
机器学习入门全指南:从概念、算法到特征工程与模型评估
前言
本文旨在为读者搭建一个清晰、系统的机器学习知识框架。我们从人工智能、机器学习、深度学习三者之间的关系切入,理清基本概念;随后详解有监督、无监督、半监督及强化学习四大算法类别,并配以直观的图示帮助理解;再深入特征工程的实用技巧,包括特征提取、预处理、降维、选择与组合;最后剖析模型拟合中的欠拟合、过拟合与泛化问题,并介绍基于 Python 的 scikit-learn 开发环境。整篇内容由浅入深,理论与实践并重,力求让每一位读者都能建立起对机器学习整体的认知,为后续深入学习和项目实践打下坚实基础。
机器学习概述
人工智能三大概念
人工智能AI
- Artificial Intelligence 人工智能
- AI is the field that studies the synthesis and analysis of computational agents that act intelligently
- AI is to use computers to analog and instead of human brain
像人一样机器智能的综合与分析;
机器模拟人类
机器学习
Field of study that gives computers the ability to learn without being explicitly programmed
让机器自动学习,而不是基于规则的编程(不依赖特定规则编程)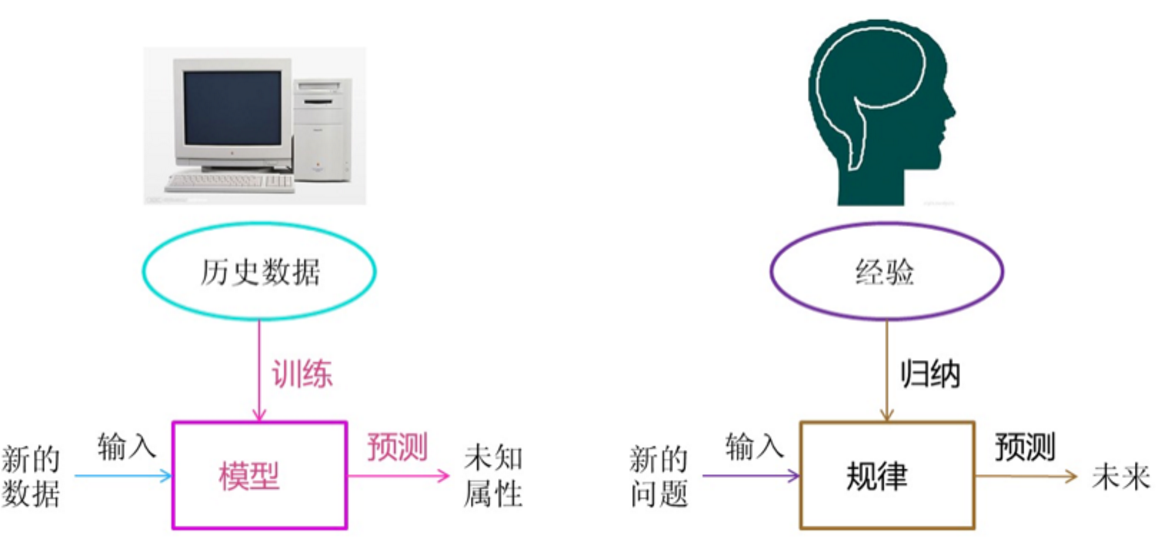
- 人类识别车:根据车的特征归纳出车的规律;来了一个新的图片,判断预测是否是车
- 机器学习识别车: 从数据中获取规律;来了一个新的数据,产生一个新的预测
深度学习
深度学习(DL, Deep Learning) : ,也叫深度神经网络,大脑仿生,设计一层一层的神经元模拟万事万物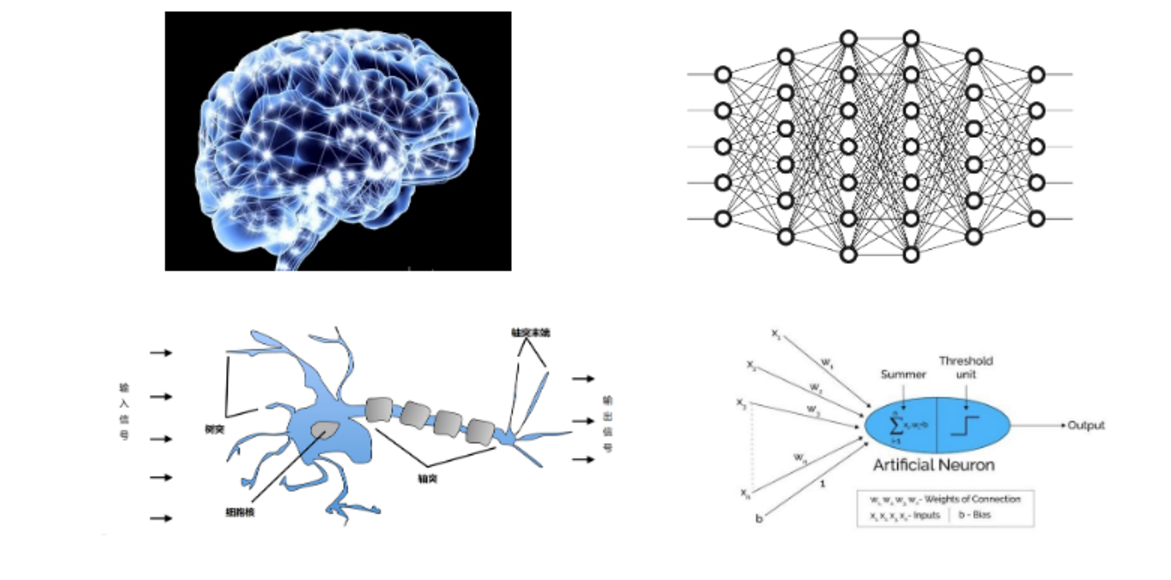
三者之间的关系
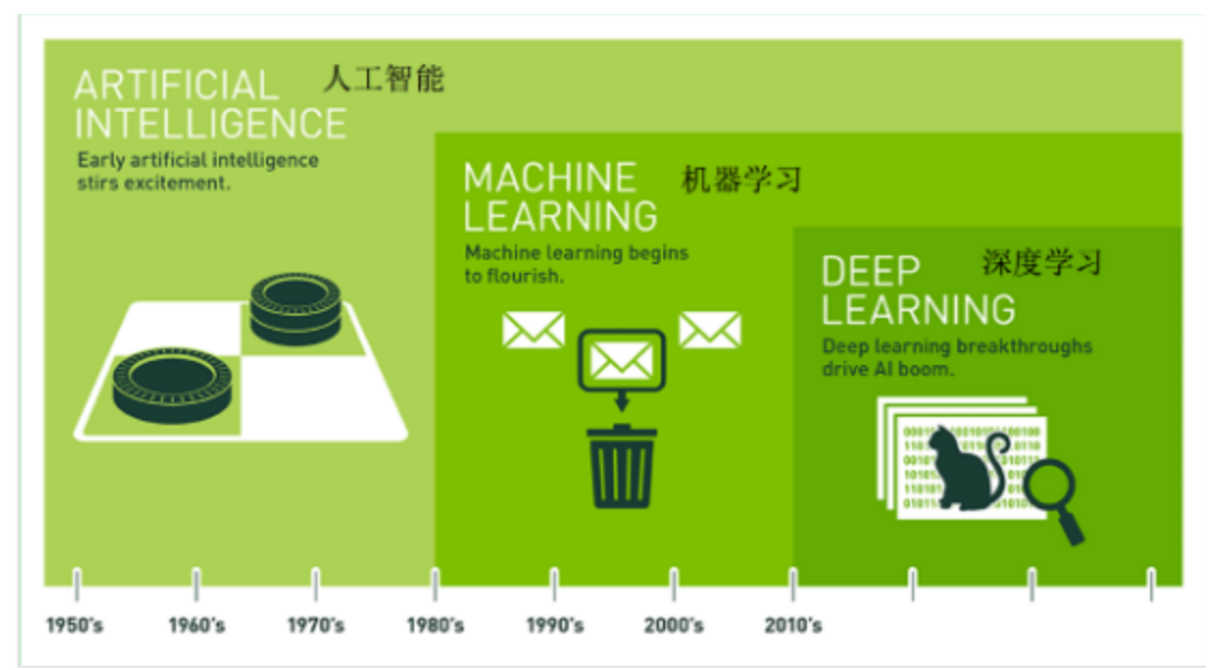
机器学习是实现人工智能的一种途径
深度学习是机器学习的一种方法
学习方式
基于规则的学习
基于规则的预测 : 程序员根据经验利用手工的if-else方式进行预测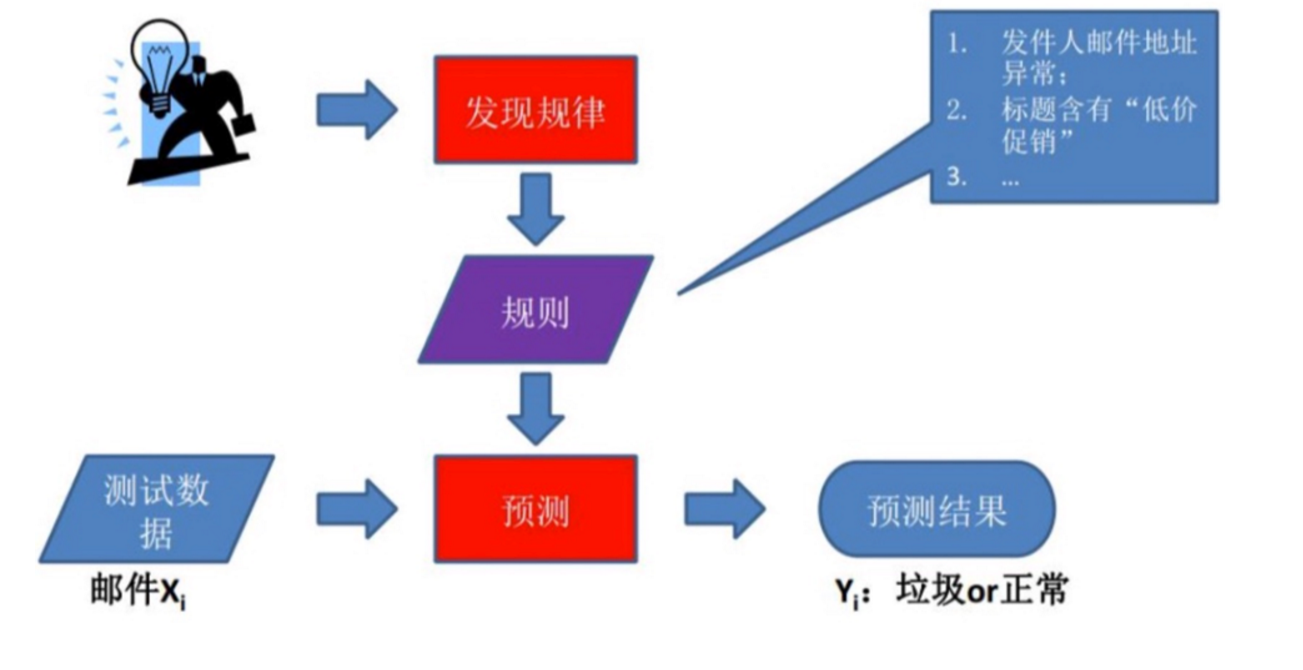
无法使用规则学习的方式来解决这一类问题,比如:
- 图像和语音识别
- 自然语言处理
基于模型的学习
基于模型的学习就是通过编写机器学习算法,让机器自己学习从历史数据中获得经验、训练模型: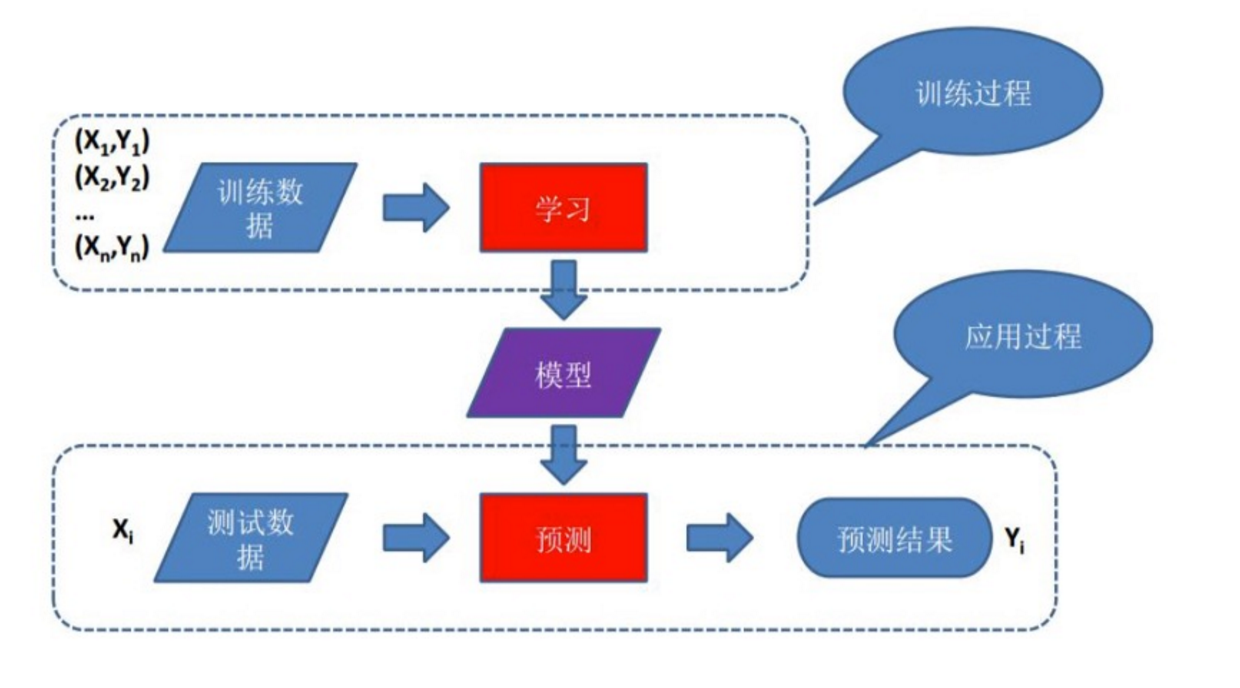
比如房价预测,数据如下图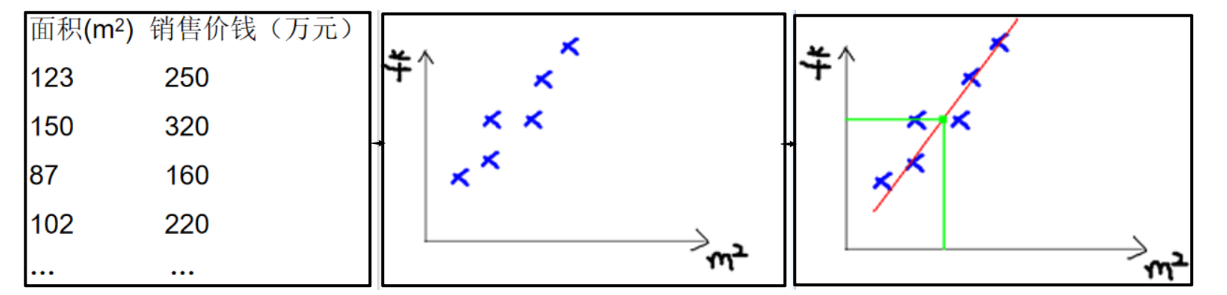
- 可以使用一条直线尽可能多的通过这些点,不通过的点尽量分布在直线的两侧,利用这条直线所表示的线性关系,我们就可以预测房价。
- 直线可以写成y=ax+b,若a,b已知,我们就能够预测房价。机器学习中a,b称为 参数 ,y=ax+b称为 模型 。通常a,b未知,是我们需要求解的量。
人工智能应用领域和发展史
应用领域
用户分析:社交网络、影评、商品评论
搜素引擎:网页、图片、规频、新闻、学术、地图
信息推荐:新闻、商品、游戏、书籍
图片识别:人像、用品、劢物、交通工具
机器翻译、摘要生成 … …
生物信息学习 … … 多模态 AR/VR
发展史
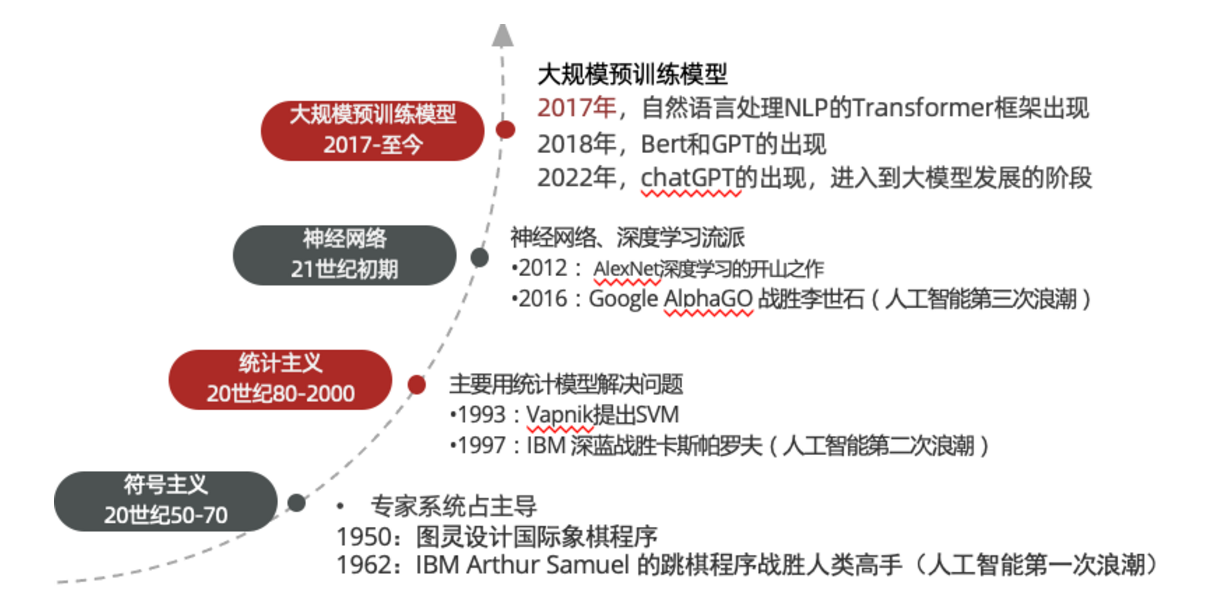
1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟智能的一系列有关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。
1956 年被认为是人工智能元年
1950-1970
符号主义流派:专家系统占主导地位
1950:图灵设计国际象棋程序
1962:IBM Arthur Samuel 的跳棋程序战胜人类高手(人工智能第一次浪潮)
1980-2000
统计主义流派:主要用统计模型解决问题
1993:Vapnik提出SVM
1997:IBM 深蓝战胜卡斯帕罗夫(人工智能第二次浪潮)
2010-2017
神经网络、深度学习流派
2012:AlexNet深度学习的开山之作
2016:Google AlphaGO 战胜李世石(人工智能第三次浪潮)
2017-至今
大规模预训练模型
2017年,自然语言处理NLP的Transformer框架出现
2018年,Bert和GPT的出现
2022年,chatGPT的出现,进入到大规模模型AIGC发展的阶段
机器学习发展三要素
数据、算法、算力三要素相互作用,是AI发展的基石
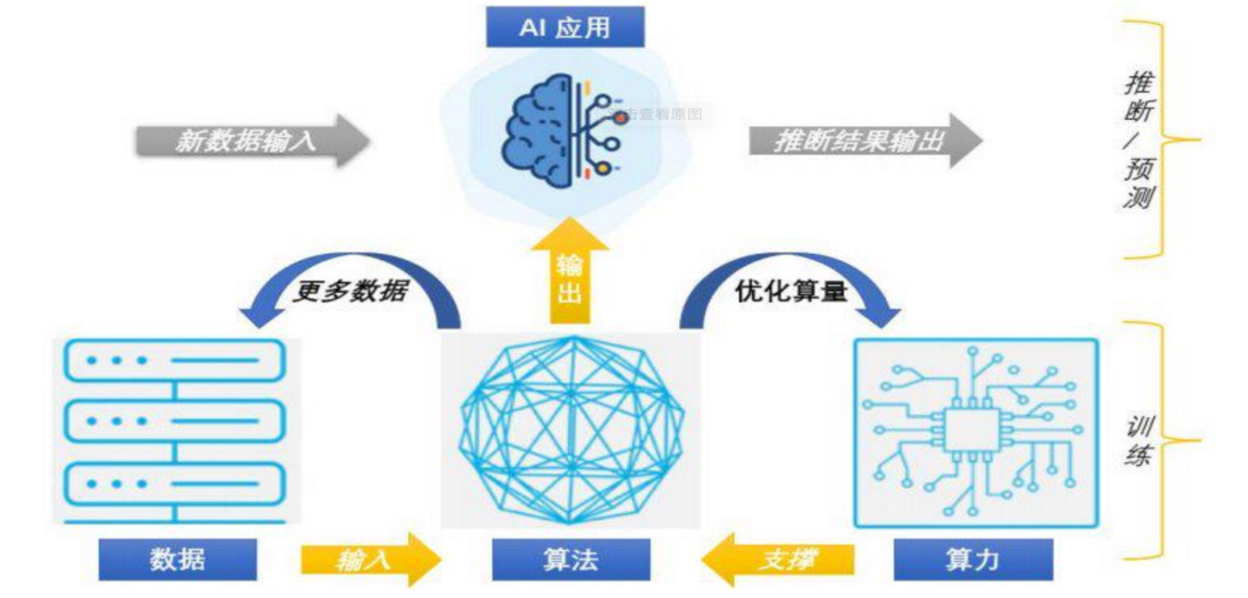
- CPU:负责调度任务、计算任务等;主要适合I\O密集型的任务
- GPU:更加适合矩阵运算;主要适合计算密集型任务
- TPU:Tensor,专门针对神经网络训练设计一款处理器
常见术语
样本,特征,标签/目标值
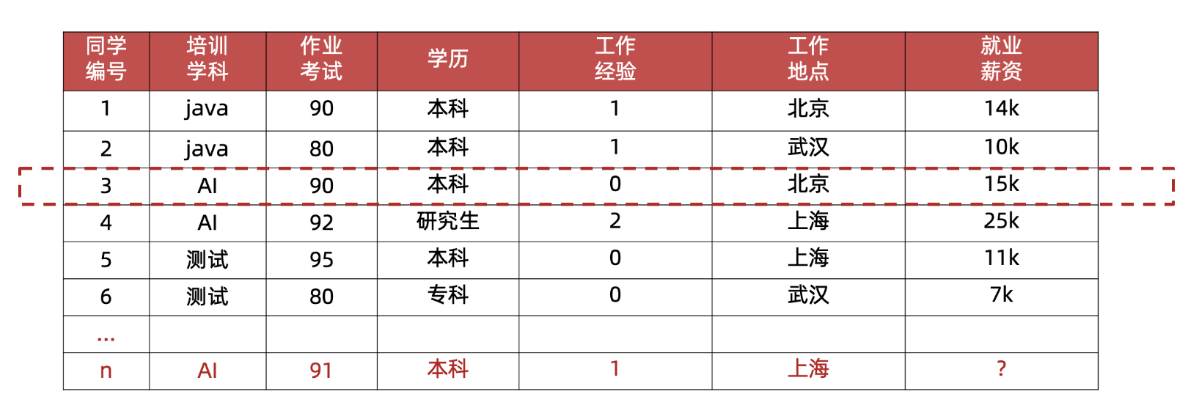
样本(sample) :一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录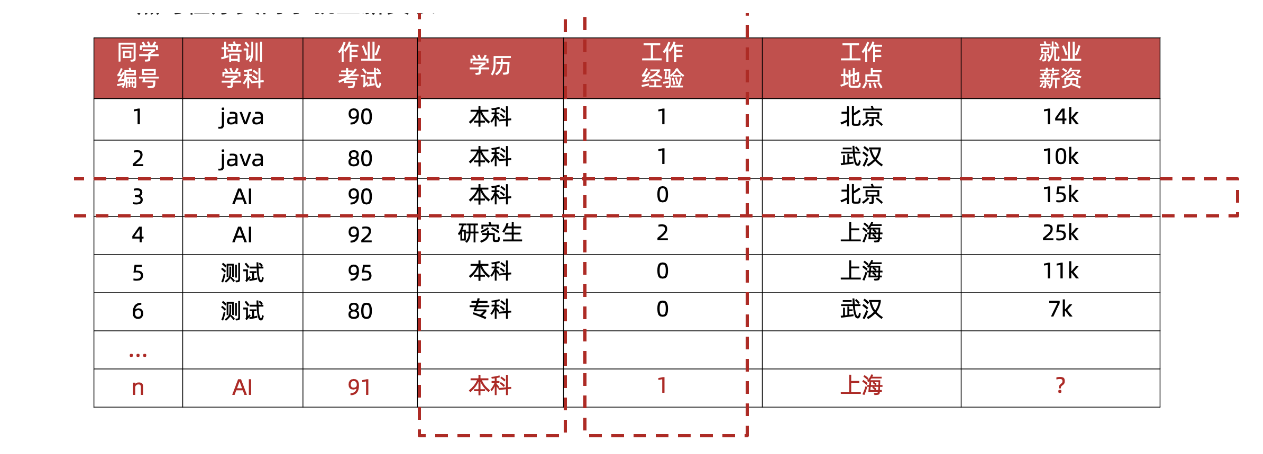
特征(feature) :一列数据一个特征,有时也被称为属性
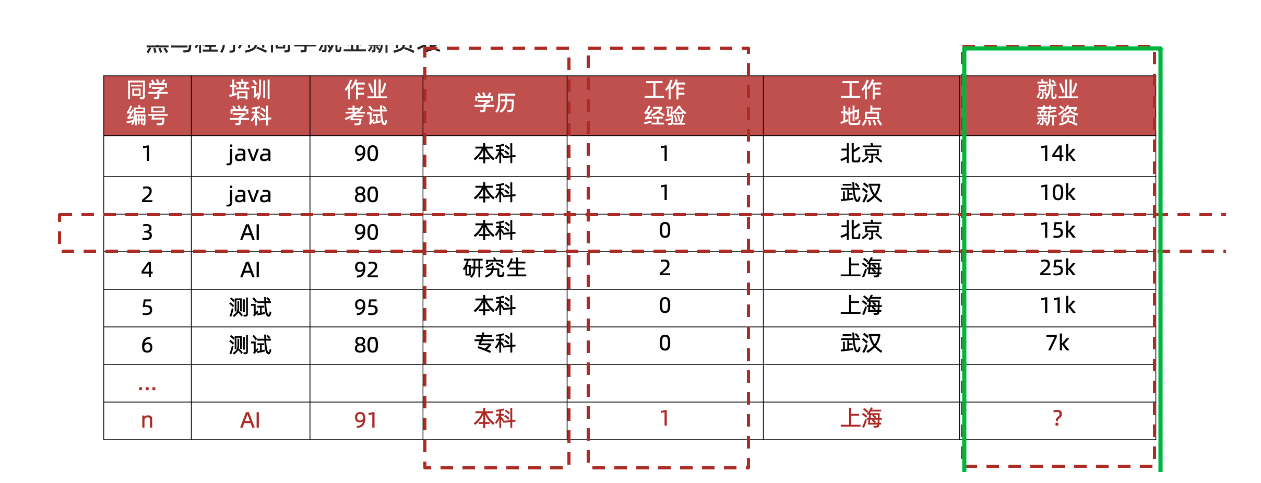
标签/目标(label/target) :模型要预测的那一列数据。
特征(重点):特征是从数据中抽取出来的,对结果预测有用的信息 eg:房价预测、车图片识别
数据集划分
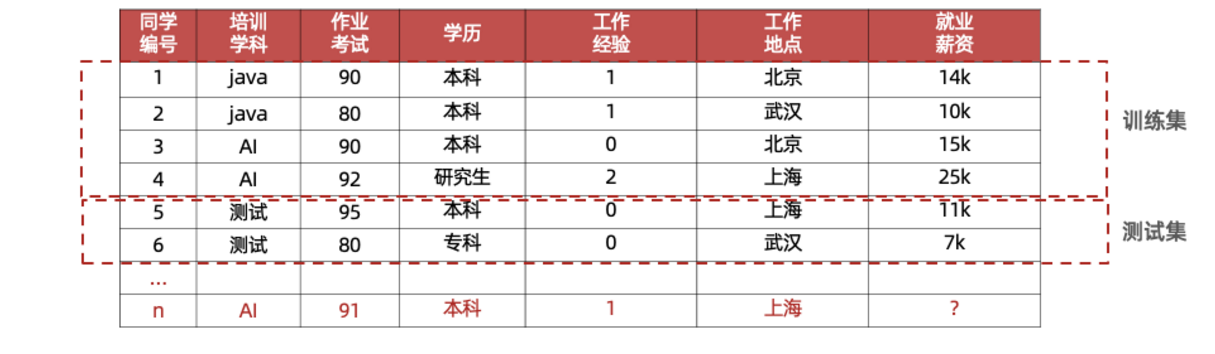
数据集可划分两部分:训练集、测试集 比例:8 : 2,7 : 3
训练集(training set) :用来训练模型(model)的数据集
测试集(testing set):用来测试模型的数据集
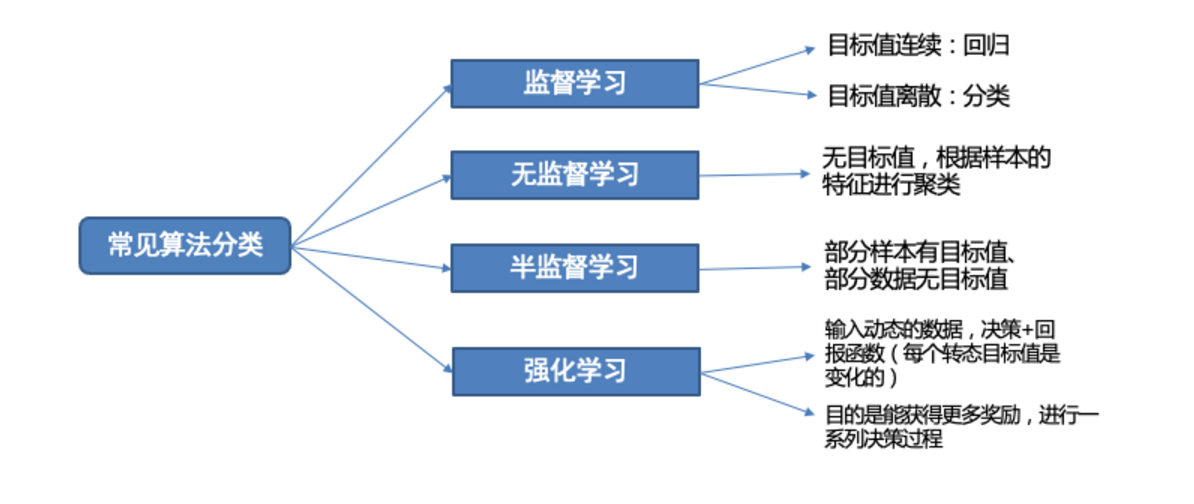
算法分类
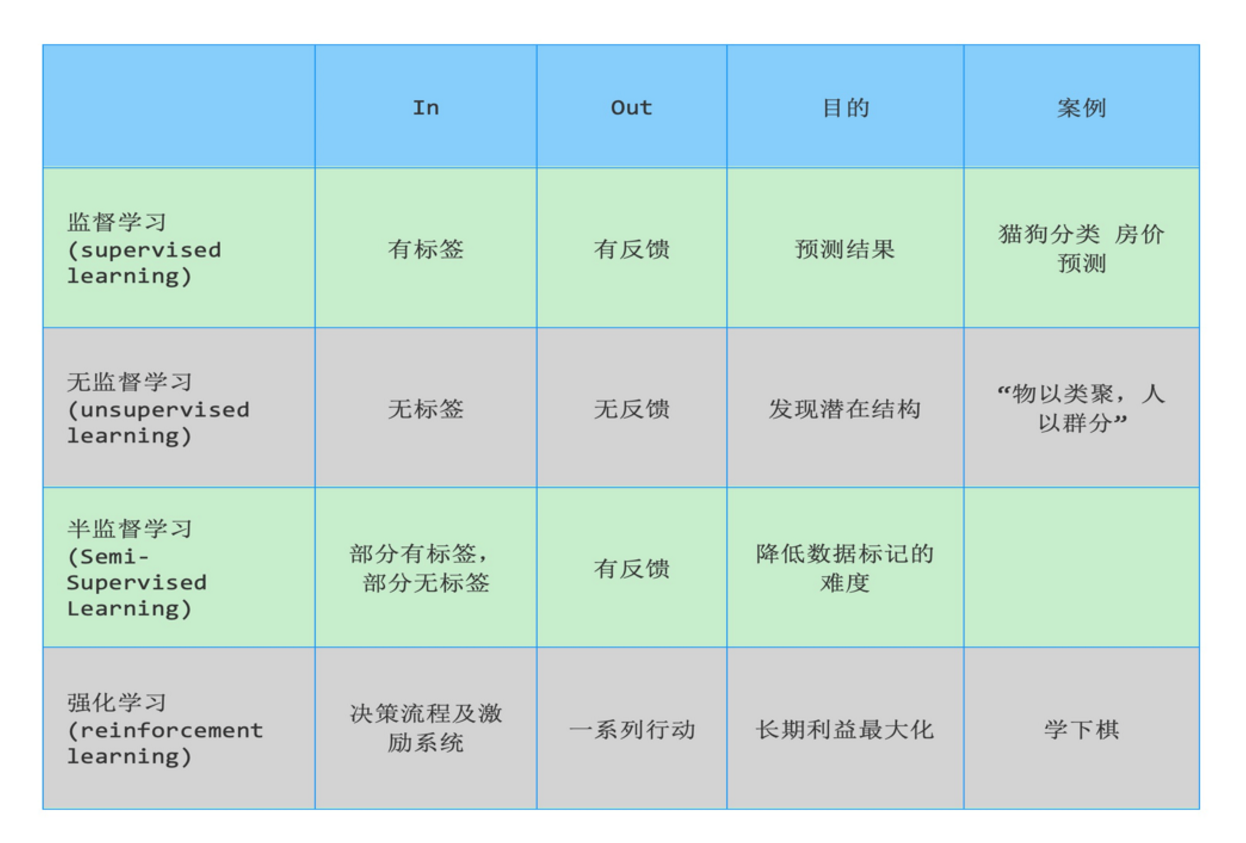
有监督学习
定义:输入数据是由输入特征值和目标值所组成,即输入的训练数据有标签的
数据集:需要人工标注数据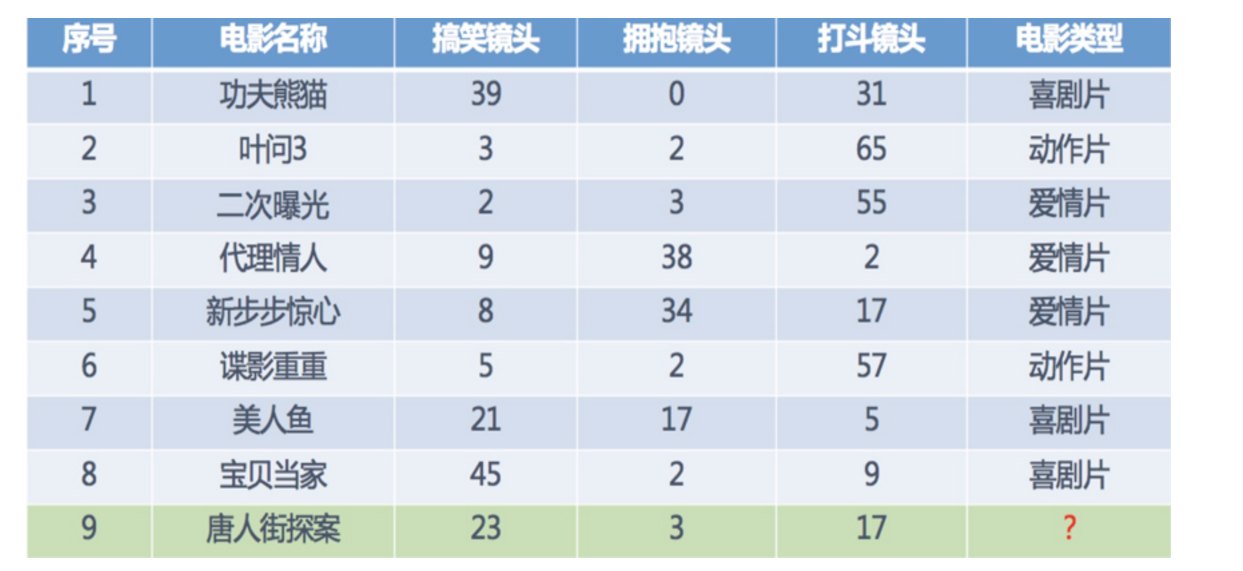
分类
- 目标值(标签值)是不连续的
- 分类种类:二分类、多分类任务、
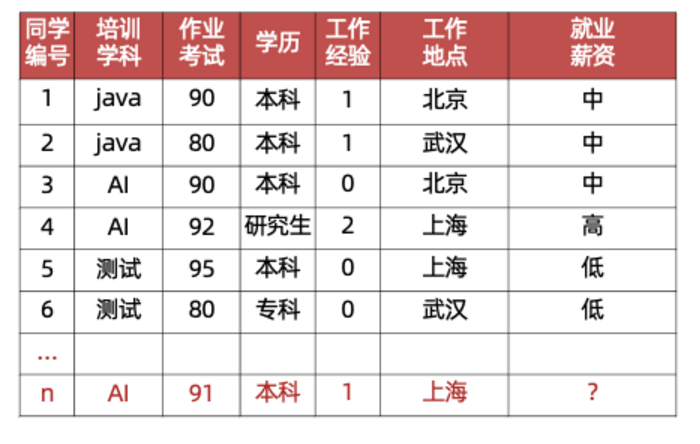
回归
目标值(标签值)是连续的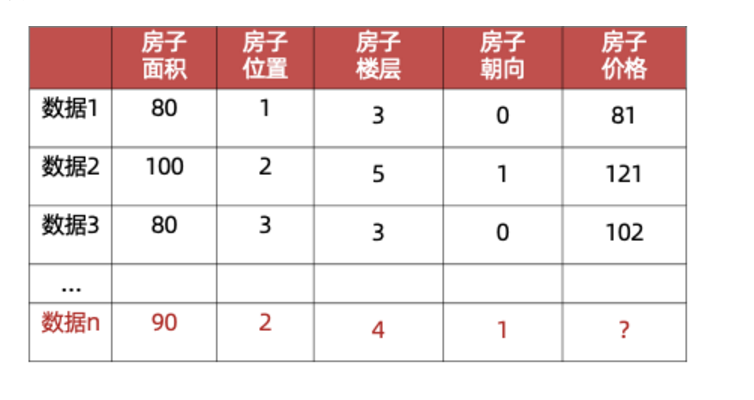
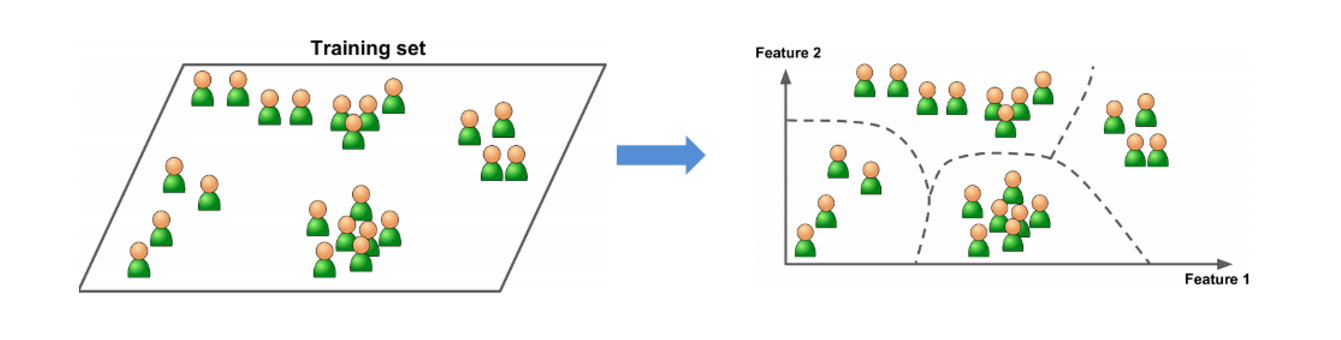
无监督学习
- 定义:输入数据没有被标记,即样本数据类别未知,没有标签,根据样本间的相似性,对样本集聚类,以发现事物内部 结构及相互关系。
- 数据集:不需要标注数据

无监督学习特点:
1 训练数据无标签
2 根据样本间的相似性对样本集进行聚类,发现事物内部结构及相互关系
半监督学习
工作原理:
1 让专家标注少量数据,利用已经标记的数据(也就是带有类标签)训练出一个模型
2 再利用该模型去套用未标记的数据
3 通过询问领域专家分类结果与模型分类结果做对比,从而对模型做进一步改善和提高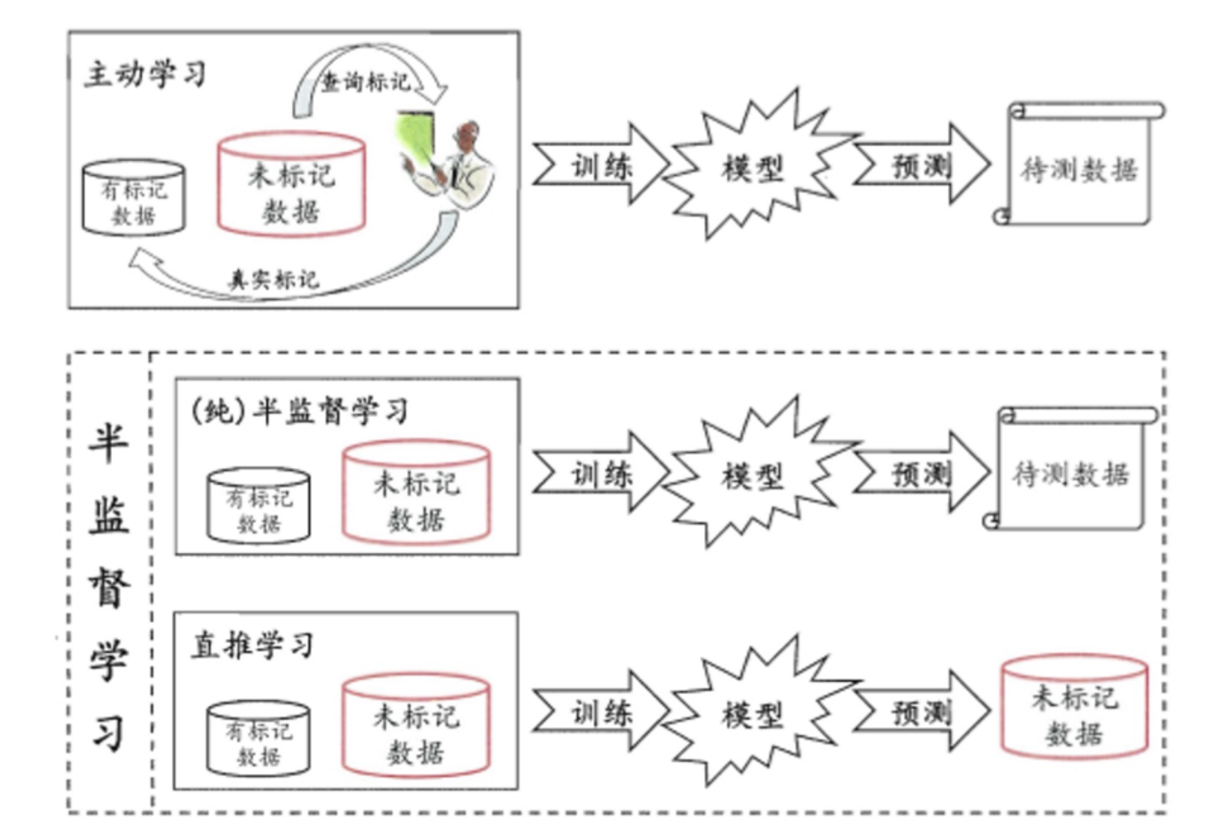
半监督学习方式可大幅降低标记成本
强化学习
1 强化学习(Reinforcement Learning):机器学习的一个重要分支
2 应用场景:里程碑AlphaGo围棋、各类游戏、对抗比赛、无人驾驶场景
3 基本原理:通过构建四个要素:agent,环境状态,行动,奖励
agent根据环境状态进行行动获得最多的累计奖励。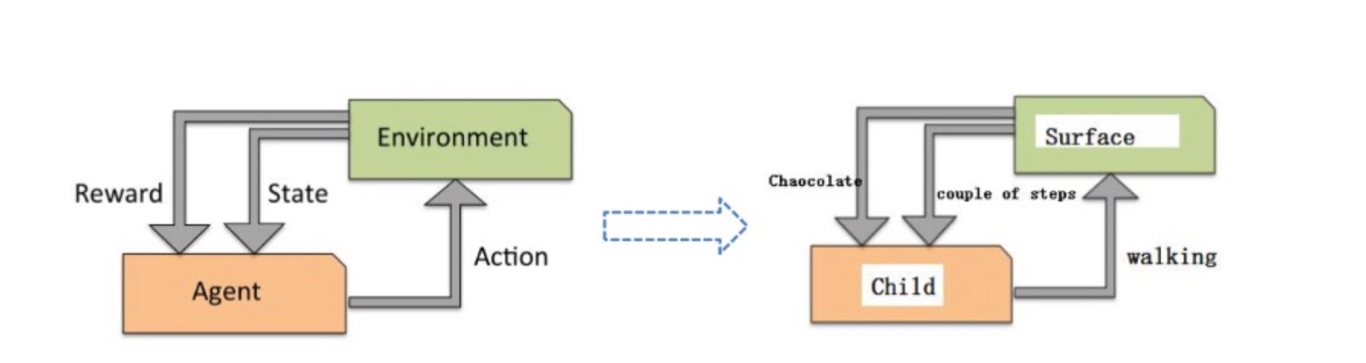
小孩子学走路:
(1) 小孩就是 agent,他试图通过采取行(即行走)来操纵环境(地面)
(2) 并且从一个状态转变到另一个状态(即他走的每一步),
(3) 当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃)
(4) 并且当他不能走路时,就不会给巧克力。
总结
机器学习的建模流程
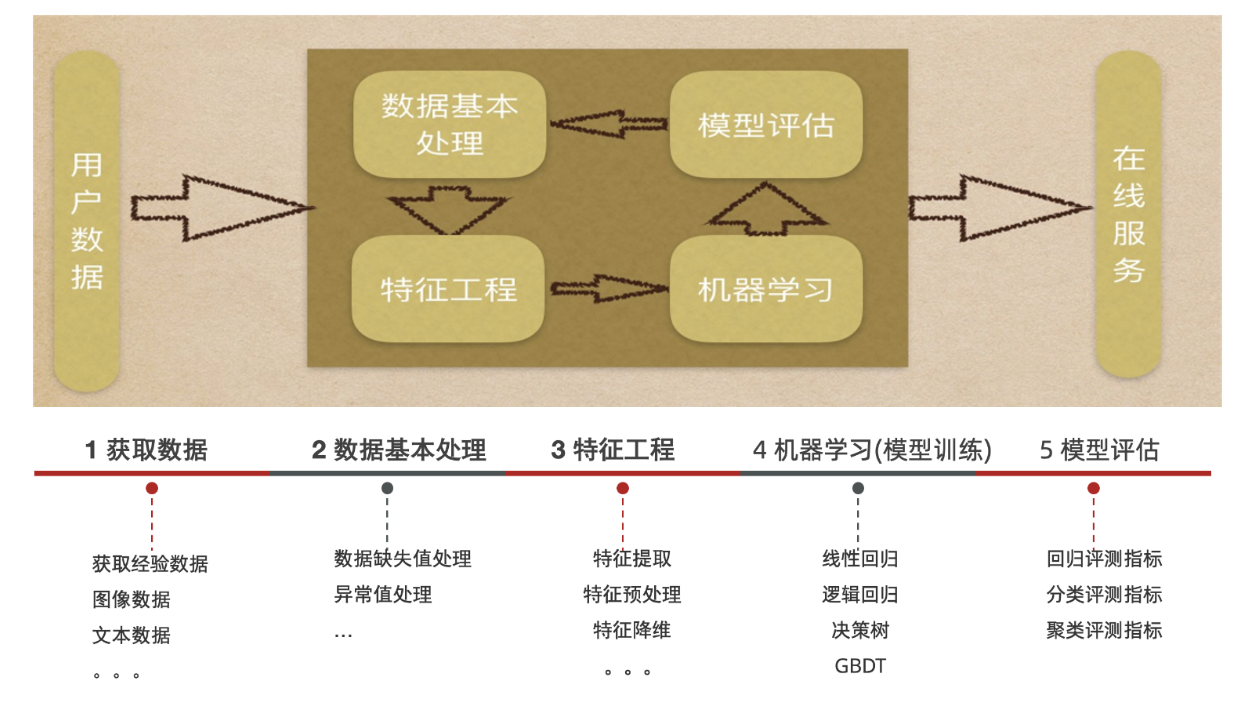
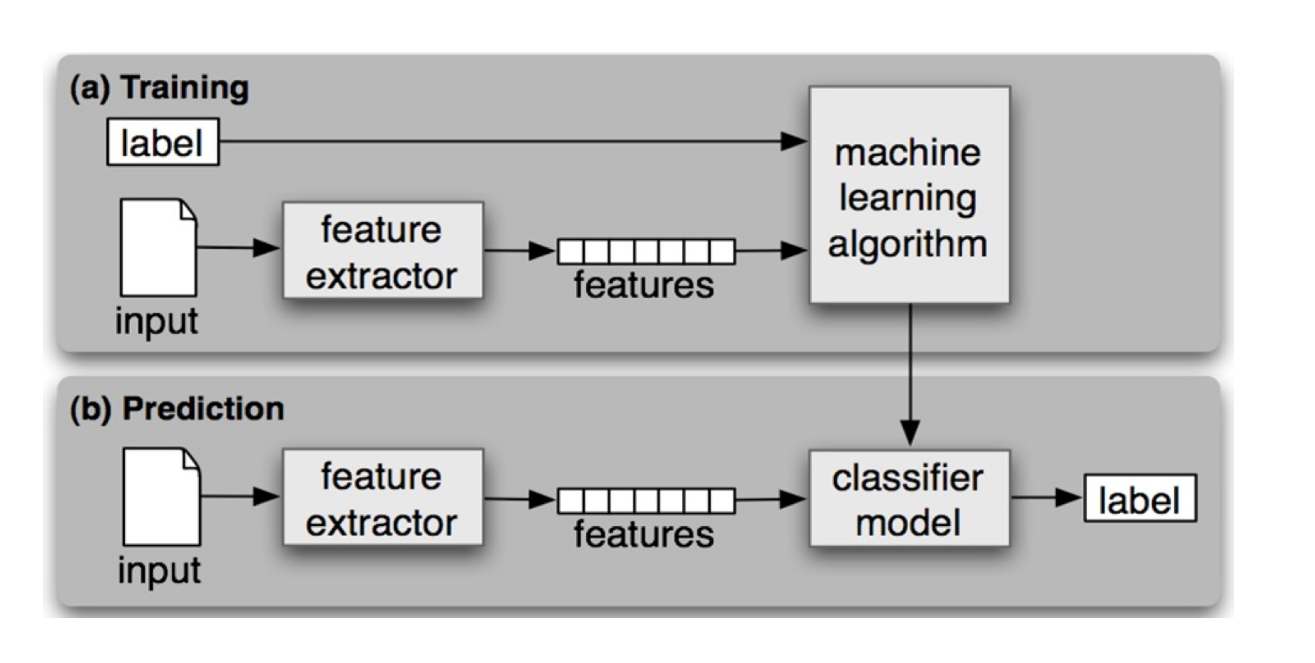
机器学习建模的一般步骤
- 获取数据:搜集与完成机器学习任务相关的数据集
- 数据基本处理:数据集中异常值,缺失值的处理等
- 特征工程:对数据特征进行提取、转成向量,让模型达到最好的效果
- 机器学习(模型训练):选择合适的算法对模型进行训练根据不同的任务来选中不同的算法;有监督学习,无监督学习,半监督学习,强化学习
- 模型评估:评估效果好上线服务,评估效果不好则重复上述步骤
特征工程

从数据集角度来看: 一列一列的数据为特征。
从模型训练角度来看: 对预测结果有用的属性为特征
特征工程是:利用专业背景知识和技巧处理数据,让机器学习算法效果最好。这个过程就是特征工程
特征提取
从原始数据中提取与任务相关的特征,构成特征向量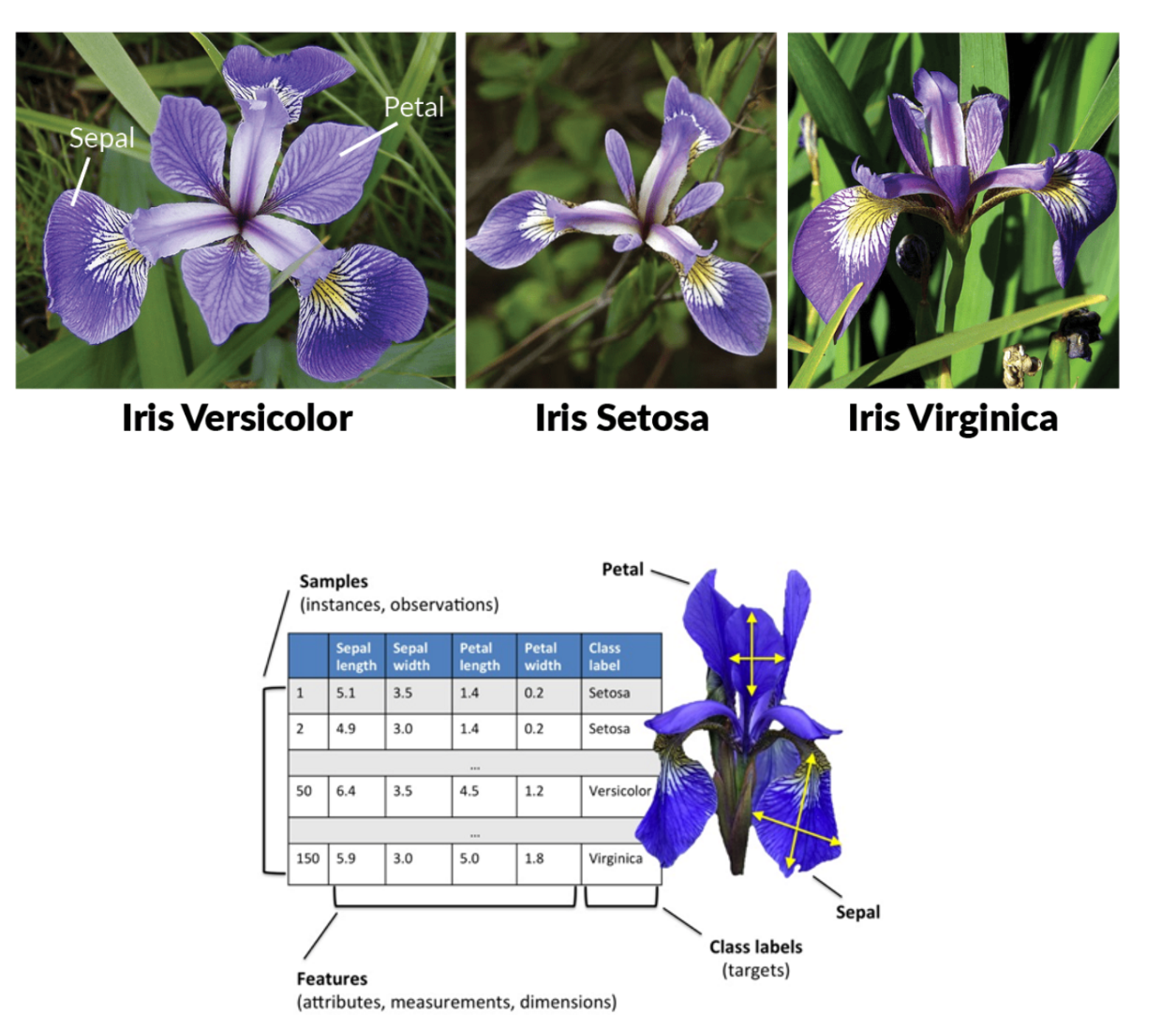
对于文本、图片这种非行列形式的数据行列形式转换,
一旦转换成行列形式一列就是特征
特征预处理
特征对模型产生影响;因单位问题,有些特征对模型影响大、有些影响小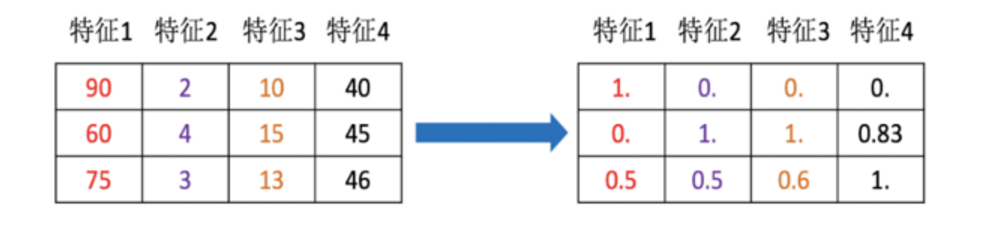
将不同的单位的特征数据转换成同一个范围内
使训练数据中不同特征对模型产生较为一致的影响
特征降维
将原始数据的维度降低,叫做特征降维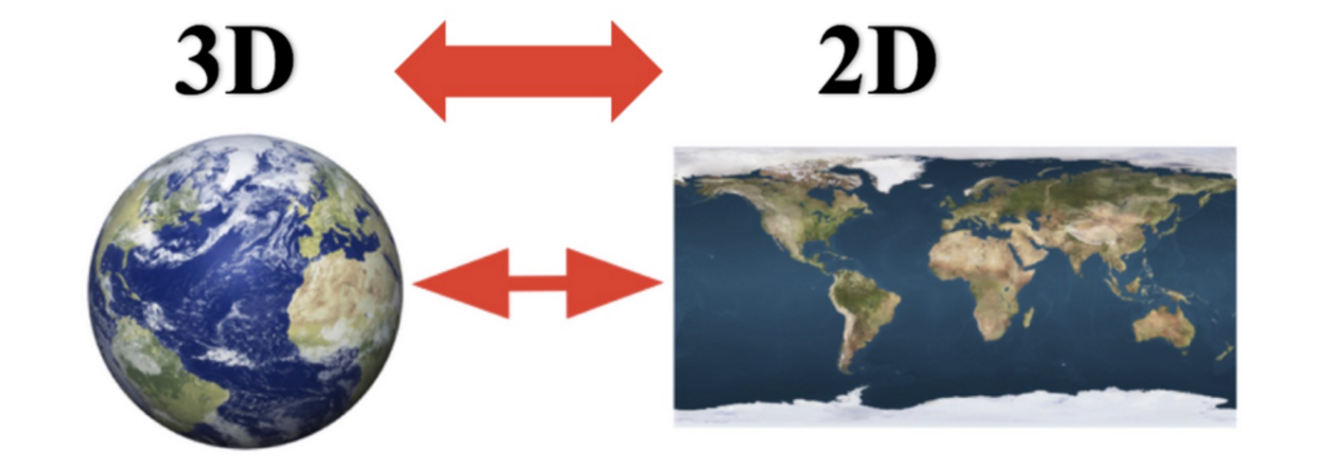
会丢失部分信息。降维就需要保证数据的主要信息要保留下来
原始数据会发生变化,不需要了解数据本身是什么含义,它保留了最主要的信息
特征选择
原始数据特征很多,但是对任务相关是其中一个特征集合子集。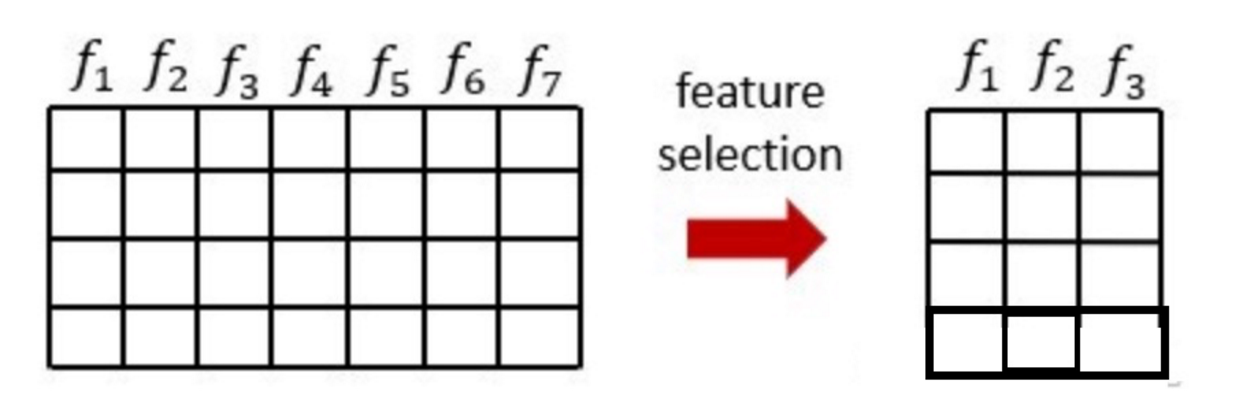
从特征中选择出一些重要特征(选择就需要根据一些指标来选择)
特征选择不会改变原来的数据
特征组合
把多个的特征合并成一个特征。
通过加法、乘法等方法将特征值合并
模型拟合问题
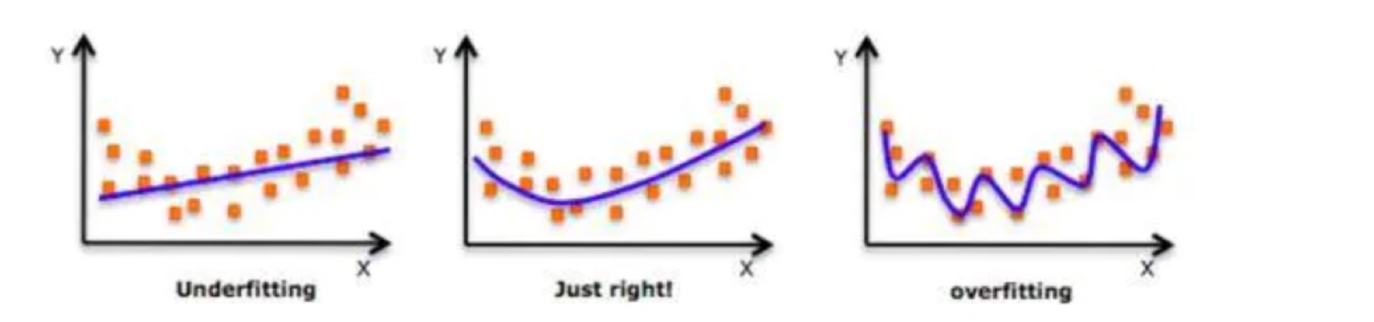
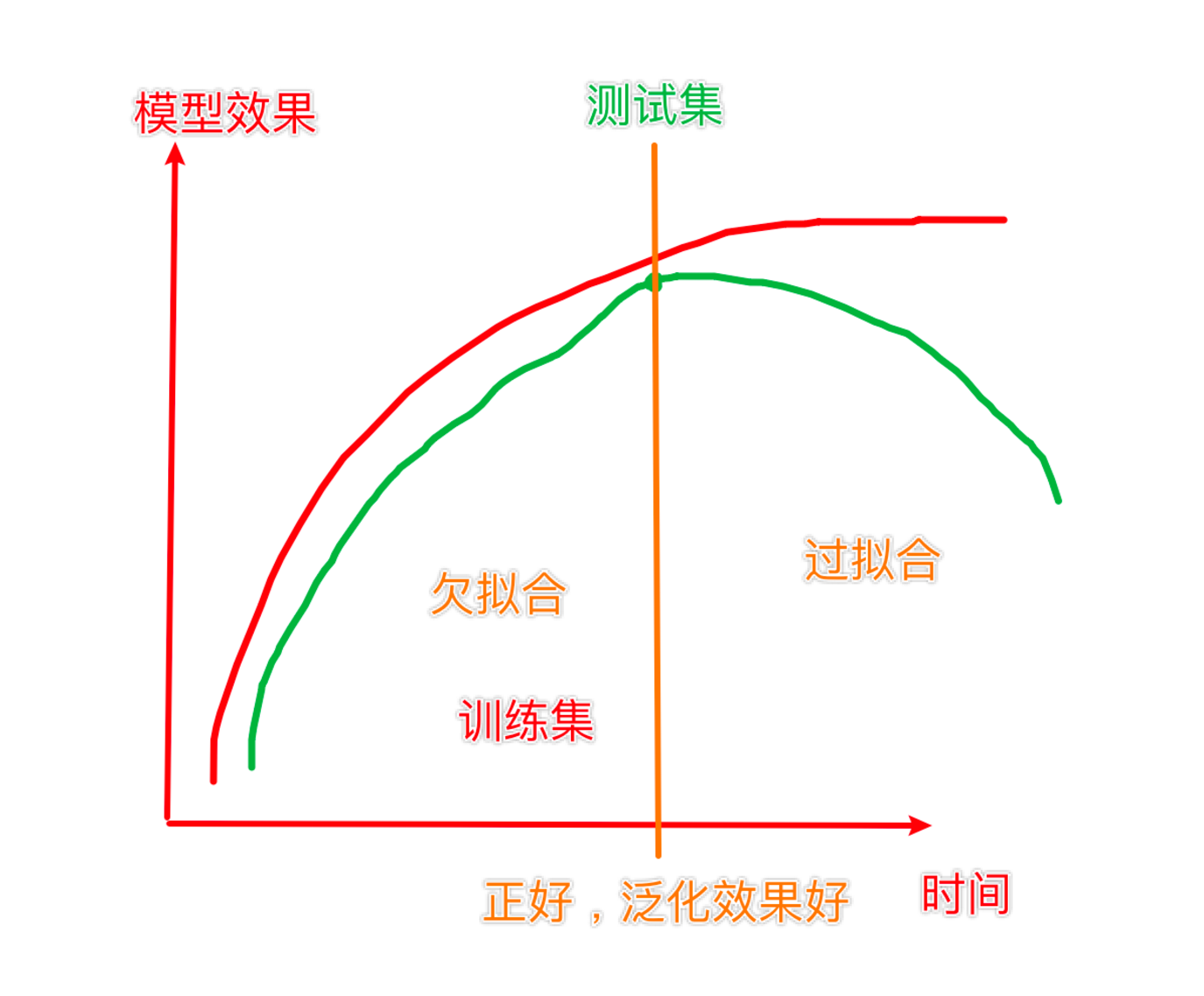
拟合:用来表示模型对样本点的拟合情况
欠拟合:模型在训练集上表现很差、在测试集表现也很差
原因:模型过于简单
过拟合:模型在训练集上表现很好、在测试集表现很差
原因:模型太过于复杂、数据不纯、训练数据太少
泛化:模型在新数据集(非训练数据)上的表现好坏的能力
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取
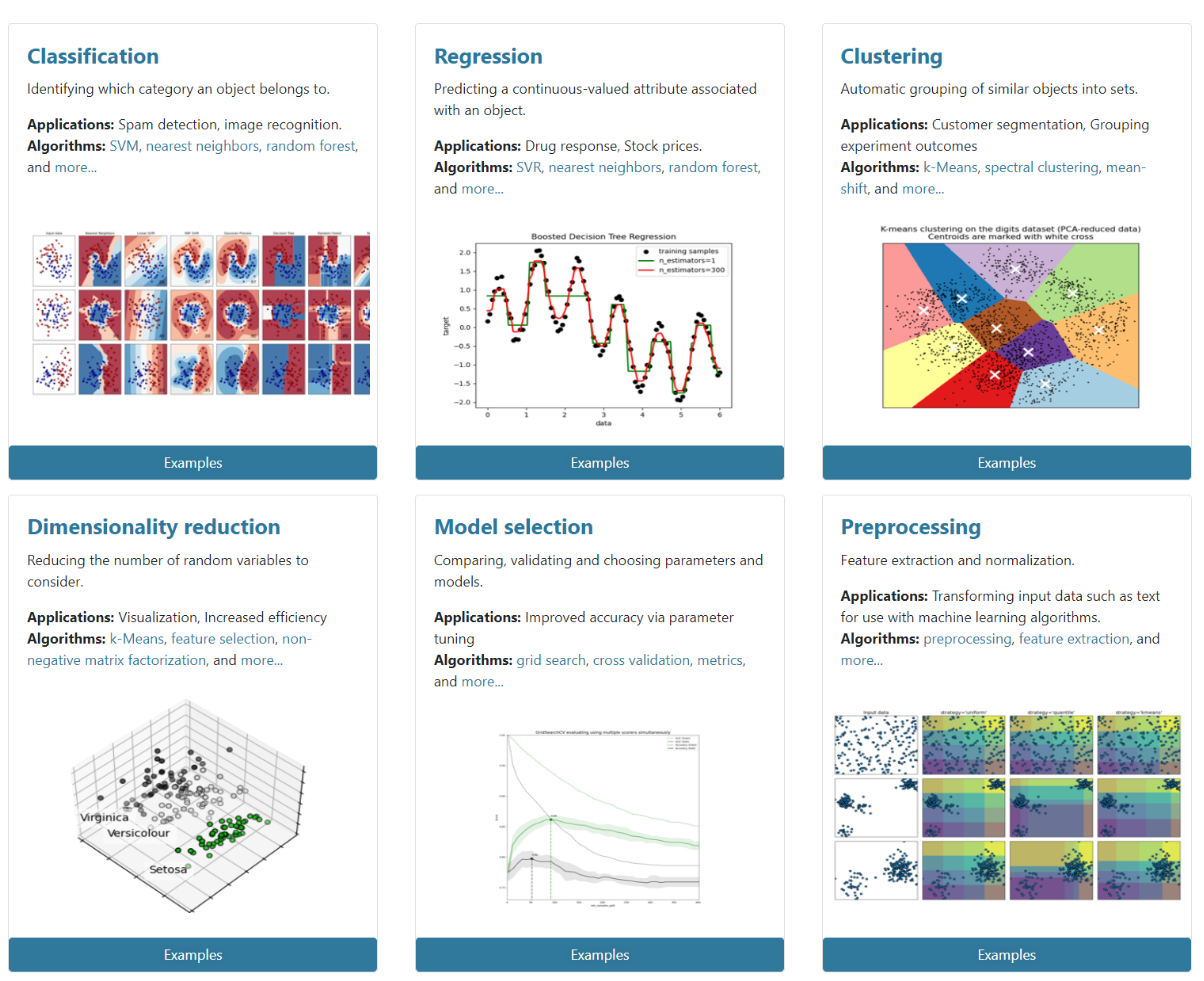
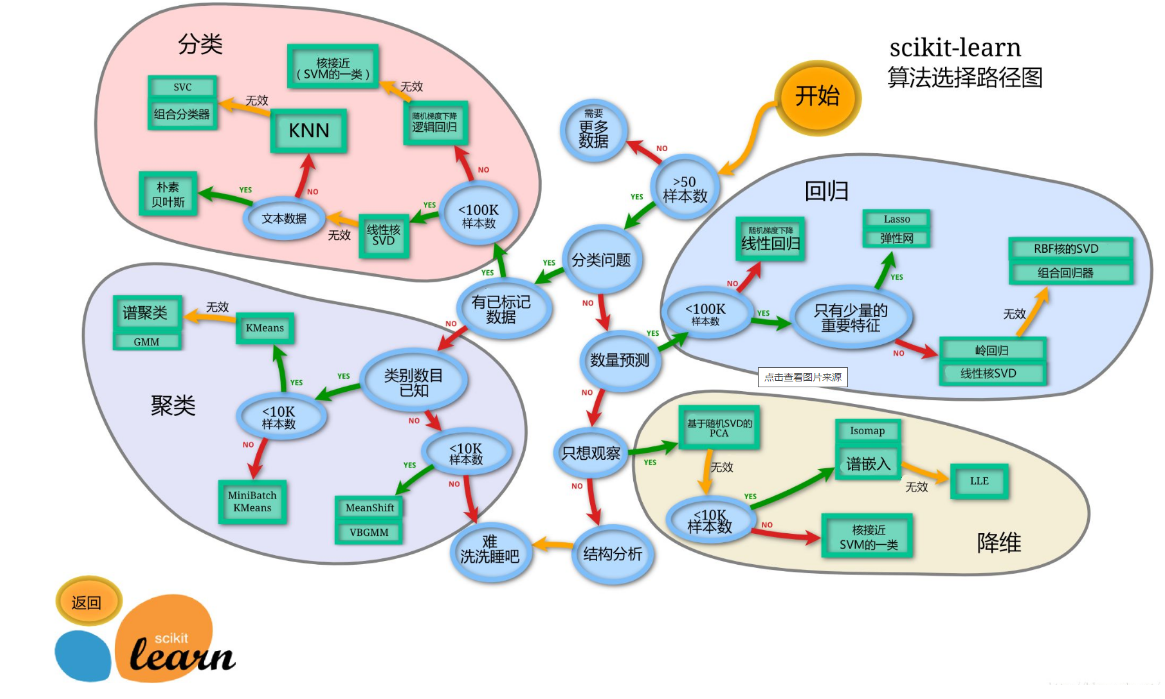
机器学习开发环境
基于Python的 scikit-learn 库:
- 简单高效的数据挖掘和数据分析工具
- 可供大家使用,可在各种环境中重复使用
- 建立在NumPy,SciPy和matplotlib上
- 开源,可商业使用-获取BSD许可证
官网:https://scikit-learn.org/stable/
pip install scikit-learn
总结
通过本文,您已具备了机器学习入门所需的基础知识。下一步,建议结合具体数据集和 scikit-learn 示例进行动手实践,将理论转化为解决实际问题的能力。机器学习的道路充满挑战,但只要脚踏实地、循序渐进,定能收获丰硕的成果。
更多推荐

 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)