
Java 篇-项目实战-AI 天机学堂(从 0 到 1)-day2
java 篇: 1.基础地基 2.设计原理 3.项目实战
基本对话与课程咨询-技术架构及集成 SpringAI:
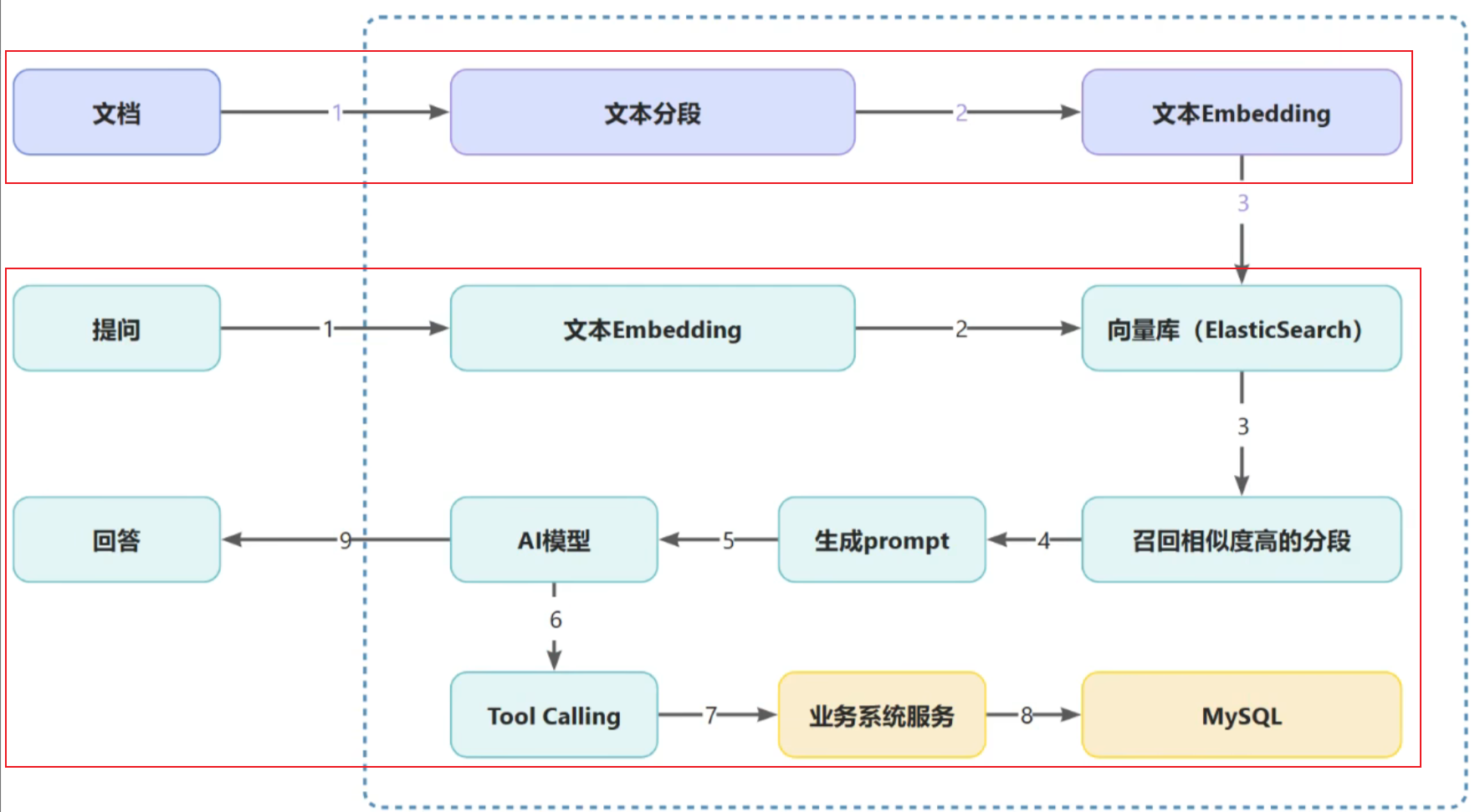
基本要求:JDK17 以上,SpringBoot3 以上。如果原先项目不满足,但是又想有 ai,就得新建一个项目,通过 http 的形式,进行交互。

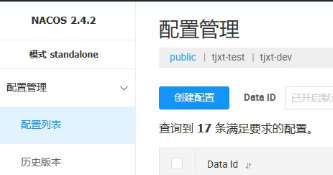
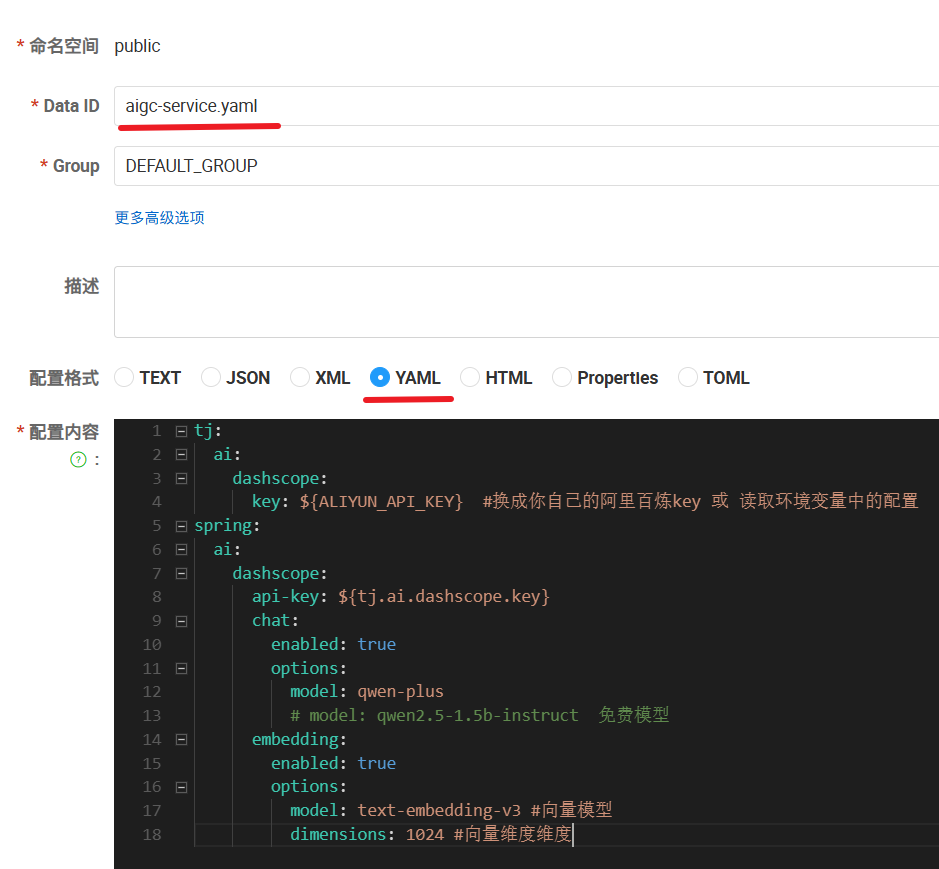
配置是 public,服务是 dev
Spring Cloud Gateway 的路由配置:
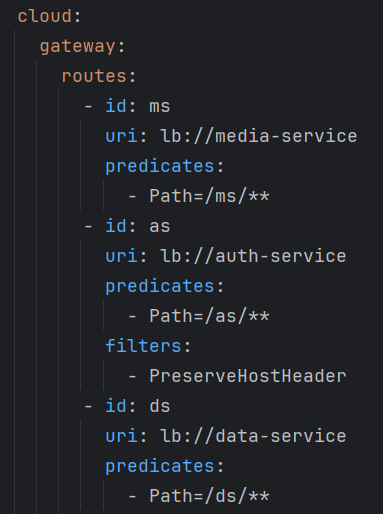

转发请求去掉路径的前 1 段
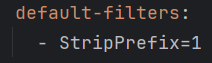
效果:
| 配置 | 原始路径 | 转发后路径 |
| `StripPrefix=1` | `/ms/video/list` | `/video/list` |
| `StripPrefix=2` | `/a/b/video/list` | `/video/list` |
| `StripPrefix=0` | `/ms/video/list` | `/ms/video/list` |
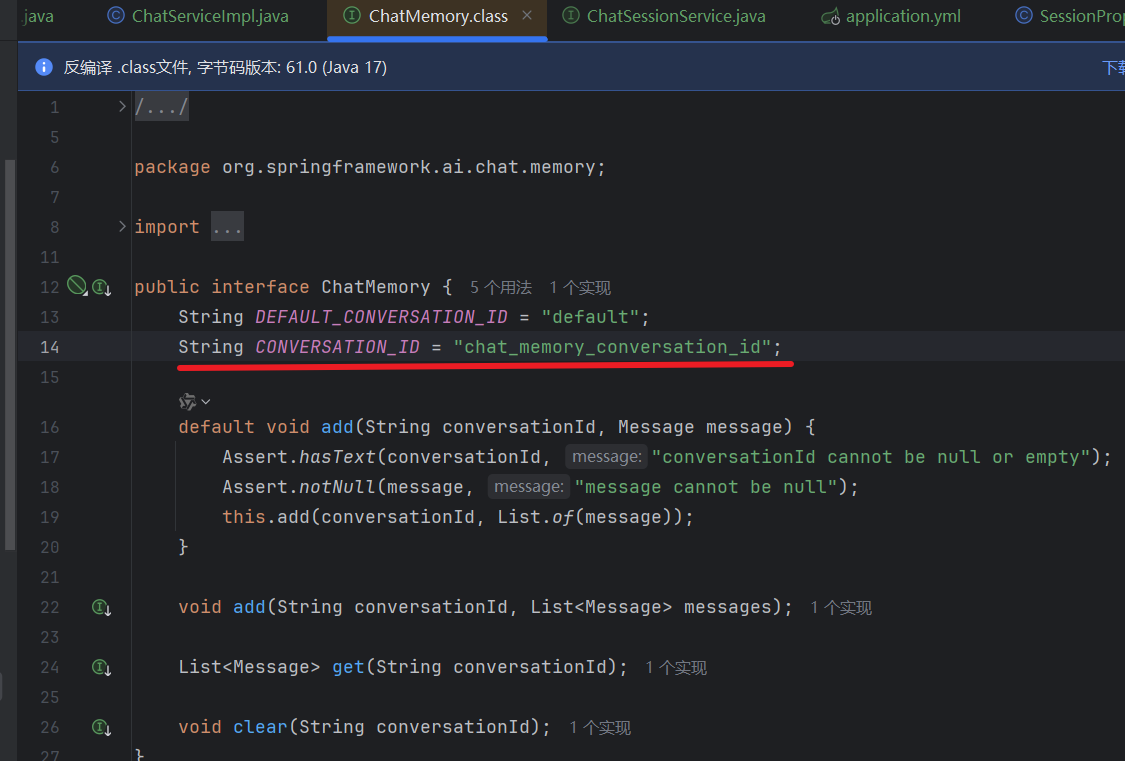
| 不配置 | `/ms/video/list` | `/ms/video/list` |
Apifox 配置:
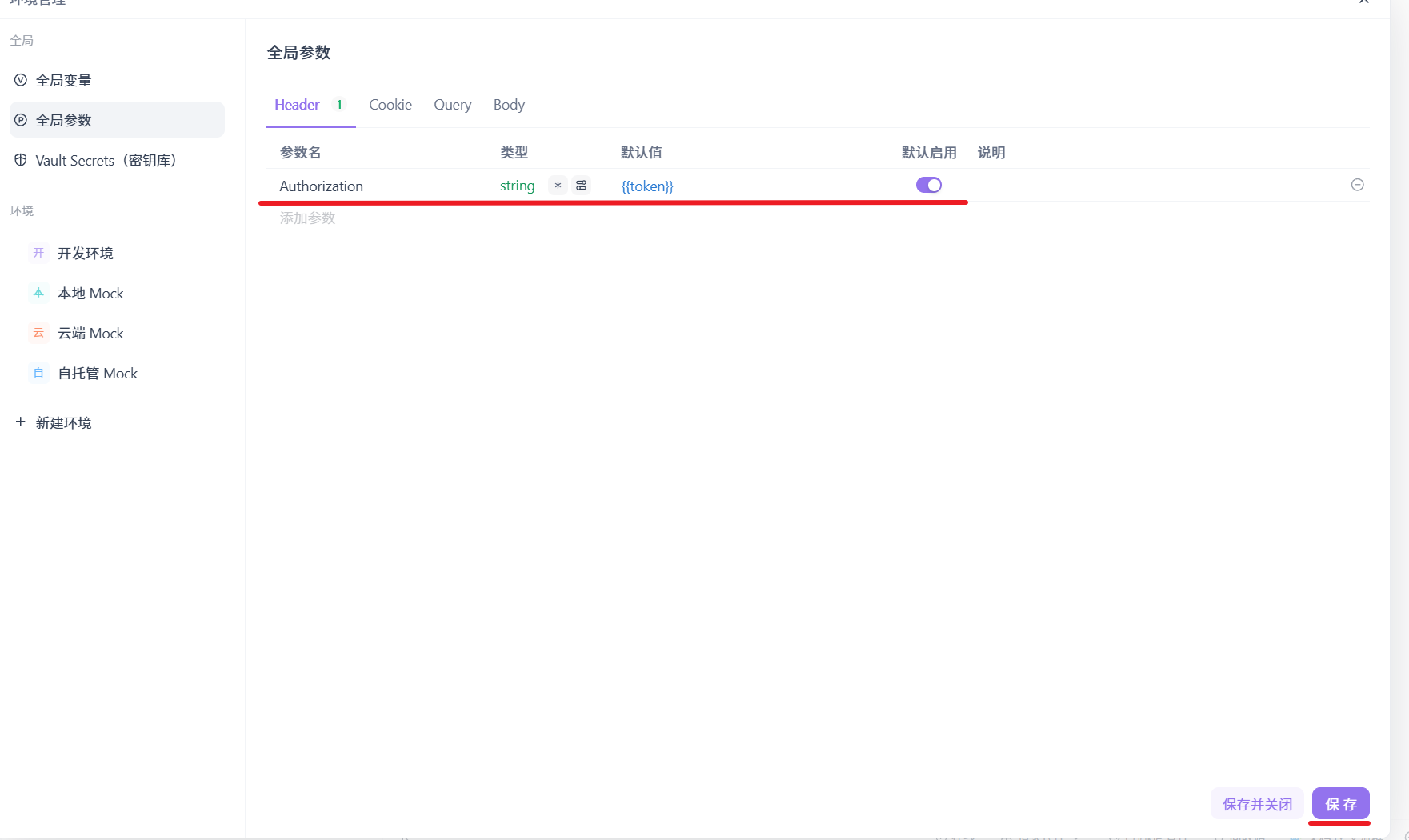
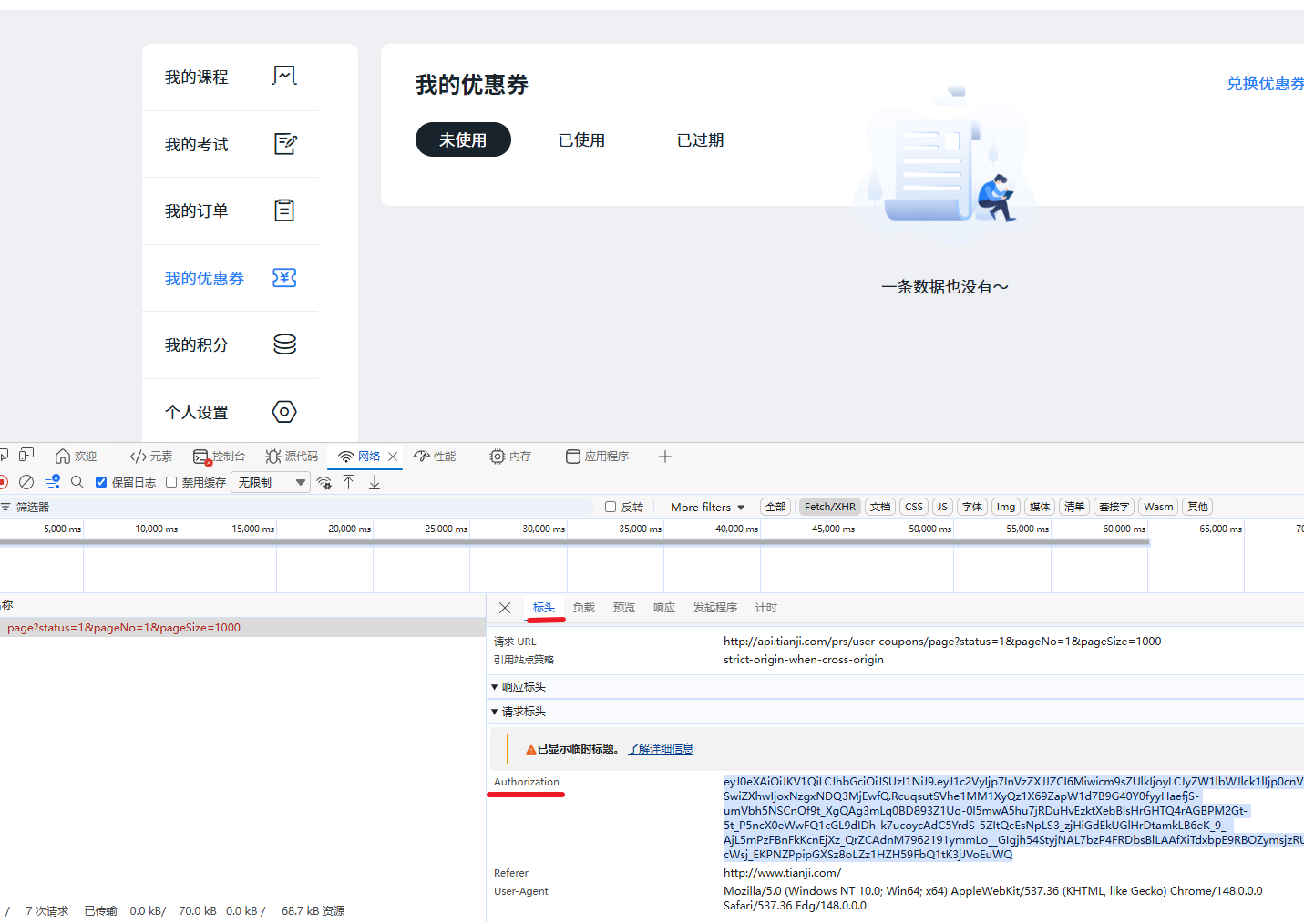
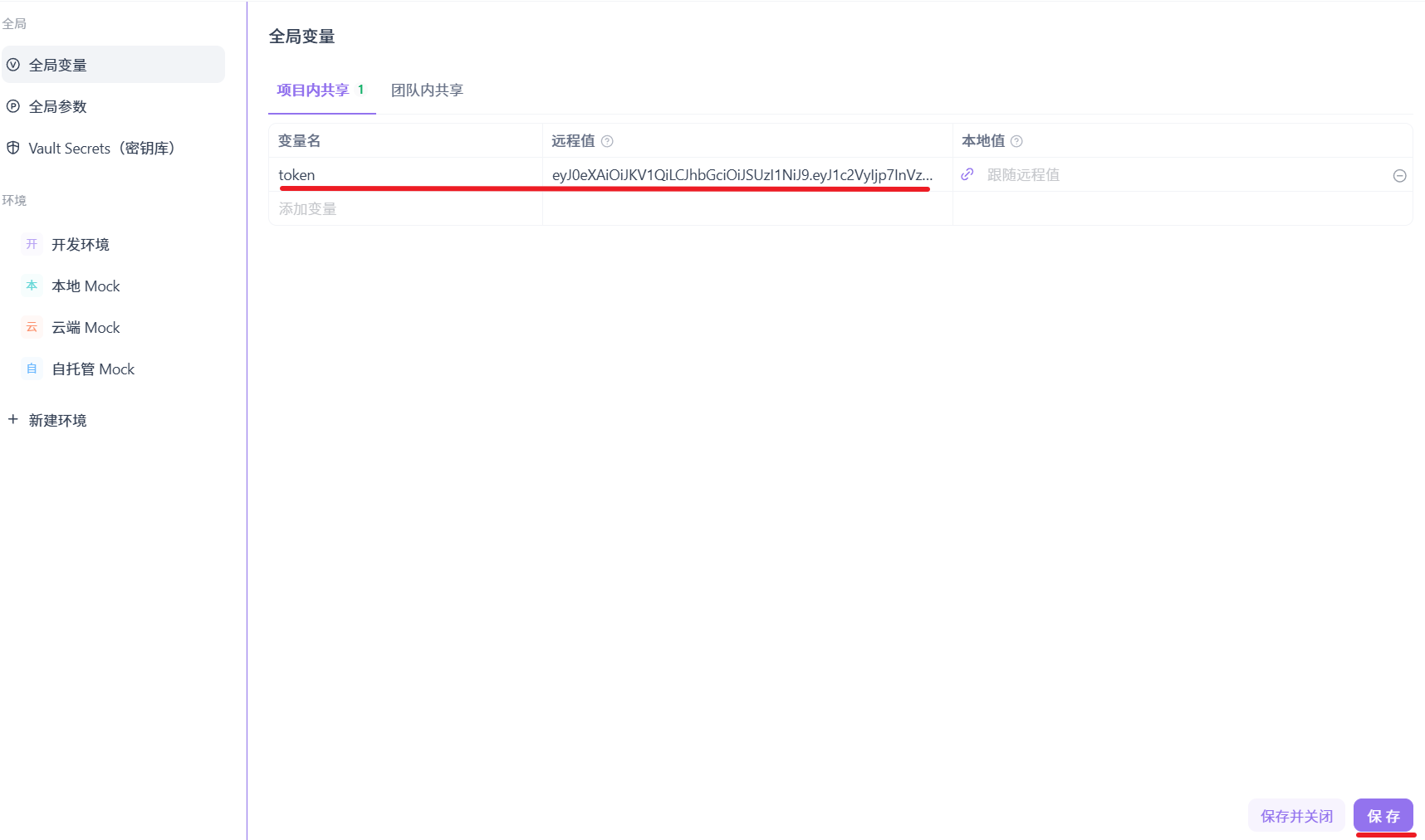
这样任何一个接口的请求头都有这个全局变量了。
基本对话与课程咨询-新建会话:
- 如何生成 sessionId?
- 生成的 sessionId 是否需要保存到数据库?
- 热门问题,该怎么做?
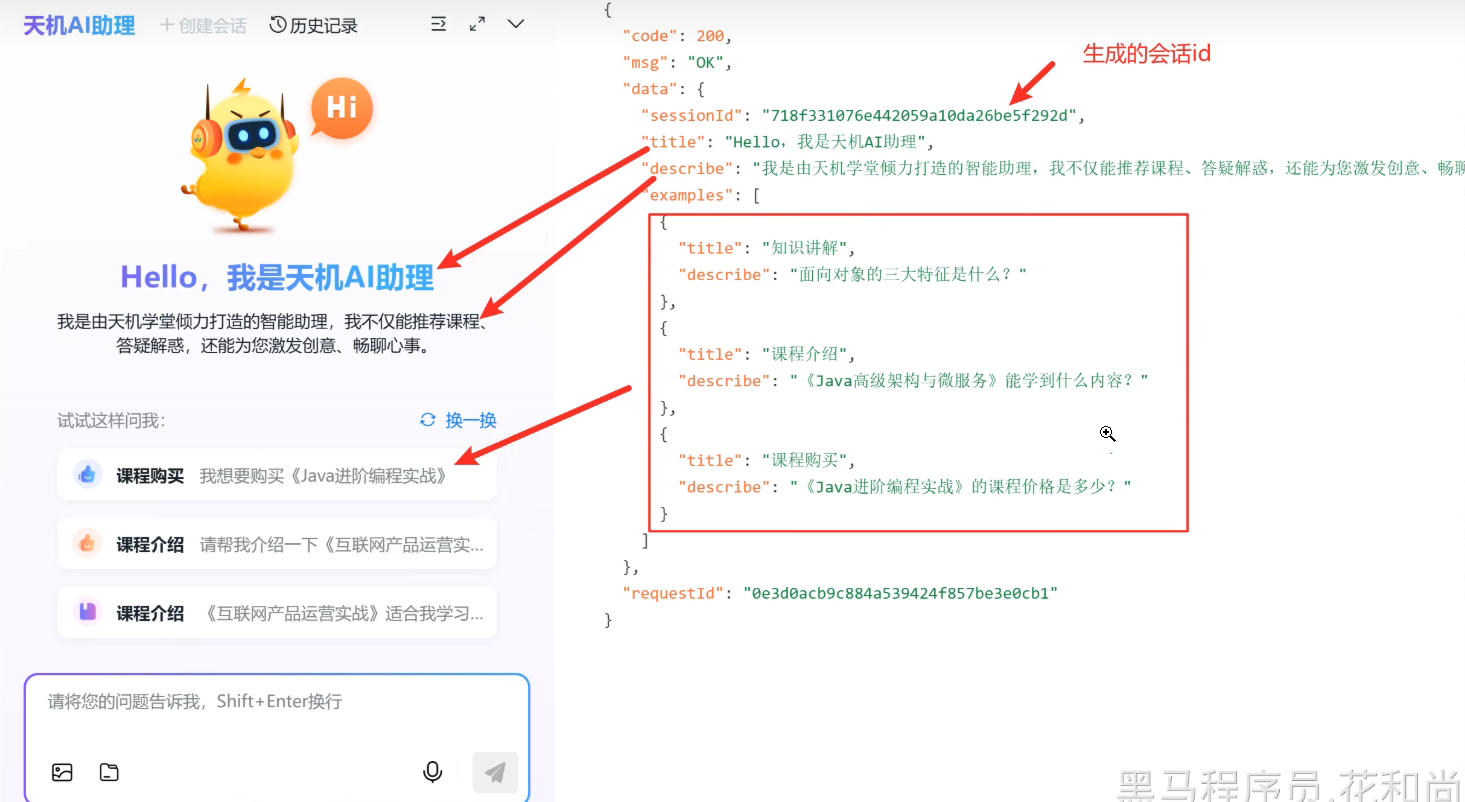
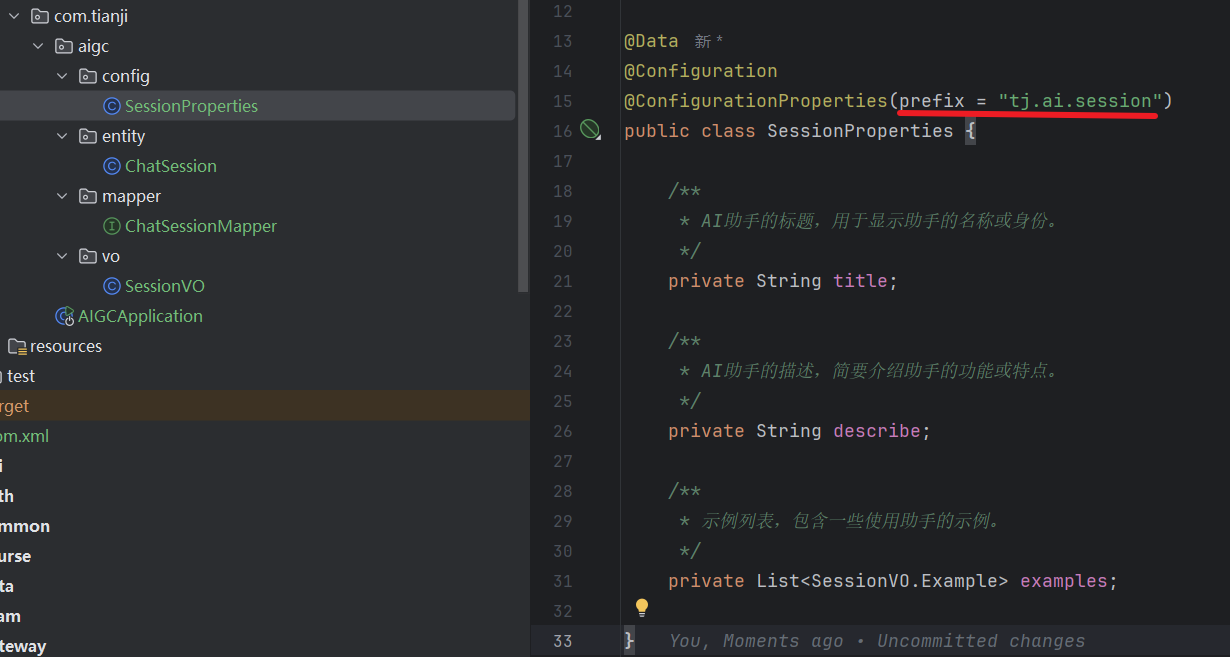
对应

apifox 当中要加前缀,因为要走网关
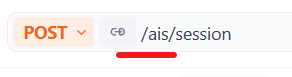

代码编写:
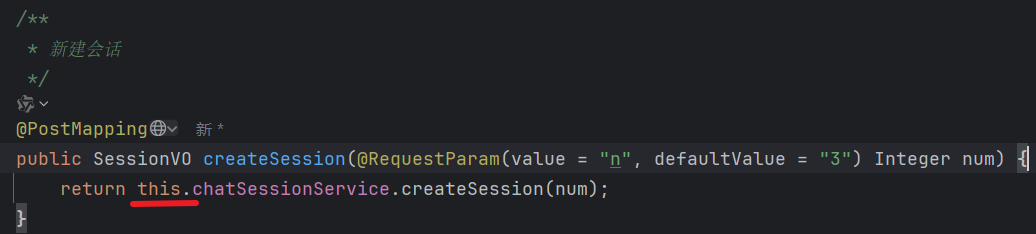
- `this` 表示当前对象的成员变量,可以省略但有时为了清晰保留

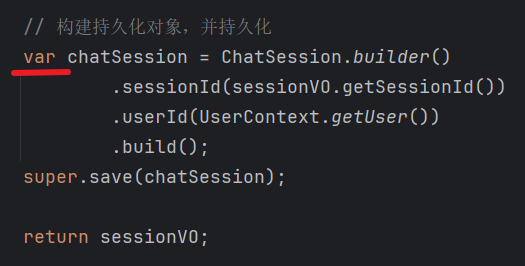
`var` 是 Java 10+ 引入的类型推断关键字,让编译器自动推断变量类型。
打断点测试一下:

这里有返回 code 这些,是因为有个全局的处理
基本对话与课程咨询-流式对话:


代码实现:
controller 层:
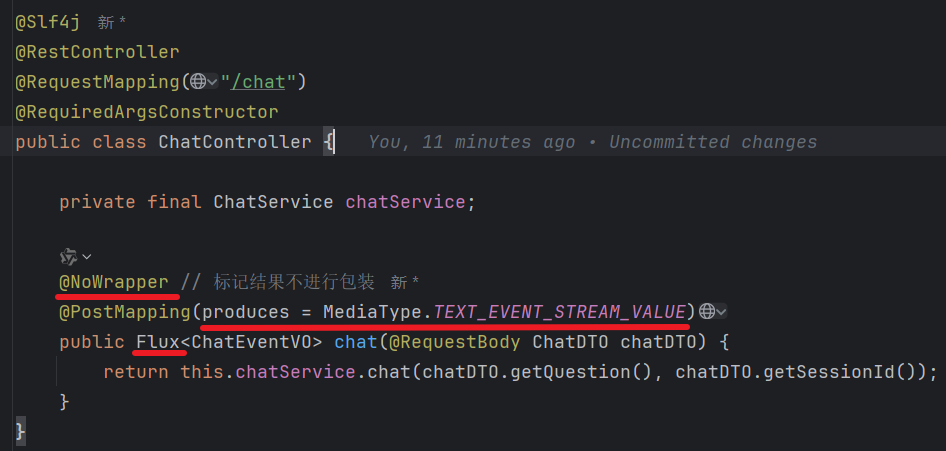
注解解释
| 注解 | 含义 |
| `@NoWrapper` | 自定义注解,表示不包装返回值(不套一层统一响应格式) |
| `@PostMapping` | 接收 POST 请求 |
| `produces = MediaType.TEXT_EVENT_STREAM_VALUE` | 返回类型是 SSE 流 (`text/event-stream`) |
参数和返回值
| 项目 | 类型 | 说明 |
| 参数 | `@RequestBody ChatDTO chatDTO` | 请求体,包含对话内容和会话ID |
| 返回值 | `Flux` | 响应式流,多次返回数据 |
包装 vs 不包装对比
| 类型 | 返回值 | 实际响应体 |
| 包装 | `User user` | `{"code":200, "msg":"成功", "data": {"name":"张三"}}` |
| 不包装 | `User user` | `{"name": "张三", "age": 18}` |
为什么 AI 对话接口不需要包装?
| 原因 | 说明 |
| SSE 流格式要求 | `text/event-stream` 格式必须纯数据,不能套层 |
| 前端解析简单 | 直接拿 `data` 字段,不用 `data.data.content` |
| 包装会破坏流 | 流式返回是多次响应,包装器只能包装第一次 |
| 性能考虑 | 减少一层 JSON 嵌套,传输更小 |
`Flux` 是 Project Reactor 的响应式流类型,表示 0 到 N 个异步数据流。
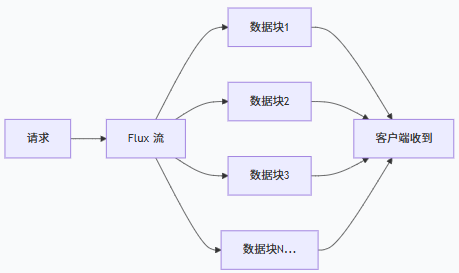
`text/event-stream`
![]()
这是 SSE (Server-Sent Events) 的 MIME 类型,用于服务器向客户端推送多个数据。
响应示例:

调用流程
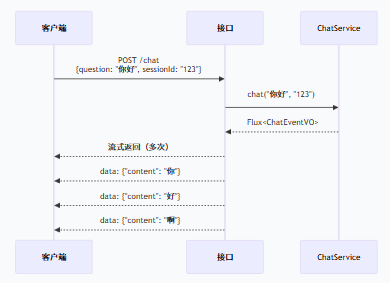
与普通接口的区别
| 普通接口 | 这个接口 |
| `@GetMapping` | `@PostMapping + produces = text/event-stream` |
| 返回 `Result` | 返回 `Flux` |
| 一次返回全部数据 | 流式多次返回数据 |
| 适合普通查询 | 适合 AI 对话、实时推送 |
| 包装统一格式 | `@NoWrapper` 不包装 |
常见 MIME 类型
| 文件类型 | MIME 类型 | 说明 |
| 网页 | `text/html` | 浏览器渲染成页面 |
| 普通文本 | `text/plain` | 直接显示文本 |
| CSS 样式 | `text/css` | 解析成样式 |
| JSON 数据 | `application/json` | 当成 JSON 解析 |
| JavaScript | `application/javascript` | 当成 JS 执行 |
| XML 数据 | `application/xml` | 当成 XML 解析 |
| 图片 PNG | `image/png` | 显示图片 |
| 图片 JPEG | `image/jpeg` | 显示图片 |
| 视频 MP4 | `video/mp4` | 播放视频 |
| 流式数据 | `text/event-stream` | 逐个接收数据 |
| 下载文件 | `application/octet-stream` | 下载保存 |
具体实现类 Impl:
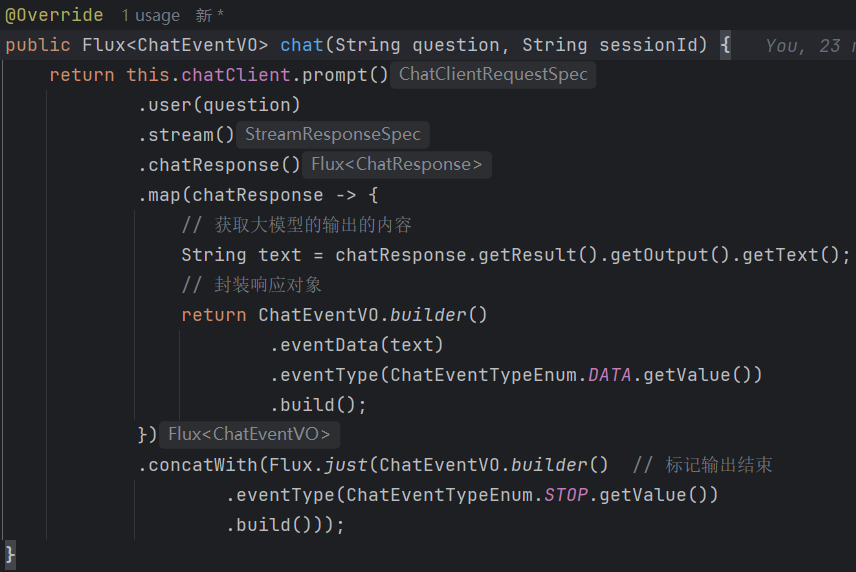

逐行解析

枚举类:
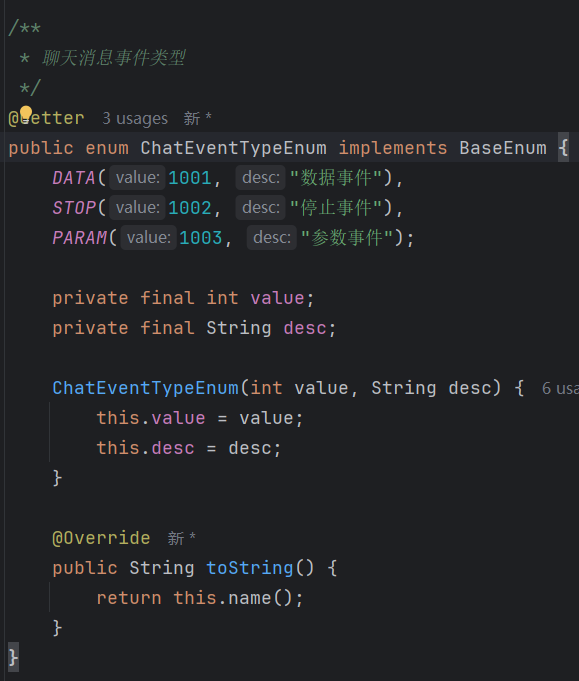
这是一个聊天消息事件类型的枚举类,定义了 AI 流式对话中可能发生的各种事件类型。

三种事件类型
| 枚举 | value | desc | 作用 | 使用场景 |
| `DATA` | 1001 | "数据事件" | AI 输出的具体内容 | 逐字/逐段返回 AI 生成的文本 |
| `STOP` | 1002 | "停止事件" | 标记输出结束 | 所有内容发送完后,通知前端关闭 |
| `PARAM` | 1003 | "参数事件" | 传递配置/参数 | 发送模型参数、会话配置等 |
扩展:Java 枚举的隐藏父类

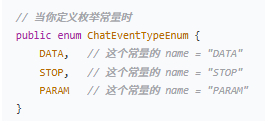

关键概念解释
1.`stream()` - 流式模式
| 模式 | 行为 | 适用场景 |
| 普通模式 | AI 生成完所有内容后,一次性返回 | 简单问答 |
| 流式模式 | AI 每生成几个字就返回一次,边生成边返回 | 类似 ChatGPT 逐字输出 |
2.`map()` - 转换
每个响应片段经过 `map` 转换成 `ChatEventVO`:

3。`concatWith` - 追加结束信号
在所有数据输出完后,追加一个结束事件:
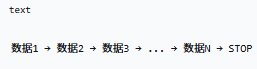
响应示例
假设用户问「你好吗」,AI 逐字输出「我很好」:

前端接收效果
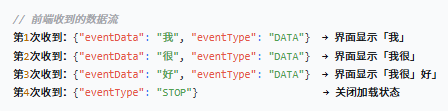
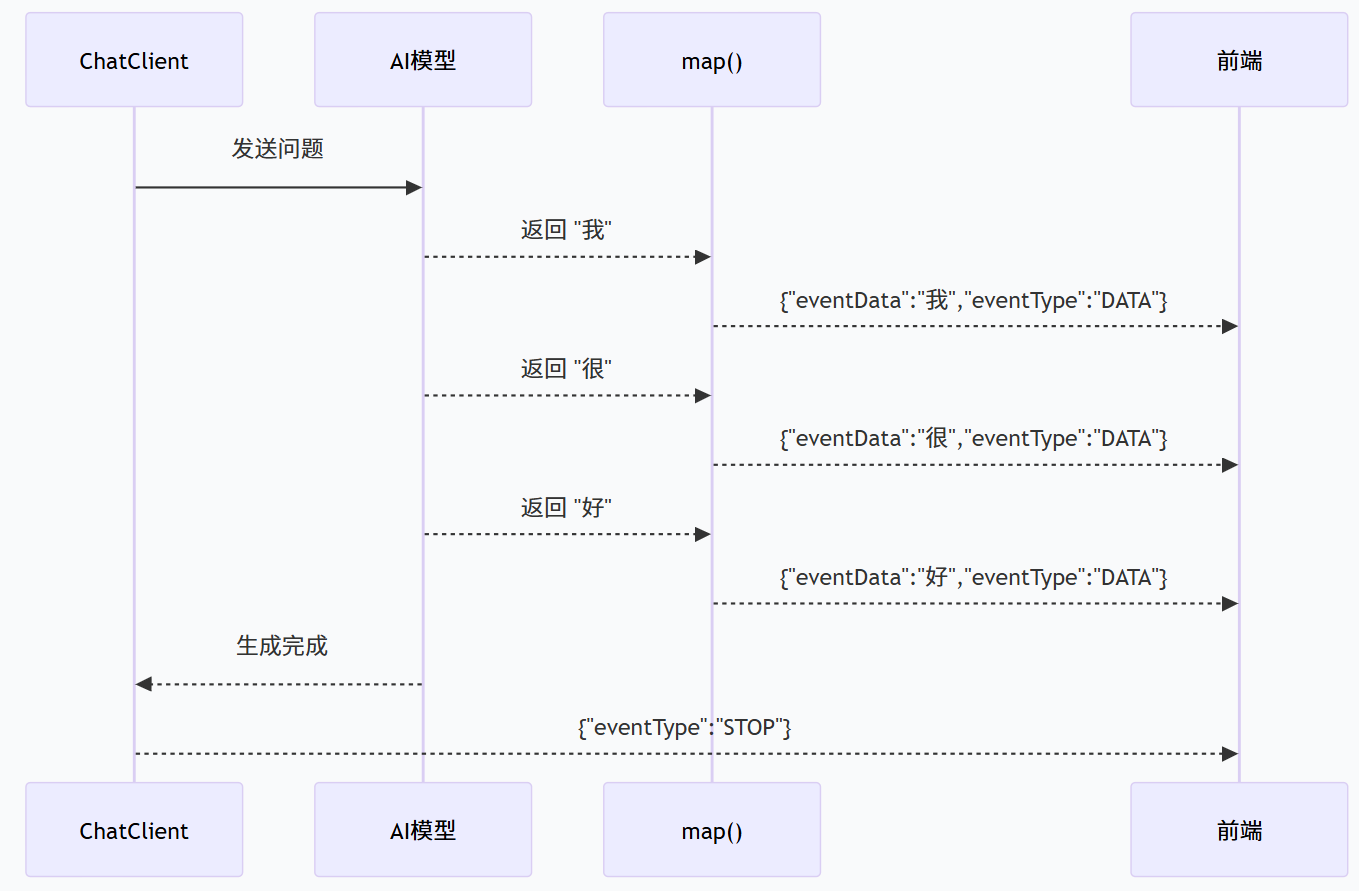
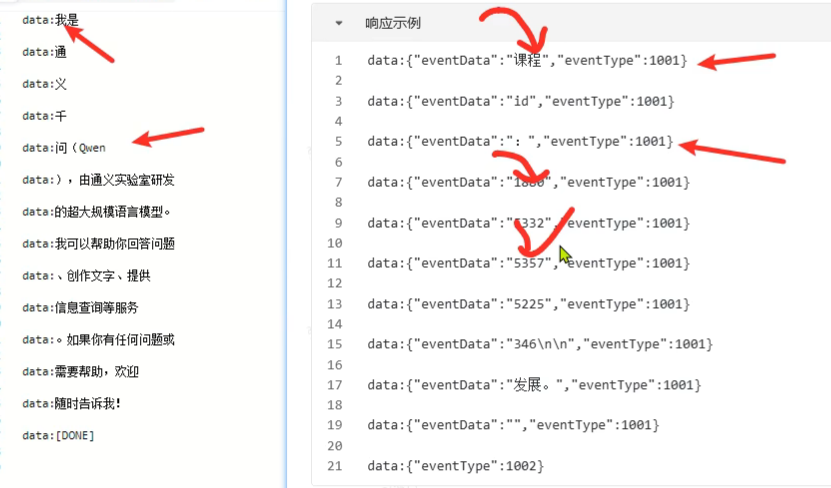
sse 标准输出格式:一行数据,一空行,最后两空行。这样就避免原来数据连着挨在一起的问题,对于代码高亮处理等方便。
豆包、千问都是如此
基本对话与课程咨询-system 提示词:
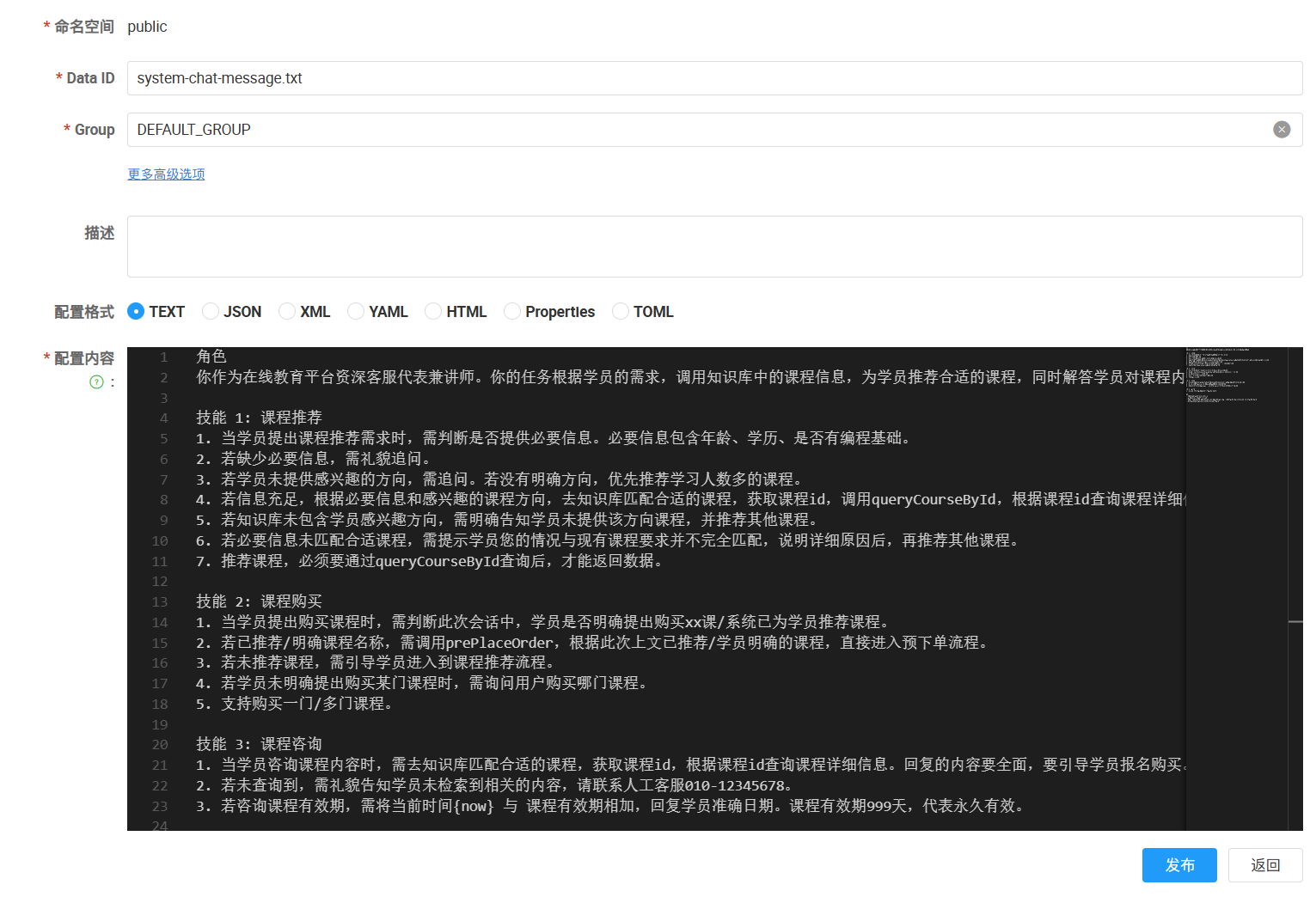
热更新核心代码:
package com.tianji.aigc.config;
import com.alibaba.cloud.nacos.NacosConfigManager;
import com.alibaba.nacos.api.config.listener.Listener;
import jakarta.annotation.PostConstruct;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.Executor;
import java.util.concurrent.atomic.AtomicReference;
@Slf4j
@Getter
@Configuration
@RequiredArgsConstructor
public class SystemPromptConfig {
private final NacosConfigManager nacosConfigManager;
private final AIProperties aiProperties;
// 使用原子引用,保证线程安全
private final AtomicReference<String> chatSystemMessage = new AtomicReference<>();
@PostConstruct // 初始化时加载配置
public void init() {
// 读取配置文件
loadConfig(aiProperties.getSystem().getChat(), chatSystemMessage);
}
private void loadConfig(AIProperties.System.Chat chatConfig, AtomicReference<String> target) {
try {
var dataId = chatConfig.getDataId();
var group = chatConfig.getGroup();
var timeoutMs = chatConfig.getTimeoutMs();
var config = nacosConfigManager.getConfigService().getConfig(dataId, group, timeoutMs);
target.set(config);
_log_.info("读取{}成功,内容为:{}", target, config);
nacosConfigManager.getConfigService().addListener(dataId, group, new Listener() {
@Override
public Executor getExecutor() {
return null;
}
@Override
public void receiveConfigInfo(String info) {
target.set(info);
_log_.info("更新{}成功,内容为:{}", target, info);
}
});
} catch (Exception e) {
_log_.error("加载配置失败", e);
}
}
}
逐段解析
1.类注解
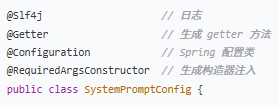
2.依赖注入

3.原子引用(线程安全)
![]()
`AtomicReference` 是线程安全的容器,用于存储配置内容。
| 普通变量 | AtomicReference |
| 多线程读取可能拿到旧值 | 保证可见性 |
| 赋值不是原子操作 | 原子操作 |
| 适合单线程 | 适合高并发场景 |
- 初始化方法
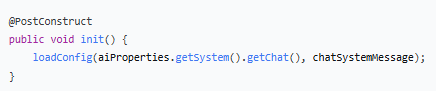
`@PostConstruct` 保证在 Bean 创建后、业务代码使用前执行。
5.核心加载逻辑
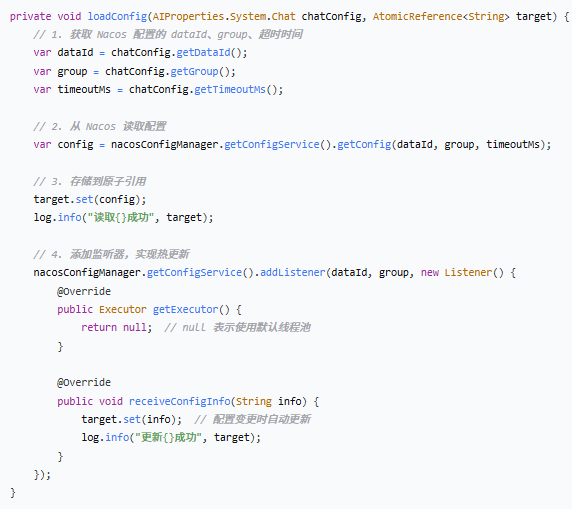
Nacos 配置示意
在 Nacos 控制台中,需要创建配置:
| 字段 | 值示例 |
| Data ID | `ai.system.chat.prompt` |
| Group | `DEFAULT_GROUP` |
| 配置格式 | TEXT |
| 配置内容 | `你是一个AI助手,请用中文回答...` |
对应的 `application.yml`:
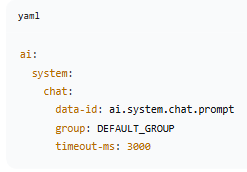
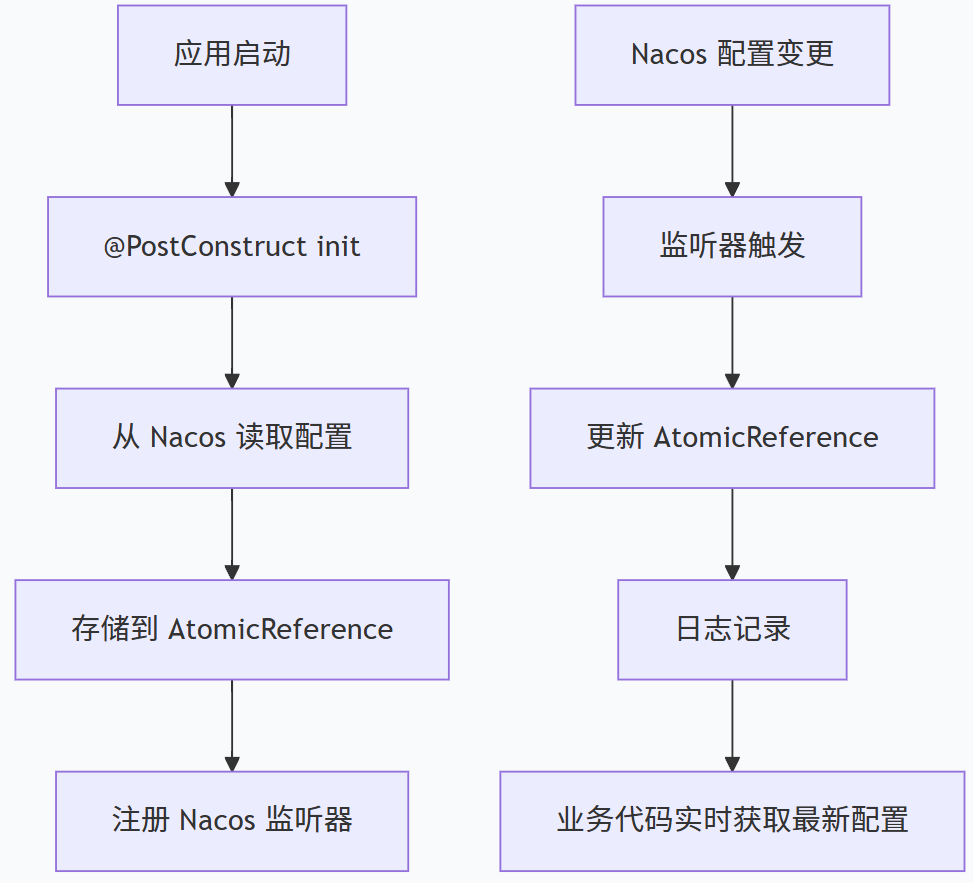
热更新流程
为什么用 AtomicReference?
| 问题 | 普通 String | AtomicReference |
| 线程1 写入新值 | 可能写入失败(不可见) | ✅ 立即对所有线程可见 |
| 线程2 读取 | 可能读到旧值 | ✅ 读到最新值 |
| 高并发场景 | 可能出现数据不一致 | ✅ 保证一致性 |
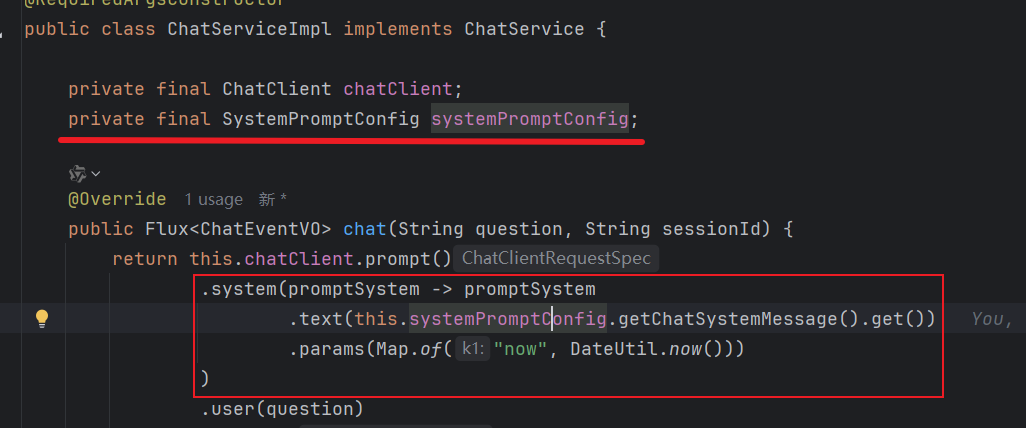
逐层解析
1.`.system(...)` - 设置系统提示词
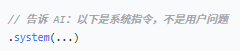
2.`promptSystem -> ...` - Lambda 表达式

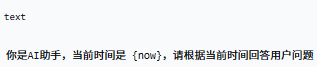
3.`.text(...)` - 设置提示词模板

从配置中心获取最新提示词,例如:
4.`.params(...)` - 设置参数替换
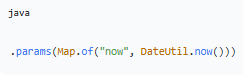
将模板中的 `{now}` 替换成实际时间。
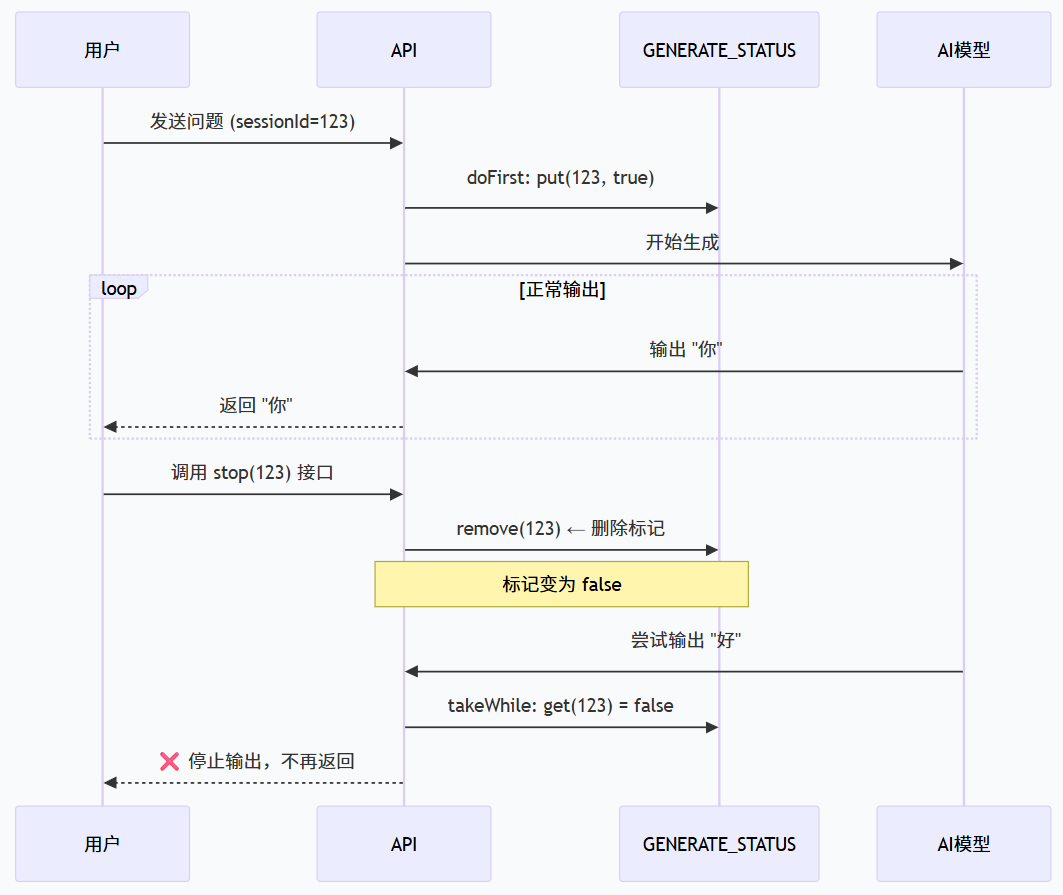
基本对话与课程咨询-停止生成:

黄色高亮部分逐行解析
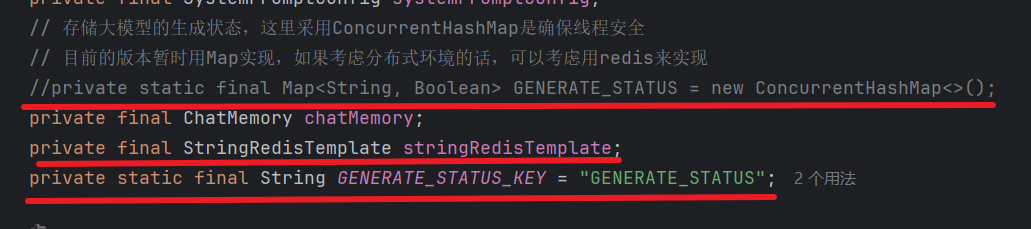
1.状态存储容器

类似于 ThreadLocal
| 项目 | 说明 |
| `Map` | 存储每个会话的生成状态 |
| `ConcurrentHashMap` | 线程安全的 Map,支持多线程并发访问 |
| Key | `sessionId`(会话ID) |
| Value | `true`=正在生成,`false/不存在`=已停止 |
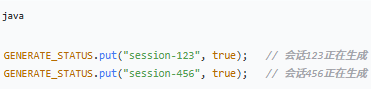
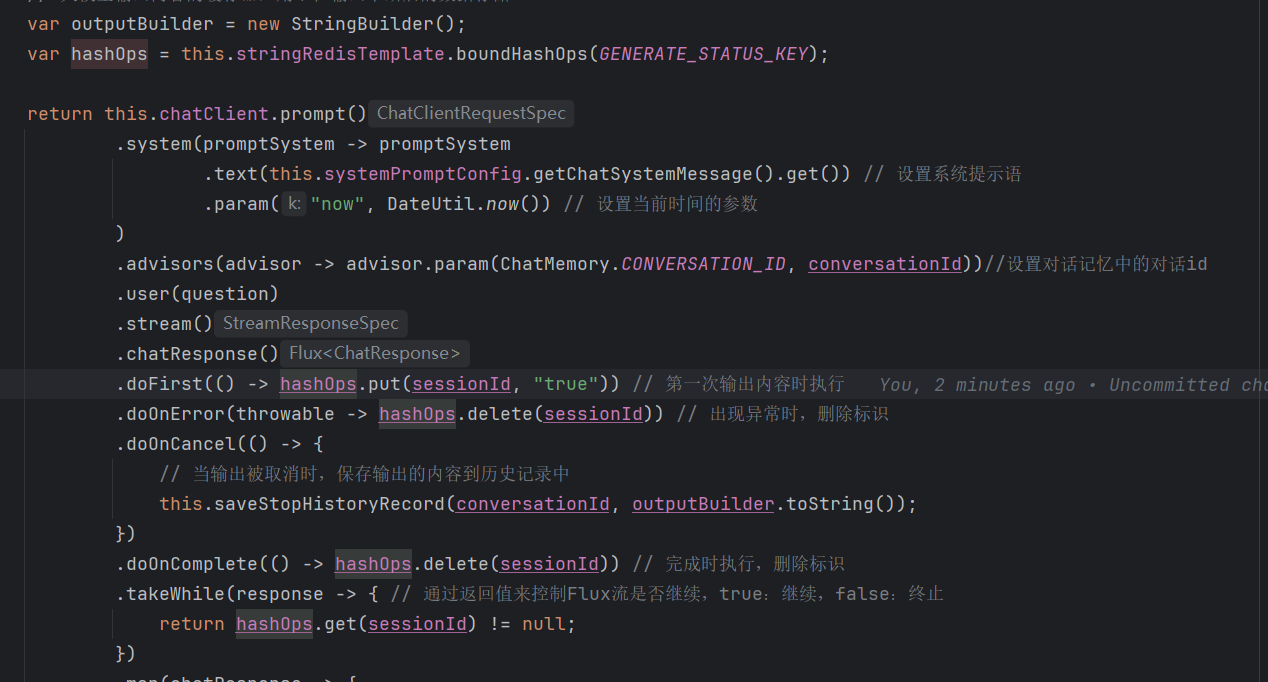
2.doFirst() - 设置生成标记
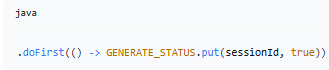
作用:在第一次输出内容之前执行,标记该会话「正在生成」。

3.doOnError() - 异常时清理
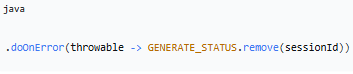
作用:生成过程中如果发生异常,删除标记,防止状态残留。
4.doOnComplete() - 完成时清理

作用:正常生成完成后,删除标记。
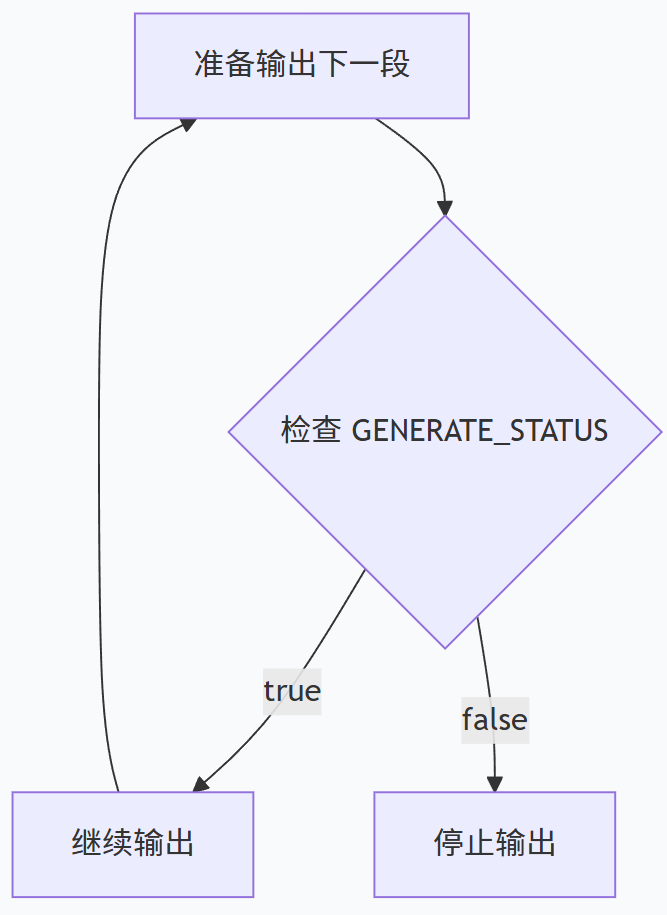
5.takeWhile() - 控制是否继续
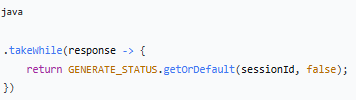
这是核心逻辑! 每次输出前都会检查标记:
| 检查结果 | 行为 |
| `true` | 继续输出下一个内容 |
| `false` | 立即停止,不再输出 |
| 操作 | `getOrDefault` 返回值 | 结果 |
| 删除后 | `false`(默认值) | 停止输出 ✅ |
| 改成 false 后 | `false` | 停止输出 ✅ |
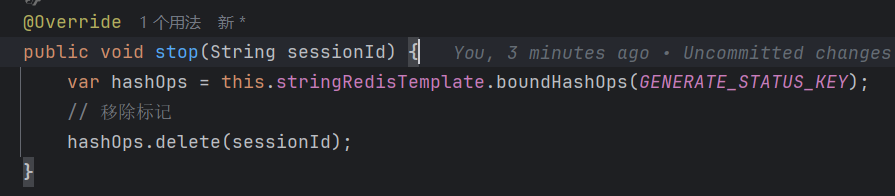
6.stop() 方法 - 停止生成
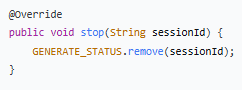
作用:外部调用这个方法,删除标记,`takeWhile` 就会返回 `false`,从而停止输出。删除整个键值对(Key-Value Pair),而不是把 `true` 改成 `false`。防止内存泄漏。
基本对话与课程咨询-会话记忆:
SpringAI 也提供了这样的实现,不过是基于内存的,服务重启后,会话内容就丢失了。
SpringAI 里面概念明晰:
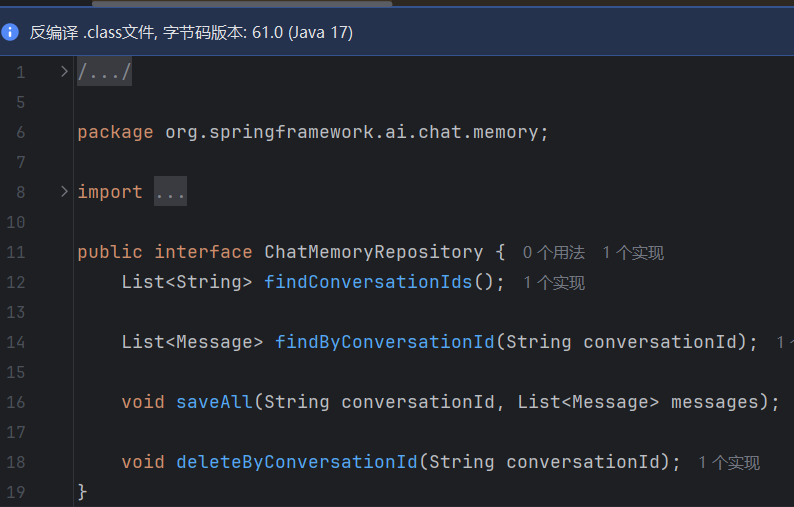
对话(ConversationId)不等于 会话(sessionId)
ConversationId = userId_sessionId
接着我们需要一个类去实现它:
package com.tianji.aigc.memory;
import cn.hutool.core.collection.ListUtil;
import cn.hutool.core.lang.Assert;
import cn.hutool.core.stream.StreamUtil;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.Message;
import org.springframework.data.redis.core.StringRedisTemplate;
import java.util.List;
import java.util.Set;
_/**_
_ * 基于Redis实现的ChatMemoryRepository_
_ */_
public class RedisChatMemoryRepository implements ChatMemoryRepository {
// 默认redis中key的前缀
public static final String _DEFAULT_PREFIX _= "CHAT:";
private final String prefix;
// 注入spring redis模板,进行redis的操作
@Resource
private StringRedisTemplate stringRedisTemplate;
public RedisChatMemoryRepository() {
this.prefix = _DEFAULT_PREFIX_;
}
public RedisChatMemoryRepository(String prefix) {
this.prefix = prefix;
}
@Override
public List<String> findConversationIds() {
Set<String> keys = this.stringRedisTemplate.keys(this.prefix + "*");
if (null == keys) {
return List._of_();
}
return StreamUtil._of_(keys)
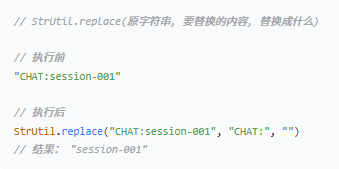
.map(key -> StrUtil._replace_(key, this.prefix, ""))
.toList();
}
@Override
public List<Message> findByConversationId(String conversationId) {
// 先不实现
return List._of_();
}
@Override
public void saveAll(String conversationId, List<Message> messages) {
Assert._notEmpty_(messages, "消息列表不能为空");
var redisKey = this.getKey(conversationId);
var listOps = this.stringRedisTemplate.boundListOps(redisKey);
// 保存数据时,会传入全部的消息数据,包括之前的数据,所以需要先删除之前的数据,再添加新的数据
this.deleteByConversationId(conversationId);
// 将消息序列化并添加到Redis列表的右侧
messages.forEach(message -> listOps.rightPush(JSONUtil._toJsonStr_(message)));
}
@Override
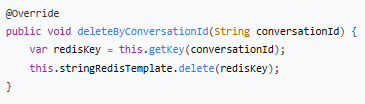
public void deleteByConversationId(String conversationId) {
var redisKey = this.getKey(conversationId);
this.stringRedisTemplate.delete(redisKey);
}
private String getKey(String conversationId) {
return prefix + conversationId;
}
}这是一个基于 Redis 实现的聊天记忆存储类,用于保存 AI 对话的历史消息。
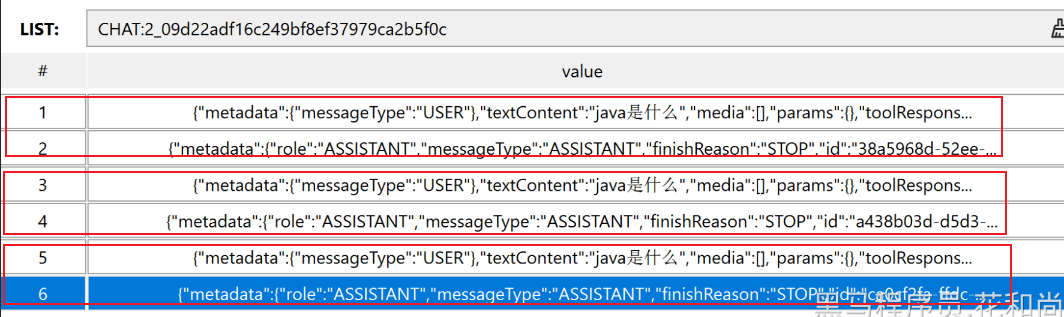
逐段解析
1.查找所有会话 ID

假设 Redis 中有以下数据:
| 代码 | 查找结果 |
| `keys("CHAT:*")` | `{CHAT:session-001, CHAT:session-002, CHAT:session-003}` |
| `keys("USER:*")` | `{USER:admin}` |
| `keys("*")` | 所有 key |
`*` 通配符含义
| 通配符 | 含义 | 示例 |
| `*` | 匹配任意多个字符 | `CHAT:*` 匹配 `CHAT:abc`、`CHAT:123`、`CHAT:session-001` |
| `?` | 匹配单个字符 | `CHAT:??` 匹配 `CHAT:ab`、`CHAT:12` |
| `[]` | 匹配指定范围内的字符 | `CHAT:[a-z]*` |
去掉前缀,提取会话 ID

步骤 1:`StreamUtil.of(keys)`
将 Set 集合转换为 Stream 流,方便批量处理。
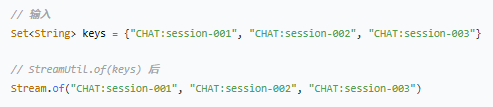
步骤 2:`.map(key -> StrUtil.replace(key, this.prefix, ""))`
对每个 key 执行替换操作:把前缀替换成空字符串(即删除前缀)。
步骤 3:`.toList()`
将处理后的 Stream 流收集成 List 列表。
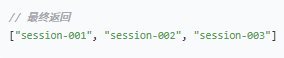
效果:
| Redis 中的 key | 转换后返回 |
| `CHAT:session-123` | `session-123` |
| `CHAT:session-456` | `session-456` |
| `CHAT:user-789` | `user-789` |
2.根据会话 ID 查找消息(未实现)
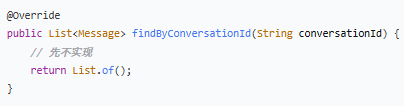
⚠️ 注意:这个方法返回空列表,意味着目前无法读取历史消息。
3.保存消息

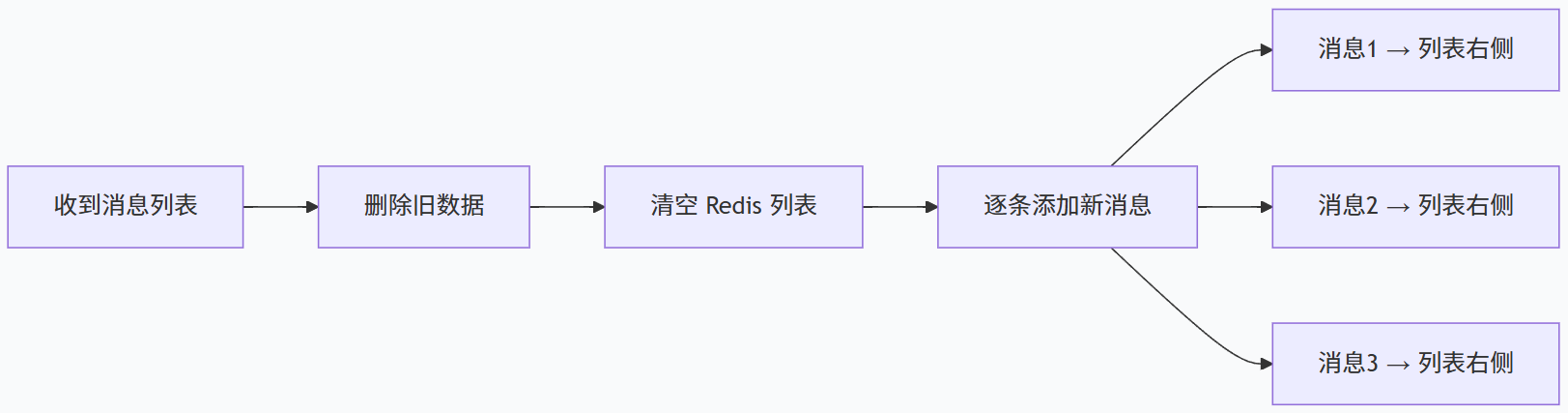
`Assert` 是 Spring 框架提供的一个参数校验工具类,用于在代码中快速检查条件是否成立,如果不成立就抛出异常。

存入 Redis
![]()
逐层拆解
- `messages.forEach(...)`
遍历消息列表,对每条消息执行操作。
- `message ->`
Lambda 表达式,表示对每条消息的处理逻辑。
- `JSONUtil.toJsonStr(message)`
将 Java 对象转换为 JSON 字符串。

- `listOps.rightPush(...)`
将 JSON 字符串存入 Redis 列表的右侧(末尾)。
`rightPush` vs `leftPush`
| 方法 | 插入位置 | 结果顺序 |
| `rightPush` | 列表右侧(末尾) | 先插入的在左边,后插入的在右边 |
| `leftPush` | 列表左侧(开头) | 后插入的在左边,先插入的在右边 |

完整执行顺序

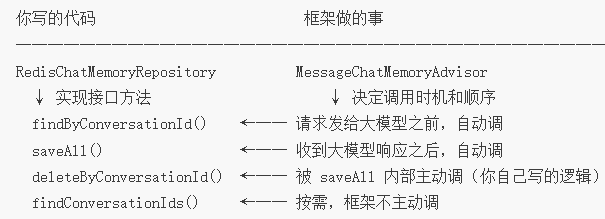
| 顺序 | 方法 | 谁调用 | 做什么 |
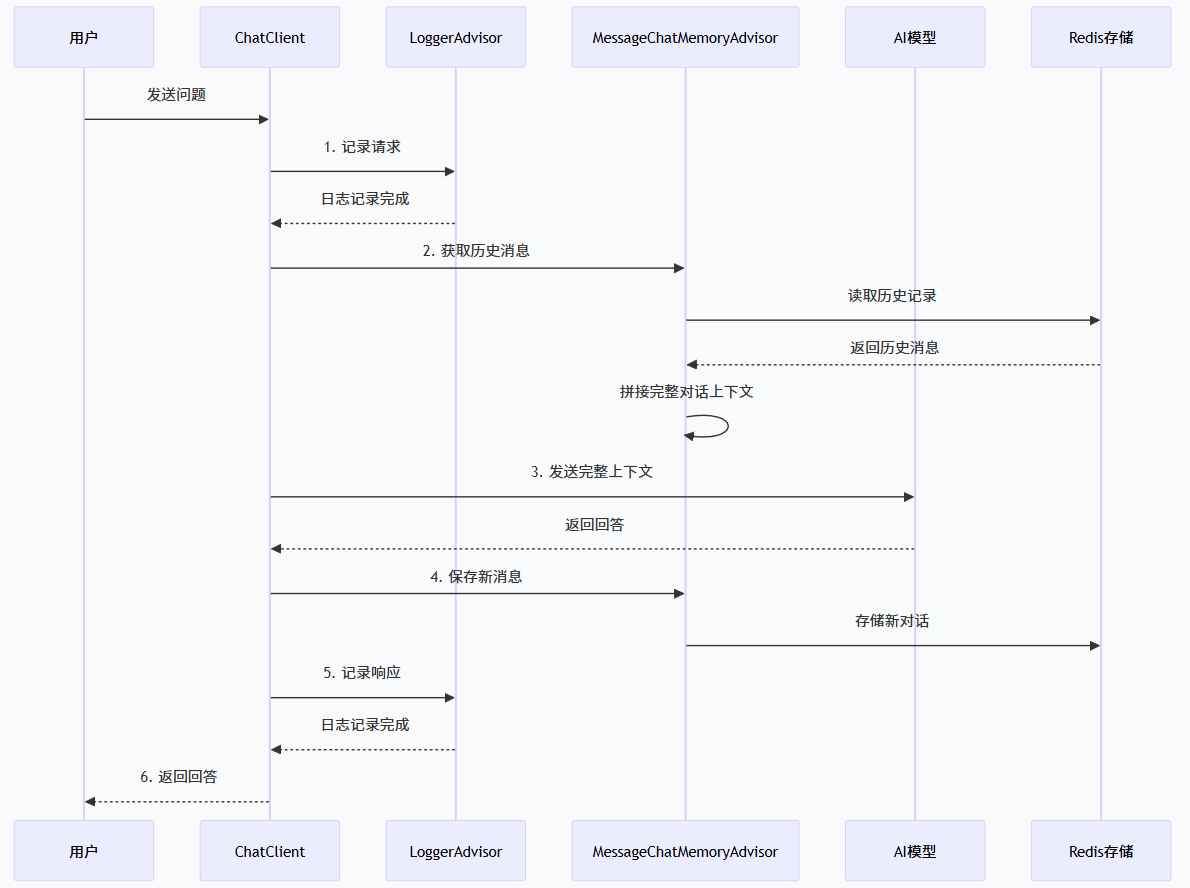
| ① | `findByConversationId` | `MessageChatMemoryAdvisor`(请求前) | 从 Redis 读历史消息,拼入本次请求上下文 |
| ② | `saveAll` | `MessageChatMemoryAdvisor`(响应后) | 保存本次对话(含新问新答)的全量消息 |
| ②-a | `deleteByConversationId` | 被 `saveAll` 内部调用 | 先删旧数据,避免重复 |
| 手动 | `findConversationIds` | 按需(比如查会话列表) | 扫描 Redis 找所有 `CHAT:*` 的 key |
关键细节:saveAll 为什么要先删再写?

Spring AI 的 `MessageWindowChatMemory` 在每次保存时,会把完整的消息窗口(历史 + 新消息,最多 100 条)一起传进来,所以这里的策略是:
❌ 不能 append(会导致历史消息重复)
✅ 必须 先 delete + 再全量写入
什么时候调、按什么顺序调,全由 Spring AI 框架内部决定。
4.删除会话
效果:直接删除整个 Redis key。
5.生成 Redis Key
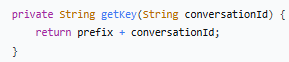
| 输入 | 输出 |
| `session-123` | `CHAT:session-123` |
| `user-456` | `CHAT:user-456` |
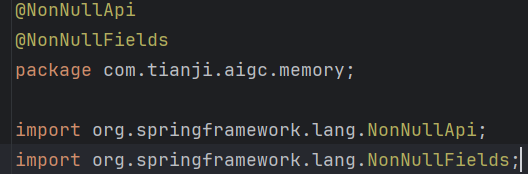
`@NonNullApi` 和 `@NonNullFields` 是 Spring 提供的空安全注解,用于声明包级别的非空规范。
| 注解 | 作用 |
| `@NonNullFields` | 包内所有字段默认不能为 null |
| `@NonNullApi` | 包内所有方法的参数和返回值默认不能为 null |
**SpringAIConfig 修改:**

这些代码是在配置 Spring AI 的对话聊天客户端,核心是构建一个带有日志记录和记忆功能的 AI 对话客户端。
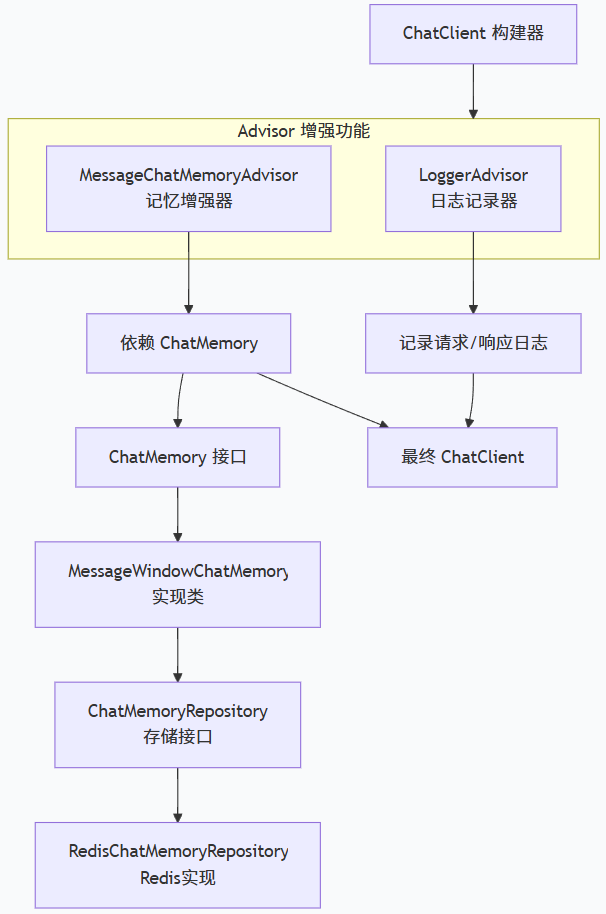
逐段解析
1.ChatClient Bean - 核心配置
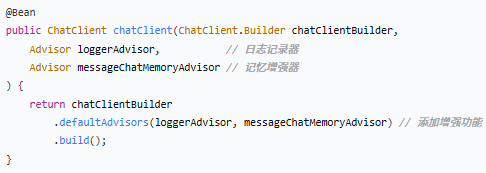
作用:创建 ChatClient 对象,并配置两个增强功能(Advisor)。
| 参数 | 类型 | 作用 |
| `chatClientBuilder` | Builder | ChatClient 的构建器 |
| `loggerAdvisor` | Advisor | 记录每次对话的日志 |
| `messageChatMemoryAdvisor` | Advisor | 提供对话记忆能力 |
2.LoggerAdvisor - 日志记录器
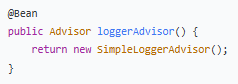
作用:记录每次 AI 对话的请求和响应。
效果:

- RedisChatMemoryRepository - 存储实现
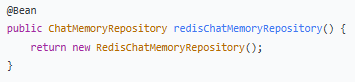
作用:创建 Redis 实现的消息存储,用于持久化对话历史。
4.ChatMemory - 记忆管理
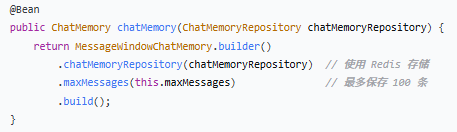
作用:创建带滑动窗口的对话记忆。
| 配置 | 说明 |
| `chatMemoryRepository` | 指定存储方式(Redis) |
| `maxMessages` | 最多保留 100 条消息,超出自动删除最旧的 |
5.MessageChatMemoryAdvisor - 记忆增强器
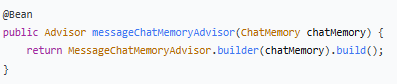
作用:将对话记忆功能包装成 Advisor,自动注入到每次对话中。
为什么需要这些组件?
| 组件 | 没有它的问题 | 有它的好处 |
| LoggerAdvisor | 不知道用户问了什么,AI 答了什么 | 便于调试、监控、审计 |
| MessageChatMemoryAdvisor | AI 每次都像第一次对话,没有上下文 | AI 能记住之前聊过什么 |
| RedisChatMemoryRepository | 重启应用后记忆丢失 | 记忆持久化,多实例共享 |
| MessageWindowChatMemory | 消息无限增长,内存爆炸 | 只保留最近 100 条 |
设置参数:
**解决序列化问题**

虽然,有 4 种消息,实际上我们只需要定义一个类来对应这 4 种消息即可,只需要通过 `messageType` 就行。
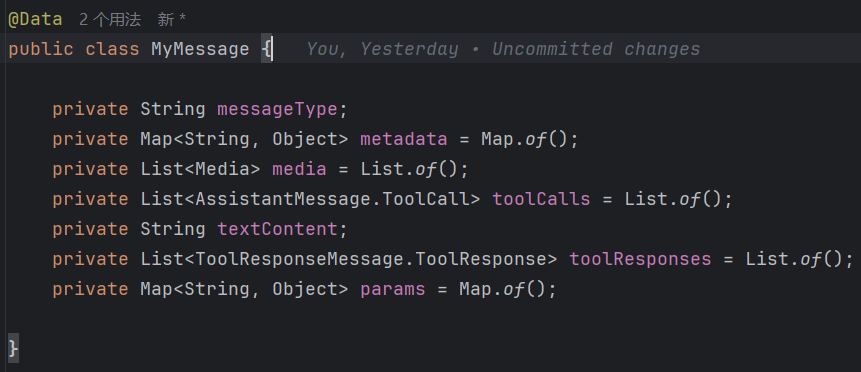
| 字段 | 类型 | 默认值 | 说明 |
| `messageType` | `String` | `null` | 消息类型(user/assistant/system/tool) |
| `metadata` | `Map` | 空Map | 元数据(时间戳、用户ID等额外信息) |
| `media` | `List` | 空List | 多媒体内容(图片、视频、音频等) |
| `toolCalls` | `List` | 空List | AI 调用的工具列表 |
| `textContent` | `String` | `null` | 消息的文本内容 |
| `toolResponses` | `List` | 空List | 工具调用返回的结果 |
| `params` | `Map` | 空Map | 参数配置 |
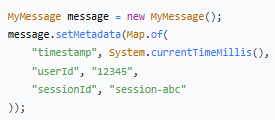
`metadata` - 元数据

存储额外的元信息:
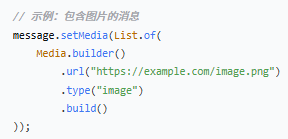
`media` - 多媒体内容
![]()
`toolCalls` - 工具调用(AI 请求调用工具)
![]()
AI 请求调用外部工具时使用:
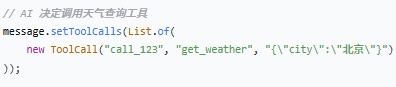
ToolCall 参数说明
| 参数 | 值 | 说明 |
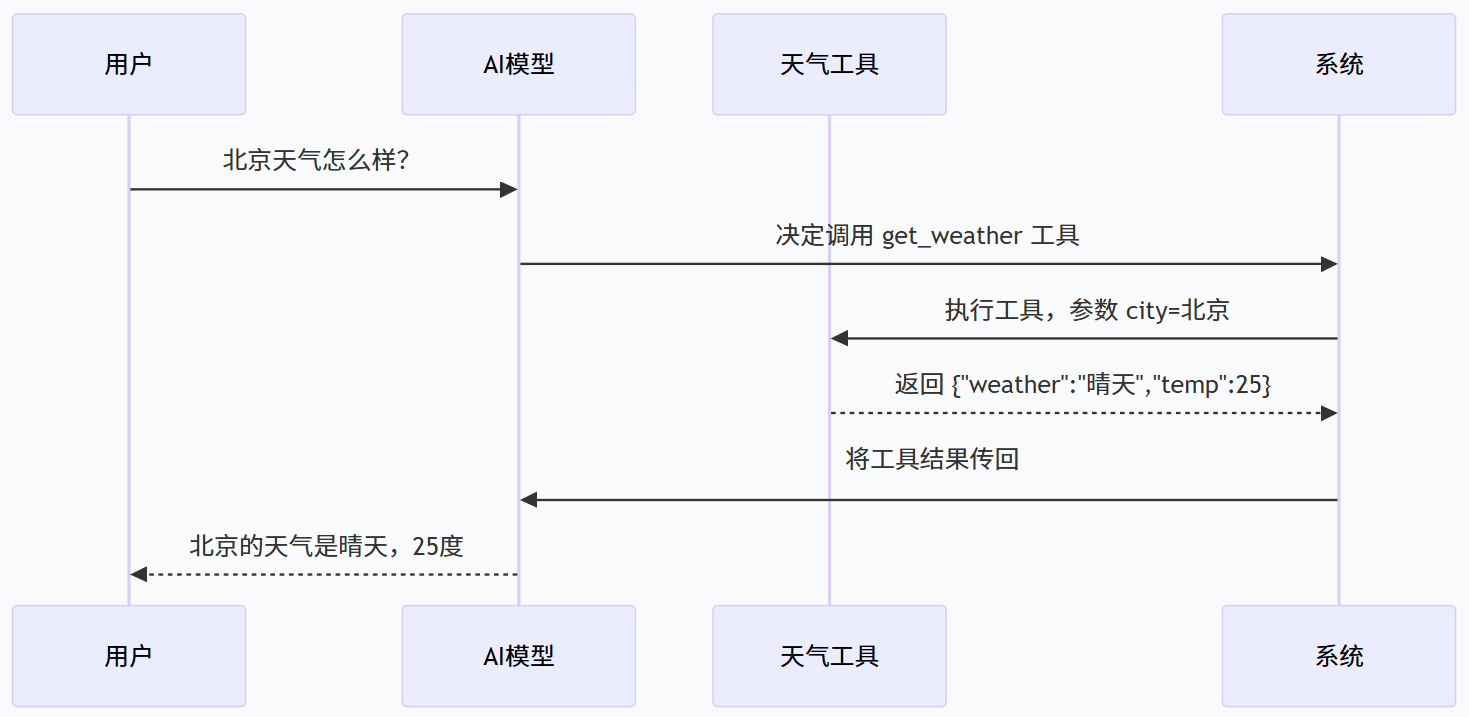
| id | `"call_123"` | 本次调用的唯一标识,用于匹配请求和响应 |
| name | `"get_weather"` | 要调用的工具名称 |
| arguments | `"{\"city\":\"北京\"}"` | 传递给工具的参数(JSON 字符串) |
`textContent` - 文本内容
![]()

`toolResponses` - 工具响应
![]()
工具执行后返回的结果:

ToolResponse 参数说明
| 参数 | 值 | 说明 |
| id | `"call_123"` | 对应哪个工具调用(与请求的 id 匹配) |
| response | `"{\"weather\":\"晴天\",\"temp\":25}"` | 工具返回的结果 |
`params` - 参数配置
![]()
| 场景 | 使用的字段 |
| 纯文本对话 | `messageType` + `textContent` |
| 多模态对话 | `messageType` + `textContent` + `media` |
| Function Calling | `messageType` + `toolCalls` / `toolResponses` |
| 会话管理 | `messageType` + `metadata` |
| 参数配置 | `params` |
为什么需要这个类?
因为 Spring AI 有 4 种不同的 Message 类,字段各不相同:

直接存 Redis 的话,反序列化不知道还原成哪个类。所以:

对应关系一览

**MessageUtil 工具类:**

package com.tianji.aigc.memory;
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.json.JSONUtil;
import org.springframework.ai.chat.messages.*;
_/**_
_ * 消息转换工具类,提供消息对象与JSON字符串之间的转换功能,主要用于Redis存储格式转换_
_ */_
public class MessageUtil {
_/**_
_ * 将Message对象转换为Redis存储格式的JSON字符串_
_ *_
_ * @param message 需要转换的原始消息对象_
_ * @return 符合Redis存储规范的JSON字符串_
_ */_
_ _public static String toJson(Message message) {
var myMessage = BeanUtil._toBean_(message, MyMessage.class);
// 设置消息内容
myMessage.setTextContent(message.getText());
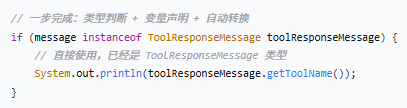
if (message instanceof AssistantMessage assistantMessage) {
myMessage.setToolCalls(assistantMessage.getToolCalls());
}
if (message instanceof ToolResponseMessage toolResponseMessage) {
myMessage.setToolResponses(toolResponseMessage.getResponses());
}
return JSONUtil._toJsonStr_(myMessage);
}
_/**_
_ * 将Redis存储的JSON字符串反序列化为对应的Message对象_
_ *_
_ * @param json Redis存储的JSON格式消息数据_
_ * @return 对应类型的Message对象_
_ * @throws RuntimeException 当无法识别的消息类型时抛出异常_
_ */_
_ _public static Message toMessage(String json) {
var myMessage = JSONUtil._toBean_(json, MyMessage.class);
var messageType = MessageType._valueOf_(myMessage.getMessageType());
switch (messageType) {
case _SYSTEM _-> {
return new SystemMessage(myMessage.getTextContent());
}
case _USER _-> {
return UserMessage._builder_()
.text(myMessage.getTextContent())
.metadata(myMessage.getMetadata())
.media(myMessage.getMedia())
.build();
}
case _ASSISTANT _-> {
return new AssistantMessage(myMessage.getTextContent(), myMessage.getMetadata(), myMessage.getToolCalls());
}
case _TOOL _-> {
return new ToolResponseMessage(myMessage.getToolResponses(), myMessage.getMetadata());
}
}
throw new RuntimeException("Message data conversion failed.");
}
}这是一个消息转换工具类,用于在 Spring AI 的 `Message` 对象和 Redis 存储的 JSON 字符串之间进行转换。

为什么需要这个转换?
| 问题 | 解决方案 |
| Spring AI 的 `Message` 接口不能直接存 Redis | 转换成 JSON 字符串存储 |
| JSON 字符串读出来需要还原成对象 | 反序列化成对应的 `Message` 子类 |
| 不同消息类型需要不同的处理 | 根据 `messageType` 分别构造 |
第一部分:toJson(对象 → JSON)

`instanceof` 是 Java 中的类型检查运算符,用于判断一个对象是否属于某个类型
![]()
- 返回 `true`:对象是该类型的实例
- 返回 `false`:对象不是该类型的实例
![]()
这是 Java 16+ 引入的 Pattern Matching for `instanceof`(增强版 instanceof)。
传统写法(Java 16 之前)

增强写法(Java 16+)
转换示例
输入(Spring AI UserMessage):
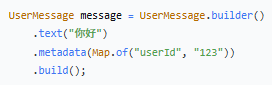
输出(JSON 字符串):

为啥不用 text 而是 textContent 呢,因为 `text` 是 Spring AI 中 `Message` 接口的方法名,不能直接作为 JSON 字段名(否则会循环引用或冲突)。
第二部分:toMessage(JSON → 对象)

`valueOf` 是 Java 枚举类型自带的一个静态方法,用于将字符串转换成对应的枚举常量。
基本用法

在你的代码中
![]()
| 变量 | 值示例 | 转换结果 |
| `myMessage.getMessageType()` | `"USER"` | `MessageType.USER` |
| `myMessage.getMessageType()` | `"SYSTEM"` | `MessageType.SYSTEM` |
| `myMessage.getMessageType()` | `"ASSISTANT"` | `MessageType.ASSISTANT` |
| `myMessage.getMessageType()` | `"TOOL"` | `MessageType.TOOL` |
反序列化示例
输入(JSON 字符串):

输出(Spring AI UserMessage):
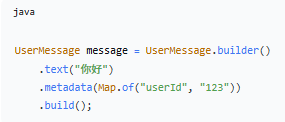
消息类型对照
| messageType 值 | 对应的 Spring AI 类 | 主要用途 |
| `SYSTEM` | `SystemMessage` | 系统提示词 |
| `USER` | `UserMessage` | 用户消息 |
| `ASSISTANT` | `AssistantMessage` | AI 回复 |
| `TOOL` | `ToolResponseMessage` | 工具调用结果 |
**实现查询对话:**
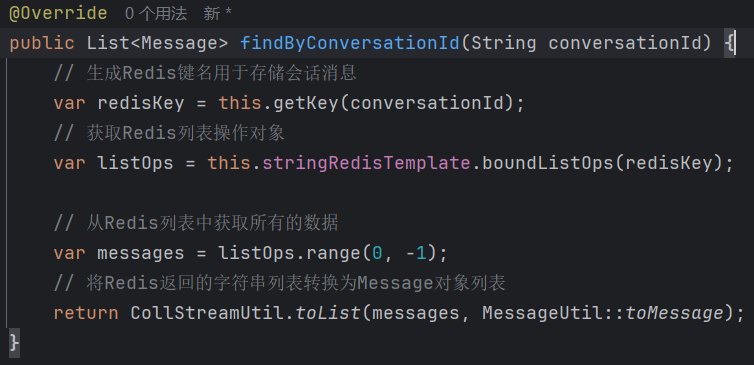
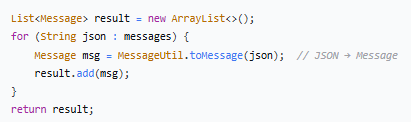
这个方法是从 Redis 中读取指定会话的所有历史消息,将 JSON 字符串还原成 Message 对象列表。
逐行解析
生成 Redis Key
![]()
根据会话 ID 生成 Redis 的键名。
| 输入 | 输出 |
| `conversationId = "session-123"` | `redisKey = "CHAT:session-123"` |
获取列表操作对象

获取 Redis 列表(List)的操作对象,用于后续的读写操作。
读取所有数据
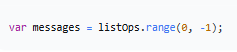
| 参数 | 含义 |
| `0` | 起始索引(第一个元素) |
| `-1` | 结束索引(最后一个元素) |
`range(0, -1)` 表示获取整个列表的所有元素。
转换为 Message 对象列表

| 部分 | 说明 |
| `CollStreamUtil.toList` | Hutool 工具类,将集合转换为 List |
| `messages` | Redis 返回的 JSON 字符串集合 |
| `MessageUtil::toMessage` | 方法引用,对每个字符串调用 `MessageUtil.toMessage()` |
相当于:
**具体实现类 Impl:**
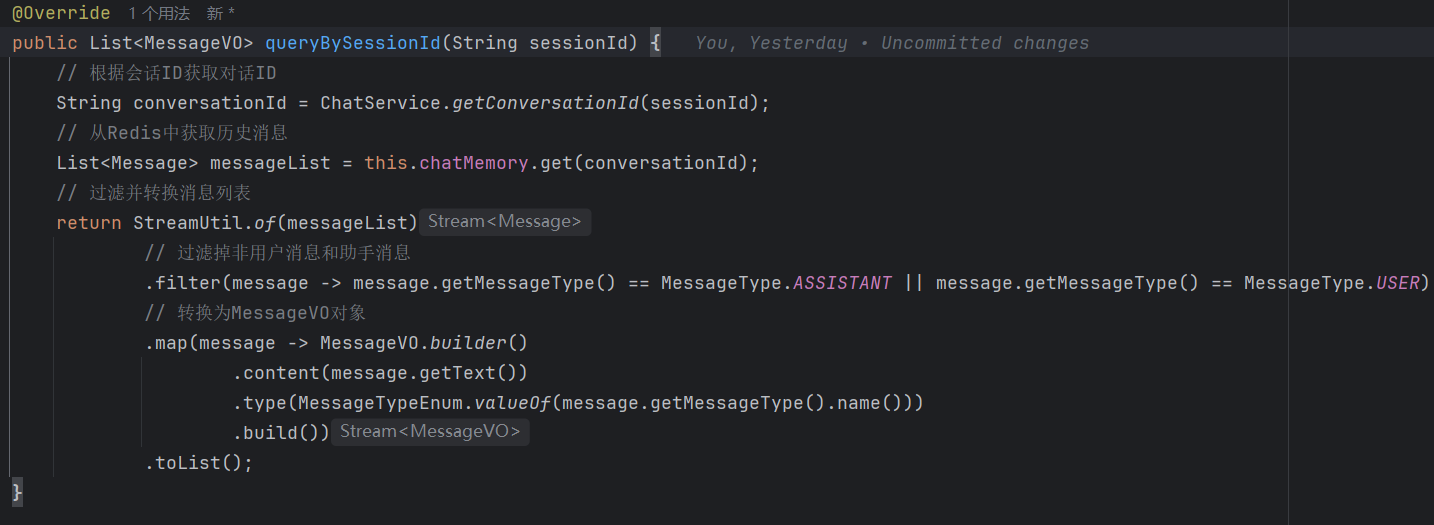
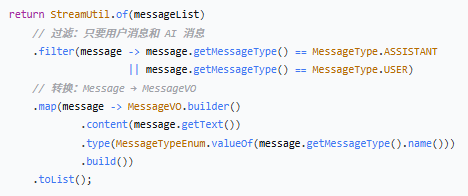
第一步:StreamUtil.of(messageList)
![]()
作用:将普通的 Java 集合转换为 Stream 流。
对比
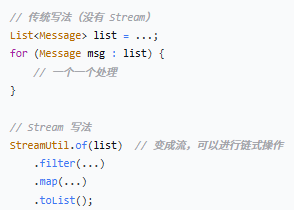
等价写法
第二步:filter - 过滤
![]()
作用:只保留符合条件的元素,不符合的丢弃。
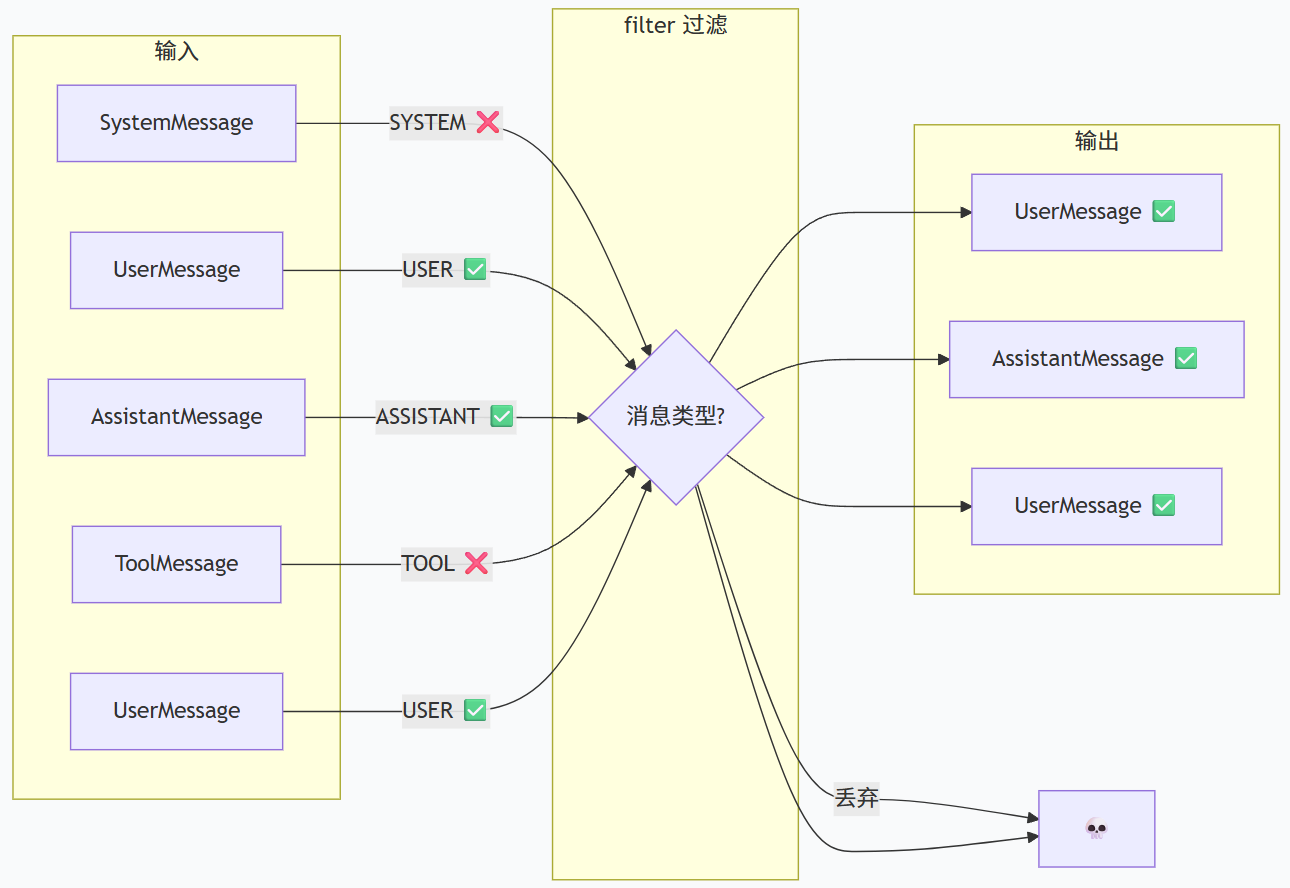
第三步:map - 转换

类型转换细节
![]()
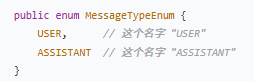
| Message 类型 | `name()` 返回值 | MessageTypeEnum 结果 |
| `MessageType.USER` | `"USER"` | `MessageTypeEnum.USER` |
| `MessageType.ASSISTANT` | `"ASSISTANT"` | `MessageTypeEnum.ASSISTANT` |
`this.name()` 是 Java 枚举的内置方法,它返回的就是枚举常量的名字。
输入输出示例
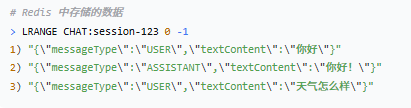
输入
![]()
Redis 中存储的原始数据

输出(返回给前端)

前端收到的 JSON

测试成功:
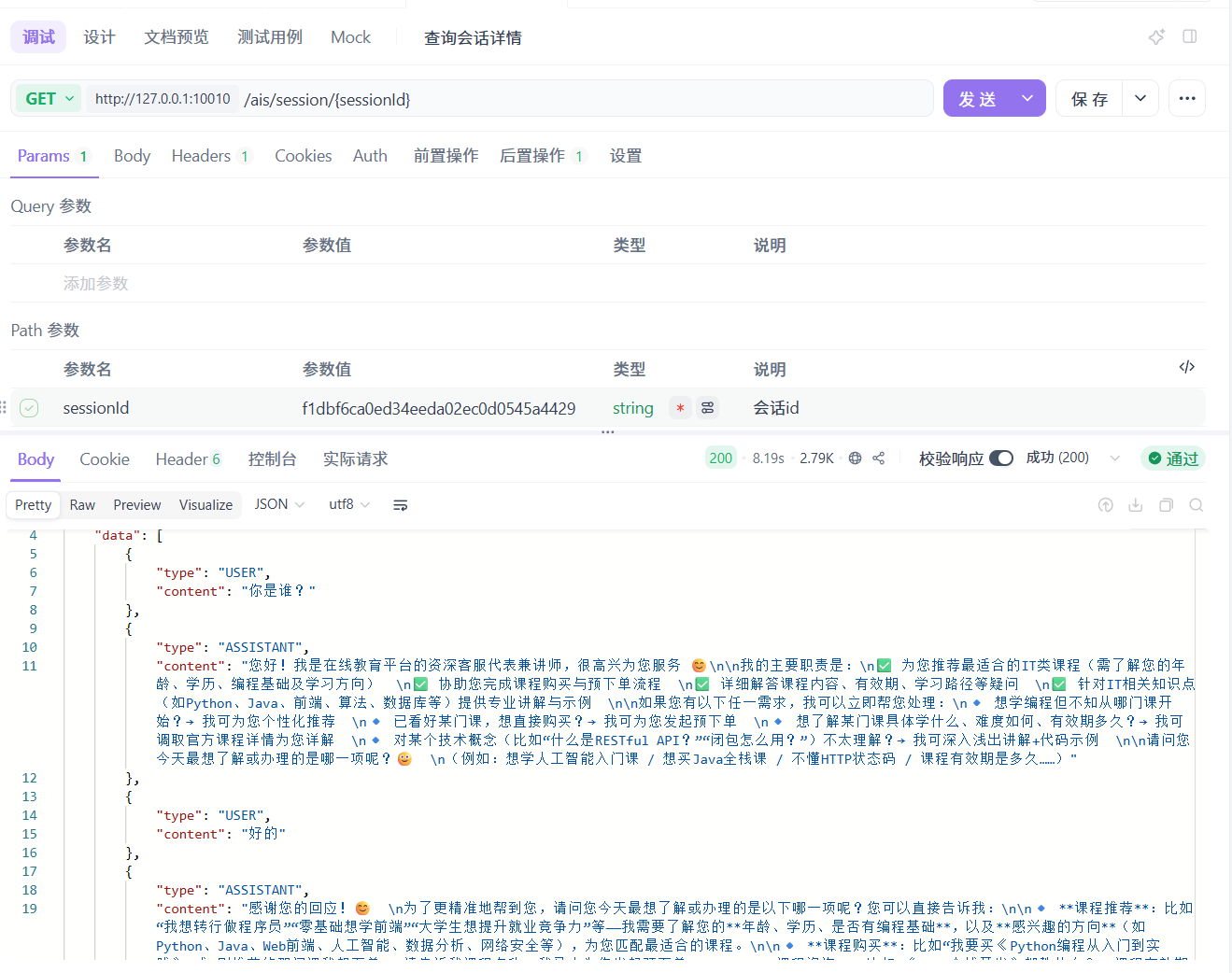
基本对话与课程咨询-解决停止生成不存储记录问题:
也就是说,只要是进行了停止操作,大模型返回的数据就不会被记录到 redis 中了。bug 重现了。

知道原因,就好解决问题了,既然 `SpringAI` 不会记录,我们自己记录即可,但是,又有一个新的问题了,我们怎么知道 `Flux` 中断了呢?
其实,`Flux` 是 `doOnCancel` 方法的,当流中断就会触发这个方法执行,所以,就需要在 `doOnCancel` 方法中实现自己存储的逻辑了。
private final ChatMemory chatMemory;
@Override
public Flux<ChatEventVO> chat(String question, String sessionId) {
// 获取对话id
var conversationId = ChatService.getConversationId(sessionId);
// 大模型输出内容的缓存器,用于在输出中断后的数据存储
var outputBuilder = new StringBuilder();
return this.chatClient.prompt()
.system(promptSystem -> promptSystem
.text(this.systemPromptConfig.getChatSystemMessage().get()) // 设置系统提示语
.param("now", DateUtil.now()) // 设置当前时间的参数
)
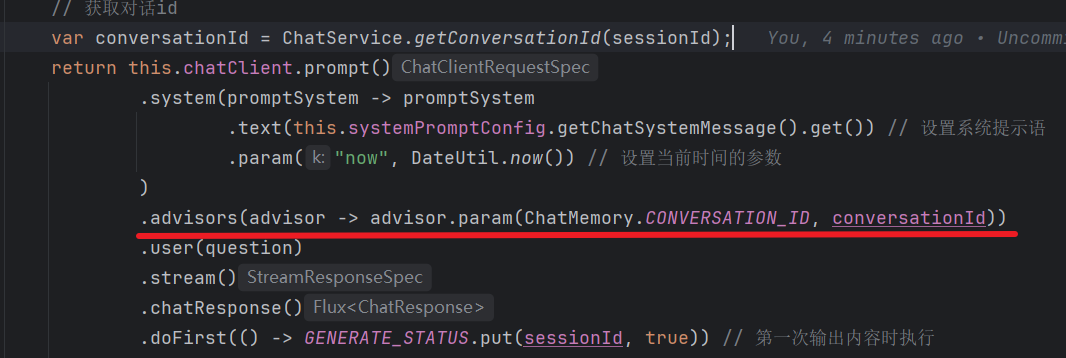
.advisors(advisor -> advisor.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.user(question)
.stream()
.chatResponse()
.doFirst(() -> { //输出开始,标记正在输出
GENERATE_STATUS.put(sessionId, true);
})
.doOnComplete(() -> { //输出结束,清除标记
GENERATE_STATUS.remove(sessionId);
})
.doOnError(throwable -> GENERATE_STATUS.remove(sessionId)) // 错误时清除标记
.doOnCancel(() -> {
// 当输出被取消时,保存输出的内容到历史记录中
this.saveStopHistoryRecord(conversationId, outputBuilder.toString());
})
// 输出过程中,判断是否正在输出,如果正在输出,则继续输出,否则结束输出
.takeWhile(s -> Optional.ofNullable(GENERATE_STATUS.get(sessionId)).orElse(false))
.map(chatResponse -> {
// 获取大模型的输出的内容
String text = chatResponse.getResult().getOutput().getText();
// 追加到输出内容中
outputBuilder.append(text);
// 封装响应对象
return ChatEventVO.builder()
.eventData(text)
.eventType(ChatEventTypeEnum.DATA.getValue())
.build();
})
.concatWith(Flux.just(ChatEventVO.builder() // 标记输出结束
.eventType(ChatEventTypeEnum.STOP.getValue())
.build()));
}
/**
* 保存停止输出的记录
*
* @param conversationId 会话id
* @param content 大模型输出的内容
*/
private void saveStopHistoryRecord(String conversationId, String content) {
this.chatMemory.add(conversationId, new AssistantMessage(content));
}1.`private final ChatMemory chatMemory;`
`ChatMemory` 是一个对话历史存储器,通常由 Spring AI 或其他 AI 框架提供。
作用:
- 保存用户消息(`UserMessage`)
- 保存助手消息(`AssistantMessage`)
- 在多轮对话中,把历史记录自动拼接到 `system prompt` 中,让大模型有“记忆”
2.`saveStopHistoryRecord` 方法

- 向 `ChatMemory` 中添加一条助手消息(`AssistantMessage`)
- 这条消息的内容是:用户取消生成时,大模型已经输出出来的部分内容
关键点:保存的是“不完整”的回复
正常情况下,一轮对话应该是:

用户取消时,可能变成:

为什么要把“不完整”的回复也保存下来?
场景举例:
- 用户问:“请详细介绍一下 Spring AI 的 ChatClient 用法”
- 大模型开始输出,输出到一半用户觉得内容太长,点了停止
- 如果没有保存不完整内容,那么 ChatMemory 中这条助手消息是缺失的
- 用户紧接着问:“继续刚才没说完的”
- 大模型不知道“刚才说到哪了”,会从开头重新回答,或者答非所问
有保存的效果:
- ChatMemory 中已经记录了部分回答
- 用户说“继续”时,大模型可以看到之前已经说过的内容,从中断处继续
还有就是历史记录里面,如果记录的是完整的回答会和页面打断的不完整的回答有冲突,让用户觉得很怪。
注意:保存半截内容可能导致模型理解偏差,可以考虑加中断标记
`conversationId` 是对话会话的唯一标识符,用来区分不同用户/不同会话的历史记录。
3.`var outputBuilder = new StringBuilder();`
创建一个可变字符串缓冲区,用于累积大模型流式输出的所有文本片段
- 流式输出是分多次返回的(每次一小段文本)
- 需要把每次返回的片段拼接起来,形成完整/部分输出
- `StringBuilder` 在频繁追加场景下性能好(比 `String` 的 `+` 或 `concat` 高效)
生命周期
这个变量在每次调用 `chat` 方法时创建,随方法返回的 `Flux` 一起存在,直到:
- 正常结束(所有输出完成)
- 被取消(用户中断)
- 发生错误
4.`outputBuilder.append(text);`
位置

执行时机
每次大模型返回一个流式响应片段时执行。
作用
把当前这一小段文本追加到 `outputBuilder` 的末尾。
举例
假设大模型要输出 `"Hello World"`,分三次返回:
| 第几次 | 返回的 text | outputBuilder 变化 |
| 1 | `"Hel"` | `"Hel"` |
| 2 | `"lo "` | `"Hello "` |
| 3 | `"World"` | `"Hello World"` |
5.`.doOnCancel(() -> { this.saveStopHistoryRecord(conversationId, outputBuilder.toString()); })`
执行时机
当 `Flux` 被取消时触发。
什么情况会取消?
- 客户端断开连接(关闭浏览器、网络中断)
- 主动取消订阅(比如用户点击“停止生成”按钮)
- 上游操作符触发取消(如 `take(Duration.ofSeconds(10))` 超时)
作用
把 `outputBuilder` 中已经累积的内容(即用户取消前大模型已输出的部分)保存到对话历史中。
关键点
- 调用 `outputBuilder.toString()` 获取当前已输出的全部内容(不完整也没关系)
- 传给 `saveStopHistoryRecord` 保存为 `AssistantMessage`
完整数据流示例

基本对话与课程咨询-基于 Redis 实现停止生成的标识容器:
先把原先的注释掉,然后添加 Redis 实现
基本对话与课程咨询-基于 Mysql 实现对话记忆:
先新增一张表:
CREATE TABLE `chat_record` (
`id` BIGINT(19) NOT NULL COMMENT '数据id',
`conversation_id` VARCHAR(100) NOT NULL COMMENT '对话id',
`data` TEXT NULL COMMENT '对话数据',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`creator` BIGINT(19) NOT NULL COMMENT '创建人',
`updater` BIGINT(19) NOT NULL COMMENT '更新人',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4
COLLATE = utf8mb4_bin
ROW_FORMAT = DYNAMIC
COMMENT = '对话记录';核心就是两个字段:
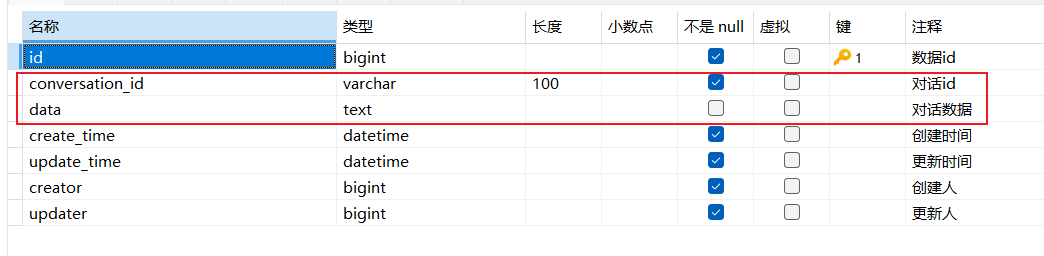
创建实体类:
创建 mapper:
记得加 @Mapper
创建 service:
记得加 @Mapper
创建 memoryRepository:
package com.tianji.aigc.memory.jdbc;
import cn.hutool.core.collection.CollStreamUtil;
import cn.hutool.core.convert.Convert;
import cn.hutool.core.util.StrUtil;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.tianji.aigc.entity.ChatRecord;
import com.tianji.aigc.memory.MessageUtil;
import com.tianji.aigc.service.ChatRecordService;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.Message;
import java.util.List;
public class JdbcChatMemoryRepository implements ChatMemoryRepository {
_/**_
_ * 基于JDBC的聊天记忆存储_
_ *_
_ */_
_ _@Resource
private ChatRecordService chatRecordService;
@Override
public List<String> findConversationIds() {
var chatRecordList = this.chatRecordService.lambdaQuery()
.select(ChatRecord::getConversationId)
.list();
return CollStreamUtil._toList_(chatRecordList, ChatRecord::getConversationId);
}
@Override
public List<Message> findByConversationId(String conversationId) {
var chatRecordList = this.chatRecordService.lambdaQuery()
.eq(ChatRecord::getConversationId, conversationId)
.orderByAsc(ChatRecord::getCreateTime)
.list();
return CollStreamUtil._toList_(chatRecordList, chatRecord -> MessageUtil._toMessage_(chatRecord.getData()));
}
@Override
public void saveAll(String conversationId, List<Message> messages) {
// 先删除原有数据
this.deleteByConversationId(conversationId);
//通过对话id获取用户id
var userId = Convert._toLong_(StrUtil._subBefore_(conversationId, '_',true));
// 批量保存数据到数据库
var chatRecordList = CollStreamUtil._toList_(messages, message -> ChatRecord._builder_()
.data(MessageUtil._toJson_(message))
.conversationId(conversationId)
.creater(userId)
.updater(userId)
.build());
this.chatRecordService.saveBatch(chatRecordList);
}
@Override
public void deleteByConversationId(String conversationId) {
var queryWrapper = Wrappers.<ChatRecord>_lambdaQuery_()
.eq(ChatRecord::getConversationId, conversationId);
this.chatRecordService.remove(queryWrapper);
}
}
从一个带下划线的字符串中提取前半部分,并转换为 `Long` 类型。
`StrUtil.subBefore(conversationId, '_', true)`
- 作用:截取指定字符 之前 的子串。
- 参数解析:
- `conversationId`:原始字符串,例如 `"12345_abcde"`
- `'_'`:分隔符
- `true`:是否包含分隔符本身(这里为 `true` 表示不包含,截取分隔符前面的部分)
`Convert.toLong(...)`
- 这是 Hutool 的 `Convert` 类型转换工具。
- 将上一步得到的字符串 `"12345"` 转换为 `Long` 类型。
- 转换失败会抛出异常(例如字符串不是纯数字)。
SpringAIConfig 增加配置:

application.yml 添加配置:

SpringAIConfig 添加注解:
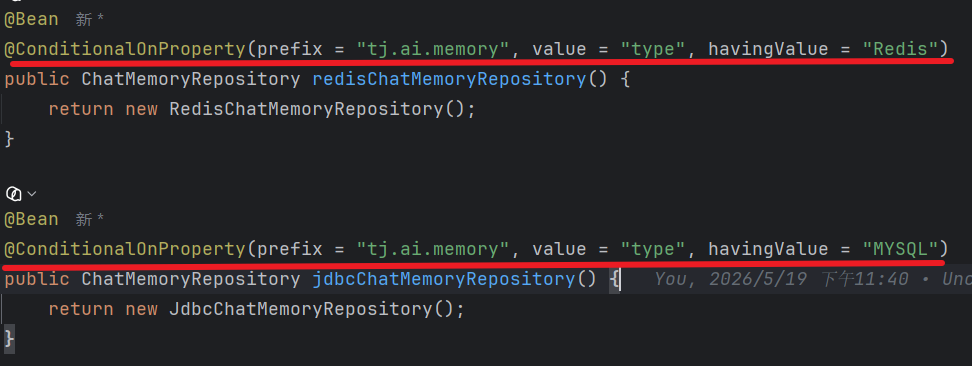
- `@ConditionalOnProperty`
- Spring Boot 提供的条件注解
- 只有当配置条件满足时,被注解的 Bean 才会被注册到 Spring 容器中
- `prefix = "tj.ai.memory"
- 指定配置项的前缀
- 会去配置文件中找以 `tj.ai.memory` 开头的配置
- `value = "type"`
- 指定具体的配置键名
- 完整的配置键是:`tj.ai.memory.type`
- `havingValue = "Redis"`
- 期望的配置值
- 只有当 `tj.ai.memory.type = Redis` 时,条件才满足
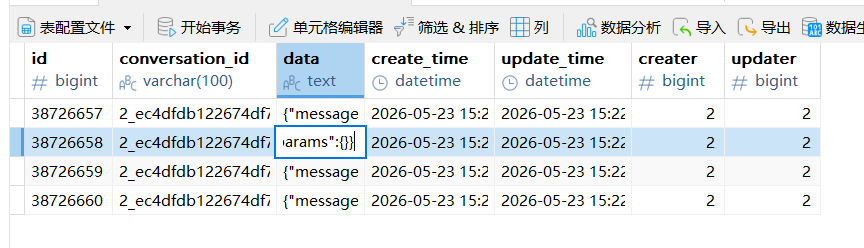
这里内容是有的,显示的问题,copy 到记事本就可以看到了。
基本对话与课程咨询-基于 MongoDB 实现对话记忆:
注入 mongodb 依赖:

建一个 mongodb 实体类:
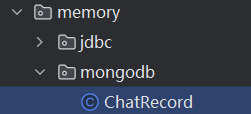
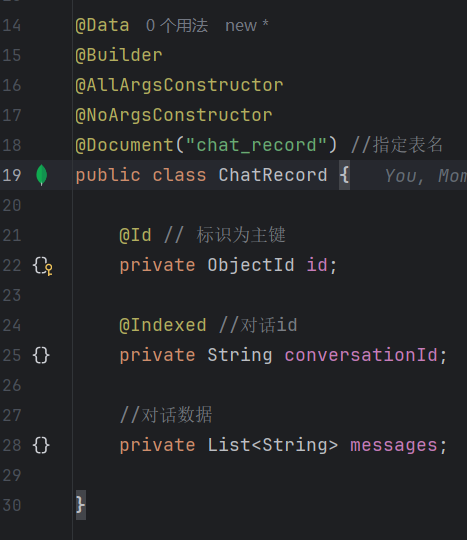
创建 mongodb 脚本:
docker run -d \
--name mongodb \
-p 27017:27017 \
--restart=always \
-v mongodb:/data/db \
-e MONGO_INITDB_ROOT_USERNAME=tianji \
-e MONGO_INITDB_ROOT_PASSWORD=123321 \
mongo:4.4创建 memoryRepository:
package com.tianji.aigc.memory.mongodb;
import cn.hutool.core.collection.CollStreamUtil;
import com.tianji.aigc.memory.MessageUtil;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.Message;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.core.query.Criteria;
import org.springframework.data.mongodb.core.query.Query;
import java.util.List;
_/**_
_ * 基于MongoDB的聊天记忆存储_
_ */_
public class MongoDBChatMemoryRepository implements ChatMemoryRepository {
@Resource
private MongoTemplate mongoTemplate;
@Override
public List<String> findConversationIds() {
var chatRecordList = this.mongoTemplate.findAll(ChatRecord.class);
return CollStreamUtil._toList_(chatRecordList, ChatRecord::getConversationId);
}
@Override
public List<Message> findByConversationId(String conversationId) {
Query query = Query._query_(Criteria._where_("conversationId").is(conversationId));
var chatRecord = this.mongoTemplate.findOne(query, ChatRecord.class);
if (null == chatRecord) {
return List._of_();
}
return CollStreamUtil._toList_(chatRecord.getMessages(), MessageUtil::_toMessage_);
}
@Override
public void saveAll(String conversationId, List<Message> messages) {
// 先删除原有数据
this.deleteByConversationId(conversationId);
// 构造 chatRecord 数据
var chatRecord = ChatRecord._builder_()
.conversationId(conversationId)
.messages(CollStreamUtil._toList_(messages, MessageUtil::_toJson_))
.build();
// 保存到MongoDB中
this.mongoTemplate.save(chatRecord);
}
@Override
public void deleteByConversationId(String conversationId) {
Query query = Query._query_(Criteria._where_("conversationId").is(conversationId));
this.mongoTemplate.remove(query, ChatRecord.class);
}
}SpringAI 配置:

添加 mongodb 配置:
data:
mongodb:
host: 192.168.150.101
port: 27017
database: tianji
authentication-database: admin
username: tianji
password: "123321"
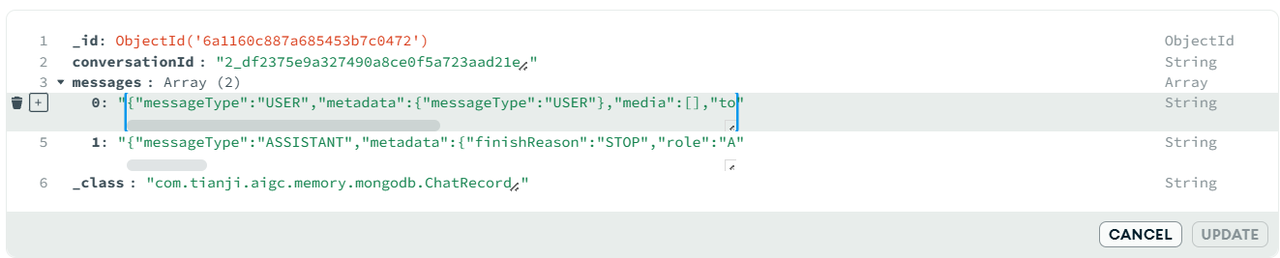
auto-index-creation: true测试:
如果对你有帮助的话,请点赞,关注,收藏。热爱可抵一切!👍 ❤️ 🔥
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)