
Requests-HTML:Python 网页解析工具
Requests-HTML:Python 网页解析工具
requests-html 是 Python 生态中广受欢迎的网页解析库,目前在 GitHub 上已获得 13,831 个 Star。这个数字充分证明了其在开发者社区中的认可度和实用性。
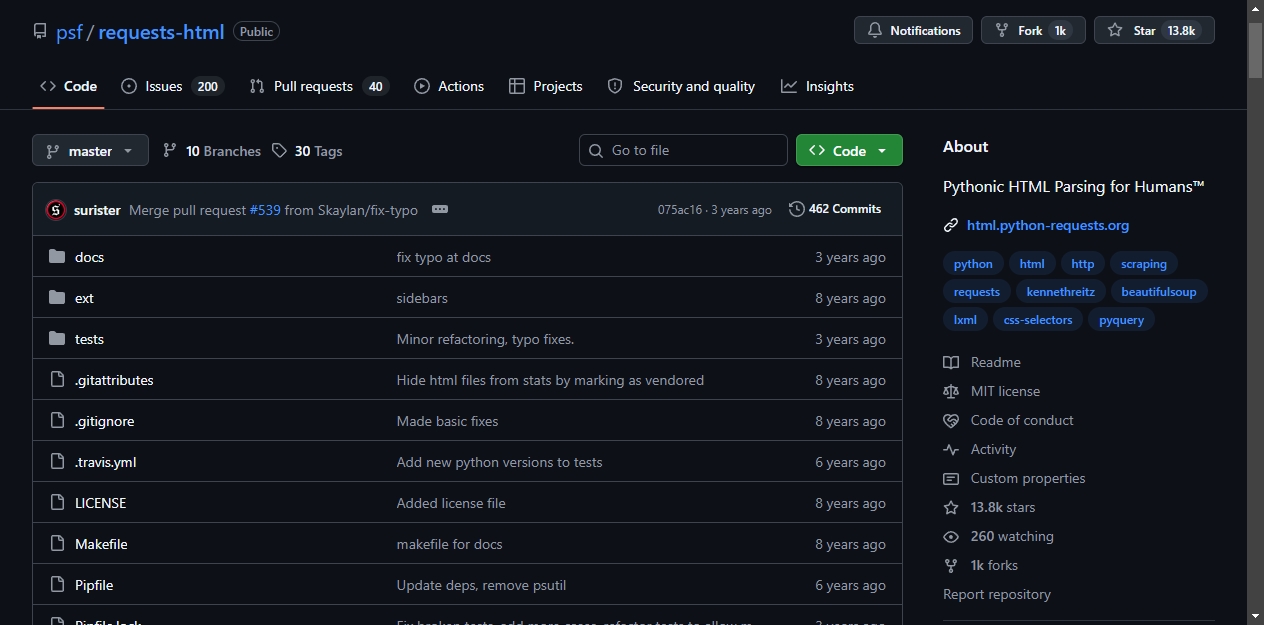
该库由 Python 软件基金会(PSF)开发,旨在让 HTML 解析(如网页抓取)变得简单直观。它将大家熟悉的 requests 库与强大的 HTML 解析能力相结合,提供了一整套网页处理解决方案。无论是数据采集、内容分析还是自动化测试,requests-html 都能成为开发者的得力助手。

核心特性
requests-html 最突出的特点是其一体化设计。不同于传统的网页抓取需要结合 requests 和 BeautifulSoup 等多个库,requests-html 将所有功能整合到一个库中,极大简化了开发流程。使用该库,你可以自动获得以下功能:
- 完整 JavaScript 支持:基于 Chromium 内核,能够渲染动态网页内容。这意味着你可以抓取那些依赖 JavaScript 加载的单页应用(SPA)内容
- CSS 选择器:支持 jQuery 风格的选择器语法,让元素定位更加便捷
- XPath 选择器:提供另一种灵活的元素定位方式,适合复杂的页面结构
- 模拟用户代理:默认使用真实浏览器的用户代理字符串,避免被目标网站识别为爬虫
- 自动重定向处理:透明处理 HTTP 重定向,无需手动处理
- 连接池与 Cookie 持久化:自动管理连接池和 Cookie,提升请求效率
- 异步支持:支持并发请求,提高爬取速度
基础使用示例
使用 requests-html 非常简单,以下是一个基本的使用示例:
>>> from requests_html import HTMLSession
>>> session = HTMLSession()
>>> r = session.get('https://python.org/')
你可以轻松获取页面上的所有链接:
>>> r.html.links
{'//docs.python.org/3/tutorial/', '/about/apps/', 'https://github.com/python/pythondotorg/issues', ...}
或者使用 CSS 选择器定位特定元素:
>>> about = r.html.find('#about', first=True)
>>> print(about.text)
About
Applications
Quotes
Getting Started
Help
Python Brochure
JavaScript 渲染支持
requests-html 真正强大的地方在于它能够处理 JavaScript 动态渲染的内容。例如,你可以抓取需要 JavaScript 加载的倒计时时钟:
>>> r = session.get('https://pythonclock.org')
>>> r.html.render() # 渲染 JavaScript 内容
>>> countdown_data = dict(zip(
... [element.text for element in r.html.find('.countdown-period')],
... [element.text for element in r.html.find('.countdown-amount')]
... ))
>>> countdown_data
{'Year': '1', 'Months': '2', 'Days': '28', 'Hours': '16', 'Minutes': '52', 'Seconds': '46'}
首次调用 render() 方法时,会自动下载 Chromium 浏览器到你的用户目录,这只需要进行一次。
异步支持
requests-html 还提供了异步支持,让你可以同时处理多个请求:
>>> from requests_html import AsyncHTMLSession
>>> asession = AsyncHTMLSession()
>>> async def get_pythonorg():
... r = await asession.get('https://python.org/')
... return r
...
>>> async def get_reddit():
... r = await asession.get('https://reddit.com/')
... return r
...
>>> results = asession.run(get_pythonorg, get_reddit)
>>> results
[<Response [200]>, <Response [200]>]
独立使用 HTML 解析
如果你已经有了 HTML 内容,也可以直接使用 requests-html 进行解析,而无需发起网络请求:
>>> from requests_html import HTML
>>> doc = """<a href='https://httpbin.org'>"""
>>> html = HTML(html=doc)
>>> html.links
{'https://httpbin.org'}
安装方法
安装 requests-html 非常简单,使用 pip 命令即可:
$ pipenv install requests-html
需要注意的是,该库仅支持 Python 3.6 及以上版本。
总结
requests-html 是一款功能全面的 Python 网页解析库,它将网络请求与 HTML 解析完美结合,提供了简洁直观的 API。其一体化设计大大降低了网页抓取的门槛,即使是初学者也能快速上手。
无论是进行简单的网页内容提取,处理复杂的动态网页,还是需要并发请求提高效率,requests-html 都能胜任。它在保持简洁 API 的同时,并没有牺牲功能的完整性,是 Python 生态中网页抓取领域的佼佼者。
如果你正在寻找一款易于使用但功能强大的网页抓取工具,requests-html 绝对值得尝试。它不仅能帮你快速完成任务,还能让整个开发过程更加愉悦。
的同时,并没有牺牲功能的完整性,是 Python 生态中网页抓取领域的佼佼者。
如果你正在寻找一款易于使用但功能强大的网页抓取工具,requests-html 绝对值得尝试。它不仅能帮你快速完成任务,还能让整个开发过程更加愉悦。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)