
JavaEE|多线程进阶
多线程初阶总结
线程
- 线程的原理,进程和线程的原理
- 线程的使用Thread类的用法
- 线程安全问题
- 等待通知机制
- 多线程的代码案例
定时器
- 定义类描述任务
- 使用优先队列
- schedule
- 扫描线程,负责执行队列中的任务
wait/notify
线程唤醒
多线程进阶
常见的锁策略
对于synchronized已经可以覆盖大多数使用场景,此处的“锁策略”不是和 Java 强相关的,其他语
言,但凡涉及到并发编程,涉及到锁,都可以谈到这样的锁策略.
锁策略的特点
1.悲观锁 vs 乐观锁
不是针对某一种具体的锁,而是某个具体锁具有“悲观”特性或者“乐观”特性
- 悲观:加锁的时候,预测接下来的锁竞争的情况非常激烈。就需要针对这样的激烈情况额外做一些工作。
例如:有一把锁有二十个线程尝试获取锁。每个线程加锁的频率都很高。一个线程加锁的时候,很
可能锁被另一个线程占用着
- 乐观:加锁的时候,预测接下来的锁竞争的情况不激烈。就不需要做额外工作
例如:有一把锁假设只有两个线程尝试获取这个锁,每个线程加锁的频率都很低。一个线程加锁的
时候,大概率另一个线程没有和他竞争
对于无论悲观锁还是乐观锁,都是描述的是加锁时候遇到的场景
2.重量级锁 vs 轻量级锁
- 重量级锁,当悲观的场景下,此时就要付出更多的代价 => 更低效
- 轻量级锁,应对乐观的场景,此时付出的代价就会更小 => 更高效
对于无论重量级锁还是轻量级锁,都是遇到场景之后的解决方案
3.挂起等待锁 vs 自旋锁
- 挂起等待锁 :重量级锁 的典型实现。
操作系统内核级别的。加锁的时候发现竞争,就会使该线程进入阻塞状态。后续就需要内核进行唤
醒了。
获取锁的周期更长,很难即使获取,但是这个过程就不必一直消耗cpu,把cpu省出来做别的事
悲观锁 => 重量级锁 => 挂起等待锁
- 自旋锁 :轻量级锁的典型实现。
应用程序级别的。加锁的时候发现竞争,一般也不是进入阻塞,而是通过忙等的形式来进行等待。
乐观锁的场景本身遇到锁竞争的概率就很小,真的遇到竞争在短时间内就能拿到锁。获取锁的周期
更短,即使获取到锁,这个过程也会一直消耗cpu
乐观锁 => 轻量级锁 => 自旋锁
补充:
synchronized是种比较特殊的锁,既是乐观又是悲观,是自适应的状态
JVM 内部, 会统计每个锁 竞争的激烈程度
- 如果竞争不激烈, 此时 synchronized 就会按照轻量级锁(自旋)
- 如果竞争激烈, 此时 synchronized 就会按照重量级锁(挂起等待)
4.互斥锁 vs 读写锁
互斥锁:像synchronized这类锁进行加锁解锁操作
读写锁:读方式加锁,写方式加锁,解锁
多个线程读取一个数据是本身就线程安全的
多个线程读取一个线程修改肯定会涉及到线程安全问题。
如果把读和写都加上普通的互斥锁,数据的读取方之间也会产生互斥锁,意味着锁冲突非常严重
- 读写锁确保读锁和读锁之间不是互斥的(不会产生阻塞)
- 写锁和读锁之间,才产生互斥
- 写锁和写锁之间,也有互斥。
保证线程安全的前提下,降低锁冲突的概率,提高效率。
5.可重入锁 vs 不可重入锁
可重入锁:一个线程 一把锁连续加锁多次 是否会死锁.
核心要点:
- 锁要记录当前是哪个线程拿到的这把锁.
- 使用计数器, 记录当前加锁了多少次, 在合适的时候进行解锁
6.公平锁 vs 非公平锁
公平锁: 遵守 "先来后到". B 比 C 先来的. 当 A 释放锁的之后, B 就能先于 C 获取到锁.
非公平锁: 不遵守 "先来后到". B 和 C 都有可能获取到锁.
注意
操作系统的线程调度是随机的. 默认锁就是非公平锁. 如果要想实现公平锁, 就需要依赖额外的数据
结构, 来记录线程们的先后顺序
总结
1.悲观和乐观
2.重量和轻量
3.挂起等待锁和自旋锁
4.互斥锁和读写锁
5.可重入锁和不可重入锁
6.公平锁和非公平锁
synchronized详细情况
锁升级
无锁 --> 偏向锁 --> 自旋锁 - -> 重量级锁
偏向锁
synchronized一上来不是真加锁,而是只是简单做一个标记,这个标记非常轻量相比于加锁解锁来
说效率高很多
如果没有其他线程来竞争这个锁, 最终当前线程执行到解锁代也就只是简单清除上述
( 标记即可~~不涉及真加锁, 真解锁)
如果有其他线程来竞争, 就抢先一步, 在另一个线程拿到锁之前, 抢先拿到锁
(偏向锁 => 轻量级锁. 其他线程只能阻塞等待)
锁升级总结
无锁 --> 偏向锁 : 代码进入 synchronized 的 代码块
偏向锁 --> 轻量级锁 : 拿到偏向锁的线程运行过程中, 遇到了其他线程尝试竞争这个锁.
轻量级锁 --> 重量级锁 : JVM 发现, 当前竞争锁的情况非常激烈
当前 JVM 中, 只提供了 "锁升级" 不能 "锁降级"
锁消除
锁消除也是编译器优化的一种体现.
编译器会判定, 当前这个代码逻辑是否真的需要加锁. 如果确实不需要加锁, 但是写了 synchronized,
就会自动把 synchronized 给去掉.
锁组化
锁的粒度
加锁和解锁之间,包含的代码越多,就认为锁的粒度就越粗
如果包含的代码越少,就认为锁的粒度就越细(不是代码行数,实际执行的指令/时间)
一个代码中,反复针对细粒度的代码加锁,就可能被优化成更粗粒度的加锁。
在多次加锁的情况下,每次解锁之后重新加锁都会增加竞争,本来是执行多次加锁解锁可能会被优
化成一次加锁解锁
并不是锁越粗效率越高,视具体情况认定
CAS
CAS: 全称Compare and swap,字面意思:”比较并交换“
一个 CAS 涉及到以下操作
- 比较 A 与 V 是否相等。(比较)
- 如果比较相等,将 B 写入 V。(交换)
- 返回操作是否成功。
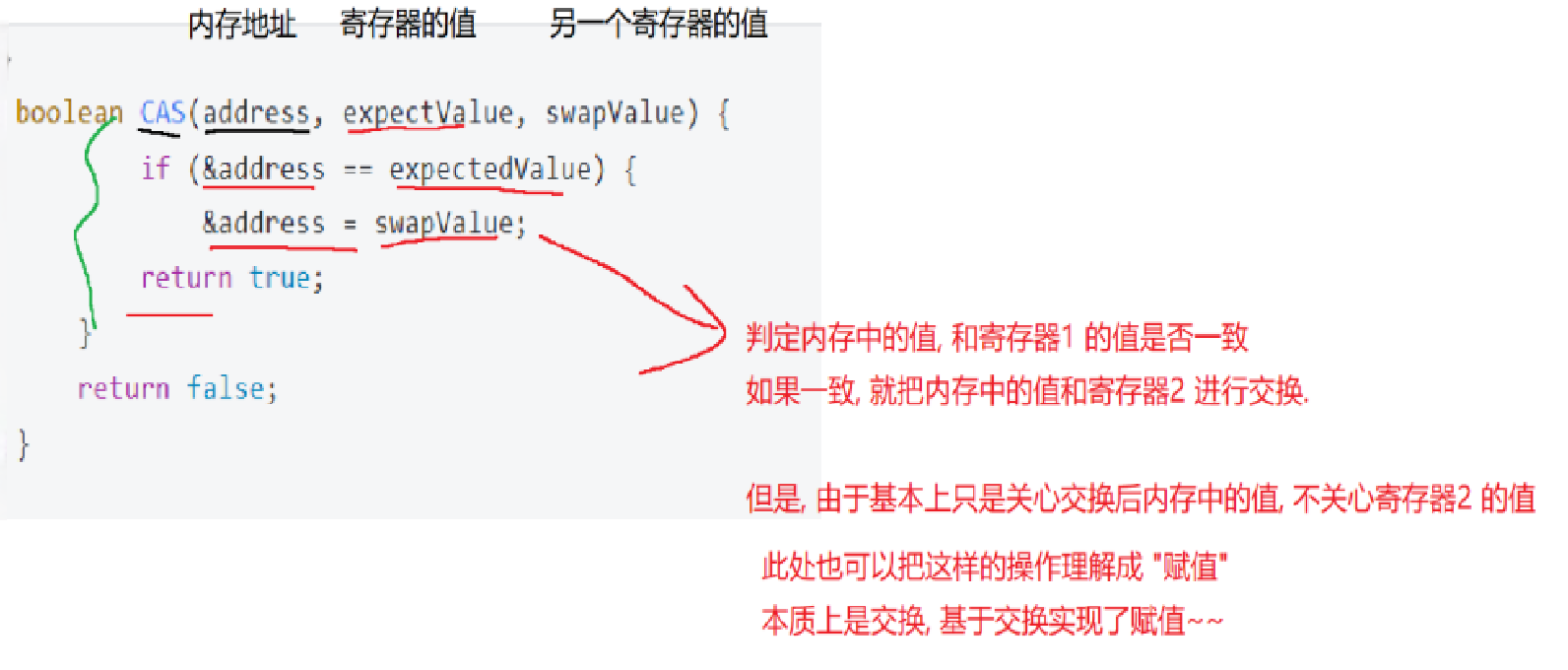
CAS
CAS是CPU的一条指令,这样的指令就给编写多线程代码/线程安全提供了很多便利
CAS本质是CPU的指令,操作系统把这个指令封装,提供一些api就可以在JVM中被调用

CAS的主要用途
- 实现原子类
boolean, int, long 这些类型进行加,减操作(例如count++)是线程不安全的,就需要加锁来解决
问题,但是又认为,加锁效率比较低
于是就可以通过 CAS 来实现 count++,确保性能,同时保证线程安全
是原子类的目的就是为了避免加锁
![]()
![]()
原子类专有名词特指atomic这个类
synchronized与原子类的区别
synchronized保证的是一个修改的原子性
原子类本身具有原子性
原子类的使用
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread t2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}对于上面这样的一个代码,当不加锁时会出现线程不安全的情况,由上面其他办法来解决
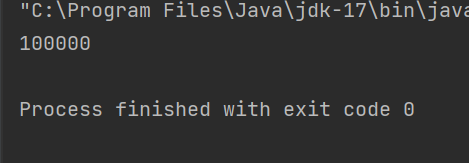
private static AtomicInteger count=new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.getAndIncrement();//count++
}
});
Thread t2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count.getAndIncrement();//count++
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
通过引入原子类发现线程安全的问题解决了,具体分析原子类操作中各处代码的含义
AtomicInteger
![]()
实例化一个对象,同时进行初始化
getAndIncrement()


类似于count++操作
incrementAndGet()
![]()
addAndGet()
![]()
类似于++count操作
- 实现自旋锁
自旋锁的实现

加锁操作中,就需要判定,锁是否被人占用,如果未被人占用,就把当前线程的引用设置到 owner
中,如果已经被人占用,就等待。
如果发现锁已经被占用,CAS 不会执行交换,返回 false进入循环再进入下一次判定,由于循环体
是空着的。整个循环速度非常快(忙等)但是一旦其他线程释放了锁,此时该线程就能第一时间拿
到这里的锁,此时就是自旋
CAS的缺陷
ABA问题
使用 CAS 能够进行线程安全的编程, 核心就是 先比较 "相等", 内存和寄存器是否相等
如果发现这里寄存器和内存的值一致, 就可以认为是没有线程穿插过来修改,但是实际上可能存
在一种情况, 另一个线程把内存从 A 修改成 B, 又从 B 修改回 A.
CAS 中的 ABA 问题, 其实大部分情况下即使出现了 ABA, 最终的程序一般也问题不大。只有一些
极端的场景, ABA 问题才回产生一些严重 bug
为了有效避免ABA问题,我们可以使用”版本号“的方法,每次修改版本号就+1
JUC(java.util.concurrent)的常见类
Callable 接口
Callable接口和Runnable接口并列关系
Callable接口返回值call(),泛型参数
Runnable接口返回值是void()类型
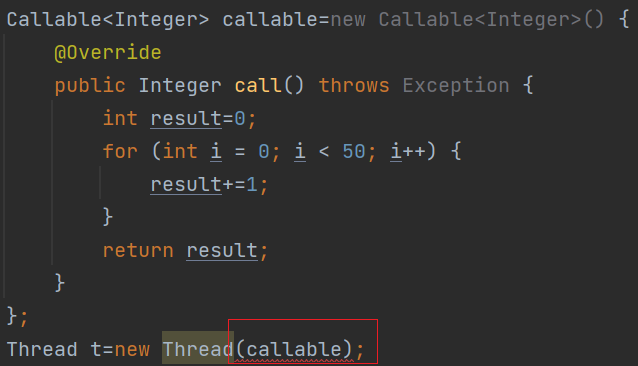
Thread本身不提供获取结果的方法需要凭FutureTask对象来拿到结果
Thread的构造方法没有提供版本传入Callable对象,但可以实现Runnable对象
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable<Integer> callable=new Callable<Integer>() {
@Override
public Integer call() throws Exception {
int result=0;
for (int i = 0; i < 50; i++) {
result+=1;
}
return result;
}
};
FutureTask<Integer> futureTask=new FutureTask<>(callable);
Thread t=new Thread(futureTask);
t.start();
System.out.println(futureTask.get());
}Thread就是线程和任务这个概念能剥离开,更不关心任务是啥样的任务(是否有返回值)
创建线程的写法
- 继承 Thread (定义单独的类/匿名内部类)
- 实现 Runnable (定义单独的类/匿名内部类)
- lambda
- 实现 Callable (定义单独的类/匿名内部类)
- 线程池, ThreadFactory
ReentrantLock
ReentrantLock是可重入互斥锁,ReentrantLock和synchronized是并列的关系,都是用来实现互斥
效果, 保证线程安全
synchronized和ReentrantLock之间的区别
- synchronized 是关键字(内部实现是 JVM 内部通过 C++ 实现的),ReentrantLock 标准库的类(Java)
- synchronized 通过代码块控制加锁解锁, ReentrantLock 需要 lock/unlock 方法需要注意 unlock 不被调用的问题.
- ReentrantLock除了提供 lock, unlock 之外, 还提供了一个方法, tryLock()
- ReentrantLock提供了公平锁的实现默认是非公平的,可以通过构造方法传入一个 true开启公平锁模式
- ReentrantLock搭配的等待通知机制是Condition类,相比wait/notify来说功能更强大一些,
tryLock()
tryLock()是判断加锁的情况,加锁成功返回true;加锁失败返回false,调用者判定返回值决定接下
来怎么做
tryLock()也可以设置超时时间,等待时间达到超时时间再返回true/false
private static int count=0;
public static void main(String[] args) throws InterruptedException {
ReentrantLock locker=new ReentrantLock();
Thread t1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
locker.lock();
count++;
locker.unlock();
}
});
Thread t2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
locker.lock();
count++;
locker.unlock();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}如何选择使用哪个锁
锁竞争不激烈的时候, 使用 synchronized, 效率更高, 自动释放更方便
锁竞争激烈的时候, 使用 ReentrantLock, 搭配 trylock 更灵活控制加锁的行为, 而不是死等
如果需要使用公平锁, 使用 ReentrantLock
信号量 Semaphore
信号量, 用来表示 "可用资源的个数". 本质上就是一个计数器描述了某种可用资源的个数,能够协调
多个进程之间的资源分配,也能够协调多个线程之间的资源分配
使用资源信号量 +1 ,这个称为信号量的 P 操作(对应Java中的acquire())
返回资源信号量 -1 ,这个称为信号量的 V 操作(对应Java中的release())
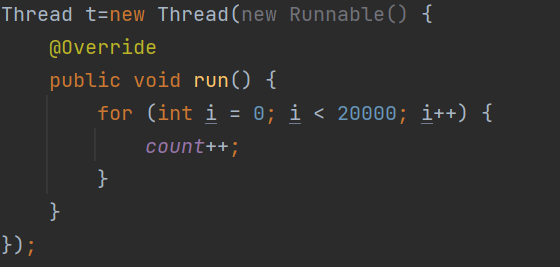
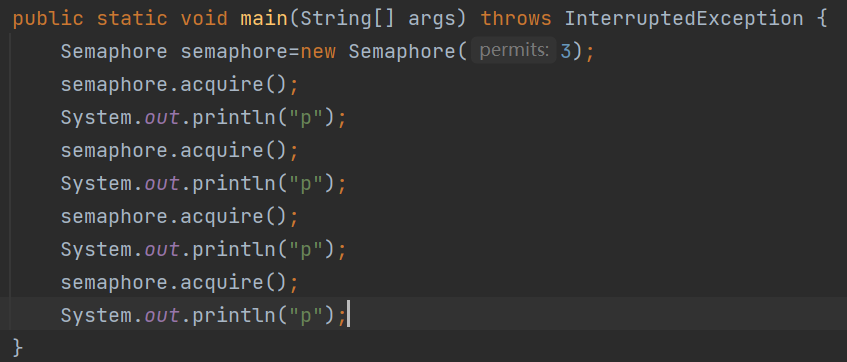
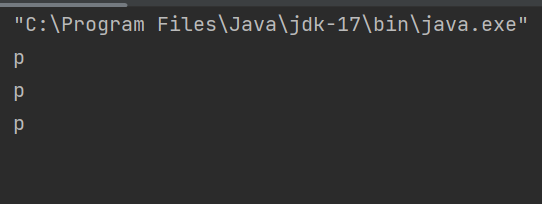
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore=new Semaphore(3);
semaphore.acquire();
System.out.println("p");
semaphore.acquire();
System.out.println("p");
semaphore.acquire();
System.out.println("p");
}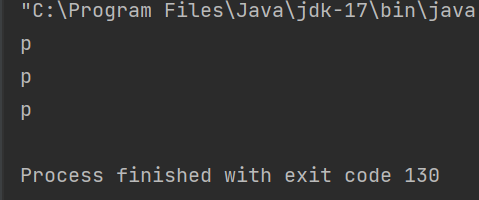
计数器为0继续申请,就会阻塞等待
信号量的一个特殊情况: 初始值为 1 的信号量.,取值要么是 1 要么是 0 (二元信号量),此时等价于
"锁" (普通的信号量, 就相当于锁的更广泛的推广)
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore=new Semaphore(1);
Thread t1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
try {
semaphore.acquire();
count++;
semaphore.release();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread t2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
try {
semaphore.acquire();
count++;
semaphore.release();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}CountDownLatch
同时等待 N 个任务执行结束
CountDownLatch的引出
使用多线程经常将一个大任务拆分成多个小任务,使用多线程执行这些子任务从而提高程序的效率
对于这些小任务怎么确定这些小任务都完成了?
- 构造方法指定参数描述拆成了多少个字任务
- 每个任务执行完毕之后都调用一次countDown方法
- 主线程调用await方法等待所有任务执行完毕,awiat就会返回否则一直阻塞
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch=new CountDownLatch(10);
ExecutorService service= Executors.newFixedThreadPool(4);
for (int i = 0; i < 10; i++) {
int finalI = i;
service.submit(() -> {
System.out.println("子任务开始执行" + finalI);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("子任务结束执行" + finalI);
latch.countDown();
});
}
latch.await();
System.out.println("任务执行完毕");
service.shutdown();
}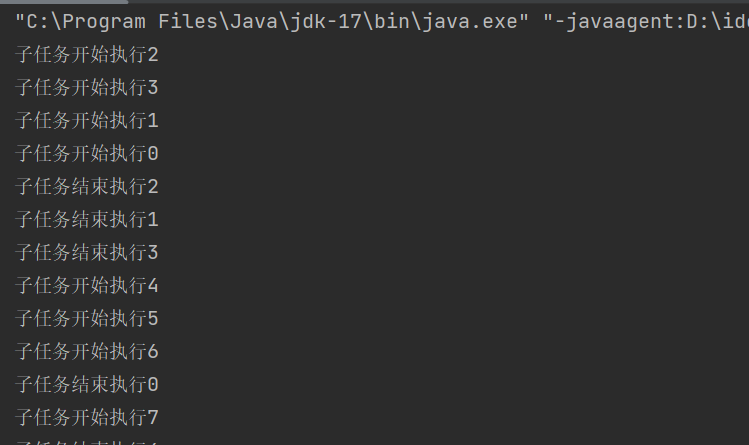

现在把整个任务拆成 10 个部分每个部分视为是一个 "子任务",可以把这 10 个子任务丢到线程池中让线程池执行,当然也可以安排 10 个独立的线程执行.
![]()
这个方法阻塞等待所有的任务结束,此处的 a => all
CountDownLatch是原子类,很实用但是用途不是特别广泛只针对特定场景解决方案
多线程下使用ArrayList
1.自行枷锁 [推荐]
分析清楚要把哪些代码打包到一起成为一个“原子”操作
2.Collections synchronizedList(new ArrayList);
相当于套壳,返回的List的各种关键字都是带有synchronized,类似于Vector Hashtable StringBuffer
3.使用CopyOnWriteArrayList
不去加锁而是去进行写时拷贝,CopyOnWrite容器即写时复制的容器。
原理:当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行
Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指
向新的容器。
要么完全读取未修改的数据,要么读取已经修改的数据,不会读到修改到一般的数据
缺陷
- 数组特别大的时候会非常低效
- 如果多个线程同时修改也容易出现问题
适用于特定场景的方案
多线程使用哈希表
HashMap 本身不是线程安全的.
在多线程环境下使用哈希表可以使用:
Hashtable (给各种public方法都加synchronized)
ConcurrentHashMap(效率更高,按照桶级别进行加锁而不是给整个哈希表加锁,有效降低锁冲突)
Hashtable
只是简单的把关键方法加上了 synchronized 关键字.

缺陷
如果多线程访问同一个 Hashtable 就会直接造成锁冲突.
size 属性也是通过 synchronized 来控制同步是比较慢的.
一旦触发扩容就由该线程完成整个扩容过程,这个过程会涉及到大量的元素拷贝效率会非常低.
ConcurrentHashMap
相比于 Hashtable 做出了一系列的改进和优化
以下面这张图为例
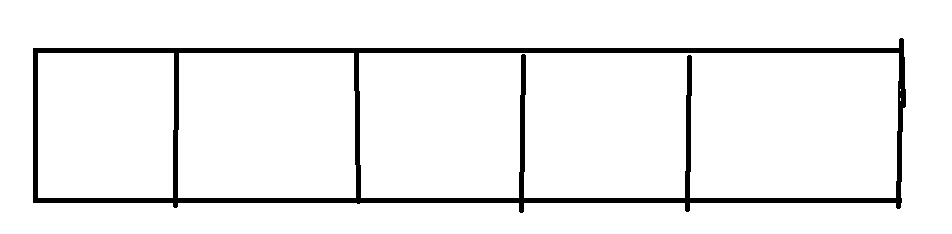
对于这样一个哈希表,Hashtable是采用全局加一把锁的形式,此时任意两个线程访问任意的两个
不同元素都会产生锁竞争,如果修改的两个元素, 在不同链表上本身就不涉及线程安全问题 (修改
不同变量)
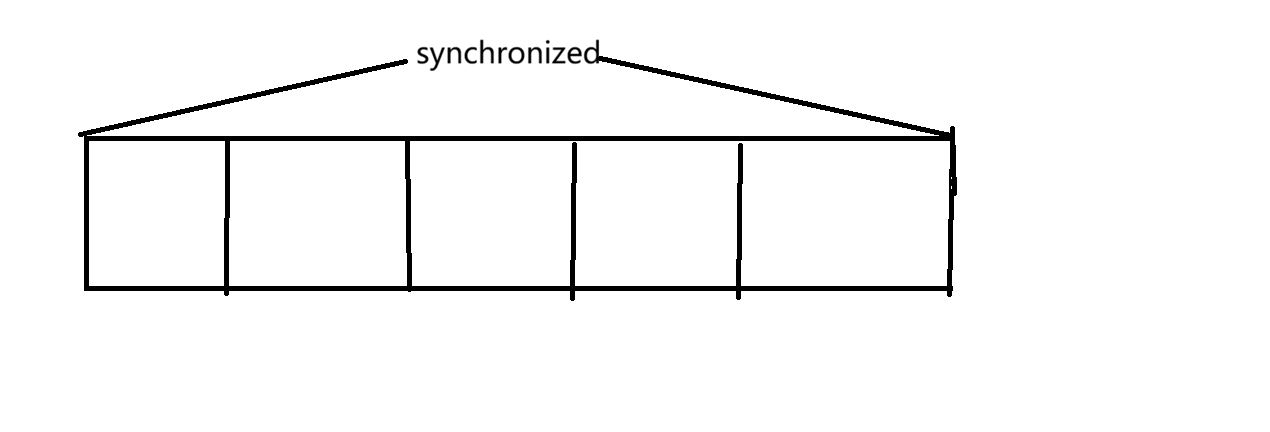
ConcurrentHashMap会针对不同的锁对象进行加锁不会产生锁竞争,针对每个哈希桶的链表的头
节点进行加锁
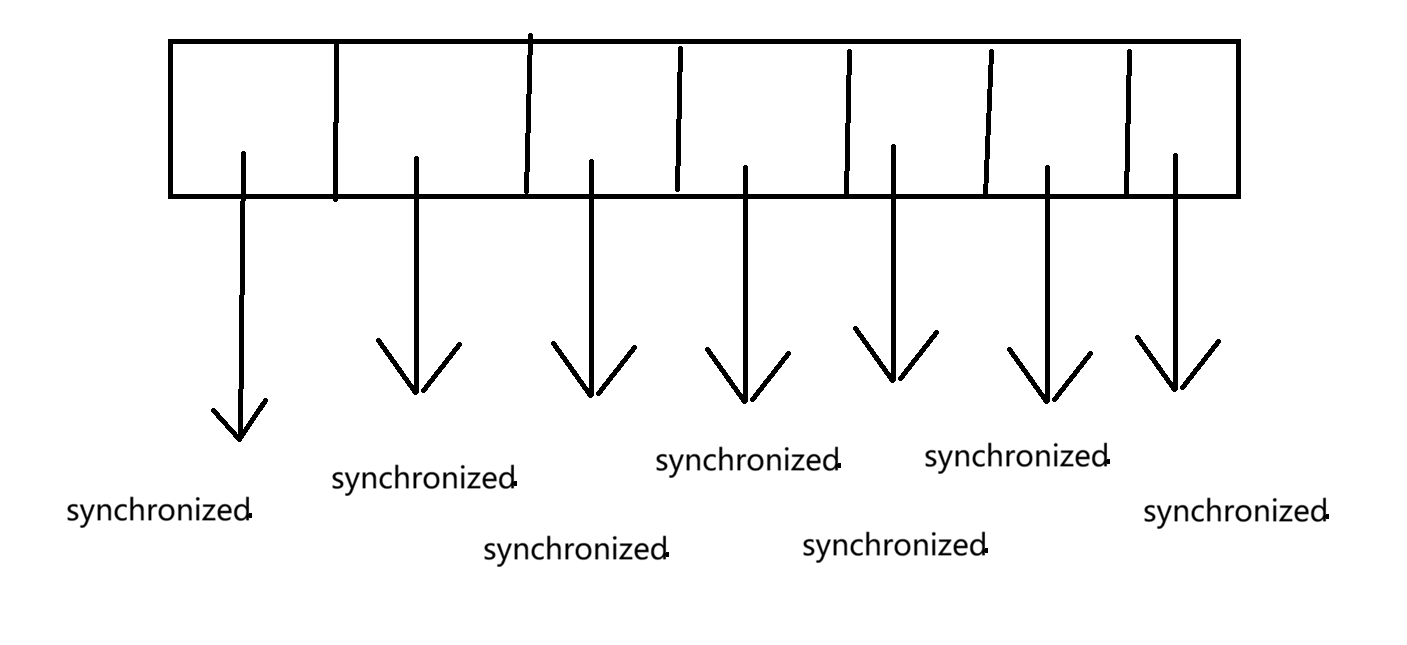
ConcurrentHashMap 核心优化点:
- 把锁整个表 => 锁桶
- 使用原子类针对size进行维护
- 针对哈希扩容的场景,化整为零,确保每个操作的加锁时间不要太长.每次操作一次, 加锁时间 1ms
更多推荐

 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)