- 跨语言沟通:实时翻译+语音合成
6.4 下一代编程范式
Audio-Visual Vibe Coding 让"动动嘴就能编程"成为现实:
- 对着产品原型图口述需求 → 生成前端代码
- 播放一段游戏录屏 → 生成游戏逻辑代码
- 录制一段操作演示 → 生成自动化脚本
七、如何体验?
7.1 普通用户
访问 Qwen Chat 即可免费体验
7.2 开发者与企业
通过阿里云百炼平台调用 API,提供三种尺寸:
- Plus:最高性能,适合复杂任务
- Flash:平衡性能与成本
- Light:轻量级,适合边缘部署
价格:每百万 Tokens 输入不到 0.8 元,不到 Gemini-3.1 Pro 的 1/10
7.3 API 接入示例
# 实时语音交互(WebSocket)
import asyncio
import websockets
async def realtime_chat():
uri = "wss://api.qwen.ai/v1/realtime"
async with websockets.connect(uri) as websocket:
# 发送音频流
await websocket.send(audio_chunk)
# 接收文本+语音响应
response = await websocket.recv()
print(response)
八、总结:全模态 AI 的生产力革命
Qwen3.5-Omni 的意义绝不仅仅是多模态能力的参数升级。它让我们看到:原本只能"看一遍就过去"的音视频内容,是如何被拆解成可以直接拿去干活的"数据资产"的 。
从《沙丘》的复杂叙事,到带货视频的商业分析,再到口述写代码的随性交互——它成功证明了能把复杂的、混乱的、连续的输入,变成可以直接拿去用的结果 。
更重要的是,它实现了真正的「听觉理解」——不是简单的语音转文字,而是对语气、情绪、背景音、多说话人场景的深度感知。
这或许才是那场我们期待已久的、属于全模态大模型的真正生产力革命 。
参考链接:

欢迎加入北京社区
更多推荐


 11
11 0
0- 0



 已为社区贡献173条内容
已为社区贡献173条内容

所有评论(0)