
Java集合底层:数组、链表、树的组合艺术
引言:
这两天系统复习了Java的集合的相关内容,从中通过对于一些知识盲区的深挖,又有了不一样的体会。我觉得整个集合的各种结构,例如例如ArrayList、HashMap主要就是对于数组、链表、树等数据结构的应用。而链表呢,它其实又是对于Java引用的应用。这种从底层一步步搭建一个个广泛应用的集合类的Java核心代码设计,真的让我体会到了Java语言的魅力。
1、集合整体架构
这里我先放一张Java集合的整体架构图(只列举了一些常用的):
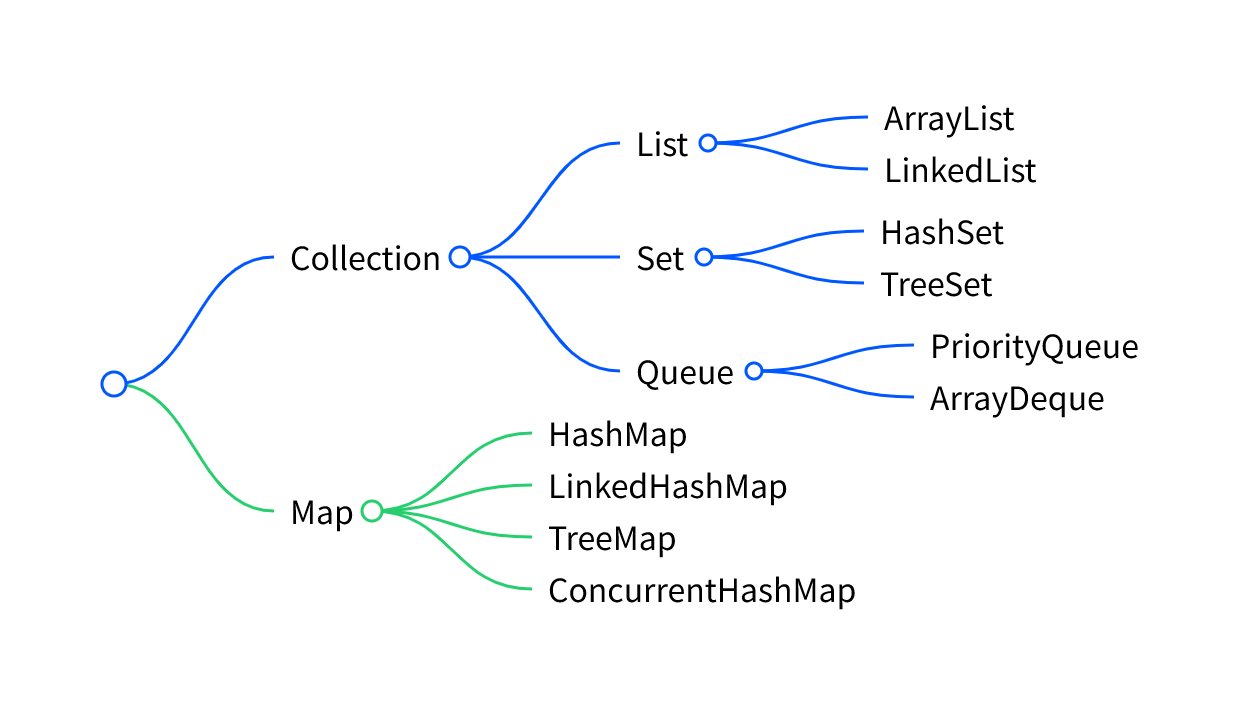
Java 集合分为两大体系: Collection 和 Map。
Collection 下面有 List、Set、Queue。List 是可重复的,常用 ArrayList 和 LinkedList。ArrayList适合需要频繁查询的场景、LinkedList适合需要频繁头尾增删场景;Set 是不可重复的,常用 HashSet 和 TreeSet。HashSet适合需要去重的场景、TreeSet适合需要排序的场景。Queue是可重复的,常用PriorityQueue和ArrayDeque 。
Map 是键值对,常用 HashMap、LinkedHashMap、TreeMap 和线程安全的 ConcurrentHashMap。HashMap适合根据key进行查询的场景、LinkedHashMap适合需要记录访问顺序场景。
内容扩展
关于Set: 一些地方说,Set是无序的,但是实际上它的实现类HashSet是无序的、而TreeSet是有序的。也就是说,Set的有序无序性不能直接确定,需要看具体的实现类。
关于Map的有序性: 我个人认为,对于Map不管什么情况下,所有key之间,本身是没有任何关联的。而它的有序无序性应该是看内部存放的键值对这个整体,例如HashMap,键值对没有联系起来,无序;LinkedHashMap,通过内部维护的双向链表,将所有键值对联系起来,有序;TreeMap,所有的键值对之间通过红黑树关联起来,有序。
2、List的常用实现类
- ArrayList
因为底层是数组,查找的效率是O(1),如果删除尾部,效率是O(1),如果要删除中间元素,后续元素由于要移动,所以效率是O(n)。新增元素由于它的预留空间机制,所以尾部写入的平均复杂度为O(1)。
它主要是对数组的运用,逻辑上看,就是一个数组,只不过只使用前面的连续区域,再用一个值记录最后一个非空位置下标,其余空位置也就是所谓的预留空间。这个空间的作用就是,每次新增元素时,只要不达到最大容量上限,就使用预留空间,预留空间也不足才扩容。能有效降低扩容频率,间接减少扩容性能开销。
扩容机制: 首次创建数组长度为10,长度不足放入下一个元素时触发扩容,新数组长度变为原来1.5倍,扩容时会将旧数组内容复制到新数组。
尾部Add的平均复杂度分析
- 平均复杂度 = 总扩容耗时 / 最终数组容量 (N)
- 假设每次扩容的耗时 = 当前数组的长度(需要复制的元素个数)
扩容耗时是一个等比数列:
首项 a = 10,公比 r = 1.5
经过 m 次扩容后,总耗时 S_m 为:
S_m = a × (r^m - 1) / (r - 1)
最终容量 N = a × r^m- 平均耗时 = S_m / N
= [a × (r^m - 1) / (r - 1)] / (a × r^m)
= [1 / (r - 1)] × (1 - 1 / r^m)
代入 r = 1.5,r - 1 = 0.5:
平均耗时 = 2 × (1 - (2/3)^m)- 当 m 增大时,(2/3)^m 趋近于 0,平均耗时趋近于常数 2因此,无论容量多大,平均耗时都不会超过这个常数。ArrayList 尾部添加的均摊时间复杂度为 O(1)。
- LinkedList
它的底层是双向链表,中间增删需要找到增删位置,时间复杂度为O(n),而头尾由于维护了头尾节点,所以增删无需定位,直接更改节点指向即可。但是什么场景需要频繁头尾增删呢?极少。我们项目中其实极少使用它,并且它的绝大多数使用场景都能被ArrayList替代。
它主要是对链表的运用,底层就是双向链表,只不过不对外暴露具体某个节点的结构,只暴露add、getFirst、getLast等高级方法。
2、Set的常用实现类
- HashSet
适合需要去重的场景。它的底层是一个value值固定的HashMap,根据key的不可重复(key相同值覆盖)实现去重。 - TreeSet
适合需要排序的场景。存入的元素天然有序。底层同样就是一个TreeMap,也就是一棵红黑树,能自然排序也能自定义排序规则排序。值得注意的是TreeMap相比与HashMap的拉链结构完全不同,没有数组链表等结构,仅仅是维护了红黑树结构。
它就是对树的运用,同样的也是一棵被封装起来的红黑树,只提供add、first、last等高级方法,内部节点是私有的。
3、Map的常用实现类
- HashMap
适合根据key进行查询的场景;在JDK 1.7 中,HashMap 是数组加链表,链表采用头插法,扩容时链表顺序会反转,多线程下可能形成环形链表导致死循环。JDK 1.8 改成了数组加链表加红黑树,当链表长度>=8 且数组长度>= 64 时,链表会转为红黑树,查找效率从 O(n) 提升到 O(log n);当链表长度<=6时 ,红黑树会转回链表。同时 JDK 1.8 改用尾插法,解决了死循环问题。- 扩容规则:
HashMap 默认容量是 16,负载因子 0.75,当元素个数达到12 时会触发扩容。扩容时新容量是旧容量的 2 倍,然后使用哈希重新计算每个元素的位置,元素要么留在原索引,要么移到原索引加原容量的位置。扩容会重新分配数组,有一定性能开销。
- 扩容规则:
它主要是对数组、链表和树的应用, 总体为拉链式散列结构,用一个数组来记录所有的哈希桶。不过同样的为了确保分布均匀,减少哈希冲突,数组中元素分布是均匀的、分散的,中间会有部分空节点。数组中永远都有空节点,因为非空元素数量/数组长度达到负载因子(默认0.75)时,会触发扩容。哈希冲突发生时,将冲突节点挂在一个链表或者红黑树上。
关于尾插法
虽然尾插法需要找链表尾部,但是HashMap中本来就有遍历链表判断key是否存在的操作,两者合并,没有额外性能开销。
死循环示例
- 初始状态
一个桶(数组槽位)里有一个链表:[3] -> [7] -> null,线程 T1 和 T2 同时对这个 HashMap 进行扩容
关键: 头插法扩容时,会把链表顺序反转,比如 3->7 变成 7->3。
步骤:
- T1 和 T2 同时进入扩容方法,都拿到了:e = 3(当前节点)next = 7(下一个节点)
- T1 被操作系统暂停(挂起),T2 继续执行。
- T2 完成整个扩容(关键:它把链表反转了):新链表变成:[7] -> [3] -> null
- T1 恢复执行,它手里仍然拿着旧数据:e = 3、next = 7,T1 开始执行它的第一次循环:把 3 插入新桶 → 由于 T2 已经把桶处理过,新桶里已有 7->3,头插法会把 3 插到头部 → 新桶变回 [3] -> [7] -> [3]
- 此时3 和 7 互相指向,形成一个环。以后只要查询到这个桶,while 循环永远走不到 null,CPU 100%。
为什么扩容后元素要么在原位置,要么到原索引加原容量的位置:
- 因为计算位置时,使用的是哈希和容量-1做与运算。由于数组长度是2的幂,并且扩容时容量翻倍,所以它的容量-1相比原容量只是最高位多了一位1,其他位完全相同。这样新旧容量与哈希做与运算时,运算结果只有最高位不同,如果是0,那么元素就在原索引。如果是1,那么就在原索引加原容量的位置。
- LinkedHashMap
适合需要记录访问顺序场景;在HashMap基础上,内部通过额外维护前驱和后继节点的指针、头尾虚节点来实现了双向链表。它有两个特点,- 第一,可以记录插入顺序或者访问顺序。默认是插入顺序,如果开启访问顺序,每次 get 后元素会被移到链表末尾,这个特性可以用来实现 LRU 缓存。
- 第二,遍历时的效率和元素个数成正比,迭代效率相较于和容量成正比的 HashMap 来说会高很多。
- 我之前的误区是认为是里面既有HashMap、又额外搞了个双向链表。但是实际上完全不是那么回事,如果是额外的链表,那么想记录访问顺序,需要O(n)复杂度定位节点,导致get时间复杂度不是O(1)。
这里我觉得有张图总结的非常好,来源于:JavaGuide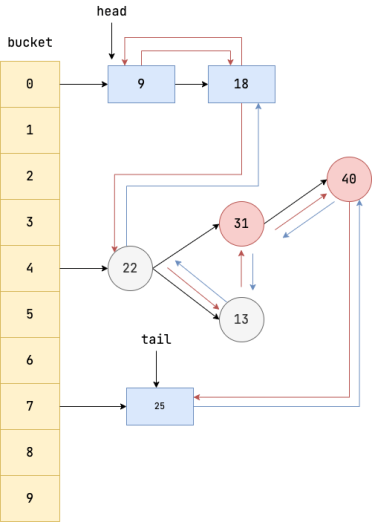
它也是对数组、链表和树的应用, 在HashMap的基础上,又增加了一个双向链表。链接每个桶中的链表、红黑树的键值对节点。
- ConcurrentHashMap
适合需要线程安全的场景。在 JDK 1.7 中,ConcurrentHashMap 采用分段锁,默认 16 个 Segment,每个 Segment 独立加锁,多个线程可以同时操作不同的 Segment,并发度最高 16。在 JDK 1.8 中,改成了 CAS 加 synchronized:当数组位置为空时,用 CAS 原子操作放进去;当发生哈希冲突时,用 synchronized 锁住链表头或红黑树根节点,锁粒度细化到单个桶,并发度更高,而且 synchronized 在 1.8 中做了锁升级优化,性能很好。
它是对于数组、链表和树的应用,在1.7中它和HashMap最大不同点在于,它把原来的大数组的桶,按照范围进行了分段,每个分段都保存一个小数组,把一整个哈希数组进行了拆分,它的扩容、查找等机制,由于额外嵌套一层对象结构,所以较为复杂。例如扩容时要同步扩张所有分段的小数组、put时先定位处于哪个分段,然后获取锁,再进行操作。1.8的底层结构和HashMap类似,只是多了一些并发安全的考量。
扩展内容
1.7的ConcurrentHashMap,内部数组是分段保存在16个Segement对象中,每个segment中有一个小数组,数组某个位置为空,由于已经加锁,所以可以直接放进去。CAS是一条原子的CPU指令,不是java代码写的。
4、总结
综上所述,所有的这些集合类,都没有跳出数组、链表、树这些数据结构的范围。都是进行了各种应用、各种组合。没有什么特别神奇的地方,也没有什么黑魔法。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)