
【c++】哈希表-开放定址法的实现
·
- 在里面不会根据key值进行排序,遍历出来是无序的。

在这里插入图片描述
- 以上是unordered_set的声明,Key是unordered_set底层关键字的类型。
- unordered_set有两个仿函数类型要求Hash和Pred,第一个是默认要求Key支持转换成整型,这与它的底层是哈希桶有关。如果不支持或想按照自己的需求走,可以自行实现将Key转成整型的仿函数传给第二个模板参数。
- 第二个是默认要求支持比较相等,这个也与底层哈希桶有关,如果不支持或者想按照自己的需求走,可以自行实现比较相等的仿函数传给第三个模板参数。
- unordered_set底层存储数据是从空间配置器申请的,如果有需要可以自己实现内存池,然后传给第四个模板参数。
- 一般来说,后面三个模板参数在实际使用中是不需要进行传递的。
差异
- 性能差异:unordered_set相对于set 增删查 O(logN)的时间复杂度,它的时间复杂度是O(1),但实际差距没有这么大。
- key的要求的差异:set要求默认支持小于比较,而unordered_set默认是要求支持等于比较,而且还要支持有Key转换整型的仿函数。它也会除重。
- 迭代器以及遍历顺序差异:set是双向迭代器,而unordered_set是支持单向迭代器。前者中序遍历->有序,后者无序。
- unordered_multimap/unordered_multiset跟multimap/multiset功能完全类似,支持Key冗余。
- unordered_multimap/unordered_multiset跟multimap/multiset之间的差异也是性能、key的要求、迭代器与遍历顺序三个方面的差异。
二、认识哈希表
1. 哈希概念
- 哈希(hash)又称散列,是一种组织数据的方式。它的本质就是通过哈希函数把关键字Key跟存储位置(数组下标)建立一个映射关系,然后查找时通过这个哈希函数来计算出Key存储的位置,进而做到快速查找。
- 哈希表通常通过数组来实现。
- 我们通过下面的直接定址法来更好的理解让关键字跟存储位置建立一个映射关系:
2. 直接定址法
- 直接定址法:直接定址法适用于关键字的范围比较集中时,比如一组关系都在[0, 99]之间,那么我们开一个大小为100个数的数组,每个关键字的值直接就是存储位置的下标。又比如一组关键字的值都在[a, z]的小写字母,那么我们开一个大小为26的数组,每个关键字ascii码 - ‘a’(a的ascii码)就是存储位置的下标。直接定址法的本质就是用关键字计算出一个绝对或者相对位置。
- 现在有一个题目:给定一个字符串 s (只有小写英文字母),找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。
- 代码实现:
代码语言:javascript
AI代码解释
int firstUniqChar(string s) {
int count[26] = {0};
for (auto e : s)
{
count[e - 'a']++;
}
//i是用来遍历s的,不是用来遍历count的
for (int i = 0; i < s.size(); i++)
{
if (count[s[i] - 'a'] == 1)
{
return i;
}
}
return -1;
}- 这里我们建立了一个用来计数的数组count,然后每一个值全初始化为0,每一个英文字母减去字母a得到的ascii值都能映射到对应的一个下标上面。之后遍历s里面的每一个英文字符,就能轻松得到每一个字母出现的次数。如果我们想要确认s里面有没有字母a,只需要访问count[0]就能知道,这里的映射关系就是数组下标 = 字母 - ‘a’。这里的关键字就是s里面出现的英文字母,它们和count数组的下标建立了映射关系。
- 直接定址法的缺点也非常明显,那就是如果关键字的范围比较分散的话,比如只存2个数,一个1,一个10000,难不成要开上10000个数大小的数组吗?甚至在有的情况下内存是不够用的,这样就太浪费空间了,所以又有其他的方法让关键字跟存储位置之间建立一个映射关系,比如除留余数法/除法散列法。
3. 除法散列法/除留余数法
- 除法散列法也叫做除留余数法,假设哈希表的大小为M,那么让关键字Key除以M得到的余数作为映射位置的下标,就能够确保所有的数都能映射到这个哈希表对应的位置上。它的哈希函数为:h(key)= key%M。
- 当使用除法散列法时,要尽量避免M为某些值,如2的幂,10的幂等。如果是2^x,那么key%2^x的本质就相当于是保留key二进制的后x位,后x位相同的值计算出来的哈希值h(key)都是一样的(会造成哈希冲突,接下来会讲到)。比如{63, 31}这两个数看起来完全没有关联,但63二进制后八位是00111111,31的二进制后八位是00011111,如果M是16,那么计算出来的哈希值就都是15,将二进制倒数第四位之前的1都抹去了。如果是10^x,保留10进制后面的x位,也是同理,它就更明显了,如果M是10,2与12与22都是一样的哈希值2。
- 当使用除法散列法时,建议M取不太接近2的整数次幂的一个质数。实践中如果可以有效解决冲突的话,M取2的整数次幂也可以,比如java里面HashMap的实现里M就是取的2的整数次幂。
- 还有其他的方法,比如乘法散列法,全域散列法等,有兴趣的读者大大们可以去了解了解。
4. 哈希冲突
当两个不同的key值经过哈希函数和模运算之后得到的数组下标可能一样,会映射到同一个位置去,这种问题我们叫做哈希冲突,也叫做哈希碰撞。
- 理想的情况是设计出一个能够避免冲突的哈希函数,但在实际情况中,冲突不可避免,能够做到的就是尽可能设计出优秀的哈希函数,减少冲突的次数,也要设计出解决冲突的办法。
5. 哈希函数
哈希函数是将任意大小的数据映射到固定范围的整数值的函数,这个整数值再通过某种方式(通常是取模)转换为数组下标。
- 比如除法散列法的的哈希函数是h(key)= key%M,模出来的哈希值被固定在0到M - 1范围内,这里的哈希值就是数组下标。
key → 哈希函数 → 哈希值 → 取模运算 → 数组下标
- 一个好的哈希函数应该让N个关键字被等概率的均匀的分布到哈希表的M个空间中,但是实际中很难做到,但也应该朝着这个方向去设计。
6. 负载因子
假设哈希表中已经映射了存储了N个值,而哈希表的大小为M,那么负载因子 = N/M。负载因子越大,代表它的空间利用率越高,越小,代表它的存储效率越高。
- 负载因子越大,代表这个哈希表越满,接下来的存储就越容易发生哈希冲突,发生哈希冲突然后根据处理哈希冲突的方法进行存储,效率一定会降低。负载因子越小,接下来的存储虽然不容易发生哈希冲突,但是会造成空间的浪费。负载因子的取值很重要,一般是取0.7左右。
三、处理哈希冲突-开放定址法的具体实现
- 解决哈希冲突主要有两种方法,开放定址法和链地址法,接下来我们来了解解决哈希冲突其中的一种办法—开放定址法。
1. 开放定址法
在开放定址法中所有的元素都放到哈希表里,当一个关键字key用哈希函数计算出的位置冲突了,则按照某种规则找到一个没有存储数据的位置进行存储,开放定址法中负载因子一定是小于1的。这里的规则有三种:线性探测,二次探测,双重探测。
1.1 线性探测
- 从发生冲突的位置开始,依此线性向后探测,直到寻找到下一个没有存储数据的位置为止,如果走到哈希表尾,则要回绕到哈希表头的位置。
- 即 h(key)= key % M = hash0,如果hash0的位置冲突了,则线性探测公式为:h(key)= hashi = (hash0 + i)% M, i = {1,2,3,…,M - 1},由于负载因子是小于1的,那么探测最多M - 1次一定能够找到存储位置。因为哈希表一定还是有没有存储数据的存储位置的。
- 群集/堆积:若hash0位置连续冲突,且hash0,hash1,hash2都已经存储了数据,那么后续映射到hash0,hash1,hash2的值都会抢夺hash3的位置,这种现象叫做群集/堆积。而二次探测可以在一定程度上解决这个问题。
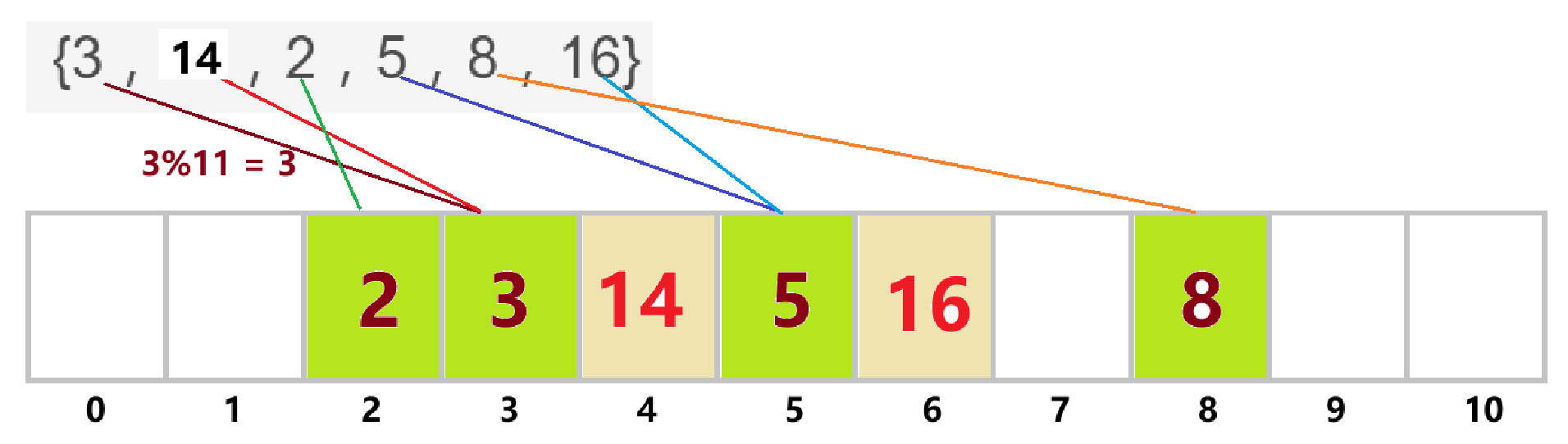
- 接下来通过一组数组来演示一下如何利用线性探测规则来存储数据。 {3,14,2,5,8,16},M为11,利用除法散列法,哈希函数为:h(key)= key % M。
在这里插入图片描述
- 按照顺序一个一个往里面存储数据,3会映射到下标为3的位置,14也会映射到下标为3的位置,但是这个位置已经存储了数据,那么14就要从下标为3的这个位置往后找一个没有存储数据的位置–下标为4的这个位置,之后再存储2,5,8,16,也是同理。如果直接映射到的那个位置没有存储值,那么直接存储就好,但若已经存储了值,就需要线性往后面找一个没有存储值的位置进行存储。
- 至于查找,也是根据key通过哈希函数得到的映射位置hash0,然后让key与这个位置存储的值进行比较,如果不相等则继续线性向后寻找然后依次进行比较,直到找到这个与key相等的值或者遇到没有存储数据的位置。
1.2 二次探测
- 从发生冲突的位置开始,依次左右按二次方跳跃式探测,直到寻找到下一个没有存储数据的位置为止,如果往右走到哈希表尾,则回绕到哈希表头的位置;如果往左走到哈希表头,则回绕到哈希表尾的位置。
- h(key)= hash0 = key % M, hash0的位置冲突了,则二次探测公式为: hc(key,i)= hashi = (hash0 ± i^2)% M,i = {1,2,3,…,M/2}(就是i变成了i^2。
- 二次探测当hashi = (hash0 - i ^ 2)% M时,当hashi < 0时,需要hashi += M。
- 二次探测能在一定程度上解决群集/堆积的问题,但是无法完全避免。双重散列能够进一步解决这个问题。
- 其实二次探测包括下面的双重散列都是为了让数据的存储能够更加分散,更加均匀,能够尽可能的减少哈希冲突。
1.3 双重散列(了解)
- 第一个哈希函数计算出的值发生冲突,使用第二个哈希函数计算出一个跟key相关的偏移量值,不断往后探测,直到寻找到下一个没有存储数据的位置为止。
- h1(key)= hash0 = key%M,hash0位置冲突了,则双重探测公式为: hc(key,i)= hashi = (hash0 + i * h2(key))% M,i = {1,2,3,…,M}。
- 要求h2(key)< M 且 h2(key)和 M 互为质数,有两种简单的取值方法:1、当M为2整数幂时,h2(key)从[0, M - 1] 任选一个奇数;2、当M为质数时,h2(key)= key % (M - 1) + 1。
- 保证h2(key)与 M 互质是因为根据固定的偏移量所寻址的所有位置将形成一个群,若最大公约数p = gcd(M,h1(key))> 1,那么所能寻址的位置的个数为M/P < M,使得对于一个关键字来说无法充分利用整个散列表。举例来说,若初始探查位置为1,偏移量为3,整个散列表大小为12,那么所能寻址的位置为{1,4,7,10},寻址个数为12 / gcd(12,3) = 4。
2. 开放定址法代码实现
2.1 框架搭建
- 我们首先要思考一个问题,如何删除一个数?倘若直接删掉它,而又有多个key都是映射到这个位置上的,删去它存储在它后面的key值应该如何去找?毕竟我们的查找的逻辑是将存储的值与key值进行比较,直到找到它或遇到没有存储key值的位置就停止,直接删掉的话,首次查找就会停止。如上表,我们若是直接将3删掉,那么这个位置将为空,14应该如何去找到?
- 我们转变思路,可以不将它直接删掉,而是设立一个状态变量用来储存每个哈希表里存储数据的状态,表示它是空(EMPTY),是删掉了(DELETE),还是存在着(EXIST),枚举类型可以很好的表示。
- 哈希表通常由数组实现,我们通过vector来实现,里面存储着的是哈希表里的数据。这个数据应该要由表示它的状态量和真正存储的数据组合而成–类HashData。
更多推荐

 1
1 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)