
Python 爬虫 · 模拟浏览器登陆 - 处理 Cookie
Python 学习第 34 天。
当我们用浏览器正常访问某网站时,常常会出现需要 “登陆” 的情况,比如登陆后才能翻页、下载、查看之前的浏览 / 操作记录,这是因为网站会将普通访问者识别为游客或用户,某些权限只为用户开放,且 HTTP 是无状态协议,只有在登陆状态下才能维持会话,保证历史信息的连贯性。另外,登陆后的用户也能绕过网站的访问数量限制。
当我们用爬虫爬取网站信息时,多数网站会默认设置防止爬虫进入的机制,为了解决这个问题,就需要将爬虫模拟成普通浏览器,遇到需要登陆的情况,也需要给爬虫带上相应身份的 “通行证(账号、密码)” ,以便其将自己伪装成用户,进入网站获取信息。
一、Cookie
Cookie 是由服务器下发,保存在客户端 / 浏览器的小型文本数据,由键值对组成。用于记录用户的登陆省份、会话 ID、浏览状态、偏好设置等,这样就能弥补 HTTP 无状态的缺陷,让服务器记住每个用户的操作信息(比如:历史订单、点赞、收藏、下载、关注、浏览记录等)。
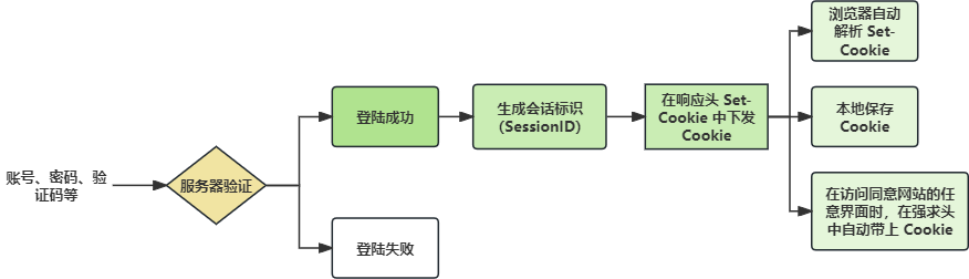
图1 Cookie 的产生与应用原理流程图
二、模拟浏览器登陆
![]()
图2 爬虫模拟浏览器登陆、抓取数据流程图
1. 安装 requests 包
pip install requests首次安装,运行结果末端部分会显示已经安装完毕和安装的版本号,类似:
![]()
已经安装过,运行结果会提示之前已经安装、存储的路径、安装的版本号,类似:
Requirement already satisfied: requests in c:\anaconda_\lib\site-packages (2.32.5)
(本专栏第 28 篇《Python 爬虫 · requests 模块基础》中对 requests 有详解。)
2. 导入包
import requests3. session() 会话函数
requests 模块中的 session() 函数是一个会话函数,它能够保证在对话(请求、回复)过程中 Cookie 不丢失,这样就能记住会话中产生的内容,保持连续性。
(1) 初始化对象
session = requests.session()(2) 登陆
确定需要爬取的网站,登陆,而后需要将网站链接、登陆信息(用户名、密码)存入变量中,后续与 session() 相关的函数需要这些信息时,直接调用变量即可。
格式:变量名 = "网站链接"
变量名 = {
"代表用户名的键":"用户名",
"代表密码的键":"密码"
}
而后,请求登陆,格式:变量名 = session.post(存储网站链接的变量名, data = 存储用户信息的变量名)
如果想查看请求登陆返回的信息,格式:存储请求登陆的变量名.text
如果想查看 Cookie,格式:存储请求登陆的变量名.cookies
(3) 爬取数据
格式:变量名 = session.get("需要爬取的网页链接")
如果想知道爬取到的网页文本信息,格式:存储爬取到的网页信息的变量名.text 或 存储爬取到的网页信息的变量名.json()
三、问题解决 - 找到标准的 url、用户名、密码、Cookie
步骤一:打开所在网页的文档
(1) 点击键盘上的 F12;
(2) 鼠标右键 → 检查;
(3) Window:点击 Ctrl + Shift + I
(4) Mac:点击 Cmd + Opt + I
(5) 点击浏览器右上角的 “三个点” → 点击 “更多工具” → 点击 “开发者工具”
注意:键盘的 F12 属于快捷键,容易被本身的电脑系统功能占用,如果发现 F12 打不开所在页面的 HTML 文档,就用 (2) ~ (5) 中任意方法打开。
步骤二:点击 “清空网络日志” 按钮 / 图标,勾选 “保留日志”,这样找的时候会更清晰
步骤三:找到并点击 Network 网络面板 / 它的图标,并在网页界面中点击右键 → 刷新

步骤四:刷新完成后,开始找
![]()
步骤五:登陆,如果登陆过的话,先退出再重新登陆一次,然后在 “名称” 里找与 login 相关的名称,点击之后在 “负载” 中查找 “username” 和 “password” 相关的字段,后面接的就是标准的用户名和密码
步骤六:先在 “名称” 里找 “主请求”,点开,这里是 www.csdn.net

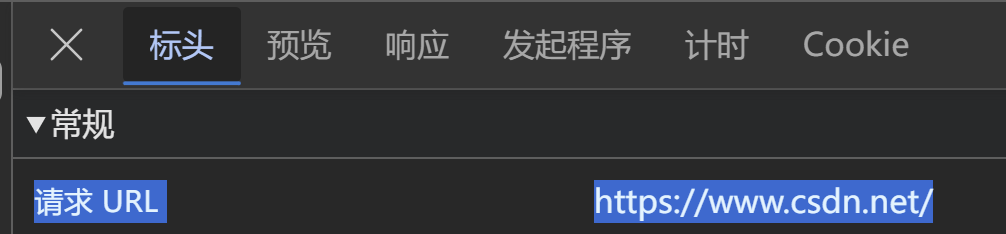
步骤七:找到 “常规” 部分,里面的 “请求 URL”,就是要找的标准 url
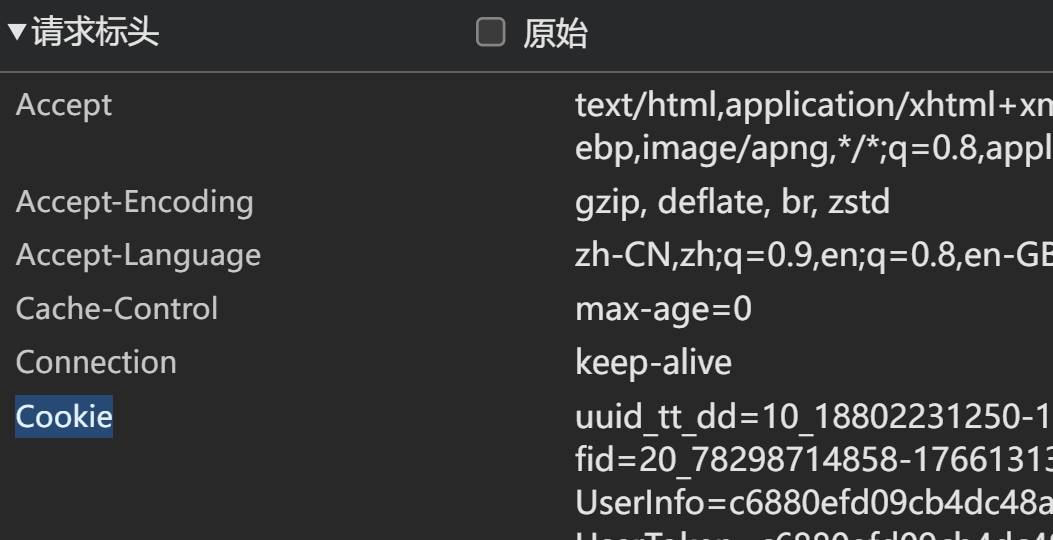
步骤八:找到 “请求标头” 部分,“Cookie” 后跟着的一长串就是标准的 cookie
通常情况下,如果不确定用户名和密码是什么(现在常用的登陆方式往往是扫码登陆、验证码登陆等),且查找很麻烦的情况下,我们会直接采用直接给 session 传入 Cookie 的方法去进行会话。格式:sesiion.headers["Cookie"] = "找到的标准 Cookie 码",这样之后的 session() 相关的函数都会自动带 Cookie,不需要我们反复输入。
另外,为了方式反爬,可以再加一句 sesiion.headers["User-Agent"] = "请求头部分 User-Agent 后跟的文本",用于告诉服务器用的是什么浏览器、操作系统、设备类型。
更多推荐

 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)