
别再死记 SQL!Java 后端 MySQL 数据表 DDL+CURD 全套操作一次性讲透
📚 目录
前言:本文是自学Java后端整理的MySQL数据表完整操作笔记,分为两大模块:
- DDL(数据定义语言):操作数据表结构,包含建表、改表、删表;
- DML(数据操作语言):操作表内数据,也就是CURD增查改删。
文中附带可直接运行的SQL示例与新手踩坑总结,不用零散背诵SQL,适合Java初学者、后端面试基础复习。
1. 表基础操作
1.1 创建表
语法 :
create [temporary] table [if not exists] tbl_name
field datatype [约束] [comment '注解内容']
[, field datatype [约束] [comment '注解内容']] ...
) [engine 存储引擎] [character set 字符集] [collate 排序规则];
- [ ] 中可以不写;
- field 列名;
- datatype 数据类型;
- temporary 表示创建的是临时表
- if not exists 如果表不存在则创建表;
知道了表的创建规则,我们此时就能创建一张学生表来进行测试:
create table if not exists student (
id int comment '学号',
name varchar(20) comment '姓名',
gender varchar(10) comment '性别'
)charset utf8mb4;
此时 , 一张空的学生表已经创建好了;注意: 当我们没有写 if not eixsts的时候,再一次创建表的时候,就会报错;
我们可以用 desc 来查看表的结构;
desc+表名;
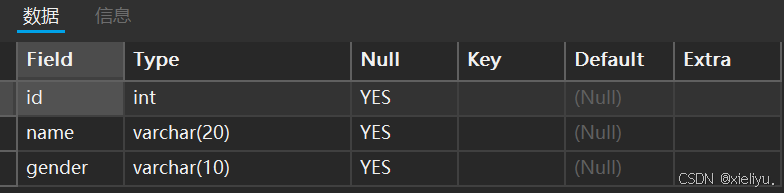
这时候我们看的这个结构是对 每一列 而不是每一行;
我们可以理解为: excel 表格中的列;
当我们后续创建表,时间太久忘记表名,或是第一次操作数据库时,可以用下面语句查看所有数据表;
show tables;

1.2 修改表
语法 :
alter table tbl_name [alter_option [, alter_option] ...];
alter_option: {
table_options
| add [column] col_name column_definition [first | after col_name]
| modify [column] col_name column_definition [first | after col_name]
| drop [column] col_name
| rename column old_col_name to new_col_name
| rename [to | as] new_tbl_name
- col_name 代表字段名;
- column_definition 定义的列名以及类型;
- add 插入新的列;
- modify 修改表中的列;
- drop 删除字段,后面跟字段名;
- rename column 重命名表中现有的列;
- rename 重命名当前的表;
使用示例 :
原表如下 :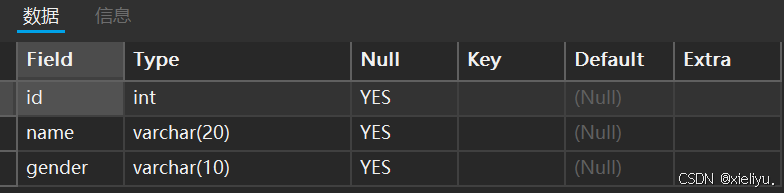
add 添加 :
例如: 此时需要向gender(性别)后面添加年龄这一列:
alter table student add age int comment '年龄';
查看表结构: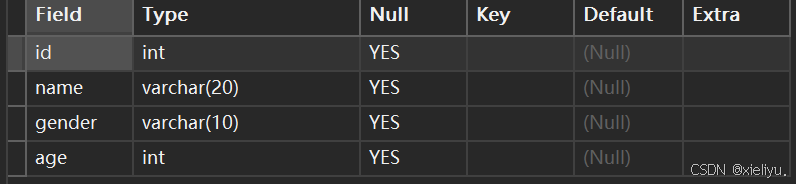
我们可以看见,我们已经成功插入年龄这一字段;
注意:MySQL中add方法如果不指定插入位置默认是插入在最后;
当然我们也可以指定位置进行插入: after 字段 ; 表示插入位置在某一字段之后;
first 表示插入位置在头位置;
如:我们指定插入在最前 :
alter table student add age int comment '年龄' first;
此时age就插入在最前;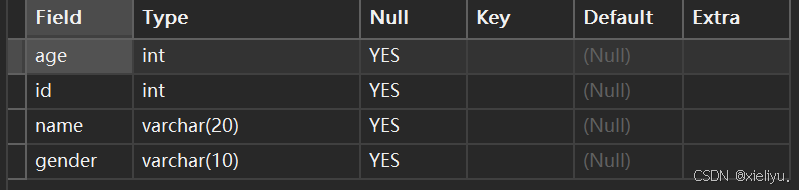
再如 :我们指定插入在name之后:
alter table student add age int comment '年龄' after name;
我们也能够看见成功插入到name之后的字段;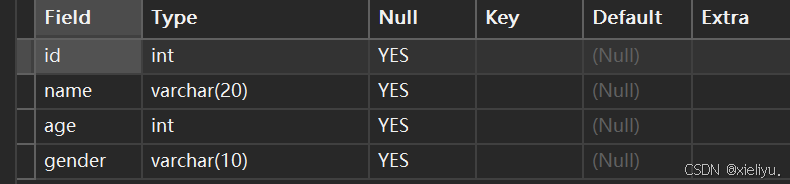
注意:
同一个字段不能够插入多次否则会报错
modify 修改:
例如:我们将字段中gender(性别的存储的最大字符大小改为20);
alter table student modify gender varchar(20);
此时能成功看见性别的最大存储量变为了20;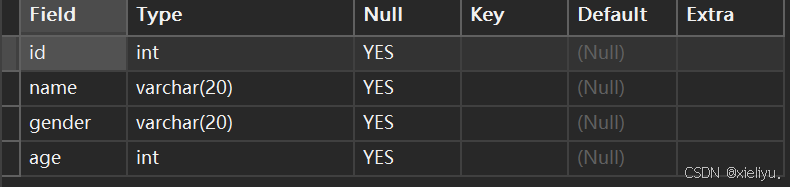
rename column 重命名表
示例:我们需要将id的名字改变为studentId;
alter table student rename column id to studentId;
能看见id成功被修改完成;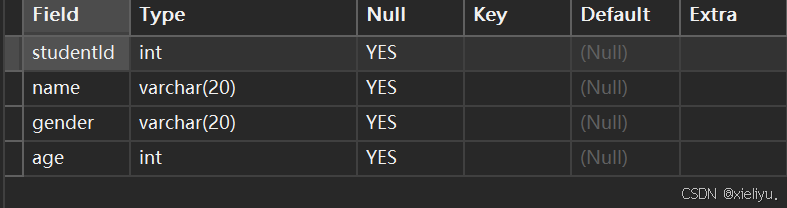
为了方便后续的操作我们重新给学号改回为id;
rename 修改表名字:
示例: 将student表名字改为emp;
alter table student rename to emp;
结果:成功完成修改操作;
drop 删除字段
示例:我们需要将student表中age字段删除掉;
alter table student drop age;
结果:
注意: 关于删除的操作都是危险的操作,如果不小心删除了一个字段,有可能删除了10几万个数据,所以我们在以后进行删除操作的时候 一定小心再小心;
1.3 删除表
语法:
drop [temporary] table [if exists] tbl_name [, tbl_name] ...
- temporary :表示一个临时表;
- tbl_name : 表名;
drop 删除
例如:此时我们需要删除我们刚才创建的临时表;
drop table if exists student;
结果:
此时我们数据库中没有任何一张表;
注意: 关于删除的操作都是危险的操作,如果不小心删除了一个字段,有可能删除了10几万个数据乃至更多的数据,所以我们在以后进行删除操作的时候一定小心再小心;
2. CURD
CURD 是数据库最核心的 4 种基础操作:
- C = Create:新增(INSERT)
- U = Update:修改(UPDATE)
- R = Retrieve:查询(SELECT)
- D = Delete:删除(DELETE)
create table if not exists student (
id int comment '学号',
name varchar(20) comment '姓名',
gender varchar(10) comment '性别',
age int comment '年龄'
)charset utf8mb4;
后续插入以student表为准;
2.1 增加数据
语法:
insert [into] table_name
[(column [, column] ...)]
values
(value_list) [, (value_list)] ...
- [(column [, column] …)]: 可指定列进行插入;
- value_list: 插入的数据值;
示例 : 在student表中进行全列插入学号为:1,姓名为:张三,性别:男,18;这一条数据;
insert into student values (1,'张三','男',18);
结果:
此时,我们看不见我们插入的数据:我们可以用 select* from来进行查询;
注意:select* from 表名 (只建议在我们日常学习中进行使用, 不建议在公司数据库中进行操作,因为公司数据库数据很多,此时进行全列查询,极大可能造成数据库卡顿,造成经济损失
查询时不加限制条件会返回表中所有结果,如果表中的数据量过⼤,会把服务器的资源消耗殆尽在⽣产环境不要使不加限制条件的查询
select* from student;
结果: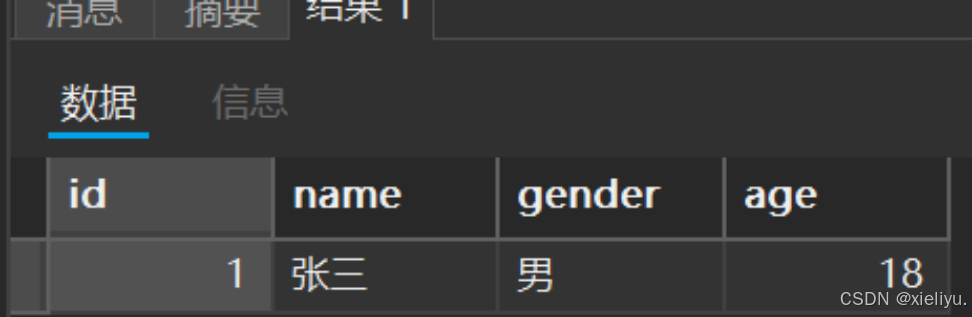
示例二: 同时全列插入多条数据 :
insert into student values (2,'李四','男',18),(3,'小美','女',20),(4,'王五','男',19);
结果: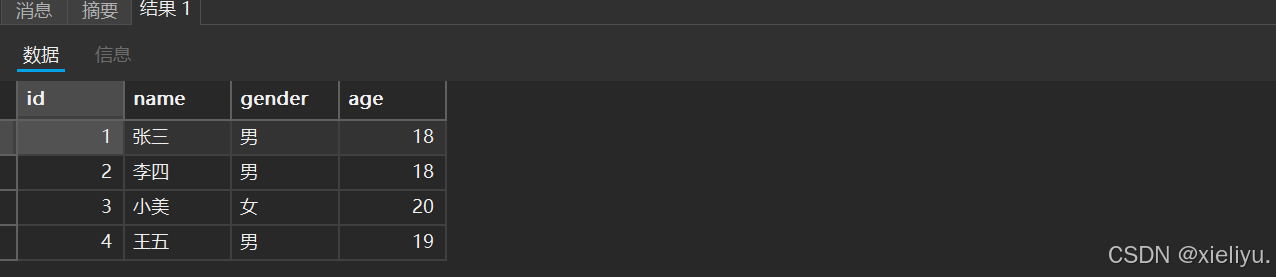
示例三: 除了全列查询,我们也可以指定列进行插入
insert into student(id,name) values (101,'匿名');
结果: 当然指定列进行插入也可以进行多行插入;
当然指定列进行插入也可以进行多行插入;
insert into student(id,name) values (102,'匿名'),(103,'匿名'),(104,'匿名');
结果:
当然,我们也可以将此表的数据插入到另外一张表中;
注意:
插入到另外一张表的类型要一致
创建一张测试表:
create table if not exists test(
id int,
name varchar(20),
gender varchar(10),
age int
);
进行插入:
insert into test (select* from student);
结果:
2.2 查询数据
语法:
select
[distinct]
select_expr [, select_expr] ...
[from table_references]
[where where_condition]
[group by {col_name | expr}, ...]
[having where_condition]
[order by {col_name | expr} [asc | desc], ... ]
[limit {[offset,] row_count | row_count offset offset}]
- select_expr:查询字段、表达式、常量
- table_references:要查询的数据表名称
- where_condition:行级过滤条件,分组之前生效
- group by:按照指定字段分组,一般配合聚合函数使用
- having:分组之后进行条件过滤,只能筛选聚合结果
- order by:对最终结果集排序
- asc:升序(默认,可以省略)
- desc:降序
- limit:分页查询,用来限定返回行数
- 写法 1:limit offset, row_count
- 写法 2:limit row_count offset offset
全列查询:select* from 表名;
select* from student;
结果: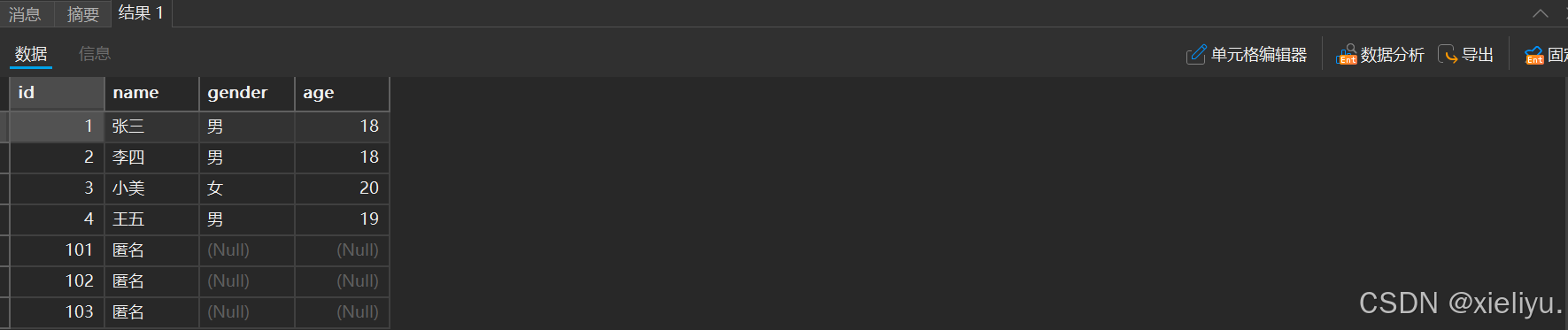
注意:select* from 表名 (只建议在我们日常学习中进行使用, 不建议在公司数据库中进行操作,因为公司数据库数据很多,此时进行全列查询,极大可能造成数据库卡顿,造成经济损失;
例如:指定姓名和年龄进行查询:
select name,age from student;
结果:
此时出现了好几个匿名的,此时我们想要去重查询,可以用distinct;distinct:
例如:
select distinct name,gender,age from student;

此时我们就能够查询到只出现一次的信息了;
当然我们也可以用表达式来进行查询:
此时我们需要重新创建一张成绩表:
create table score (
name varchar(20),
chinese int,
math int,
english int
);
insert into score values ('张三',90,89,70),('李四',60,82,92),('王五',98,65,45);

此时:我们需要查询总成绩;
select name,chinese+math+english as totol from score;
使用as我们可以让我们查询到的信息变为我们自己想要的名字
我们也可以让总分加10;
select name,chinese+math+english+10 as totol from score;
结果:
注意:这里加上10并不会影响我们表中的元素,只是在我们查询到的结果上加上10;where语句:
在说明where语句前,我们先来了解了解sql语句中的比较和关系运算符比较运算符
| 运算符 | 说明 |
|---|---|
| > , >= , < , <= | 大于、大于等于、小于、小于等于 |
| = | 判断相等,对null比较不安全,null = null 结果仍为null |
| <=> | 安全相等,支持null对比,null <=> null 返回true(1) |
| != , <> | 不等于 |
| value between a0 and a1 | 闭区间匹配 [a0,a1],满足 a0 <= value <= a1 返回true;not between 取反 |
| value in (option,…) | 值在列表内返回true,not in 取反 |
| is null | 判断值为null |
| is not null | 判断值不为null |
| like | 模糊匹配:%匹配任意多个字符(含0个),_匹配单个字符;not like 取反 |
sql语句中判断相等是一个等号;具体和c语言和Java有一定的区别;逻辑运算符
| 运算符 | 说明 |
|---|---|
| and | 逻辑与,全部条件为true,结果才为true(1) |
| or | 逻辑或,任意一个条件为true,结果就为true(1) |
| not | 逻辑非,条件为true时,结果变为false(0)&ems`or和and |
在 SQL 中,AND 的优先级高于 OR。这意味着,在没有括号明确指定顺序的情况下,AND 会先被计算,然后才是 OR。这个规则与许多编程语言(如 C、Java)中的逻辑运算符优先级一致。
优先级规则:
and>or- 可以使用括号
()来改变运算顺序,括号内的表达式会优先计算。
示例 1:理解默认优先级
假设我们有一张 score 表,数据如下:
| name | chinese | math | english |
|---|---|---|---|
| 张三 | 90 | 89 | 70 |
| 李四 | 60 | 82 | 92 |
| 王五 | 98 | 65 | 45 |
查询需求: 找出语文成绩大于 80 或者 数学成绩大于 80 并且 英语成绩大于 60 的学生。
如果直接写:
select* from score where chinese > 80 or math > 80 and english > 60;
由于 AND 优先级更高,实际等价于:
select * from score where chinese > 80 or(math > 80 and english > 60);
执行过程:
- 先计算
math > 80 and english > 60:- 李四:math=82>80 且 english=92>60 → 条件成立
- 张三:math=89>80 且 english=70>60 → 条件成立
- 王五:math=65>80 不成立 → 条件不成立
- 再计算
chinese > 80 or(上述结果):- 张三:chinese=90>80 成立 → 最终结果 成立
- 李四:chinese=60>80 不成立,但
math > 80 AND english > 60成立 → 最终结果 成立 - 王五:chinese=98>80 成立 → 最终结果 成立
所以查询结果会返回 张三、李四、王五 三条记录。
示例 2:使用括号改变优先级
如果我们的本意是:(语文成绩大于80 或者 数学成绩大于80) 并且 英语成绩大于60,即两个条件必须同时满足:
- 语文>80 或 数学>80
- 英语>60
那么必须用括号明确:
select* from score where (chinese > 80 or math > 80) and english > 60;
执行过程:
- 先计算括号内
chinese > 80 OR math > 80:- 张三:chinese=90>80 成立
- 李四:math=82>80 成立
- 王五:chinese=98>80 成立
三人都满足括号内条件。
- 再计算
AND english > 60:- 张三:english=70>60 成立 → 最终结果 成立
- 李四:english=92>60 成立 → 最终结果 成立
- 王五:english=45>60 不成立 → 最终结果 不成立
所以查询结果只返回 张三、李四 两条记录。
对比总结:
| 查询语句 | 实际逻辑 | 返回结果 |
|---|---|---|
chinese > 80 or math > 80 and english > 60 |
语文>80 或 (数学>80 且 英语>60) | 张三、李四、王五 |
(chinese > 80 or math > 80) and english > 60 |
(语文>80 或 数学>80) 且 英语>60 | 张三、李四 |
最佳实践:
在编写复杂的 where 条件时,即使你知道优先级规则,也建议显式使用括号来明确意图。这样:
- 提高可读性:让他人(包括未来的自己)一眼看懂逻辑。
- 避免错误:防止因优先级记错导致查询结果与预期不符。
- 便于维护:后续修改条件时,括号能清晰界定组合关系。
回到最初的简单示例:查询语文成绩大于80并且数学成绩大于80的学生
select* from score where chinese > 80 andmath > 80;
这里只有一个 and,不存在优先级混淆问题。查询结果只包含 张三(语文90>80,数学89>80)。
当然除此之外我们还得了解sql语句的执行顺序:行顺序**:
- from:先找到数据表,把整张表的数据加载出来
- where:逐行过滤数据,把符合条件的数据留下,不符合直接舍弃
- group by:对筛选完的数据进行分组
- 聚合函数 (count、sum):统计分组数据
- having:再次过滤分组之后的结果
- select:挑选需要展示的字段,字段别名在这里才生效
- order by:给最终结果排序
- limit:分页截取数据
总结来记:先查表→再过滤→分组统计→二次筛选→起别名→排序→分页;
2.3 修改数据
语法:
update [low_priority] [ignore] table_reference
set assignment [, assignment] ...
[where where_condition]
[order by ...]
[limit row_count]
以成绩表为例子:
| name | chinese | math | english |
|---|---|---|---|
| 张三 | 90 | 89 | 70 |
| 李四 | 60 | 82 | 92 |
| 王五 | 98 | 65 | 45 |
示例1:让所有人数学加上5分;
update score set math = math+5;
结果:
注意:
我们没有加任何条件约束,修改的是整张表的数据;
MySQL中并不像Java和C语言那样能使用+=来进行赋值;
修改操作也是非常危险,稍有不慎可能酿成大祸;
示例2:我们可以指定王五英语加上15分;
update score set english = english+15 where name = '王五';
结果:
2.4 删除数据
语法:
delete from tbl_name [where where_condition] [order by ...] [limit row_count]
注意:
删除操作在数据库中非常危险,删除数据前记得提前备份;
删除时如果不加任何条件,会将表内的数据全被删除掉;
示例:指定名字为李四这一行进行删除;
delete from score where name = '李四';
结果:
示例2:不指定任何字段进行删除;
delete from score;
结果:表中数据全被删除掉了;
额外拓展: 截断法
truncate [table] tbl_name
注意:
此方法删除数据比delete快很多,在工作中慎用!!!
3 高级查询
3.1 排序 order by
语法:
select * from score order by 字段 排序规则;
MySQL语句: 分为desc(降序排序),asc(升序排序);
如果不写任何排序规则,MySQL中默认采用升序排序;
| name | chinese | math | english |
|---|---|---|---|
| 张三 | 90 | 89 | 70 |
| 李四 | 60 | 82 | 92 |
| 王五 | 98 | 65 | 45 |
如果此时我们想计算总分排序:可以使用order by (降序排序)
select name,chinese+math+english as totol from score order by totol asc;
结果:
&em升序排序:
select name,chinese+math+english as totol from score order by totol desc;
结果:
有没有发现:我们排序的时候是使用别名进行排序的?为什么where不可以?
在 SQL 中,order by 子句可以使用 select 列表中定义的别名(如 totol),但 where 子句却不能。这背后的原因与 SQL 语句的执行顺序 密切相关。
为什么 order by 可以使用别名,而 where 不能?
要理解这个问题,我们需要回顾一下之前提到的 SQL 执行顺序:
- from:先找到数据表,把整张表的数据加载出来
- where:逐行过滤数据,把符合条件的数据留下,不符合直接舍弃
- group by:对筛选完的数据进行分组
- 聚合函数 (count、sum):统计分组数据
- having:再次过滤分组之后的结果
- select:挑选需要展示的字段,字段别名在这里才生效
- order by:给最终结果排序
- limit:分页截取数据
总结来记:先查表→再过滤→分组统计→二次筛选→起别名→排序→分页;
关键点在于:where子句在select之前执行,而order by在select之后执行。
详细解释:
1. where 子句的执行时机
当数据库执行 WHERE 子句时,它需要根据条件逐行过滤数据。此时,SELECT 列表中的表达式(如 chinese+math+english)还没有被计算,更没有被赋予别名。数据库引擎根本不知道 totol 这个别名代表什么。
尝试在 where 中使用别名会导致错误:
-- 错误示例:WHERE 子句中使用别名
select name, chinese+math+english as totol
from score
where totol > 200; -- 这里会报错:Unknown column 'totol' in 'where clause'
2. order by 子句的执行时机
order by 是在 select 执行之后才处理的。此时,表达式已经计算完毕,别名也已经分配,所以 order by 可以引用这些别名。
正确示例:
-- 正确:order by 可以使用别名
select name, chinese+math+english as totol
from score
order by totol desc; -- 这里可以正常使用 totol 别名
解决方案:如何在 where 中实现类似功能?
如果需要在过滤条件中使用计算后的值,有几种方法:
方法1:重复表达式
最直接的方法是在 where 子句中重复计算表达式:
-- 在 where中重复表达式
select name, chinese+math+english as totol
from score
where chinese+math+english > 200
order by totol desc;
方法2:使用子查询
将计算和别名定义放在子查询中,然后在外部查询的 WHERE 中使用别名:
-- 使用子查询,在外部 where中使用别名
select * from (
select name, chinese+math+english as totol
from score
) as temp_table
where totol > 200
order by totol desc;
方法3:使用 having(仅适用于分组后过滤)
如果涉及分组和聚合,可以在 having 子句中使用别名,因为 having 在 select 之后执行:
-- having可以使用 select中的别名
select name, avg(chinese+math+english) as avg_score
from score
group by name
having avg_score > 80; -- HAVING 可以使用 avg_score 别名
实际示例对比
让我们通过一个完整的示例来加深理解。假设我们有以下 score 表数据:
| name | chinese | math | english |
|---|---|---|---|
| 张三 | 90 | 89 | 70 |
| 李四 | 60 | 82 | 92 |
| 王五 | 98 | 65 | 45 |
需求: 查询总分大于 200 的学生,并按总分降序排列。
错误写法(WHERE 中使用别名):
-- 这会报错:Unknown column 'totol' in 'where clause'
select name, chinese+math+english as totol
from score
where totol > 200
order by totol desc;
正确写法1(where中重复表达式):
select name, chinese+math+english as totol
from score
where chinese+math+english > 200
order by totol desc;
结果:
| name | totol |
|---|---|
| 张三 | 249 |
| 李四 | 234 |
正确写法2(使用子查询):
select * from (
select name, chinese+math+english as totol
from score
) as temp_table
where totol > 200
order by totol desc;
结果: 同上
总结
理解 SQL 执行顺序是写出正确查询的关键:
where在select之前执行:此时别名还未定义,所以不能使用。order by在select之后执行:此时表达式已计算,别名已定义,所以可以使用。having在select之后执行:分组后的过滤可以使用别名。order by在select之前执行:分组时也不能使用别名(除非是 MySQL 的扩展特性)。
记住这个简单的口诀:“先过滤,后选择,再排序”。where 负责过滤(先),select 负责选择并计算别名(中),order by 负责排序(后)。掌握了这个执行顺序,就能避免很多常见的 SQL 错误,写出更高效、更准确的查询语句。
3.2 模糊查询
语法:
select * from 表名 where 字段 like '匹配内容';
我们以 score 表为基础,并添加一些包含“孙”字的姓名数据作为示例:
| name | chinese | math | english |
|---|---|---|---|
| 张三 | 90 | 89 | 70 |
| 李四 | 60 | 82 | 92 |
| 王五 | 98 | 65 | 45 |
| 孙悟空 | null | null | null |
| 行者孙 | null | null | null |
| 孙行者 | null | null | null |
| 孙 | null | null | null |
在使用 like 进行模糊查询之前,我们需要先了解两个核心的通配符:% 和 _。
%:匹配任意多个字符(包括零个字符)。_:匹配任意单个字符。
例如,我们想要查询姓名中包含“孙”字的所有记录。这时,我们需要在“孙”的左右两侧都加上 %,写成 '%孙%'。这个模式表示:只要姓名中任意位置出现“孙”字,就会被匹配到。
如果只在“孙”的左侧加上 %,写成 '%孙',那么它只会匹配以“孙”结尾的姓名。例如,'行者孙' 会被匹配到,但 '孙悟空' 和 '孙行者' 则不会,因为它们不是以“孙”结尾的。
同理,如果只在“孙”的右侧加上 %,写成 '孙%',那么它只会匹配以“孙”开头的姓名。例如,'孙悟空' 和 '孙行者' 会被匹配到,但 '行者孙' 则不会。
下面我们通过具体的 SQL 示例来演示不同通配符模式的效果:
1. 查询包含“孙”字的记录(任意位置)
-- 匹配所有包含“孙”字的姓名
select * from score where name like '%孙%';
查询结果:
2. 查询以“孙”开头的记录
-- 匹配所有以“孙”开头的姓名
select * from score where name like '孙%';
查询结果:
3. 查询以“孙”结尾的记录
-- 匹配所有以“孙”结尾的姓名
select * from score where name like '%孙';
查询结果:
4. 使用 _ 匹配单个字符
_ 通配符用于匹配恰好一个任意字符。例如,我们想查询名字为三个字且第二个字是“行”的所有记录:
-- 匹配格式为“_行_”的姓名(三个字,中间是“行”)
select * from score where name like '_行_';
查询结果:
这个查询会匹配到 '孙行者',因为:
- 第一个
_匹配了“孙” - “行”字精确匹配
- 第二个
_匹配了“者”
而 '孙悟空' 不会被匹配,因为它的第三个字是“空”而不是“者”;'行者孙' 也不会被匹配,因为它的第二个字是“者”而不是“行”。
5. 组合使用 % 和 _
我们可以将 % 和 _ 组合使用,实现更复杂的匹配模式。例如,查询名字以“孙”开头且至少包含三个字符的记录:
-- 匹配以“孙”开头且至少有三个字符的姓名
select * from score where name like '孙__%';
查询结果:
这个模式 '孙__%' 的含义是:
'孙':必须以“孙”开头__:后面必须紧跟至少两个字符(两个_)%:后面可以跟任意多个字符(包括零个)
所以它匹配了 '孙悟空'(三个字)和 '孙行者'(三个字),但没有匹配 '孙'(只有一个字)。
6. 使用 NOT LIKE 进行反向匹配
如果我们想查询不包含“孙”字的记录,可以使用 NOT LIKE:
-- 查询姓名中不包含“孙”字的记录
select * from score where name not like '%孙%';
查询结果:
注意事项:
-
敏感性:在 MySQL 中,
LIKE默认是不区分大小写的,但这一行为可能因数据库的字符集和校对规则(collation)设置而异。在生产环境中,如果需要进行大小写敏感的匹配,可以考虑使用BINARY关键字或调整表的校对规则。 -
性能考虑:以
%开头的模糊查询(如'%孙%')通常无法使用索引,会导致全表扫描。当数据量较大时,这种查询可能会比较慢。如果可能,尽量使用以确定字符开头的模式(如'孙%'),这样可以利用索引提高查询效率。 -
转义特殊字符:如果需要在模式中匹配
%或_字符本身,需要使用转义字符。在 MySQL 中,默认的转义字符是反斜杠\。例如,要查找包含'50%'的字符串,可以写成'%50\\%%'(第一个%是通配符,\\%表示字面量的百分号)。 -
空字符串匹配:
'%'会匹配所有记录,包括空字符串。而'_'则要求必须有一个字符,所以不会匹配空字符串。
3.3 分页查询
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 num 条结果
select ... from table_name [where ...] [order by ...] limit num;
-- 从 start 开始,筛选 num 条结果
select ... from table_name [where ...] [order by ...] limit start, num;
-- 从 start 开始,筛选 num 条结果,比第二种用法更明确,建议使用
select ... from table_name [where ...] [order by ...] limit num offset start;
- start :下标起始位置;
- num : 一页展现的数据;
| name | chinese | math | english |
|---|---|---|---|
| 张三 | 90 | 89 | 70 |
| 李四 | 60 | 82 | 92 |
| 王五 | 98 | 65 | 45 |
-- 写法一:LIMIT offset, row_count
select* from score limit 1,2;
-- 写法二:LIMIT row_count OFFSET offset
select* from score limit 2 offset 1;
以上两种写法完全等价,执行结果相同:
注意: 如果 LIMIT 子句只跟一个参数,表示从第一条记录开始返回指定数量的数据。例如:
-- 从第 1 条记录开始,返回 1 条数据
select* from score limit 1;
结果:
3.4 分组查询 group by
语法:
select {col_name | expr}, ... , aggregate_function (aggregate_expr)
from table_references
group by {col_name | expr}, ...
[having where_condition]
- col_name | expr :
要查询的列或表达式,必须在据group by 子句中作为分组的依; - aggregate_function :
聚合函数; - aggregate_expr :
聚合函数传⼊的列或表达式,如果列或表达式 不在group by 子句中,必须包含在聚合函数中;
首先:我们可以创建一张表:emp
create table if not exists emp (
name varchar(20) comment '姓名',
role varchar(20) comment '角色',
salary decimal(10,2) comment '薪水'
);
我们在表中随便插入几个数据;
insert into emp values
('张三','牛马',8000.00),('小咩','牛马',10000.00),
('李四','老板',1000000.00),('王五','老板',200000.00),
('小王','服务员',6000.00);
插入信息:
示例:统计每个角色的人数:
select role,count(*) from emp group by role;
结果:
having 子句用于对 group by 分组后的结果进行过滤。它与 where 子句功能相似,但执行时机和适用对象完全不同。
mysql 内置了大量工具函数,包含字符串处理、日期运算、数学计算等。这类函数在开发中按需查阅文档即可,本文只重点讲解核心高频函数,不再逐一罗列。
语法:
select {col_name | expr}, ... , aggregate_function (aggregate_expr)
from table_references
group by {col_name | expr}, ...
[having where_condition]
having 与 where 的核心区别已在上述查询中讲解这里不过多讲解:
通俗理解:
where:像一个“守门员”,在数据进入分组房间之前,就把不符合条件的个人(行)拦在外面。having:像一个“房间管理员”,在数据已经按组(分组)进入房间并统计好之后,再把不符合条件的小组(分组)整个淘汰掉。
示例详解:
继续使用我们创建的 emp 表:
| name | role | salary |
|---|---|---|
| 张三 | 牛马 | 8000.00 |
| 小咩 | 牛马 | 10000.00 |
| 李四 | 老板 | 1000000.00 |
| 王五 | 老板 | 200000.00 |
| 小王 | 服务员 | 6000.00 |
1. 基础分组查询
-- 统计每个角色的平均薪资
select role, avg(salary) as avg_salary
from emp
group by role;
结果:
2. 使用 having 过滤分组结果
假设我们只想查看平均薪资超过 10,000 的角色组。
-- 错误:在 WHERE 中使用聚合函数(会报错)
select role, avg(salary) as avg_salary
from emp
where avg(salary) > 10000 -- 错误!WHERE 不能使用聚合函数
group by role;
-- 正确:使用 having对分组后的聚合结果进行过滤
select role, avg(salary) as avg_salary
from emp
group by role
having avg(salary) > 10000;
结果:
3. where 与 having 结合使用
我们可以先用 where 过滤原始数据,再用 group by 分组,最后用 having 过滤分组结果。
需求: 统计除“服务员”角色外,其他角色中平均薪资超过 8,000 的角色组。
SELECT role, AVG(salary) AS avg_salary
FROM emp
WHERE role != '服务员' -- 1. 先过滤掉“服务员”的原始数据行
GROUP BY role -- 2. 对剩余数据按角色分组
HAVING avg_salary > 8000; -- 3. 再过滤平均薪资 > 8000 的分组
执行过程:
where role != '服务员':过滤掉“小王”这条记录。group by role:将剩余数据按“牛马”和“老板”分组。- 计算每组的平均薪资:“牛马”组 (8000+10000)/2 = 9000,“老板”组 (1000000+200000)/2 = 600000。
having avg_salary > 8000:过滤出平均薪资 > 8000 的组。
结果:
| role | avg_salary |
|---|---|
| 牛马 | 9000.00 |
| 老板 | 600000.00 |
5. 更复杂的 having 条件having 子句的条件可以包含多个聚合函数和逻辑运算符。
-- 查询角色人数大于1且总薪资超过 15000 的角色
select role,
count(*) as person_count,
sum(salary) as total_salary
from emp
group by role
having count(*) > 1 and sum(salary) > 15000;
结果:
总结与最佳实践:
- 执行顺序牢记心:
where→group by→聚合函数→having→select→order by→limit。 - 功能区分要明确:
- 对原始行数据过滤 → 用
where。 - 对分组聚合结果过滤 → 用
having。
- 对原始行数据过滤 → 用
- 别名使用有讲究:
having和order by中可以使用select中定义的别名,where和group by中不能。 - 性能优化小提示:尽可能在
WHERE子句中提前过滤掉不需要的数据,减少group by需要处理的数据量,可以提升查询性能。
通过 having 子句,我们可以对分组后的统计结果进行灵活的筛选,从而得到更精确的分析数据。它是 SQL 数据分析中不可或缺的强大工具。having⼦句
更多推荐


 22
22 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)