
第二天:Java 线程池七大参数详解|面试必问 通俗易懂版(从线程基础到线程池实战)
第二天: Java 线程池七大参数详解| 通俗易懂版(从线程基础到线程池实战)
🔥 适合人群:Java零基础、准备面试的应届生、刚接触多线程的开发小白
🔥 核心亮点:从线程基础入手,循序渐进引出线程池,七大参数逐字拆解,大白话+代码+面试话术,看完直接背、直接用
前言
很多初学Java、准备面试的小伙伴,一听到「线程、多线程、线程池」就头大,概念分不清、用法记不住、面试一问就卡壳。
今天从零开始,先讲清楚什么是线程、创建线程的4种方式,再自然引出线程池的核心意义,最后把线程池七大参数掰开揉碎,用大白话+生活比喻讲透,零基础能听懂、面试直接背就能满分答题。
一、基础铺垫:什么是线程?(先搞懂底层,再学线程池)
要学线程池,必须先搞懂「线程」和「进程」的区别,否则线程池的设计逻辑根本理解不了,记七大参数也只是死记硬背。
1.1 什么是进程?
进程:电脑上独立运行的一个软件程序,是 资源分配的最小单位。
通俗比喻:进程就像你电脑上打开的「微信」「浏览器」「IDEA」,每打开一个软件,就相当于启动了一个进程。每个进程都有自己独立的内存空间和资源,互不干扰。
1.2 什么是线程?
线程:进程内部最小的执行单元,一个进程可以包含多个线程,是 任务执行的最小单位。
通俗比喻:如果把进程比作「一座工厂」,那么线程就是工厂里「干活的工人」—— 一座工厂(进程)可以有多个工人(线程),多个工人同时干不同的活,这就是「多线程」。
1.3 单线程 vs 多线程(为什么需要多线程?)
-
单线程:从头到尾按顺序干活,一件事做完再做下一件,效率极低(比如你一边吃饭一边看电视,只能交替进行,不能同时做)。
-
多线程:多个线程并行执行,同时处理多个任务,能充分利用CPU资源,提高程序效率(比如工厂里多个工人同时干活,比一个工人干所有活快得多)。
1.4 线程和进程的核心区别(面试简答必背)
为了更直观理解线程与进程的关系,附上简易流程图:
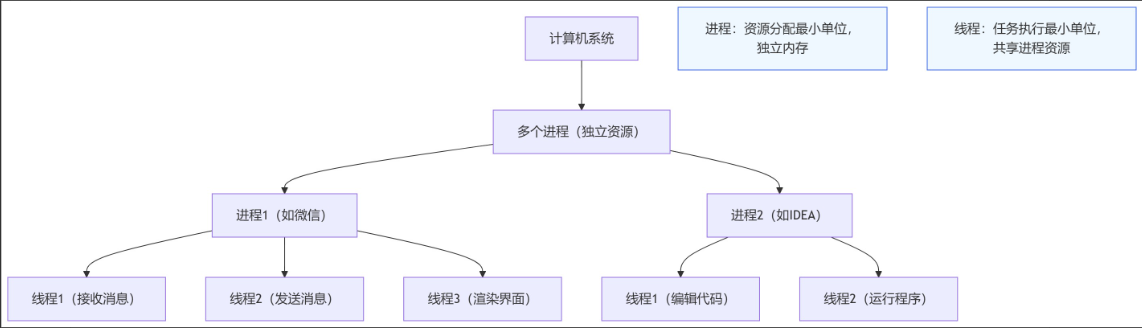
-
资源分配:进程有独立的内存和资源,线程共享所属进程的资源。
-
开销成本:创建、销毁进程的开销很大,线程的开销远小于进程。
-
稳定性:一个进程崩溃,不会影响其他进程;但一个线程崩溃,可能导致整个进程崩溃。
二、Java中创建线程的4种方式(超详细,附完整代码)
了解了线程的概念,接下来看Java中如何创建线程——这是基础,也是面试常考的基础题,4种方式全部掌握,小白也能轻松应对。
方式一:继承 Thread 类(最基础,有局限)
核心步骤:自定义类继承 Thread 类 → 重写 run() 方法(编写线程任务) → 创建子类对象,调用 start() 方法启动线程。
/**
* 方式一:继承Thread类
* 缺点:Java单继承局限,继承Thread后不能再继承其他类
*/
class MyThread extends Thread {
// 重写run()方法,写线程要执行的任务
@Override
public void run() {
// 模拟线程任务:循环打印
for (int i = 0; i < 5; i++) {
System.out.println("继承Thread的线程:" + i);
// 模拟任务耗时,便于观察多线程效果
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 测试使用
public class ThreadCreateDemo {
public static void main(String[] args) {
// 创建线程对象
MyThread thread = new MyThread();
// 启动线程(注意:不能调用run(),否则就是普通方法调用)
thread.start();
}
}
注意:启动线程必须调用 start() 方法,不能直接调用 run() 方法——start() 会触发JVM创建线程,再执行 run() 里的任务;直接调用 run() 只是普通的方法调用,不会创建新线程。
方式二:实现 Runnable 接口(推荐,无单继承局限)
核心步骤:自定义类实现 Runnable 接口 → 实现 run() 方法 → 创建 Runnable 对象,传给 Thread 构造器,调用 start() 启动。
/**
* 方式二:实现Runnable接口
* 优点:避免单继承局限,任务和线程分离,更灵活
*/
class MyRunnable implements Runnable {
// 实现run()方法,编写线程任务
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("实现Runnable的线程:" + i);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 测试使用
public class ThreadCreateDemo {
public static void main(String[] args) {
// 1. 创建Runnable任务对象
MyRunnable runnable = new MyRunnable();
// 2. 把任务传给Thread,创建线程并启动
new Thread(runnable).start();
}
}
对比方式一:这种方式更推荐使用,因为Java是单继承,实现接口不会影响类的继承关系,而且可以把「任务」和「线程」分离,便于复用任务逻辑。
方式三:实现 Callable 接口(带返回值、可抛异常)
前面两种方式(Thread、Runnable)的 run() 方法,有两个明显局限:无返回值、不能抛出异常。
如果需要获取线程执行的结果,或者线程任务可能抛出异常,就用 Callable 接口,配合 FutureTask 获取返回值。
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
/**
* 方式三:实现Callable接口
* 优点:有返回值、可抛出异常,适合需要获取线程执行结果的场景
*/
class MyCallable implements Callable<Integer> {
// 实现call()方法,返回值类型和Callable泛型一致
@Override
public Integer call() throws Exception {
int sum = 0;
// 模拟线程任务:计算1-10的和
for (int i = 1; i <= 10; i++) {
sum += i;
Thread.sleep(100);
}
// 返回线程执行结果
return sum;
}
}
// 测试使用
public class ThreadCreateDemo {
public static void main(String[] args) throws Exception {
// 1. 创建Callable任务对象
MyCallable callable = new MyCallable();
// 2. 用FutureTask包装Callable,用于获取返回值
FutureTask<Integer> futureTask = new FutureTask<>(callable);
// 3. 启动线程
new Thread(futureTask).start();
// 4. 获取线程执行结果(会阻塞,直到线程执行完成)
Integer result = futureTask.get();
System.out.println("线程执行结果:1-10的和 = " + result);
}
}
关键说明:FutureTask 的 get() 方法会阻塞主线程,直到子线程执行完成并返回结果,适合需要依赖线程结果继续执行的场景。
方式四:线程池创建线程(工作常用、面试重点)
前面3种方式,每次创建线程都要 new Thread(),用完就销毁,存在很多弊端(后面会详细说)。
实际工作中,我们几乎不用上面3种方式,而是用「线程池」统一管理线程——提前创建好线程,复用线程处理多个任务,不用频繁创建和销毁。
简单示例(后面会详细讲解线程池的创建和七大参数):
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 方式四:线程池创建线程(工作常用)
*/
public class ThreadPoolDemo {
public static void main(String[] args) {
// 1. 创建一个固定大小的线程池(3个线程)
ExecutorService threadPool = Executors.newFixedThreadPool(3);
// 2. 提交3个任务,线程池复用线程处理
for (int i = 0; i < 3; i++) {
threadPool.submit(() -> {
System.out.println("线程池中的线程执行任务:" + Thread.currentThread().getName());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 3. 关闭线程池(一般项目中不用手动关闭,随项目生命周期)
threadPool.shutdown();
}
}
三、为什么需要线程池?(引出线程池核心意义)
既然我们已经会创建线程了,为什么还要用线程池?—— 这是面试常问的问题,核心就是「解决传统创建线程的弊端」。
3.1 传统创建线程的3大弊端(面试必背)
-
开销极大:频繁创建、销毁线程,会消耗大量CPU和内存资源(就像临时招人、辞退人,招聘和辞退的成本很高)。
-
系统不稳定:无限制创建线程,线程太多会互相抢占CPU和内存,导致程序卡顿、死机,甚至出现OOM(内存溢出)。
-
无法管控:不能统一管理线程数量、任务排队规则,一旦任务过多,会出现任务混乱、执行无序的情况。
3.2 线程池的4大核心作用(面试必背)
-
线程复用:线程创建后不销毁,反复处理多个任务,减少创建、销毁的开销(就像固定员工,干完活继续待命,不用辞退)。
-
控制最大并发:限制线程总数,避免无限制创建线程拖垮系统(比如工厂规定最多10个工人,不会因为活多就无限招人)。
-
任务排队管理:任务太多时,自动进入队列排队,有序执行,避免任务混乱(就像客户排队办理业务,不会拥挤)。
-
统一管控:可统一设置线程空闲回收时间、任务拒绝规则、线程名称,便于线上排查问题(比如给每个工人贴标签,方便管理)。
四、线程池七大参数超详细讲解(面试必考,重中之重)
Java中线程池的核心实现类是 ThreadPoolExecutor,其构造方法中包含7个参数,这7个参数决定了线程池的工作机制——面试时,只要能把这7个参数讲清楚,就能拿到满分。
4.1 线程池标准构造方法(七大参数原型)
/**
* ThreadPoolExecutor 核心构造方法,包含7个参数
*/
public ThreadPoolExecutor(
int corePoolSize, // 1. 核心线程数(常驻线程)
int maximumPoolSize, // 2. 最大线程数(核心+临时工)
long keepAliveTime, // 3. 空闲线程存活时间(临时工空闲多久被辞退)
TimeUnit unit, // 4. 时间单位(配合上面的存活时间)
BlockingQueue<Runnable> workQueue,// 5. 任务阻塞队列(任务排队区)
ThreadFactory threadFactory, // 6. 线程工厂(创建线程的工厂)
RejectedExecutionHandler handler // 7. 拒绝策略(任务爆满时的处理方式)
)
4.2 七大参数逐个拆解(大白话+面试话术,通俗易懂)
1. corePoolSize(核心线程数)
通俗解释:线程池中的「正式员工」,常驻线程,只要线程池不关闭,这些线程就永远不会被销毁,一直待命,优先处理新任务。
核心特点:
-
线程池初始化后,核心线程不会立即创建,而是等到有任务提交时才创建(可以通过 prestartAllCoreThreads() 方法提前初始化所有核心线程)。
-
核心线程空闲时,不会被回收,一直保持存活状态,等待新任务。
业务配置建议(工作常用):
-
CPU密集型任务(比如计算、排序):核心线程数 ≈ CPU核心数(比如8核CPU,设置8个核心线程),避免线程切换消耗CPU。
-
IO密集型任务(比如数据库操作、接口调用、文件读写):核心线程数可以设置大一点(比如20、50),因为IO操作会有大量等待时间,线程空闲时可以处理其他任务。
面试话术:核心线程数是线程池中常驻的线程数量,线程池不关闭则核心线程一直存活,不被回收,新任务会优先交给核心线程执行,用于保证任务的快速响应。
2. maximumPoolSize(最大线程数)
通俗解释:线程池能创建的「最大线程总数」,等于「核心线程数 + 临时工线程数」—— 只有在核心线程全部忙完、任务队列也满了的情况下,才会创建临时工线程,直到达到这个最大值。
核心公式:临时工线程数 = maximumPoolSize - corePoolSize
触发时机:核心线程全部忙碌 + 任务阻塞队列已满 → 新建临时工线程处理新任务。
注意:最大线程数不能设置太大,否则会导致线程过多,抢占资源,反而降低效率;也不能设置太小,否则无法应对高并发任务。
面试话术:最大线程数是线程池允许创建的线程总数上限,由核心线程和非核心线程(临时工)组成,只有在核心线程满载且队列满时,才会创建非核心线程,直到达到该上限。
3. keepAliveTime(空闲线程存活时间)
通俗解释:只对「临时工线程」生效,指临时工线程干完活后,空闲多久会被销毁,释放系统资源(就像临时工没事干,超过规定时间就被辞退)。
核心特点:
-
默认只对非核心线程生效,核心线程不会被回收。
-
可以通过 allowCoreThreadTimeOut(true) 方法,让核心线程也受该时间控制(空闲超时后也会被回收)。
面试话术:空闲线程存活时间是指非核心线程空闲后的最大存活时长,超时后会被自动回收,用于节省系统资源,避免空闲线程占用内存。
4. unit(时间单位)
通俗解释:配合上面的 keepAliveTime,指定空闲线程存活时间的单位,避免歧义。
常用时间单位(TimeUnit类静态常量):
-
TimeUnit.MILLISECONDS:毫秒(最常用,1秒=1000毫秒)
-
TimeUnit.SECONDS:秒
-
TimeUnit.MINUTES:分钟
-
TimeUnit.HOURS:小时
示例:keepAliveTime=10,unit=TimeUnit.SECONDS → 表示临时工线程空闲10秒后被销毁。
5. workQueue(任务阻塞队列)
通俗解释:线程池的「任务排队区」,当核心线程全部忙碌时,新提交的任务不会直接创建新线程,而是先进入这个队列排队,等有核心线程空闲了,再从队列中取出任务执行。
核心作用:缓冲任务,避免任务过多时直接创建大量线程,保护系统稳定。
面试常考3种队列(重点):
-
ArrayBlockingQueue(有界队列):
-
特点:队列容量固定,有明确的上限。
-
优点:能控制任务队列大小,避免任务堆积导致OOM。
-
适用:高并发场景,需要控制队列长度,避免系统压力过大。
-
-
LinkedBlockingQueue(无界/有界队列):
-
特点:默认是无界队列(容量无限大),也可以手动设置容量。
-
缺点:无界队列会导致任务无限堆积,最终引发OOM(内存溢出)。
-
适用:任务量可控、并发不高的场景。
-
-
SynchronousQueue(同步队列):
-
特点:不存储任何任务,来了任务必须立马有线程处理,否则就会创建新线程(直到达到最大线程数)。
-
适用:任务处理速度快、并发高的场景(比如实时通信)。
-
面试话术:任务阻塞队列是核心线程满载后,新任务的临时存放区域,用于缓冲任务;不同队列的选择会影响线程池的性能和稳定性,常用的有有界队列ArrayBlockingQueue、无界队列LinkedBlockingQueue和同步队列SynchronousQueue。
6. threadFactory(线程工厂)
通俗解释:专门负责「创建线程」的工厂,主要作用是自定义线程的相关属性,方便线上排查问题。
核心作用:
-
自定义线程名称(比如命名为「order-thread-1」「pay-thread-2」),便于日志排查和线程堆栈定位。
-
设置线程优先级(1-10,默认5)、是否为守护线程等。
简单示例(自定义线程工厂):
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
// 自定义线程工厂,设置线程名称
class MyThreadFactory implements ThreadFactory {
// 原子类,保证线程安全,用于计数
private final AtomicInteger threadNum = new AtomicInteger(1);
// 线程名称前缀
private final String prefix;
public MyThreadFactory(String prefix) {
this.prefix = prefix;
}
@Override
public Thread newThread(Runnable r) {
// 自定义线程名称:prefix + 线程编号
Thread thread = new Thread(r, prefix + "-thread-" + threadNum.getAndIncrement());
// 设置线程优先级(默认5)
thread.setPriority(Thread.NORM_PRIORITY);
// 非守护线程(默认就是非守护线程)
thread.setDaemon(false);
return thread;
}
}
// 使用:创建线程池时传入自定义线程工厂
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
3, 5, 10, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10),
new MyThreadFactory("java-thread-pool"), // 自定义线程工厂
new ThreadPoolExecutor.AbortPolicy()
);
面试话术:线程工厂用于创建线程,可自定义线程名称、优先级、守护线程属性,其核心作用是便于线上日志排查和线程问题定位,避免默认线程名(pool-xxx-thread-xxx)无法区分业务线程。
7. RejectedExecutionHandler(拒绝策略)
通俗解释:当线程池达到「最大线程数」,且「任务队列也满了」,再来新任务时,线程池无法处理,此时就会触发拒绝策略,处理这些无法执行的任务。
触发条件(必背):核心线程满 + 队列满 + 达到最大线程数 → 触发拒绝策略。
JDK内置4种拒绝策略(面试必背,逐字记):
-
AbortPolicy(默认策略):
-
行为:直接抛出 RejectedExecutionException 异常,阻止程序继续运行。
-
适用:不允许任务丢失的场景,比如支付、订单提交等核心业务。
-
-
CallerRunsPolicy(调用者运行策略):
-
行为:谁提交的任务,谁自己执行(比如主线程提交任务,就由主线程执行该任务)。
-
优点:不会抛异常、不会丢任务,能缓解线程池压力。
-
缺点:会阻塞提交任务的线程,影响主线程效率。
-
-
DiscardPolicy(丢弃策略):
-
行为:直接丢弃无法处理的新任务,不抛异常、不通知。
-
适用:任务无关紧要,允许丢失的场景(比如日志收集)。
-
-
DiscardOldestPolicy(丢弃最老任务策略):
-
行为:丢弃任务队列中最老的任务(最早提交的任务),然后执行新任务。
-
适用:任务有先后顺序,但允许丢弃老任务的场景。
-
面试话术:拒绝策略是线程池无法处理新任务时的处理方式,JDK内置4种策略,分别是AbortPolicy(抛异常)、CallerRunsPolicy(调用者执行)、DiscardPolicy(丢弃任务)、DiscardOldestPolicy(丢弃最老任务),实际开发中可根据业务场景选择合适的策略。
五、线程池任务执行完整流程(必背,面试高频)
掌握了七大参数,还要懂线程池的任务执行流程——把流程讲清楚,能体现你对线程池的深度理解,面试加分。
线程池任务执行完整流程图(贴合面试话术,可直接记忆):
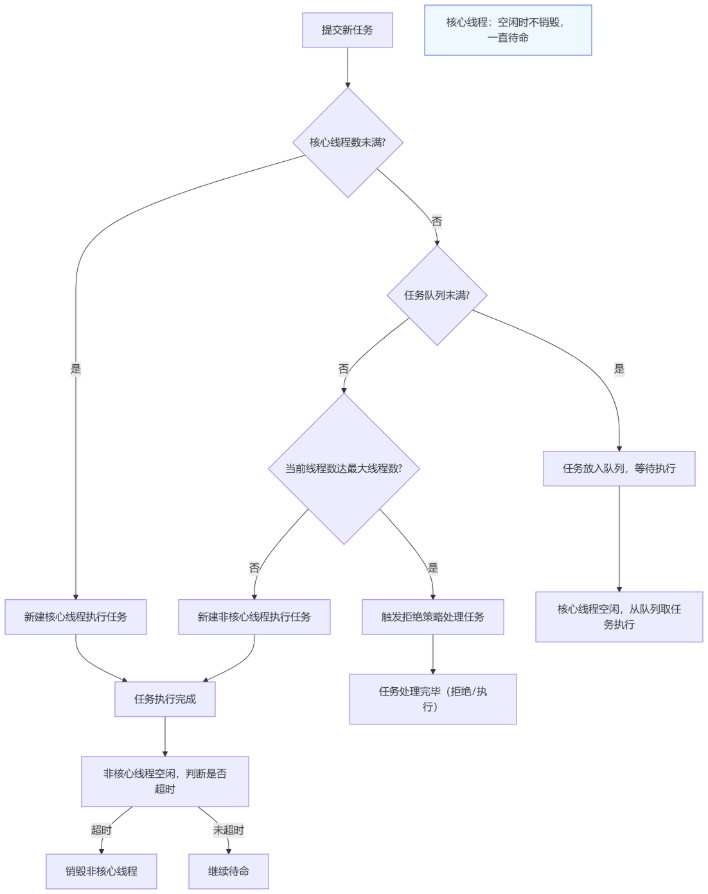
-
新任务提交到线程池,首先判断「核心线程数」是否未满。
-
如果核心线程未满,新建核心线程,执行该任务。
-
如果核心线程已满,判断「任务阻塞队列」是否已满。
-
如果队列未满,将任务放入队列,等待核心线程空闲后执行。
-
如果队列已满,判断「当前线程数」是否达到「最大线程数」。
-
如果未达到最大线程数,新建非核心线程(临时工),执行该任务。
-
如果已达到最大线程数,触发「拒绝策略」,处理该任务。
通俗总结:先找正式员工(核心线程)→ 正式员工忙,就排队(队列)→ 队列满了,找临时工(非核心线程)→ 临时工也满了,就拒绝(拒绝策略)。
六、面试常考补充(加分项)
6.1 线程池的状态(面试简答)
线程池有5种状态,了解即可,面试时能说出来就加分:
-
RUNNING:运行状态,能接收新任务,处理队列中的任务。
-
SHUTDOWN:关闭状态,不接收新任务,但会处理完队列中的任务。
-
STOP:停止状态,不接收新任务,不处理队列中的任务,中断正在执行的任务。
-
TIDYING:整理状态,所有任务执行完毕,线程数为0,准备进入TERMINATED状态。
-
TERMINATED:终止状态,线程池彻底关闭。
6.2 工作中如何合理配置线程池?(面试综合题)
核心原则:根据任务类型(CPU密集型/IO密集型)配置核心线程数和最大线程数,选择合适的队列和拒绝策略。
-
CPU密集型:核心线程数 ≈ CPU核心数,最大线程数 = CPU核心数 + 1(避免线程切换消耗)。
-
IO密集型:核心线程数 = CPU核心数 * 2,最大线程数可以设置为CPU核心数 * 4(根据IO等待时间调整)。
-
队列选择:优先用有界队列(ArrayBlockingQueue),避免无界队列导致OOM。
-
拒绝策略:核心业务用AbortPolicy(抛异常,及时发现问题),非核心业务用DiscardPolicy或CallerRunsPolicy。
总结
本文从线程基础入手,循序渐进讲解了线程的概念、创建线程的4种方式,再引出线程池的核心意义,最后详细拆解了线程池七大参数和任务执行流程,全程通俗易懂,无复杂理论。
对于面试来说,重点记住:线程和进程的区别、创建线程的4种方式、线程池的作用、七大参数的含义+面试话术、任务执行流程——掌握这些,线程池相关的面试题就能轻松应对。
如果觉得本文对你有帮助,欢迎点赞+收藏+关注,后续会持续更新Java核心知识点和面试干货!
通过网盘分享的文件:Java 线程池七大参数详解|通俗易懂版(从线程基础到线程池实战).zip
链接: https://pan.baidu.com/s/1dgI6IrI9a_qo-sXwBEbv-A 提取码: utx8
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)