
【Python专项】进阶语法-数据容器与文件(2)
·
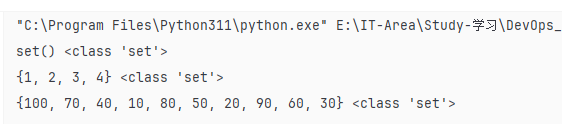
13.集合的定义

# 定义一个空集合
set1 = set()
print(set1,type(set1))
# set 集合:无序且自动去重
set2 = {1,2,2,3,3,3,4,4,4,4}
print(set2,type(set2))
set3 = {10,20,30,40,50,60,70,80,90,100}
print(set3,type(set3))
📝 代码总结
- 核心知识点:集合(Set)的定义与核心特性
- 实现逻辑:空集合必须用
set(),非空用{};打印自动展示无序排列与重复元素过滤 - 关键语法:
set(),{元素} - 功能作用:演示集合的创建规范,直观验证“无序性”与“天生去重”两大数学集合特性
14.集合的增删查方法

"""
add():增加方法
remove():移除方法
in:支持几乎所有的容器类型,如列表、元组、字典(只能判断字典中是否包含某个key)、集合
for:循环遍历集合类型
"""
set1 = set()
set1.add(10)
set1.add(20)
set1.add(30)
print(set1)
set1.remove(30)
print(set1)
if 10 in set1:
print('exists')
else:
print('not exists')
for i in set1:
print(i)
📝 代码总结
- 核心知识点:集合的基础操作与成员检测
- 实现逻辑:使用
.add()/.remove()维护元素;in判断存在性;for无序遍历 - 关键语法:
.add(),.remove(),in,for var in set: - 功能作用:提供集合标准 CRUD 接口,强调
in在集合中的高效哈希查找优势
15.集合求差集

s1 = {'杜皓杰','姜昆沅','鄢语晨'}
print(s1,type(s1))
s2 = {'杜皓杰'}
s3 = s1 - s2
print(s2,type(s2))
print(s3,type(s3))

📝 代码总结
- 核心知识点:集合的数学差集运算
- 实现逻辑:使用
-运算符计算属于第一个集合但不属于第二个集合的元素 - 关键语法:
set1 - set2 - 功能作用:利用集合运算快速解决“求未交集/未完成任务”类业务问题,代码极简且高效
16.文件操作三步走
文件的作用就是为了实现数据的持久化存储
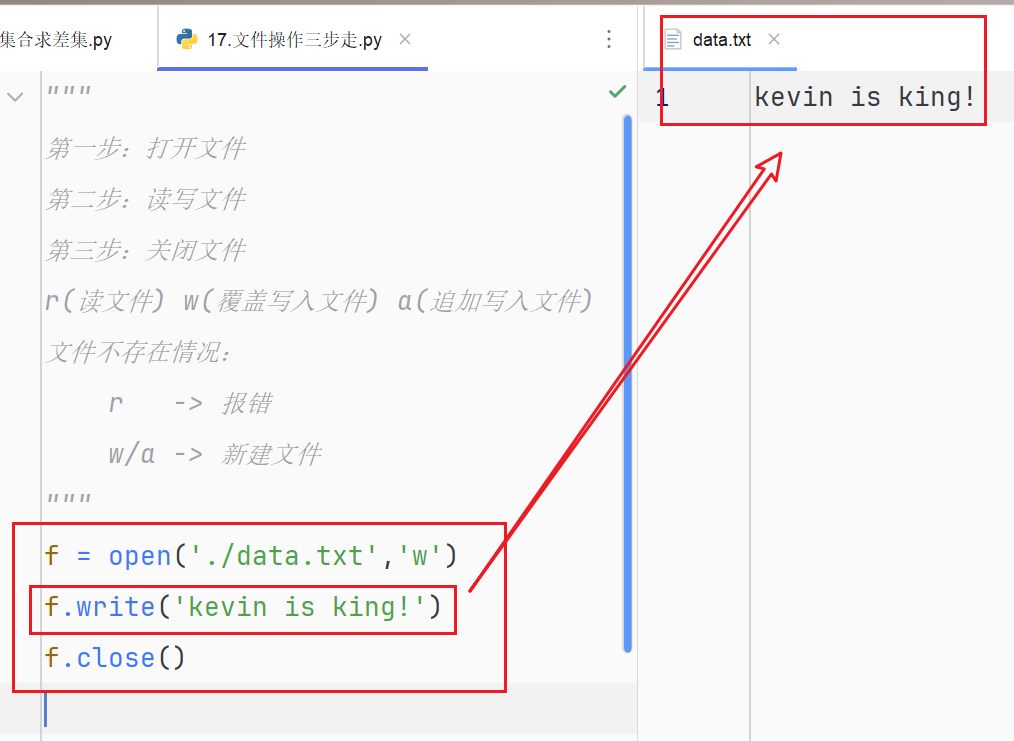
"""
第一步:打开文件
第二步:读写文件
第三步:关闭文件
r(读文件) w(覆盖写入文件) a(追加写入文件)
文件不存在情况:
r -> 报错
w/a -> 新建文件
"""
f = open('./data.txt','w')
f.write('kevin is king!')
f.close()
📝 代码总结
- 核心知识点:文件操作三步骤(打开、读写、关闭)及写入模式详解
- 实现逻辑:以
'w'模式打开data.txt文件,写入字符串'kevin is king!',关闭文件保存更改 - 关键语法:
open(文件路径, 模式)、f.write(内容)、f.close() - 模式对比:
'r':只读模式,文件不存在时报错'w':覆盖写入模式,文件不存在时自动新建'a':追加写入模式,文件不存在时自动新建
- 注意事项:
'w'模式会清空文件原有内容再写入,需谨慎使用 - 功能作用:掌握文件写入的基本操作流程,理解不同打开模式对文件存在性的处理差异
17.文件操作三步走之乱码解决
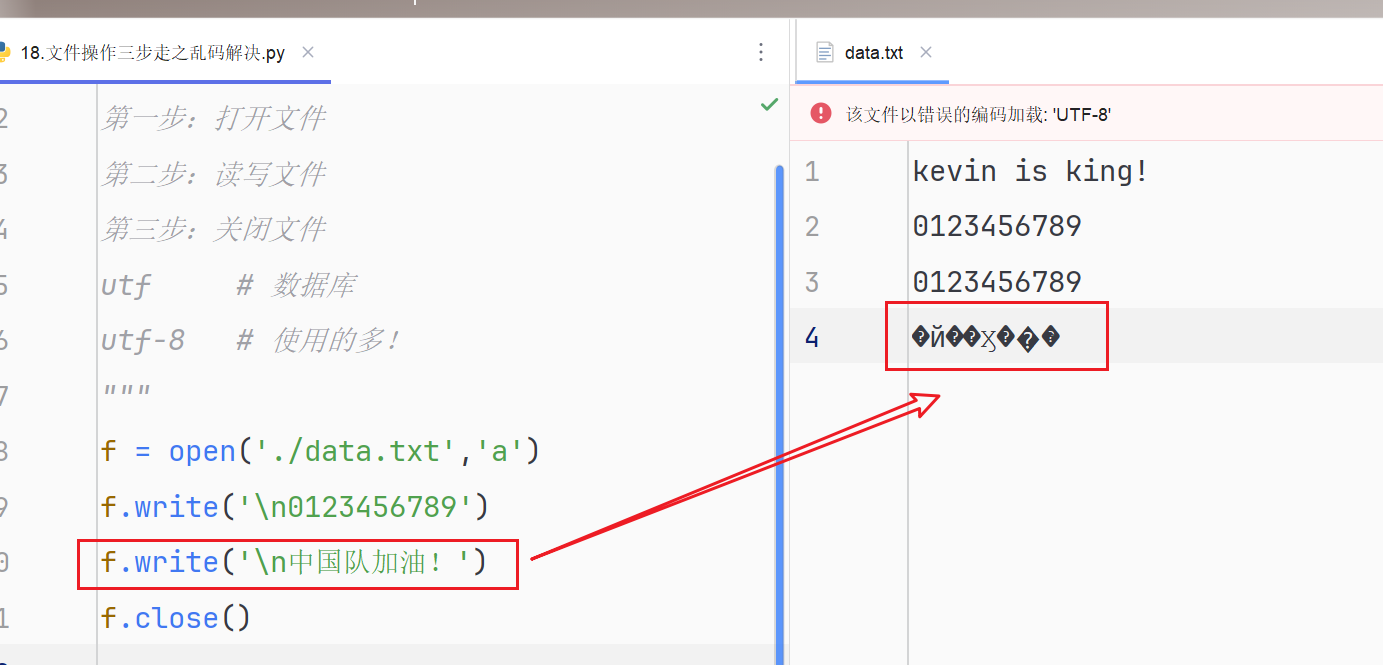
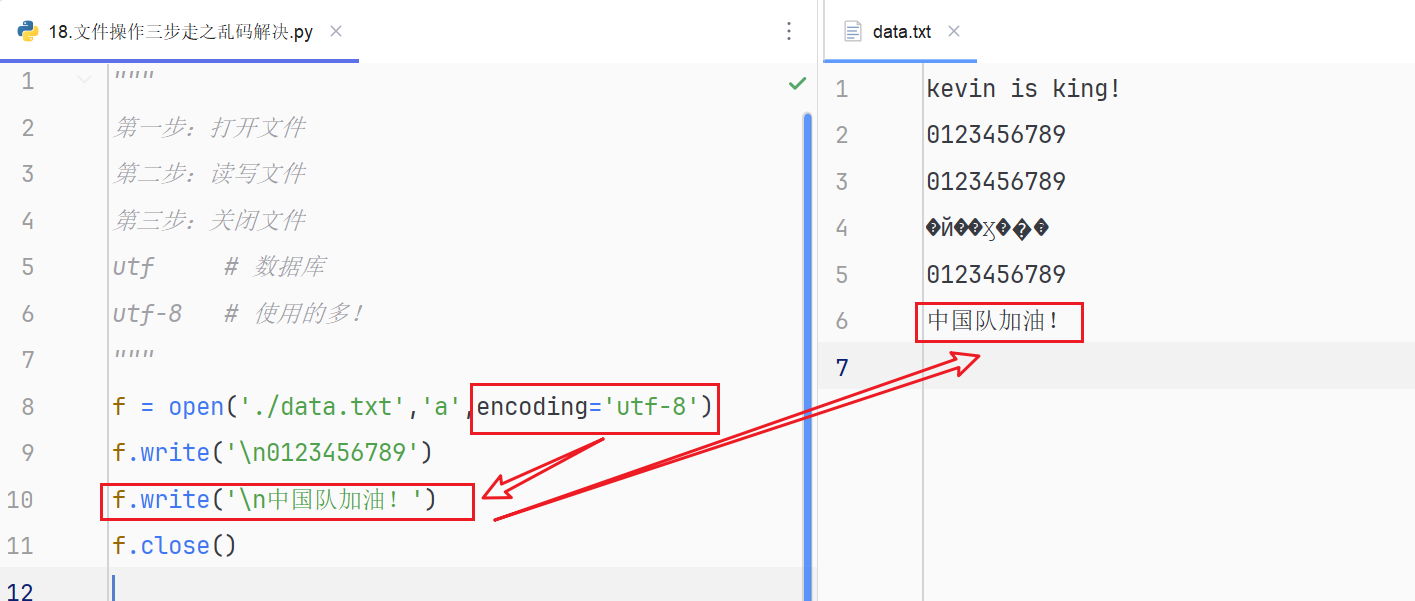
"""
第一步:打开文件
第二步:读写文件
第三步:关闭文件
utf # 数据库
utf-8 # 使用的多!
"""
f = open('./data.txt','a',encoding='utf-8')
f.write('\n0123456789')
f.write('\n中国队加油!')
f.close()
📝 代码总结
- 核心知识点:文件读写编码规范
- 实现逻辑:在
open()中显式声明encoding='utf-8',确保非 ASCII 字符正确序列化 - 关键语法:
open(..., encoding='utf-8') - 功能作用:解决跨平台/多语言环境下的中文乱码问题,强调现代文本文件处理的标准编码实践
18.文件的读取操作f.read(),f.read(n)
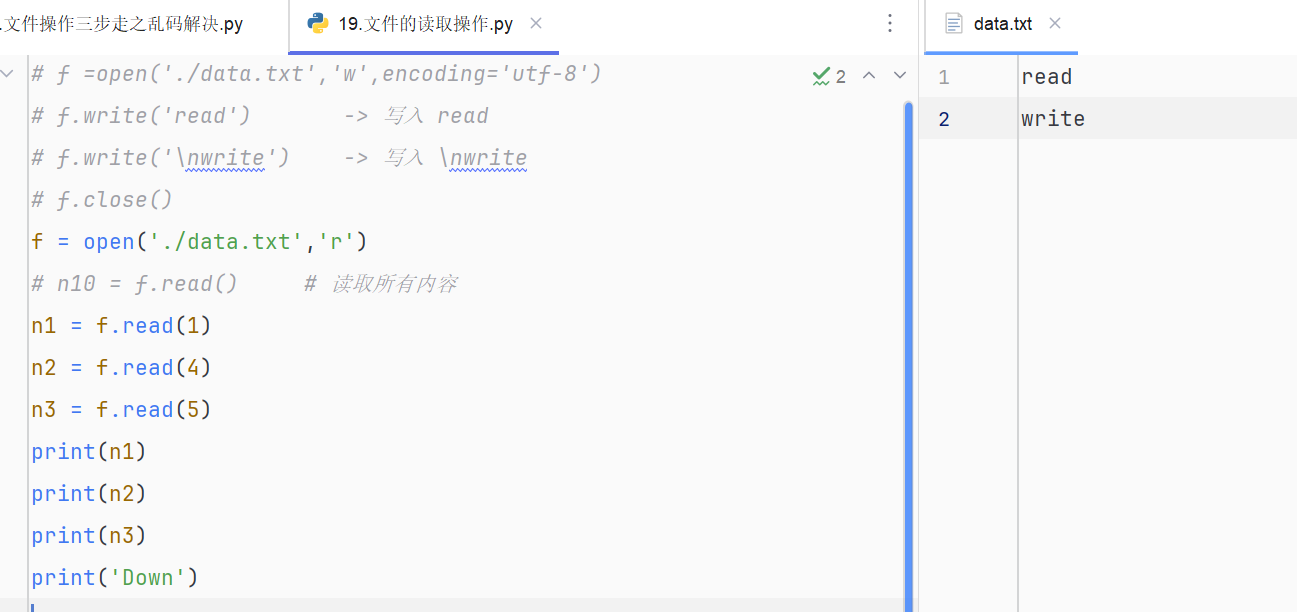
f.read() # 所有
f.read(n) # n-指针
# f =open('./data.txt','w',encoding='utf-8')
# f.write('read') -> 写入 read
# f.write('\nwrite') -> 写入 \nwrite
# f.close()
f = open('./data.txt','r')
# n10 = f.read() # 读取所有内容
n1 = f.read(1)
n2 = f.read(4)
n3 = f.read(5)
print(n1)
print(n2)
print(n3)
print('Down')
初始状态:
[r][e][a][d][\n][w][r][i][t][e]
↑指针在 0
n1 = f.read(1) 后:
[r][e][a][d][\n][w][r][i][t][e]
↑指针移到 1 ← 读走了 'r'
n2 = f.read(4) 后(读4个:e、a、d、\n):
[r][e][a][d][\n][w][r][i][t][e]
↑指针移到 5 ← 读走了 "ead\n"
n3 = f.read(5) 后(读5个:w、r、i、t、e):
[r][e][a][d][\n][w][r][i][t][e]
↑指针移到末尾 ← 读走了 "write"
📝 代码总结
- 核心知识点:文件内容读取策略
- 实现逻辑:调用
.read()无参读全文,传参读指定字符数;注释说明大小文件适用场景 - 关键语法:
.read(),.read(n) - 功能作用:演示按需读取机制,为内存敏感型大文件处理提供分块读取思路
19.文件的读取操作readlines()
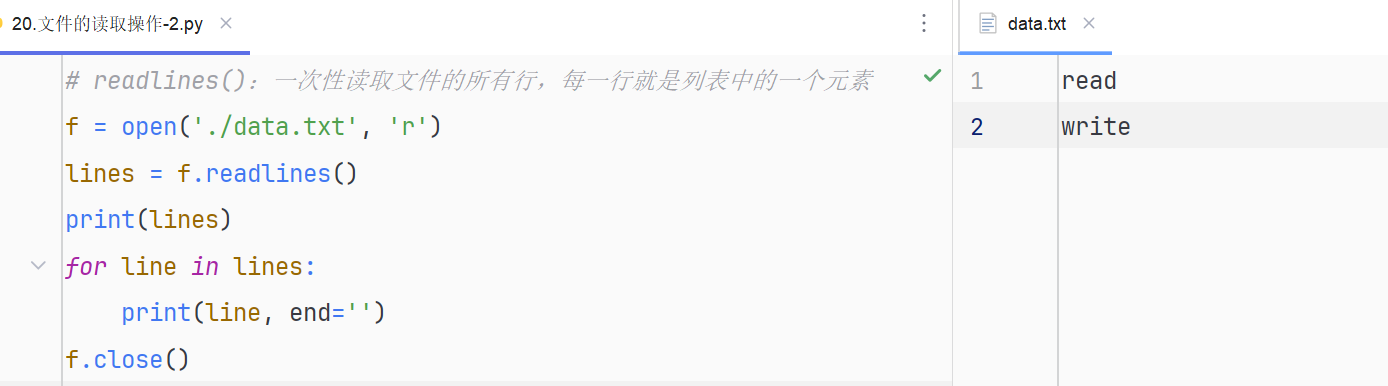
# readlines():一次性读取文件的所有行,每一行就是列表中的一个元素
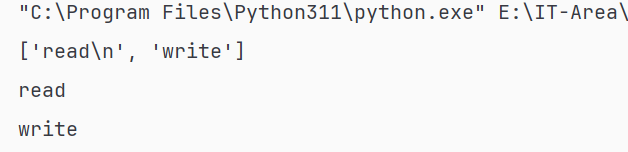
f = open('./data.txt', 'r')
lines = f.readlines()
print(lines)
for line in lines:
print(line, end='')
f.close()
📝 代码总结
- 核心知识点:按行批量读取文件
- 实现逻辑:
.readlines()将全文按换行符切割为字符串列表,随后遍历输出 - 关键语法:
.readlines(),for line in list: - 功能作用:适合小文件结构化处理,将文本直接映射为列表数据结构便于逐行分析
20.文件的读取操作readline()

"""
readline():没有s,代表一次读取文件的一行,适合大文件读取
readline 如果想输出文件的所有行,我们可以使用 while True + readline 方式来进行实现
"""
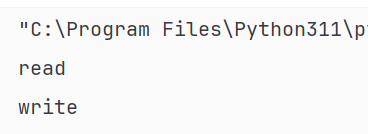
f = open('./data.txt', 'r')
while True:
content = f.readline()
# 添加一个判断,判断读取到的文件内容是否为空,如果为空,则终止循环
# 现有文件有3行,当循环到第4次时,读取不到任何内容,返回为空
# 如果文件读取不到任何内容,则触发if条件,会自动调用break终止while True死循环
if not content:
break
print(content, end='')
f.close()
📝 代码总结
- 核心知识点:流式逐行读取与 Python 布尔隐式转换
- 实现逻辑:
while True循环调用.readline(),利用空字符串转False的特性触发break安全退出 - 关键语法:
.readline(),while True,if not var: break - 功能作用:提供内存友好的大文件读取范式,演示 Python 真值测试在循环控制中的巧妙应用
21.with上下文管理器
"""
传统文件操作:
需要三步,打开文件、读写文件、关闭文件;
有时候,我们可能忘记关闭文件对象,会导致浪费服务器资源。
有没有什么办法可以在文件操作结束后,自动关闭文件,而不需要手工设置?
答:可以使用 with 上下文管理器
"""
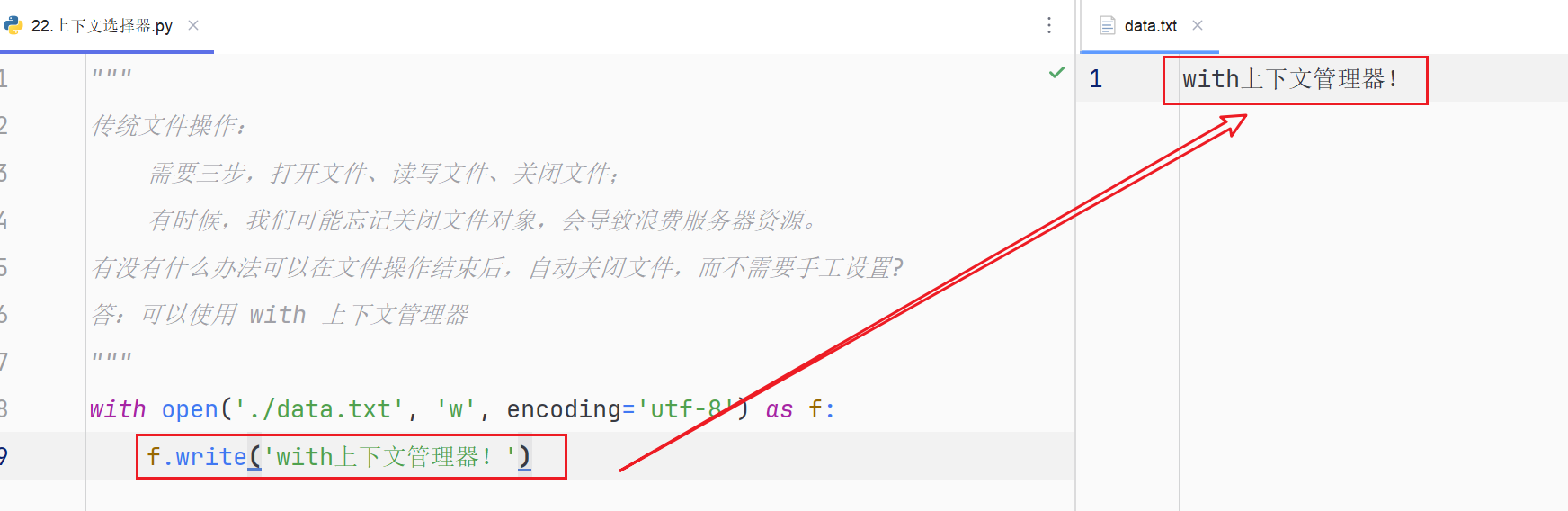
with open('./data.txt', 'w', encoding='utf-8') as f:
f.write('with上下文管理器!')
📝 代码总结
- 核心知识点:
with上下文管理器协议 - 实现逻辑:进入代码块时自动打开文件,退出时(无论正常或异常)自动调用
.close() - 关键语法:
with open(...) as f: - 功能作用:简化文件 I/O 代码结构,彻底杜绝资源泄漏风险,提升代码健壮性与可读性
22.with结合for循环实现遍历文件行操作

with open('./data.txt','r',encoding='utf-8') as f:
for a in f:
print(a, end='')

📝 代码总结
- 核心知识点:文件对象直接迭代与上下文管理器结合
- 实现逻辑:文件对象本身是可迭代器,
for循环逐行 yield 数据,配合with自动管理生命周期 - 关键语法:
with open(...) as f: for line in f: - 功能作用:Python 文件处理的最佳实践,兼顾内存效率、代码简洁性与资源安全性
23.os系统模块的文件操作

"""
os 系统模块 --> 进程管理,文件管理操作
time 时间模块 --> 获取系统时间,时间戳或休眠操作
os.rename(old_file, new_file) --> 重命名文件爱你
time.sleep(xx) --> 休眠xx时间
os.remove('file_name') --> 删除文件
"""
import os
import time
with open('aaa.txt','w',encoding='utf-8') as f:
f.write('中国队--世界杯!\n')
f.write('中国队--宇宙杯!\n')
os.rename('./aaa.txt','test.txt')
time.sleep(10)
os.remove('test.txt')
📝 代码总结
- 核心知识点:操作系统级文件管理与程序休眠
- 实现逻辑:调用
os模块重命名/删除文件,使用time.sleep()暂停执行流 - 关键语法:
os.rename(),os.remove(),time.sleep(seconds) - 功能作用:演示跨平台文件系统操作与执行节奏控制,常用于自动化脚本与临时文件清理
24.os系统模块下的目录操作

import os
if not os.path.exists('./var'):
os.mkdir('./var')
if not os.path.exists('./var/log'):
os.mkdir('./var/log')
print(os.getcwd()) # 查看当前文件路径,cwd 代表当前目录
os.chdir('./var/log')
print(os.getcwd())
os.chdir('../') # 切换着上级目录
print(os.getcwd())
print(os.listdir()) # 查看当前路径及其拥有文件
os.rmdir('log') # 删除空目
os.chdir('../')
print(os.getcwd())

📝 代码总结
- 核心知识点:目录导航、创建、列出与删除
- 实现逻辑:安全检查路径存在性后创建;获取/切换工作目录;列出内容;删除空目录
- 关键语法:
os.path.exists(),os.mkdir(),os.getcwd(),os.chdir(),os.listdir(),os.rmdir() - 功能作用:完整演示文件系统目录树的基础运维操作,强调路径安全校验与相对路径切换
25.os系统模块下的(非空)目录递归删除操作

# 传统删除目录 => os.rmdir("目录名称") => 只能删除空目录,无法删除非空目录
# 类似于 rm -r
import os
import shutil
if os.path.exists('./var'):
shutil.rmtree('./var')
print('目录已成功删除!')

📝 代码总结
- 核心知识点:非空目录的递归删除
- 实现逻辑:使用
shutil.rmtree()突破os.rmdir()仅限空目录的限制,强制删除整个目录树 - 关键语法:
import shutil,shutil.rmtree(path) - 功能作用:提供生产环境中清理复杂目录结构的安全方案,等价于 Linux
rm -rf的 Python 实现
26.综合案例-Nginx访问日志分析
前置nginx_access准备:

127.0.0.1 - - [22/Nov/2024:10:00:00 +0000] "GET /index.html HTTP/1.1" 200 512
192.168.1.1 - - [22/Nov/2024:10:05:00 +0000] "POST /login HTTP/1.1" 404 1024
10.0.0.2 - - [22/Nov/2024:10:10:00 +0000] "GET /about HTTP/1.1" 200 2048
127.0.0.1 - - [22/Nov/2024:10:15:00 +0000] "GET /contact HTTP/1.1" 500 512
192.168.1.1 - - [22/Nov/2024:10:20:00 +0000] "POST /upload HTTP/1.1" 403 102
# 定义两个变量(字典),
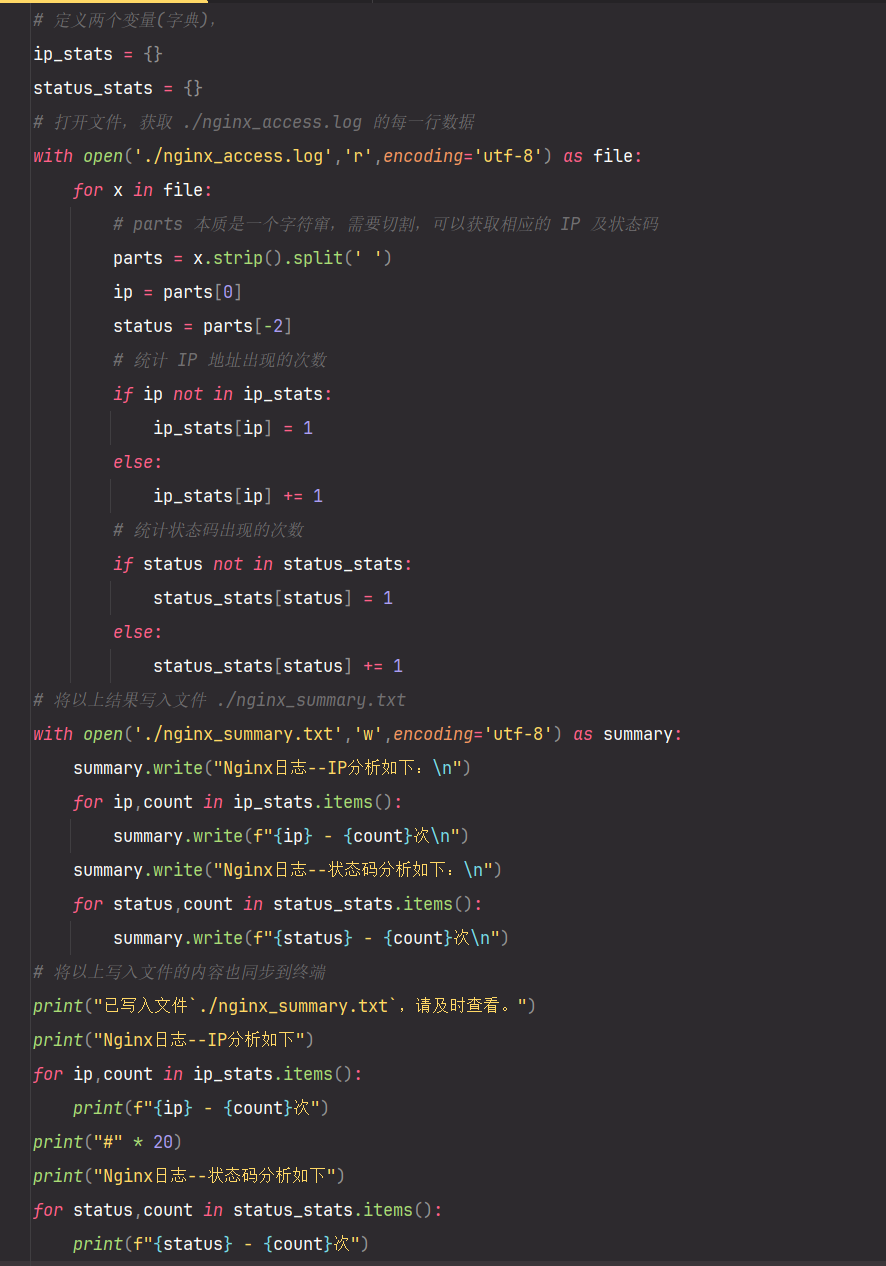
ip_stats = {}
status_stats = {}
# 打开文件,获取 ./nginx_access.log 的每一行数据
with open('./nginx_access.log','r',encoding='utf-8') as file:
for x in file:
# parts 本质是一个字符窜,需要切割,可以获取相应的 IP 及状态码
parts = x.strip().split(' ')
ip = parts[0]
status = parts[-2]
# 统计 IP 地址出现的次数
if ip not in ip_stats:
ip_stats[ip] = 1
else:
ip_stats[ip] += 1
# 统计状态码出现的次数
if status not in status_stats:
status_stats[status] = 1
else:
status_stats[status] += 1
# 将以上结果写入文件 ./nginx_summary.txt
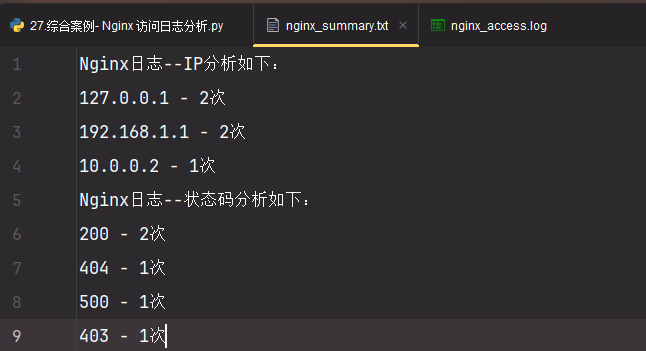
with open('./nginx_summary.txt','w',encoding='utf-8') as summary:
summary.write("Nginx日志--IP分析如下:\n")
for ip,count in ip_stats.items():
summary.write(f"{ip} - {count}次\n")
summary.write("Nginx日志--状态码分析如下:\n")
for status,count in status_stats.items():
summary.write(f"{status} - {count}次\n")
# 将以上写入文件的内容也同步到终端
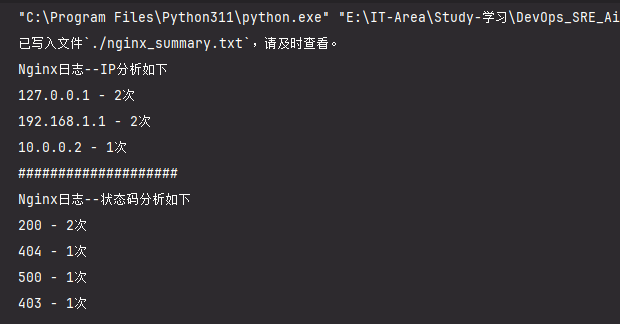
print("已写入文件`./nginx_summary.txt`,请及时查看。")
print("Nginx日志--IP分析如下")
for ip,count in ip_stats.items():
print(f"{ip} - {count}次")
print("#" * 20)
print("Nginx日志--状态码分析如下")
for status,count in status_stats.items():
print(f"{status} - {count}次")
📝 代码总结
- 核心知识点:日志解析、数据聚合与多端输出综合实战
- 实现逻辑:流式读取日志 → 字符串切割提取字段 → 字典频次统计 → 结果写入报告文件并同步打印终端
- 关键语法:
with open迭代,.strip().split(),字典计数逻辑if k not in d: d[k]=1 else: d[k]+=1,.items()解包,f-string 格式化 - 功能作用:完整还原数据清洗与分析 pipeline,串联文件 I/O、字符串处理、哈希统计与格式化输出,具备直接应用于运维监控场景的实战价值
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)