
【课程作业2】Python 自动化科研神器:解放双手,一键批量爬取知网文献与摘要(附完整源码)
【课程作业2】Python 自动化科研神器:解放双手,一键批量爬取知网文献与摘要(附完整源码)
🌟 前言:为什么写这个脚本?
对于刚接触科研的同学来说,写开题报告或文献综述最痛苦的莫过于:在知网上搜了一个关键词,面对几百篇文献,需要挨个点击进入详情页、复制题目、复制作者、复制摘要……枯燥且极其耗时。
为了把有限的精力留给真正的学术思考,今天教大家用 Python 写一个“全自动知网文献采集器”。你只需要输入关键词,它就会模拟真人的操作,自动翻页、自动穿透详情页,把你需要的核心信息全部整整齐齐地扒下来,整理成排版精美的“文献卡片”TXT 文档。
🛠️ 第一步:准备工作:需要安装哪些库?
如果从主页课程作业1过来的同学应该已经安装好了Playwright,可以跳过安装步骤,如果还未安装,可以跟着下面的步骤进行:
这个脚本的核心驱动力是微软开源的自动化测试神器 —— Playwright。它比传统的 Selenium 速度更快,配置也更简单,不需要你去到处找浏览器驱动(ChromeDriver)。
请打开你的终端(CMD 或 Anaconda Prompt),按顺序执行以下两行命令:
1.1 安装 Python 库
pip install playwright -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2 第二步:安装 Playwright 自带的浏览器内核(这一步千万不能漏!)
playwright install chromium
注意:下载浏览器内核可能需要几分钟时间,请耐心等待直到提示 Success。
脚本中用到的其他库(time, random, os)都是 Python 自带的内置库,无需额外安装。
💻第二步: 完整源码(直接复制运行)
新建一个 Python 文件(例如 cnki_spider.py),将以下代码复制进去。
你只需要修改代码开头的 keyword(你想搜的词)和 TARGET_COUNT(你想抓多少篇),其他地方完全不用动!
from playwright.sync_api import sync_playwright
import time
import random
import os
def scrape_cnki_to_card_txt():
# ================= 核心目标配置 =================
keyword = "线结构光 焊缝提取" # 在这里修改你想搜索的关键词
TARGET_COUNT = 200 # 设定的最大抓取数量
# ================================================
# 默认保存在 E 盘的这个文件夹,如果没有会自动创建
save_dir = r"E:\AI_try\ai_code\jiaoben_result"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
txt_file_path = os.path.join(save_dir, f"知网_{keyword.replace(' ', '_')}_{TARGET_COUNT}篇全息卡片.txt")
base_url = "https://kns.cnki.net/kns8s/defaultresult/index"
print("🚀 正在启动自动化浏览器...")
with sync_playwright() as p:
# headless=False 表示显示浏览器界面,这在反爬中非常重要!
browser = p.chromium.launch(headless=False)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/122.0.0.0 Safari/537.36"
)
main_page = context.new_page()
print("🌐 正在打开知网首页...")
main_page.goto(base_url)
time.sleep(3)
print(f"🔍 正在输入检索词: {keyword}")
search_input = main_page.locator('#txt_SearchText, .search-input, input[type="text"]').first
search_input.fill(keyword)
time.sleep(1)
main_page.locator('.search-btn, #btnSearch, .btn-search').first.click()
# 提前打开 TXT 文件准备追加写入
with open(txt_file_path, "w", encoding="utf-8-sig") as f:
f.write(f"【检索关键词】:{keyword}\n")
f.write(f"【抓取上限】:{TARGET_COUNT} 篇\n")
f.write(f"【导出时间】:{time.strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write("=" * 60 + "\n\n")
total_count = 0
page_num = 1
# ================= 自动翻页的大循环 =================
while total_count < TARGET_COUNT:
print(f"\n📄 正在处理第 {page_num} 页的数据...")
try:
main_page.wait_for_selector('table.result-table, .result-table-list', timeout=60000)
time.sleep(3)
except Exception:
print("❌ 等待表格加载超时,或者遇到了无法越过的验证码。")
break
job_rows = main_page.locator('tr').filter(has=main_page.locator('.name a, a.fz14')).all()
if not job_rows:
print("⚠️ 当前页面没有检测到任何文献,可能已经到底了。")
break
print(f"📊 本页共检测到 {len(job_rows)} 条文献,开始提取...")
# 遍历当前页的每一篇文献
for row in job_rows:
if total_count >= TARGET_COUNT:
break
try:
# 1. 提取外层基础信息
title_element = row.locator('.name a, a.fz14').first
title = title_element.inner_text().strip()
href = title_element.get_attribute("href")
full_link = f"https://kns.cnki.net{href}" if href and href.startswith("/") else href
authors = "未知作者"
author_elem = row.locator('.author').first
if author_elem.count() > 0:
authors = author_elem.inner_text().strip()
source_journal = "未知来源"
source_elem = row.locator('.source').first
if source_elem.count() > 0:
source_journal = source_elem.inner_text().strip()
pub_date = "未知时间"
date_elem = row.locator('.date').first
if date_elem.count() > 0:
pub_date = date_elem.inner_text().strip()
database = "未知数据库"
data_elem = row.locator('.data, td:nth-child(6)').first
if data_elem.count() > 0:
database = data_elem.inner_text().strip()
# 2. 隐身穿透详情页,提取摘要
abstract = "摘要提取失败或无摘要"
if full_link.startswith("http"):
try:
print(f" 👉 穿透详情页 [{total_count + 1}/{TARGET_COUNT}]: 《{title[:15]}...》")
detail_page = context.new_page()
detail_page.goto(full_link, timeout=30000)
detail_page.wait_for_selector('#ChDivSummary, .abstract-text', timeout=10000)
abstract_element = detail_page.locator('#ChDivSummary, .abstract-text').first
if abstract_element.count() > 0:
abstract = abstract_element.inner_text().strip()
if abstract.startswith("摘要:") or abstract.startswith("Abstract:"):
abstract = abstract[3:].strip()
except Exception:
print(f" ⚠️ 详情页超时跳过。")
finally:
# 抓完立刻关掉标签页,防止内存爆炸
detail_page.close()
# 3. 文本清洗与格式化输出
title = title.replace("\n", "").strip()
authors = authors.replace("\n", "; ").strip()
source_journal = source_journal.replace("\n", "").strip()
pub_date = pub_date.replace("\n", "").strip()
database = database.replace("\n", "").strip()
abstract = abstract.replace("\n", "").strip()
if title:
card_text = (
f"【论文题目】:{title}\n"
f"【作 者】:{authors}\n"
f"【来 源】:{source_journal}\n"
f"【发表时间】:{pub_date}\n"
f"【数 据 库】:{database}\n"
f"【摘要内容】:{abstract}\n"
f"【文献链接】:{full_link}\n"
f"{'-' * 60}\n\n"
)
f.write(card_text)
total_count += 1
# ==========================================
# ⚠️ 救命机制:绝对不能删除的动态休眠!
# ==========================================
sleep_time = random.uniform(4.5, 8.5)
print(f" ✅ 成功录入!休眠 {sleep_time:.1f} 秒...")
time.sleep(sleep_time)
except Exception as e:
print(f" ❌ 提取出错,跳过该行。报错: {e}")
continue
if total_count >= TARGET_COUNT:
print(f"\n🎯 已达到设定的目标数量 {TARGET_COUNT} 篇!准备收工。")
break
# 4. 自动点击“下一页”
next_page_btn = main_page.locator('a#PageNext, a:has-text("下一页")').first
if next_page_btn.count() > 0 and next_page_btn.is_visible():
print(f"🔄 当前页处理完毕,正在点击下一页...")
next_page_btn.click()
page_num += 1
time.sleep(5)
else:
print(f"\n🛑 没有检测到“下一页”按钮,所有相关文献已抓取完毕!")
break
print(f"\n🎉 完美结束!共成功抓取 {total_count} 篇文献。")
print(f"💾 你的全量文献档案已存至: {txt_file_path}")
browser.close()
if __name__ == '__main__':
scrape_cnki_to_card_txt()
🛑第三步:新手避坑指南(必读)
写爬虫最容易遇到的问题就是被反爬系统拦截。为了保证大家的知网使用安全,这套代码内置了两个强力防御机制,请务必注意:
3.1 遇到验证码不要慌,用手滑!
代码特意设置了 headless=False,也就是运行的时候你会看到一个真实的浏览器弹出来自己动。
如果在搜索或者翻页时,知网突然弹出了一个“滑动拼图”或者“点选汉字”的验证码,代码会卡住等你。这个时候请直接拿鼠标过去把验证码滑开! 只要验证通过,代码就会瞬间复活,继续往下跑。程序最多会留给你 60 秒的时间来操作。
3.2 宁可去泡杯咖啡,也千万别删 time.sleep()!
由于我们要抓取“摘要”,代码会在后台不断地打开详情页、关掉详情页。这在知网服务器看来是非常高频的动作。
代码第 107 行设置了 random.uniform(4.5, 8.5) 的随机休眠时间。抓满 200 篇大约需要 20 分钟左右。强烈警告:千万不要为了贪快把这个休眠时间改成 0! 否则不出 30 篇,你的网络 IP 就会被知网直接拉黑关进小黑屋!
🎁第四步:最终效果展示
运行结束后,去 E:\AI_try\ai_code\jiaoben_result 文件夹下找到生成的 TXT 文件。
打开之后,你将得到一份排版极其舒适、可以直接喂给 ChatGPT/Kimi 帮你写文献综述的“神级资料库”:
【论文题目】:基于线结构光的复合型坡口特征点提取算法
【作 者】:张三; 李四
【来 源】:组合机床与自动化加工技术
【发表时间】:2025-04-18
【数 据 库】:期刊
【摘要内容】:在使用结构光视觉系统提取复合型坡口特征点时,由于坡口表面反射和环境光干扰等...
【文献链接】:https://kns.cnki.net/...
------------------------------------------------------------
运行过程
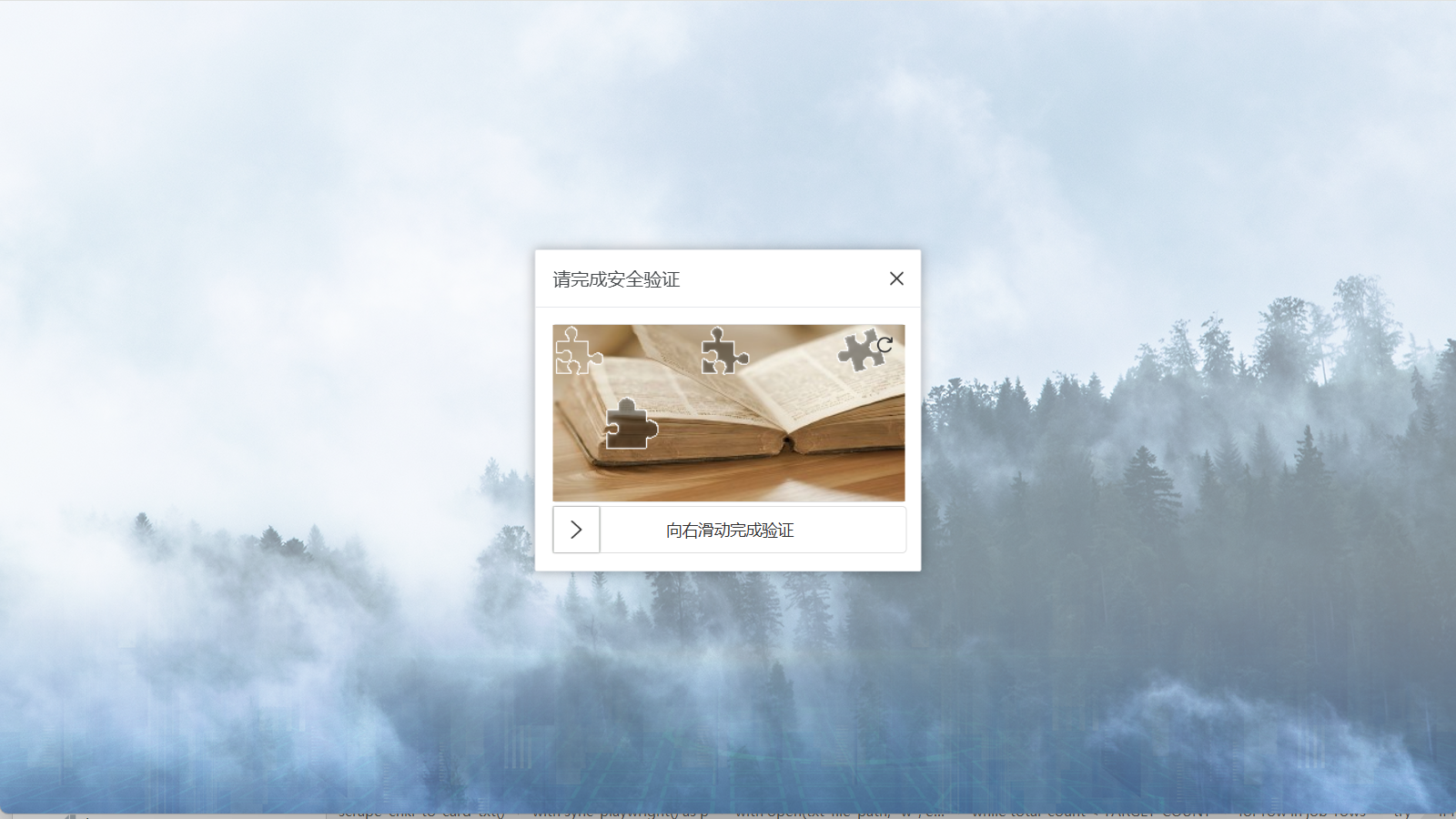
在运行脚本后会弹出知网链接,需要人为拖动验证码进行验证。

pycharm终端会打印是否穿透详情页并录入文献。
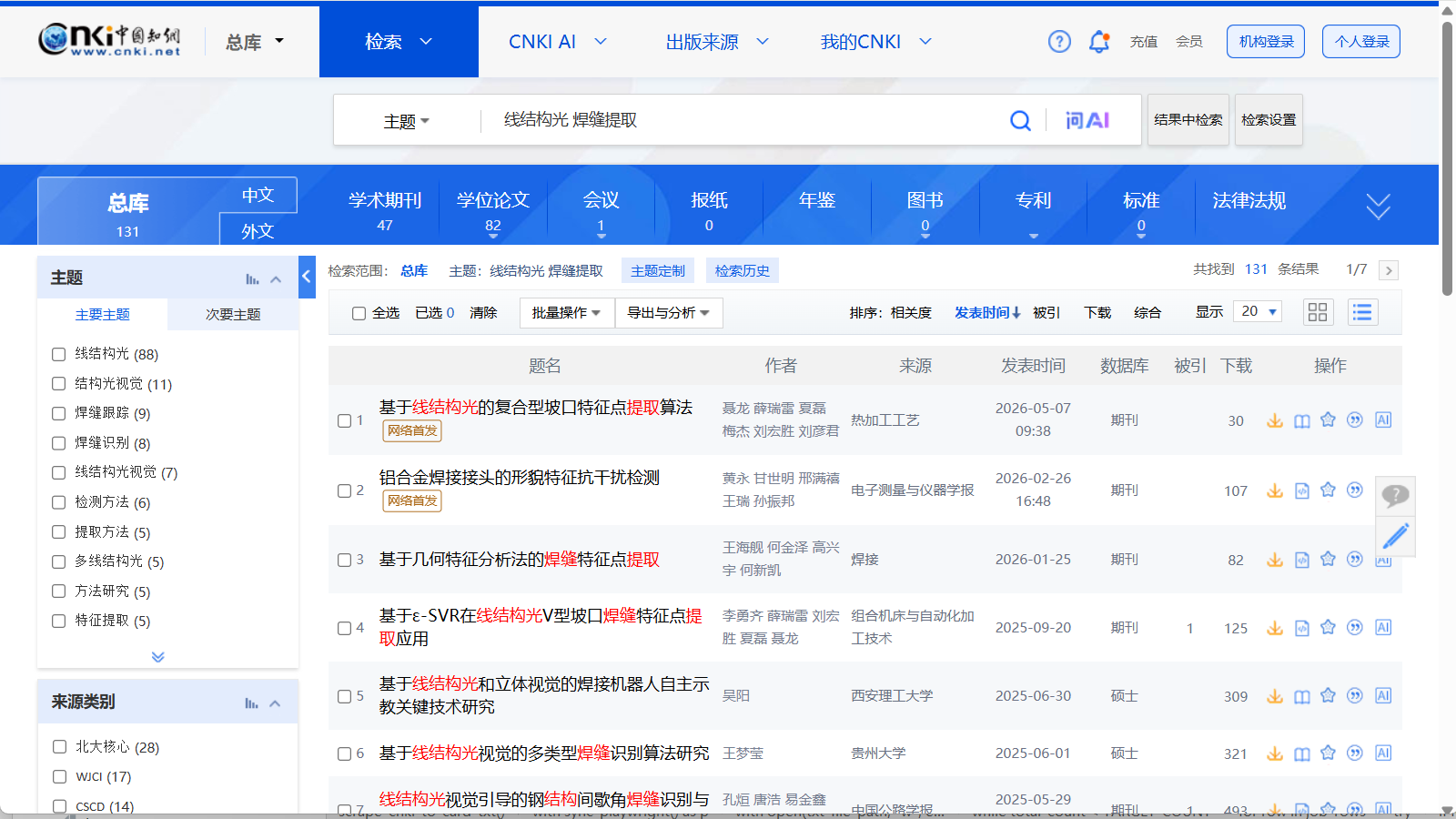
拖动验证后,会根据你输入的关键词跳转到知网搜索界面。
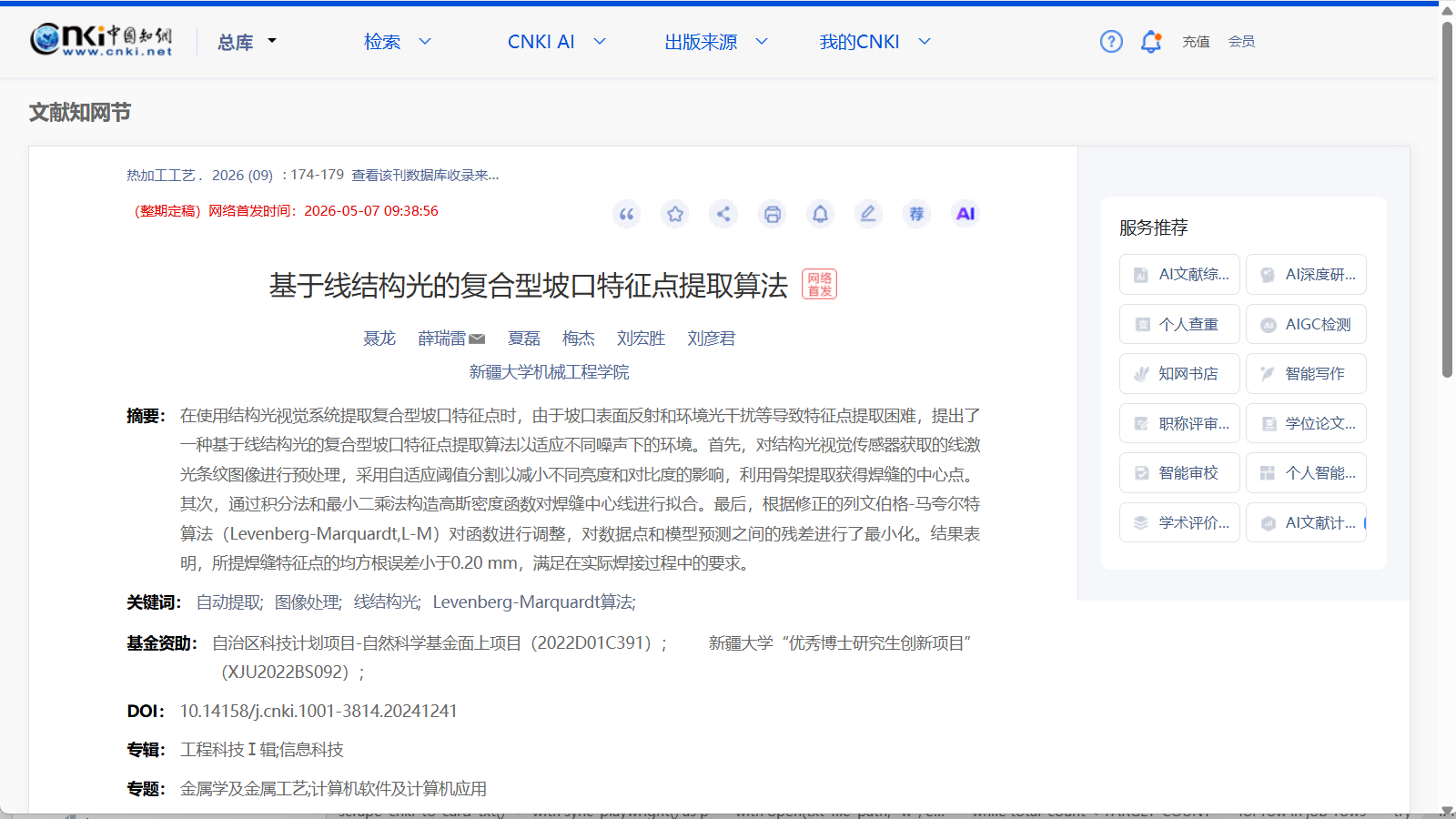
脚本自动逐个进入二级页面获取文章摘要。

最终效果显示,此时可以接入大模型自动导入txt文件进行综述的撰写,或者直接发给你的豆包总结也可,一般而已txt文本格式更有利于数据读取不乱码,但是工作需求不同,也可将最后保存格式设为csv、excel等。
总结
这是一篇针对科研新手的高质量 Python 实战教程,手把手教你如何用 Playwright 编写自动化脚本,一键批量抓取并下载知网文献标题、作者及核心摘要,最终生成适合 AI 辅助阅读的结构化数据,真正实现解放双手、高效科研,并且内置了关键的防封号安全机制。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)