
第二:Python中selenium八大元素定位
·
一.如何进行元素定位
1.元素: 由标签头+标签尾+标签头和标签尾包括的文本内容
2.元素的信息就是指元素的标签名以及元素的属性
3.元素的层级结构就是指元素之间相互嵌套的层级结构
4.元素定位最终就是通过元素的信息或者元素的层级结构来进行元素定位
二.浏览器开发者工具介绍
1.浏览器开发者工作主要用来查看元素的信息, 同时也可以查看接口的相关信息
2.浏览器开发者工作不需要安装,浏览器自带
3.浏览器开发者工具的启动
3.1.直接按F12 不区分浏览器
3.2.通过右键的方式来启动浏览器开发者工具 (谷歌浏览器右键选择“检查”, 火狐浏览器右键选择“检查元素”
4.浏览器开发者工具使用
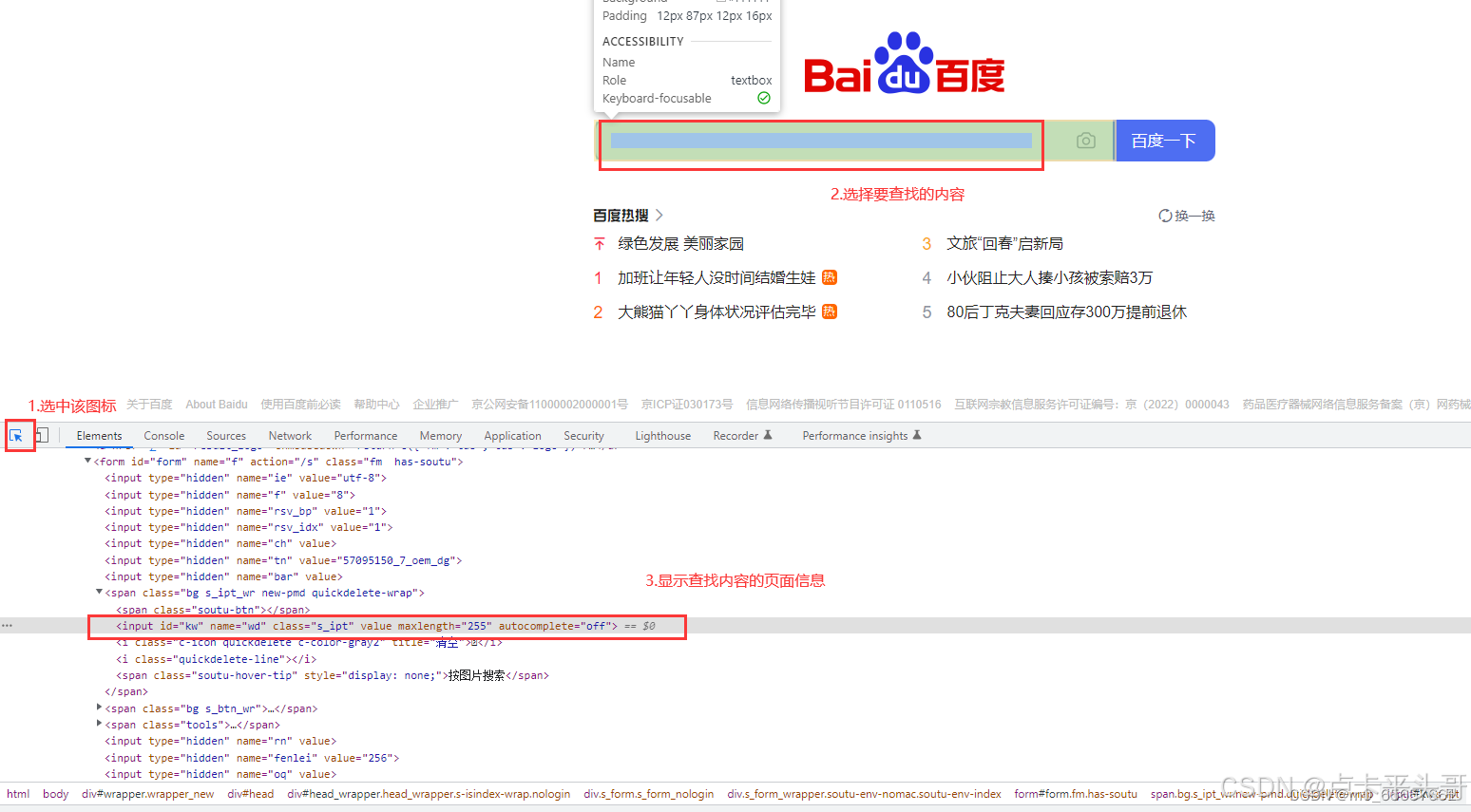
4.1.点击 浏览器开发者工具左上角的 元素查看器按钮
4.2.再点击想要查看的元素
4.3.元素定义的返回值
4.4.返回匹配到的第一个元素
三.id属性定位
1.通过元素的ID属性值来进行元素定位 ,在html标准规范中 ID值是唯一的
2.说明: 元素要有ID属性
3.定位方法: find_element_by_id(id)
# id参数表示的是id的属性值
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.title)
# 获取搜索框
search_input=driver.find_element_by_id('kw')
print(type(search_input))
print('搜索框的name属性值=',search_input.get_attribute('name'))
driver.quit()
四.name定位
1.通过元素的name属性值为进行元素定位 name属性值 在HTML页面 中,是可以重复的
2.说明:元素要有name属性
3.定位方法: find_element_by_name(name)
# name 参数表示的是name的属性值
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.title)
# 通过name属性定位搜索框
search_input_by_name=driver.find_element_by_name('wd')
print('4.搜索框的id=',search_input_by_name.get_attribute('id'))
driver.quit()
五.class_name定位
1.通过元素的class属性值进行元素定位 class属性值是可重复的
2.说明:元素必须要有class属性
3.定位方法: find_element_by_class_name(class_name)
# class_name参数表示的是class的其中一个属性值
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.title)
# 3.百度logo
logo=driver.find_element_by_class_name('index-logo-src')
print('3.百度logo的src=',logo.get_attribute('src'))
driver.quit()
六.tag_name定位
1.通过元素的标签名称进行定位, 在同一个html页面当中,相同标签元素会有很多
2.这种定位元素的方式不建议大家在工作当中使用
3.定位方法: find_element_by_tag_name(tag_name)
# tag_name表示的是元素的标签名称
4.如果有重复的元素,定位到的元素默认都是第一个元素
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
title=driver.find_element_by_tag_name('title')
print('百度首页的title=',title.tag_name)
driver.quit()
七.link_text定位
1.通过超链接的全部文本信息进行元素定位 ,主要用来定位a标签
2.定位方法: find_element_by_link_text(link_text)
# link_text参数代表的是a标签的全部文本内容
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
el_a=driver.find_element_by_link_text('新闻')
print('新闻栏目的url',el_a.get_attribute('href'))
driver.quit()
八.partail_link_text定位
1.通过超链接的局部文本信息进行元素定位,主要用来定位a标签
2.定位方法:find_element_by_partial_link_text(partial_link_text)
# partial_link_text表示的是a
3.标签 的局部文本内容
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
el_a=driver.find_element_by_partial_link_text('新')
print('新闻栏目的url',el_a.get_attribute('href'))
driver.quit()
九.xpath定位
1.xpath是一个解析html/xml的语言
2.选取节点
| nodename | 选取此节点的所有子节点 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
2.1.案例: //div 获取文档中所有的div
3.谓语
3.1.用来查找某个特定的节点或者包含某个指定的值的节点,谓语被嵌在方括号中
| //div[@class=“active”] | 选取class="active"的div |
|---|---|
| //div[@class=“active”]/span | 选取class="active"的div子元素的第一个span元素(索引从1开始) |
| //div[@class=“active”]/span[2] | 选取class="active"的div子元素的第二个span元素 |
| //div[@class=“active”]/span[last()] | 选取class="active"的div子元素的倒数第一个span元素 |
4.轴
4.1.用来查找相对于当前节点的节点(轴名称::节点名称[谓语])
| ancestor | 选取当前节点的所有先辈(父、祖父等) |
|---|---|
| parent | 选取当前节点的父节点 |
| descendant | 选取当前节点的所有后代元素(子、孙等) |
| child | 选取当前节点的所有子元素 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点 |
| preceding-sibling | 选取当前节点之前的所有同级节点 |
| following | 选取文档中当前节点的结束标签之后的所有节点 |
| following-sibling | 选取当前节点之后的所有同级节点 |
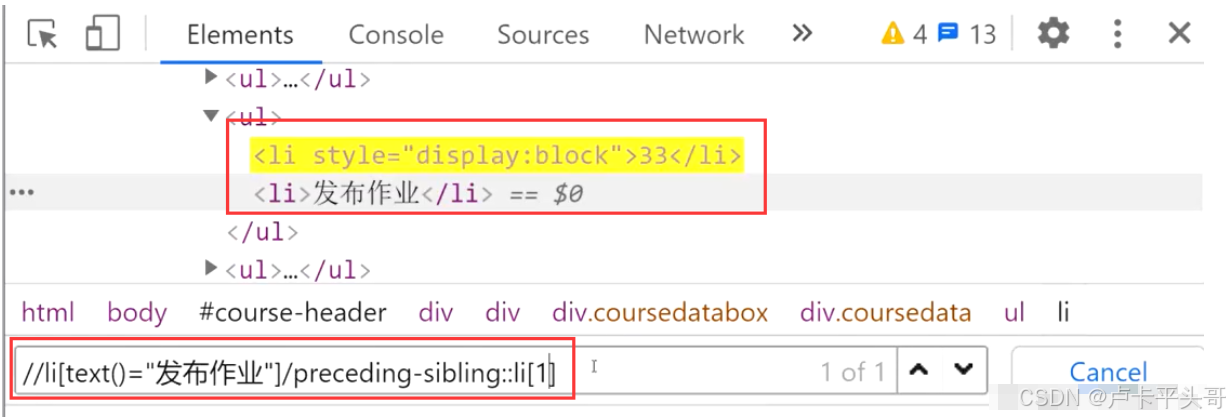
4.2.案例://li[text()='发布作业']/preceding-sibling::li[1] 选取text()='发布作业'的li的前面的第一个想到节点li
5.函数
5.1.text():元素的text内容
li[text()='发布作业'] text()='发布作业'的li
5.2.contains(@属性名/text(),value) :包含内容
li[contains(@class,'ls')] class包含'ls'的li
6.逻辑运算
6.1.and 与:
//div[@class='btn' and contains(@style,'display:block')]
表示div元素中class='btn'且style包display:block
6.2.or 或
//div[@class='btn' or contains(@style,'display:block')]
表示div元素中class='btn'或style包含display:block
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
search_btn=driver.find_element_by_xpath('//input[@value="百度一下"]')
print('2.搜索按钮的id=',search_btn.get_attribute('id'))
driver.quit()
十.css定位
1.css的定义
1.1.总结:css是可以用来在selenium中定位元素的
1.2.CSS定位元素的方法: find_element_by_css_selector(css_selector)
# css_selector表示的是CSS选择器表达式
2.css定位策略
a.id选择器
b.class选择器
c.元素选择器
d.属性选择器
e.层级选择器
1.id选择器
1.1.表达式: #id
# 表示通过元素的ID属性进行元素选择 id 表示的的id属性的属性值
# 直接根据id定位,send_keys往输入框输入文本
driver.find_element_by_css_selector("#kw").send_keys('12345')
# 通过标签加id的形式定位,click点击
driver.find_element_by_css_selector('input#su').click()
2.class选择器
2.1.表达式: .class
.表示通过元素的class属性进行元素选择, class表示的class属性的其中一个属性值
# 直接根据clas定位
driver.find_element_by_css_selector(".s_ipt").send_keys('12345')
# 标签加class
driver.find_element_by_css_selector('input.s_btn').click()
# 多class属性定位
# driver.find_element_by_css_selector('.bg.s_btn').click() # class1 class2
# driver.find_element_by_css_selector('input.bg.s_btn').click() # input加多属性
3.tag_name元素选择器
3.1.通过元素标签名称来选择元素
3.2.表达式: tag_name 不推荐使用
# 通过css的元素选择器定位搜索输入框,输入12345
inputs = driver.find_elements_by_css_selector('input')
print(inputs)
for i in inputs:
if i.get_attribute('id') == 'kw':
i.send_keys('12345')
# 通过css的元素选择器定位搜索按钮,并点击
for i in inputs:
if i.get_attribute('id') == 'su':
i.click()
4.属性选择器
4.1.通过元素的属性来选择元素。
4.1.1.表达式:[attribute='value'] #attribute 表示的是属性名称,value表示的是属性值
4.2.如果使用的是class属性,需要带上class的全部属性值
# 通过css的属性选择器定位搜索输入框,输入12345
driver.find_element_by_css_selector("[class='s_ipt']").send_keys('12345')
# 通过css的属性选择器定位搜索按钮,并点击
driver.find_element_by_css_selector("[class='s_btn']").click()
5.层级选择器
5.1.父子层级关系选择 器
5.1.1.表达式: element1>element2 通过element1来找element2,并且element2是element1的直接子元素
5.2.隔代层级关系选择器
5.2.1.表达式: element1 element2 通过element1来找element2, 并且element2是element1的后代元素
# 匹配子元素, A>B
driver.find_element_by_css_selector('form>span>input').send_keys('12345')
# 匹配后代元素, A空格B
driver.find_element_by_css_selector('form span input').send_keys('12345')
6.CSS扩展
6.1.input[type^='value'] input表示标签名称,type表示属性名称, value表示的文本内容
6.1.1.查找元素type属性值是以value开头的元素
input[type^='p'] #type属性以p字母开头的元素
6.2.input[type$='value'] input表示标签名称,type表示属性名称, value表示的文本内容
6.2.1.查找元素type属性值以value结尾的元素
input[type$='d'] #type属性以d字母结束的元素
6.3.input[type*='value'] input表示标签名称,type表示属性名称, value表示的文本内容
6.3.1.查找元素type属性值包含value的元素
input[type*='w'] # type属性包含w字母的元素
# 精准匹配
driver.find_element_by_css_selector('input[name=wd]').send_keys('12345') # 属性名=属性值
driver.find_element_by_css_selector('input[type="submit"][value="百度一
下"]').click() # 多属性
# 模糊匹配(正则表达式匹配)
driver.find_element_by_css_selector('input[id ^="k"]').send_keys('12345') # ^=匹配以 k 开头的id
driver.find_element_by_css_selector('input[id $="w"]').send_keys('12345') # $=匹配以 w 结尾的id
driver.find_element_by_css_selector('input[value *="度一"]').click() # *= 匹配value 值的中间部分
十一.元素动态定位
1.当元素的定位方式不确定,可能是id,可能是xpath时,需要通过不同的方式动态指定定位方法
1.1.需要导入By类
find_element(by, value) :by为定位方式,value为定位表达式
2.By选择将上面繁琐的元素定位封装了起来,这样使用起来较为方便,只是在使用By选择器前要导入
from selenium.webdriver.common.by import By
2.1.用法如下,非常简单
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
# 打开百度页面
driver.get('http://www.baidu.com')
id_loc=(By.ID,'kw')
# by的最初用法
# driver.find_element(By.ID,'kw').send_keys('我通过id定位')
# 将id_loc解包传入
driver.find_element(*id_loc).send_keys('12345')
time.sleep(10)
driver.quit()
3.各元素定位方式写法
By.ID
By.CLASS_NAME
By.CSS_SELECTOR
By.TAG_NAME
By.NAME
By.PARTIAL_LINK_TEXT
By.LINK_TEXT
By.XPATH
十二.定位元素的选择
1.若html中id元素可用唯一且始终可预测,则id是元素定位的首选方法,因为id是直接定位,不存在遍历带来的大量处理
2.若没有唯一的id,则推荐使用css和xpath来查找元素,当使用xpath时
3.xpath可通过增加节点层级加快查找速度,但当子节点过多时,页面又发生变化则需要修改定位信息,故层级多时稳定性不高
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)