
Java 篇-项目实战-AI 天机学堂(从0到1)-day3
java 篇: 1.基础地基 2.设计原理 3.项目实战
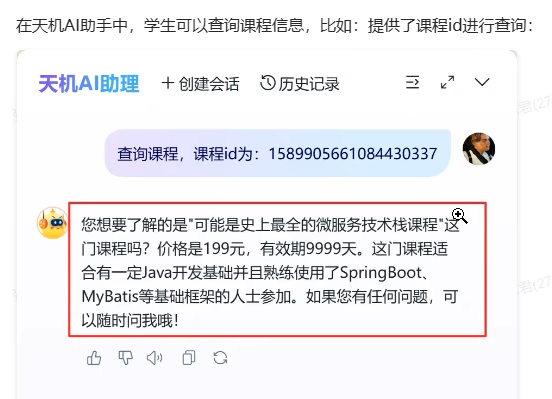
购买课程与知识库-查询课程-实现分析:
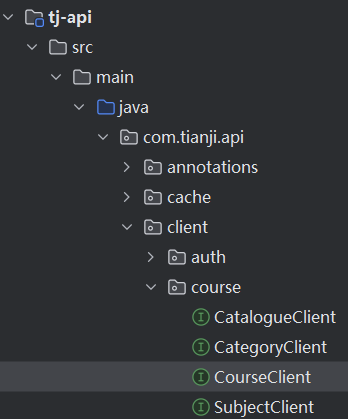
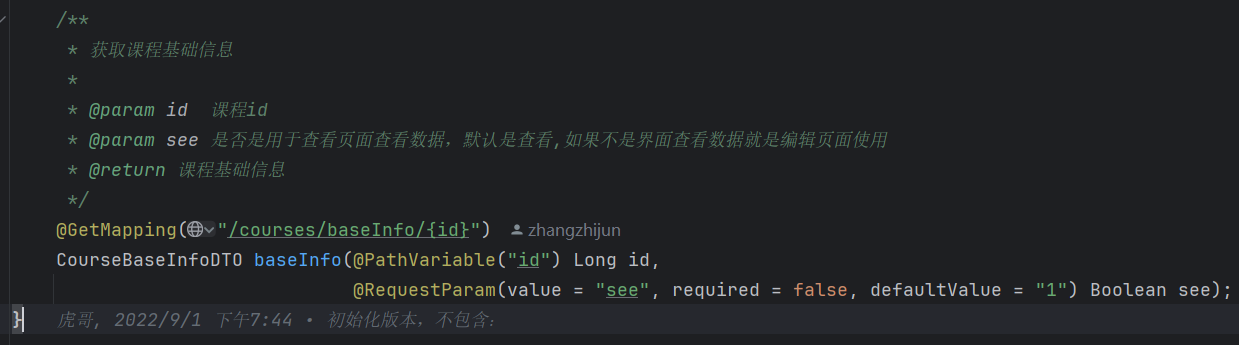
调用这个 OpenFeign 接口:
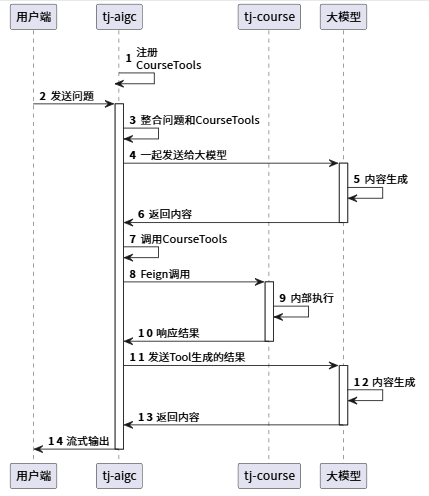
实现流程:
因为如果直接调用返回的数据比较多,并不一定都需要,所以需要定义一个类。
定义 DTO:
package com.tianji.aigc.tools.result;
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.core.util.NumberUtil;
import com.fasterxml.jackson.annotation.JsonPropertyDescription;
import com.tianji.api.dto.course.CourseBaseInfoDTO;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Optional;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class CourseInfo {
@JsonPropertyDescription("课程id")
private Long id;
@JsonPropertyDescription("课程名称")
private String name;
@JsonPropertyDescription("课程价格,单位为元,货币为人民币")
private double price;
@JsonPropertyDescription("课程学习有效期,单位:月")
private Integer validDuration;
@JsonPropertyDescription("适用人群,例如:初学者")
private String usePeople;
@JsonPropertyDescription("课程详细介绍")
private String detail;
_/**_
_ * 将CourseBaseInfoDTO转换为CourseInfo对象_
_ *_
_ * @param courseBaseInfoDTO 课程基础信息数据传输对象(包含原始课程数据)_
_ * @return 转换后的课程信息实体对象(包含格式化后的价格和详情页URL)_
_ */_
_ _public static CourseInfo of(CourseBaseInfoDTO courseBaseInfoDTO) {
if (null == courseBaseInfoDTO) {
return null;
}
// 基础对象属性拷贝(忽略转换错误)
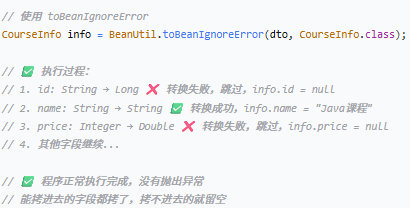
CourseInfo courseInfo = BeanUtil._toBeanIgnoreError_(courseBaseInfoDTO, CourseInfo.class);
// 价格格式化处理:分转元 -> 四舍五入保留两位小数 -> 默认值0.0
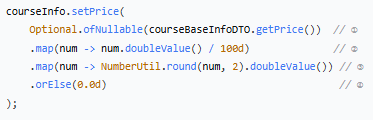
courseInfo.setPrice(Optional._ofNullable_(courseBaseInfoDTO.getPrice())
.map(num -> num.doubleValue() / 100d)
.map(num -> NumberUtil._round_(num, 2).doubleValue())
.orElse(0.0d));
return courseInfo;
}
}![]()
- `public static`:工具方法,可以直接通过类名调用
- `CourseInfo`:返回类型是课程信息实体
- `of`:工厂方法命名惯例,表示"转换/创建"
- 参数:原始的课程基础信息 DTO
基础属性拷贝
![]()
- `BeanUtil.toBeanIgnoreError()`:Hutool 工具方法
- 作用:将 DTO 中同名的属性自动拷贝到 CourseInfo 对象中
- `IgnoreError`:遇到类型不匹配等错误时忽略,不中断执行
- 例如:DTO 的 `name` → CourseInfo 的 `name`,DTO 的 `description` → CourseInfo 的 `description`
价格格式化处理(核心逻辑)
逐步解析:
① `Optional.ofNullable(courseBaseInfoDTO.getPrice())`
- 将价格包装成 Optional,避免空指针
- 如果价格为 `null`,后面会走 `orElse(0.0d)`
② `.map(num -> num.doubleValue() / 100d)`
- 分转元:数据库通常存储分为单位(避免浮点精度问题)
- 例如:`1299 分` → `12.99 元`
- 除以 `100d` 得到元,`d` 是 Java 中表示 double 类型字面量 的后缀。
③ `.map(num -> NumberUtil.round(num, 2).doubleValue())`
- 四舍五入保留两位小数
- `NumberUtil.round()`:Hutool 的精确四舍五入
- 例如:`12.999` → `13.00`
④ `.orElse(0.0d)`
- 如果原始价格为 `null`,默认设置为 `0.0`
定义课程工具类:
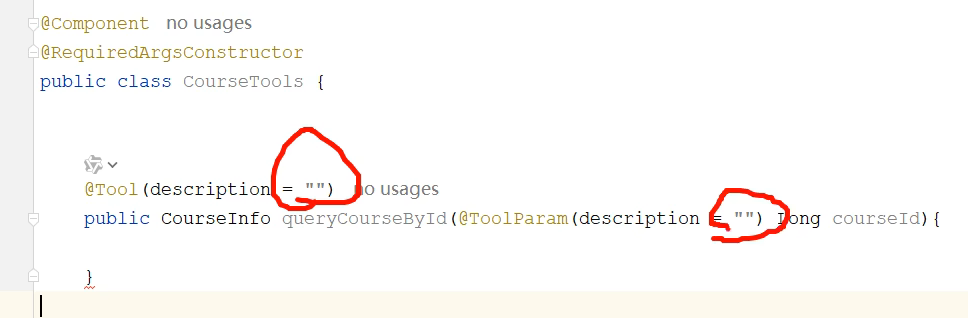
工具描述和工具参数描述放到常量类当中
定义常量类:
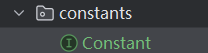
package com.tianji.aigc.constants;
public interface Constant {
interface Tools {
String _QUERY_COURSE_BY_ID _= "根据课程id查询课程详细信息";
}
interface ToolParams {
String _COURSE_ID _= "课程id";
}
}
可以直接都罗列,但不优雅。

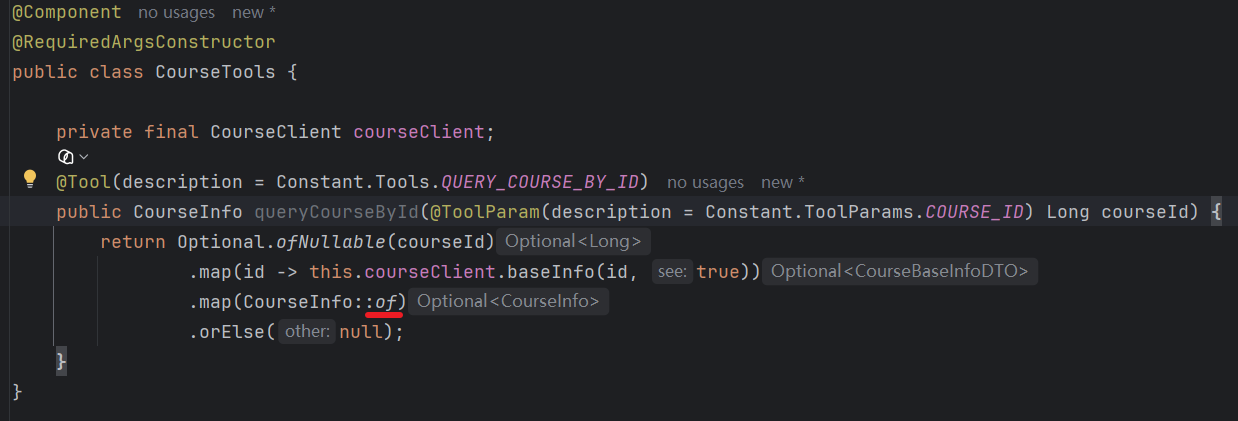
这里就用到了之前的 of 方法,写好之后,就需要在 SpringAIConfig 把它注入进来。
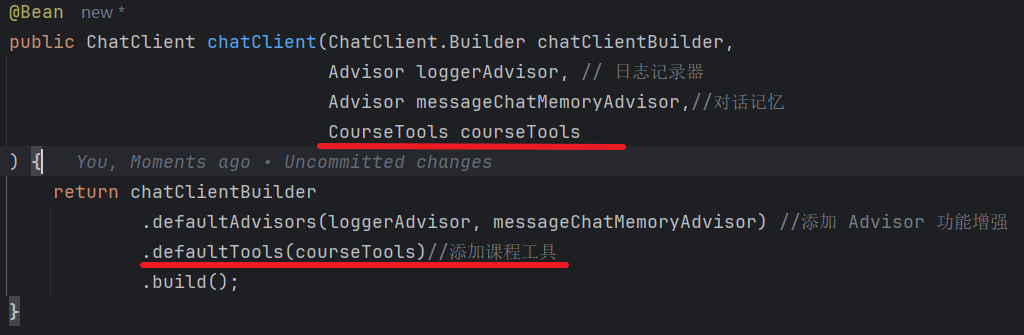
下面进行测试:
在工具里面打个断点:
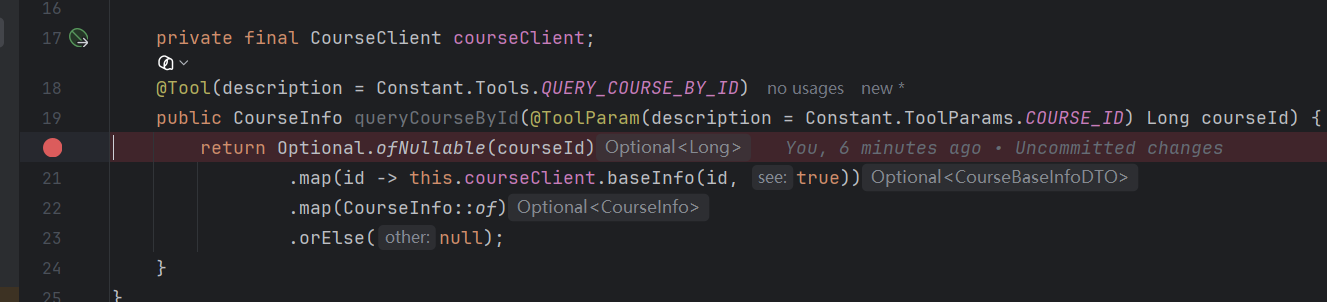
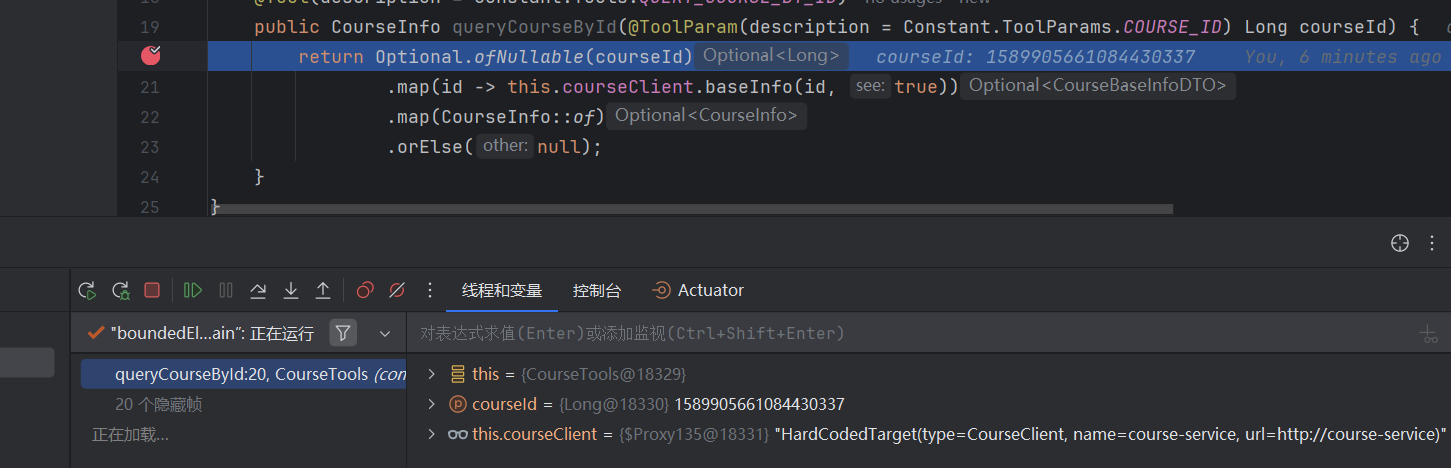
输入内容:查询课程,课程 id 为:1589905661084430337
发现进到这个工具里面了,调用工具成功
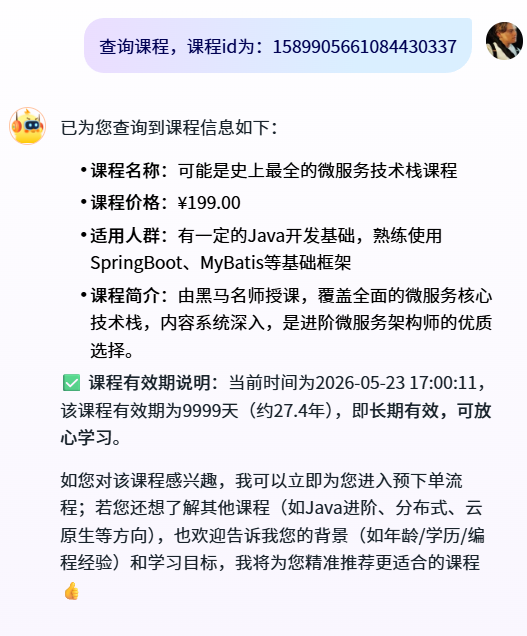
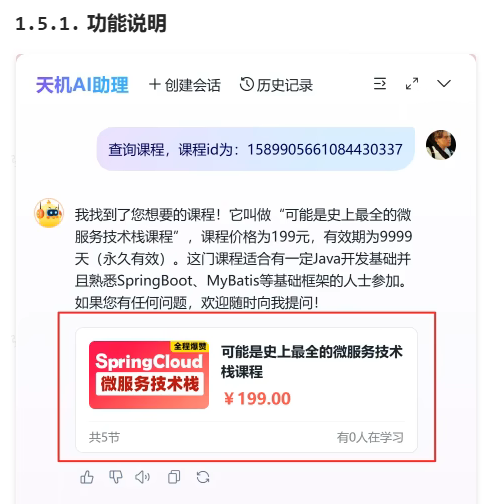
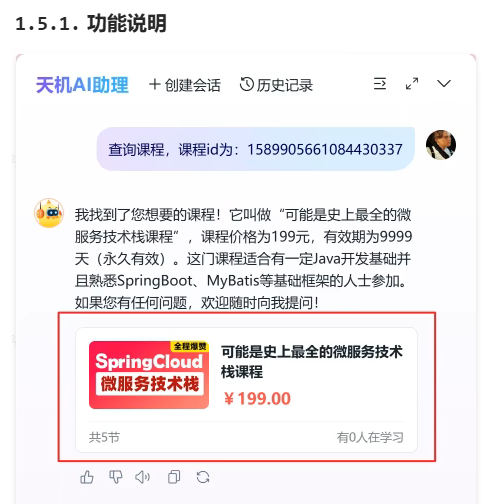
购买课程与知识库-查询课程-课程卡片:
实现思路:
要想实现这个效果,就必须给前端返回相应的参数数据,前端才能展示卡片,但是,上述的内容,都是大模型返回的,都是些文字数据,而我们需要给前端的是格式化的数据,例如 json 数据,该怎么做呢?
实际上,就是在 `Flux` 输出流的最后,做判断,如果调用了工具,拿到工具的结果,追加到输出流的结束标签之前即可。像这样
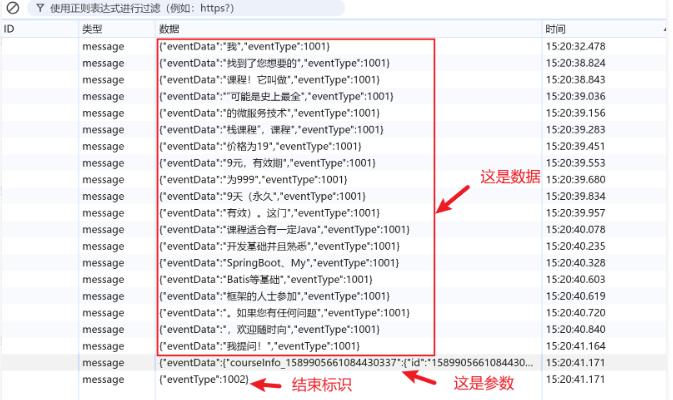
这个参数数据结构是这样的:**(这个是和前端约定好的结构)**

这里有一件很重要的事情还没搞清楚,就是,Tool 执行的结果已经给了大模型,我们在 Flux 输出时如何获取到呢?**(这个问题很重要)**
要想解决这个问题,就必须在全局有个容器,工具执行完后,将结果放入容器,流输出的最后进行判断,判断这个容器中是否有数据,如果有,就添加到流中,反之,就不需要添加。这样就可以解决问题了。
仔细想想,其实还有一个问题,就是存入这个容器的数据,怎么确保是这次请求的结果数据呢?能不能和 sessionId 关联?这其实是不可以的,因为同一个 sessionid 也可能有并发的情况,所以不能使用 sessionId,那就需要重新生成一个 requestId,这个请求 id,每次发起大模型时都会生成一个新的 id,用这个请求 id 和容器的数据关联起来,问题就解决了。
基本的流程如下:
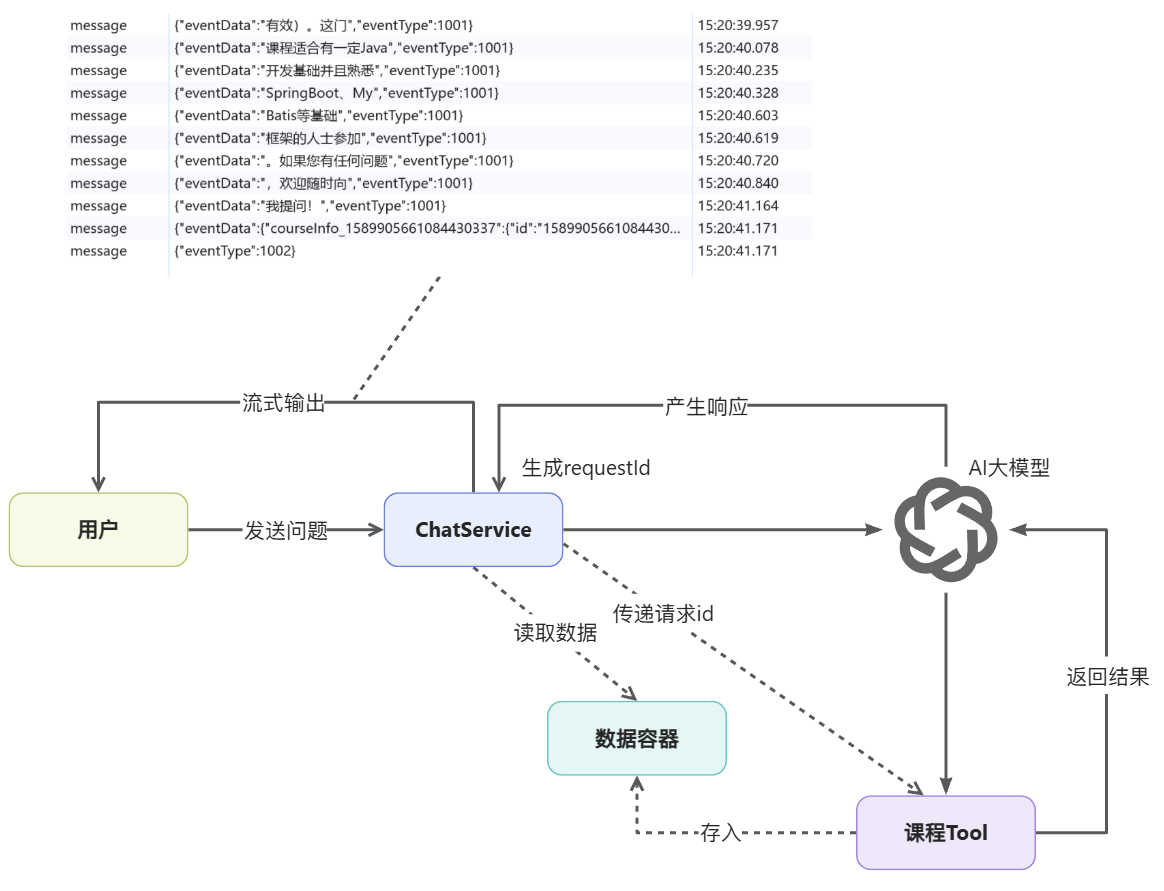
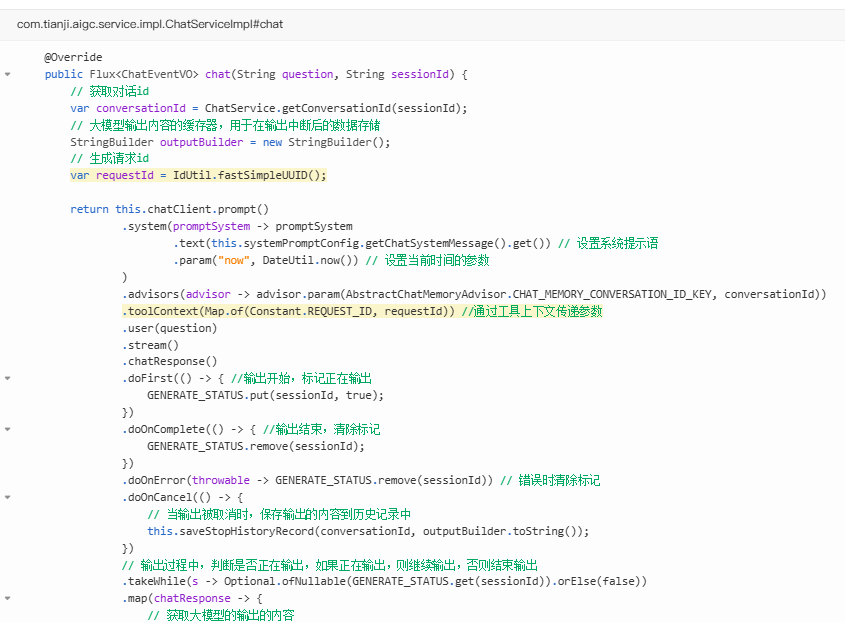
生成一个唯一的请求 ID,并传递给工具方法


`toolContext()` 方法

- 这是 `ChatClient` 或类似类的一个方法
- 作用:设置工具调用的上下文参数
- 参数:接收一个 `Map` 类型的参数
- 返回:返回自身对象,支持继续链式调用
`Map.of()` 静态方法
![]()
- Java 9+ 引入的静态工厂方法
- 作用:快速创建不可变的 Map(最多支持 10 对键值对)
- 语法:`Map.of(key1, value1, key2, value2, ...)`
在 CourseTools 添加接收这个参数:
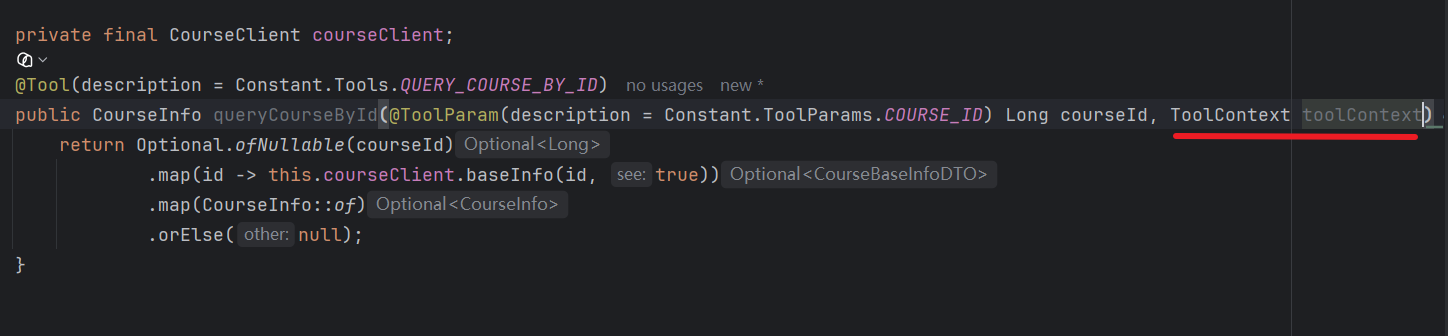
定义一个工具结果保持器,也就是容器:
package com.tianji.aigc.config;
import cn.hutool.core.lang.Assert;
import java.util.HashMap;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.ConcurrentHashMap;
_/**_
_ * 工具结果保持器,用来存储tools中得到的结果,请求id 作为key, value为键值对数据_
_ *_
_ * @author zzj_
_ * @version 1.0_
_ */_
public class ToolResultHolder {
private static final Map<String, Map<String, Object>> _HANDLER_MAP _= new ConcurrentHashMap<>();
_/**_
_ * 工具类,禁止实例化_
_ */_
_ _private ToolResultHolder() {
}
public static void put(String key, String field, Object result) {
Assert._notNull_(key, "key is not null!");
Assert._notNull_(field, "field is not null!");
_HANDLER_MAP_.computeIfAbsent(key, k -> new HashMap<>()).put(field, result);
}
public static Map<String, Object> get(String key) {
return key == null ? null : _HANDLER_MAP_.get(key);
}
public static Object get(String key, String field) {
Assert._notNull_(key, "key is not null!");
Assert._notNull_(field, "field is not null!");
return Optional._ofNullable_(_HANDLER_MAP_.get(key))
.map(map -> map.get(field))
.orElse(null);
}
public static void remove(String key) {
Assert._notNull_(key, "key is not null!");
_HANDLER_MAP_.remove(key);
}
}
前面的大 key 对应 request_id,而小 key 对应如下
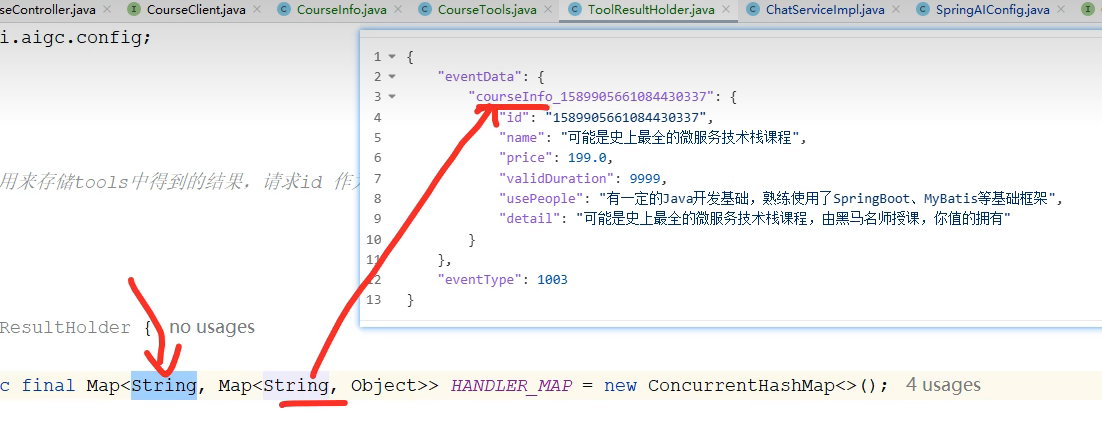
`HANDLER_MAP.computeIfAbsent(key, k -> new HashMap<>()).put(field, result);`
获取指定 key 对应的 Map,如果不存在就创建一个新的,然后往这个 Map 中放入键值对。
工具保存数据:
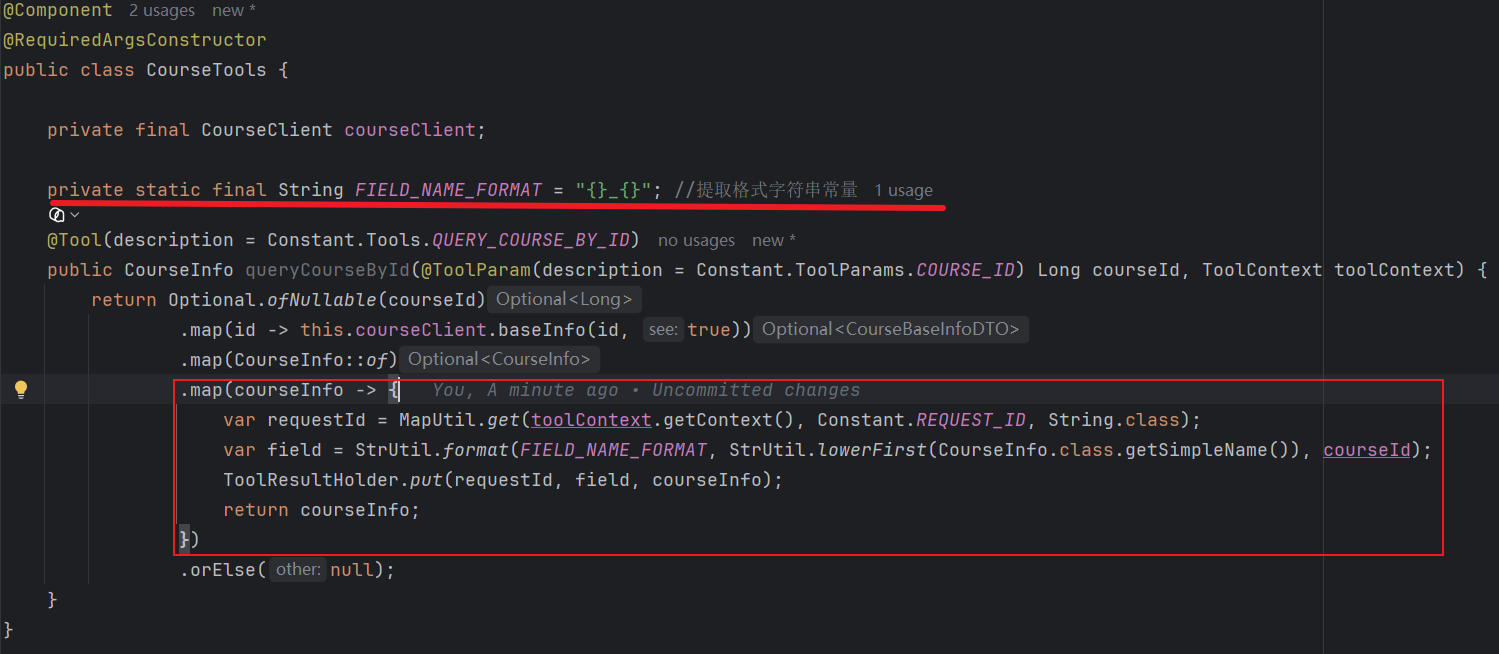
整体功能:将查询到的课程信息缓存到 `ToolResultHolder` 中,以便在同一次请求的其他地方复用,避免重复查询。
常量定义
![]()
- 定义缓存 key 的格式模板
- 最终会生成类似 `courseInfo_12345` 这样的 key
核心逻辑(在 map 中执行)
`MapUtil.get(toolContext.getContext(), Constant.REQUEST_ID, String.class)`
从 `toolContext` 的上下文 Map 中,取出 `Constant.REQUEST_ID` 这个 key 对应的值,并且把这个值转为 `String` 类型返回。
`var field = StrUtil.format(FIELD_NAME_FORMAT, StrUtil.lowerFirst(CourseInfo.class.getSimpleName()), courseId);`
获取类名
![]()
| 项目 | 说明 |
| `CourseInfo.class` | 获取 `CourseInfo` 类的 Class 对象 |
| `getSimpleName()` | 获取类的简单名称(不包含包名) |
| 返回值 | `"CourseInfo"` |
首字母小写
![]()
| 项目 | 说明 |
| `StrUtil.lowerFirst()` | Hutool 工具,将字符串首字母转为小写 |
| 返回值 | `"courseInfo"` |
格式化字符串
![]()
| 项目 | 说明 |
| `StrUtil.format()` | Hutool 的字符串格式化工具 |
| 执行过程 | 将 `{}` 占位符依次替换为后面的参数 |
| 返回值 | `"courseInfo_12345"` |
`ToolResultHolder.` _put_ `(requestId, field, courseInfo);`
这段代码只是中间处理(副作用操作),对 `courseInfo` 对象本身没有任何实际修改。
输出流中添加结果

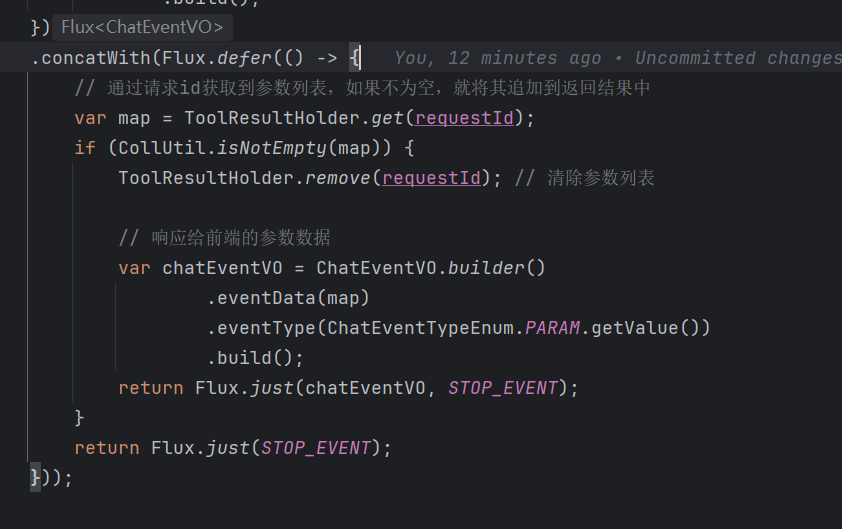
| 步骤 | 操作 | 目的 |
| 1 | `concatWith(Flux.defer(...))` | 在响应流结束后追加逻辑 |
| 2 | `ToolResultHolder.get(requestId)` | 获取缓存的工具调用结果 |
| 3 | `ToolResultHolder.remove(requestId)` | 清理缓存,释放内存 |
| 4 | 构建 `PARAM` 事件 | 将参数数据传给前端 |
| 5 | 发送 `STOP_EVENT` | 告诉前端流结束 |
![]()
作用:创建一个 Flux 流,依次发出指定的元素,然后自动结束。
`Flux.just(chatEventVO, STOP_EVENT)` 创建了一个响应式流,这个流会依次发出参数事件和结束事件,然后自动关闭。
测试一下:
还是输入:查询课程,课程 id 为:1589905661084430337

测试成功
购买课程与知识库-无法存储 params 的 bug 修复:

params 参数没有内容,查看历史记录,数据无法回显。
定位问题:
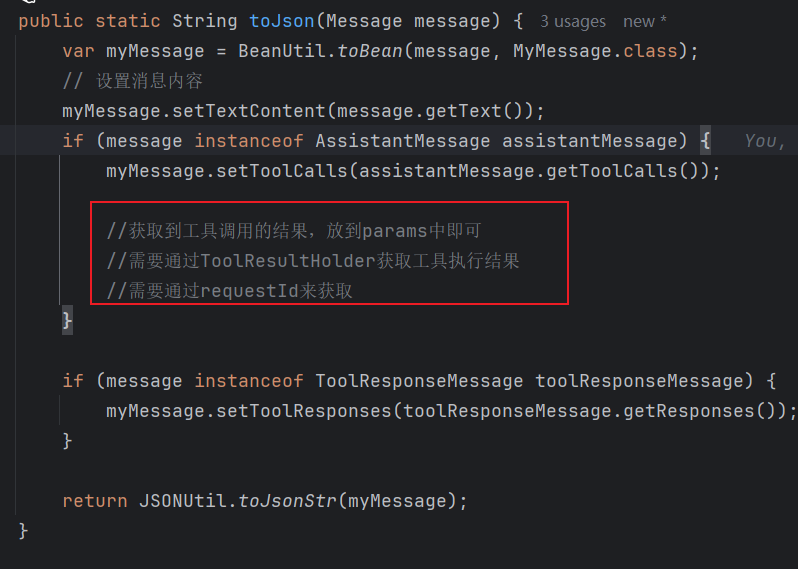
解决思路:
这个 bug 的解决思路就是,在 `RedisChatMemoryRepository` 中保存数据时,获取到 `ToolResultHolder` 中的数据,将数据保存到 `params` 中即可。
但是,`ToolResultHolder` 中的数据,是与 `requestId` 关联的,`requestId` 是我们自己生成的,在 `RedisChatMemory` 中是没有的,所以,这个问题的关键就是如何获取到 `requestId` 了,只要有了 `requestId` 就可以获取到数据,进行保存了。
如何传递 `requestId`?
其实,同样也是可以借助于 `ToolResultHolder` 来完成,我们可以把 `ToolResultHolder` 看作是一个**通用的容器**,可以放 Tool 的结果,也可以放其他的内容,只要及时的删除即可。
在 ChatServiceImpl 中将 messageId 和 requestId 关联起来
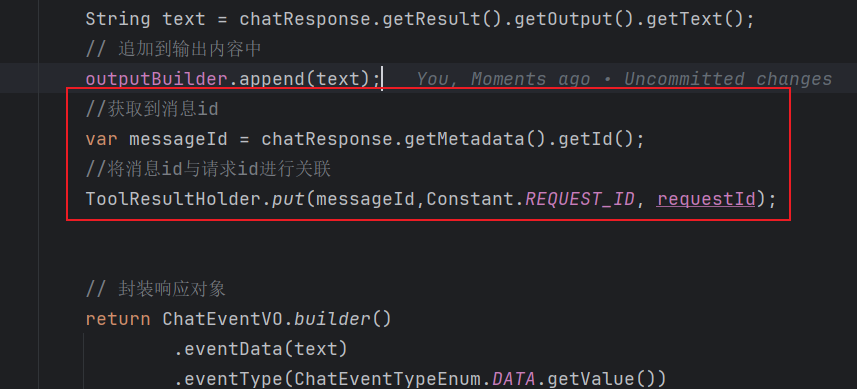
在 MessageUtil 当中添加:
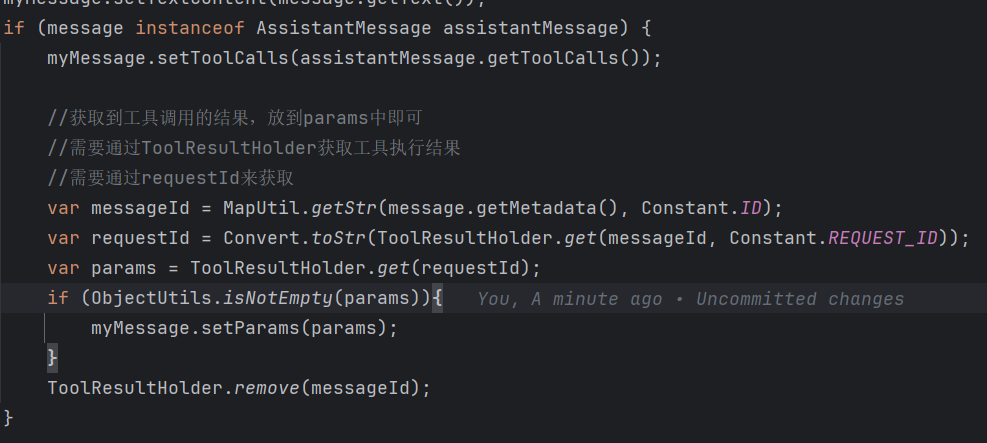
测试一下:

params 有值了
购买课程与知识库-代码优化:
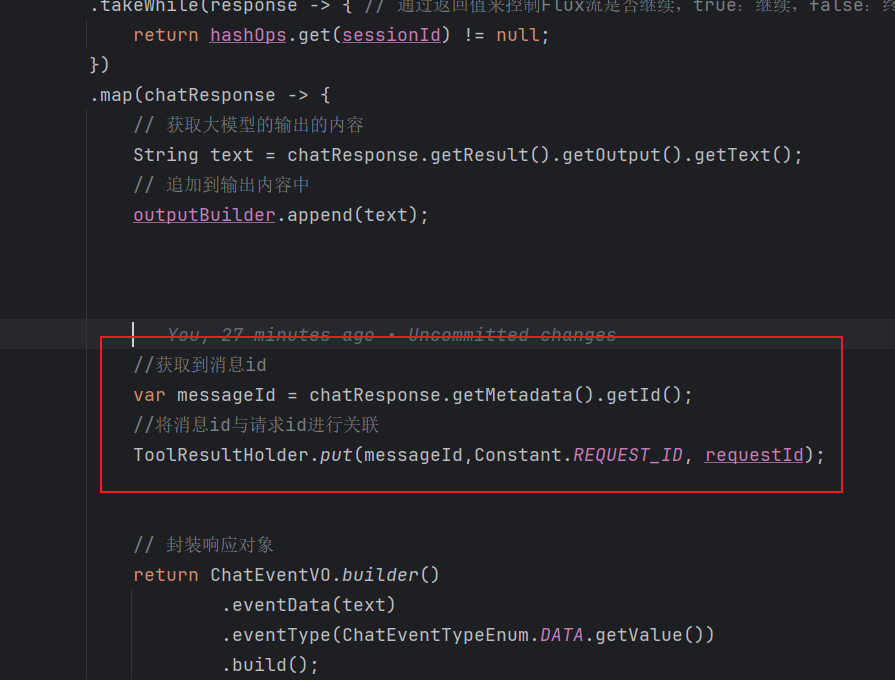
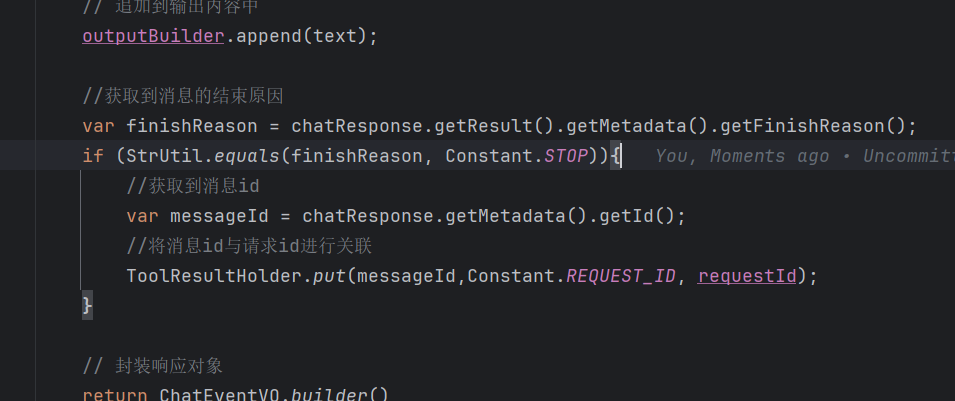
因为是流式输出,所以现在是每次都去获取消息 id,但是其实在要结束的时候去获取关联就行了。


获取结束原因
![]()
作用:获取 AI 响应的结束原因
数据流向:

购买课程与知识库-反序列化的处理:
因为 SpringAI 没有这个参数,所以我们需要定义一个类然后继承它来实现
MessageUtil 当中:

**MyAssistantMessage:**
package com.tianji.aigc.memory;
import lombok.Getter;
import lombok.Setter;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.content.Media;
import java.util.List;
import java.util.Map;
@Getter
@Setter
public class MyAssistantMessage extends AssistantMessage {
private Map<String, Object> params;
public MyAssistantMessage(String content, Map<String, Object> properties, List<ToolCall> toolCalls, List<Media> media, Map<String, Object> params) {
super(content, properties, toolCalls, media);
this.params = params;
}
}要实现原来最多参数的那个方法。
MessageUtil 替换原来的 **AssistantMessage**

查询的时候也用到了,所以 ChatSessionServiceImpl 当中 queryBySessionId 的方法也得改。
测试一下:

测试通过。
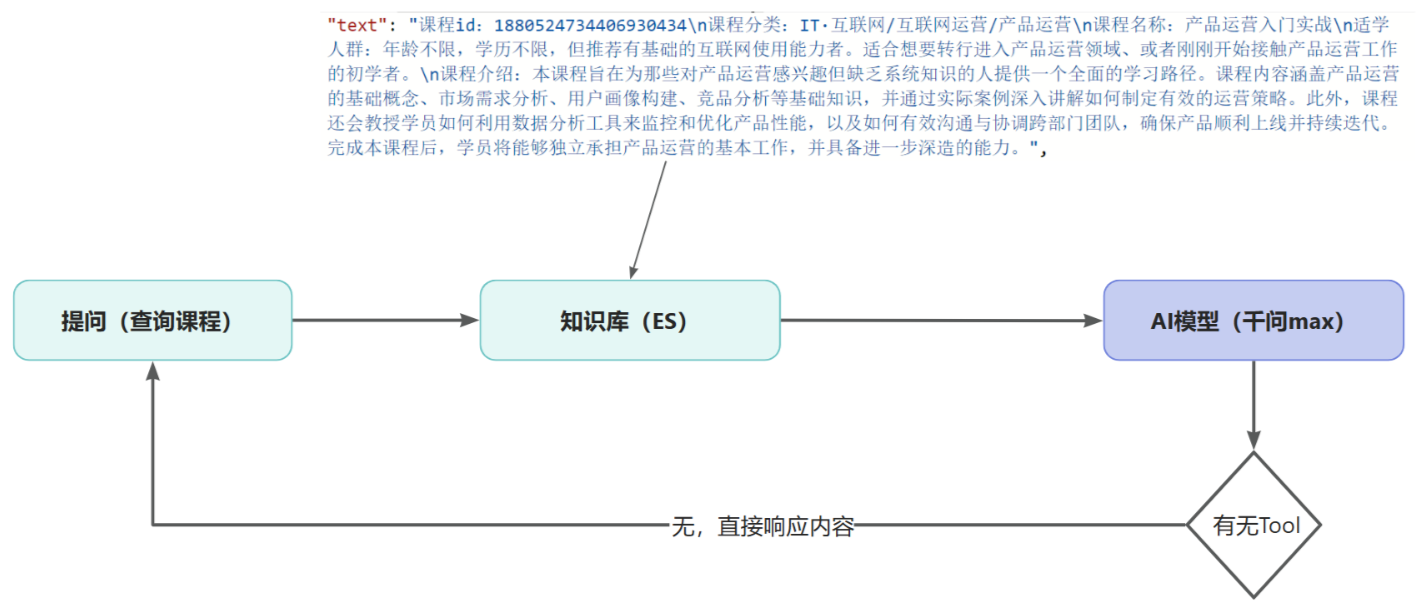
购买课程与知识库-RAG 基本原理:
之所以要使用知识库,是因为我们在做课程推荐时,需要先从知识库匹配到课程,再通过课程 id 查询课程信息进行推荐,如果没有知识库,就无法根据学生的需求进行推荐,所以必须要用到知识库了。
实现流程如下:

部署 es:
#win平台
docker run -d \
--name es2 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
-v es2-data:/usr/share/elasticsearch/data \
-v es2-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es2-net \
--restart=always \
-p 19200:9200 \
-p 19300:9300 \
registry.cn-beijing.aliyuncs.com/itcast/elasticsearch:8.13.4
---------------------------------------------------------------------------------
#M系列MAC虚拟机
docker run -d \
--name es2 \
-e "discovery.type=single-node" \
-e "xpack.security.enabled=false" \
-v es2-data:/usr/share/elasticsearch/data \
-v es2-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es2-net \
--restart=always \
-p 19200:9200 \
-p 19300:9300 \
docker.1ms.run/elasticsearch:8.13.4
#如果容器已经存在,可以先删除,再创建
#删除
docker rm -f es2
#清理挂载目录中无用的数据
docker volume prune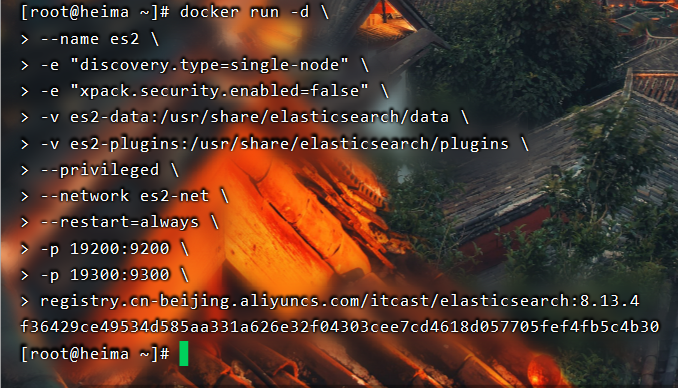
之后访问:[http://192.168.150.101:19200/](http://192.168.150.101:19200/)
看到下面就成功了
然后在项目中集成 es:
在 tj-aigc 项目中,导入 SpringAI 集成 ES 的依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
<exclusions>
<exclusion>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.15.5</version>
</dependency>在 nacos 的配置中心的 `aigc-service.yaml` 文件中进行配置:
spring:
elasticsearch:
uris: http://192.168.150.101:19200
ai:
dashscope:
api-key: ${tj.ai.dashscope.key}
chat:
enabled: true
options:
model: qwen-plus
# model: qwen-plus
# model: qwen2.5-1.5b-instruct 免费模型
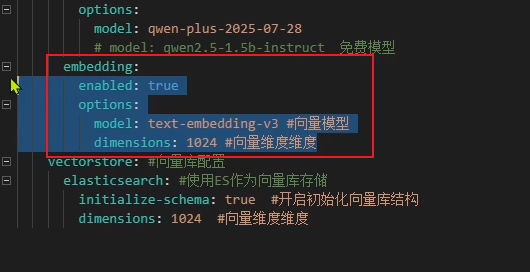
embedding:
enabled: true
options:
model: text-embedding-v3 #向量模型
dimensions: 1024 #向量维度维度
vectorstore: #向量库配置
elasticsearch: #使用ES作为向量库存储
initialize-schema: true #开启初始化向量库结构
dimensions: 1024 #向量维度维度| 放 Nacos | 放 application.yml |
| ✅ 数据库/ES/Redis 连接地址 | ✅ 应用名称、端口 |
| ✅ API Key、密码、密钥 | ✅ 固定开关(enabled: true) |
| ✅ 环境差异配置 | ✅ 固定维度、模型名 |
| ✅ 动态开关(可实时修改) | ✅ 日志格式、编码 |
| ✅ 不同环境不同值 | ✅ 本地开发专用配置 |
核心原则:会变的放 Nacos,不变的放本地;敏感信息放 Nacos,框架配置放本地。当然也可以都在 nacos 当中配,但是不推荐。这里所有关于 spring-ai 的配置都在 nacos 当中配
部署 kibana
可视化界面,部署 `kibana` 的目的是用于查看 `ES` 中是否已经创建了索引库。
#win平台
docker run -d \
--name kibana2 \
-e ELASTICSEARCH_HOSTS=http://192.168.150.101:19200 \
-p 15601:5601 \
docker.elastic.co/kibana/kibana:8.13.4
#M系列MAC虚拟机
docker run -d \
--name kibana2 \
-e ELASTICSEARCH_HOSTS=http://192.168.150.101:19200 \
-p 15601:5601 \
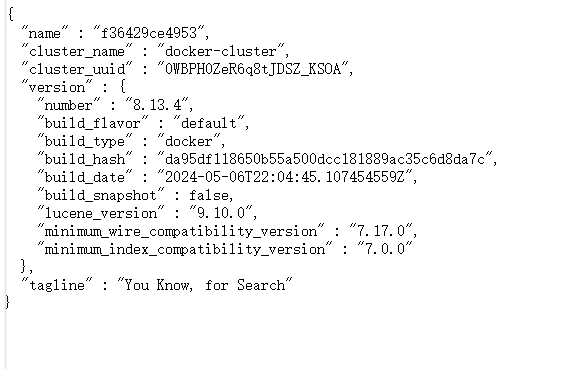
docker.1ms.run/kibana:8.13.4等待 `kibana` 启动好之后,访问地址:[http://192.168.150.101:15601/app/dev_tools#/console](http://192.168.150.101:15601/app/dev_tools#/console)
看到页面就成功了,现在是直接进入 dev_tools 开发工具
如果是首页,可以点击这里
或者直接搜索
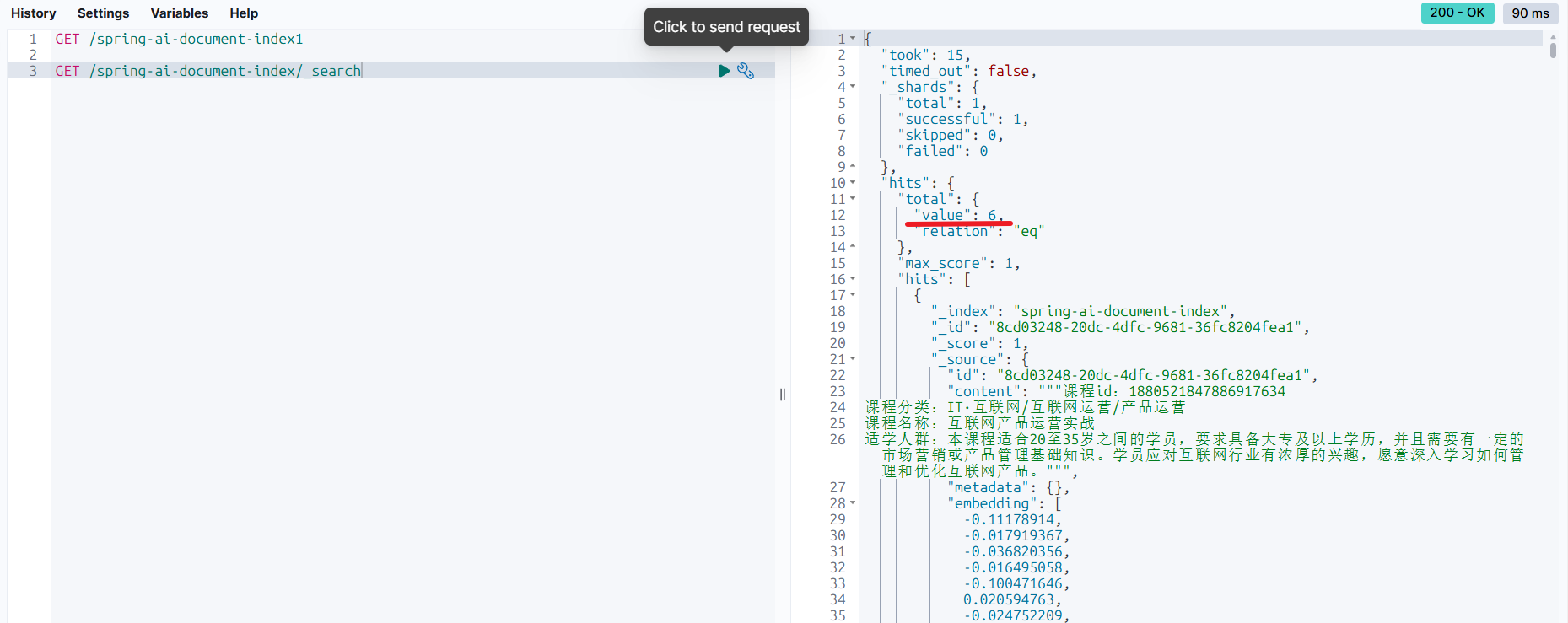
默认索引库名字:

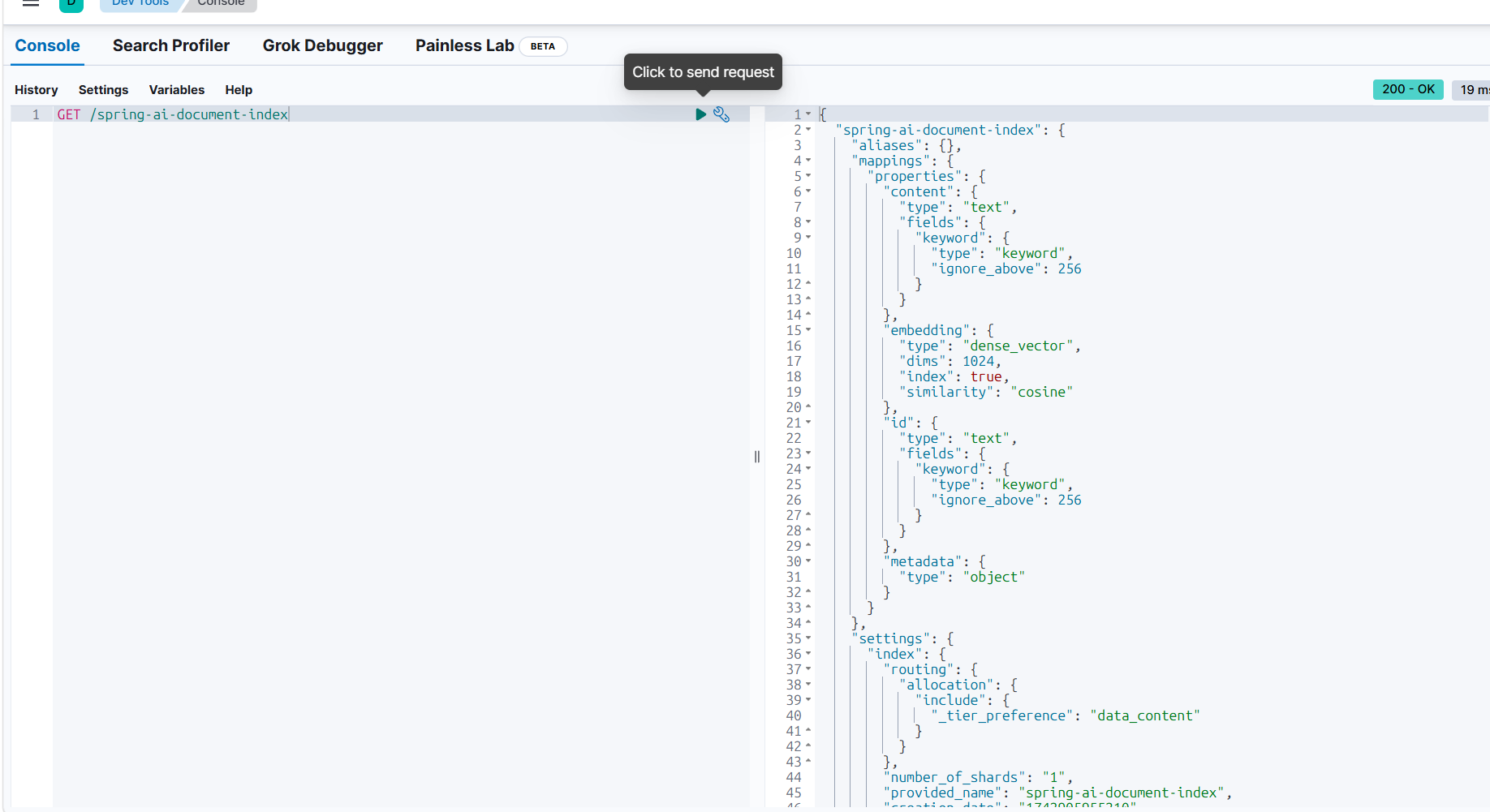
查下看下索引库在不在
在:
不在:
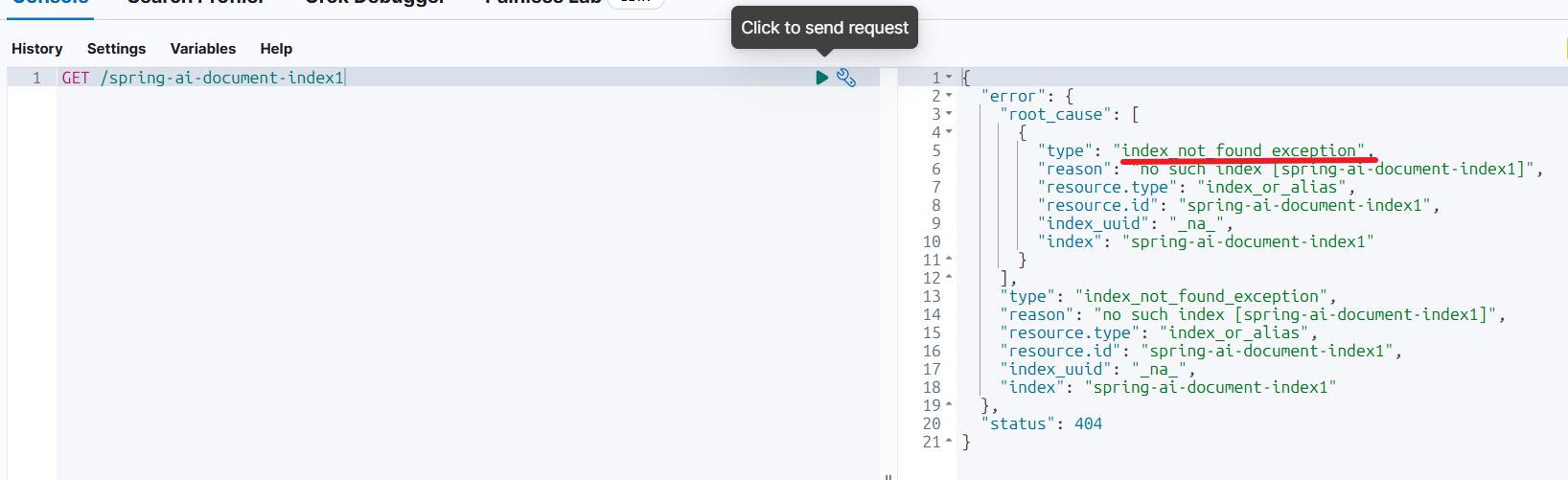
搜索索引库数据:
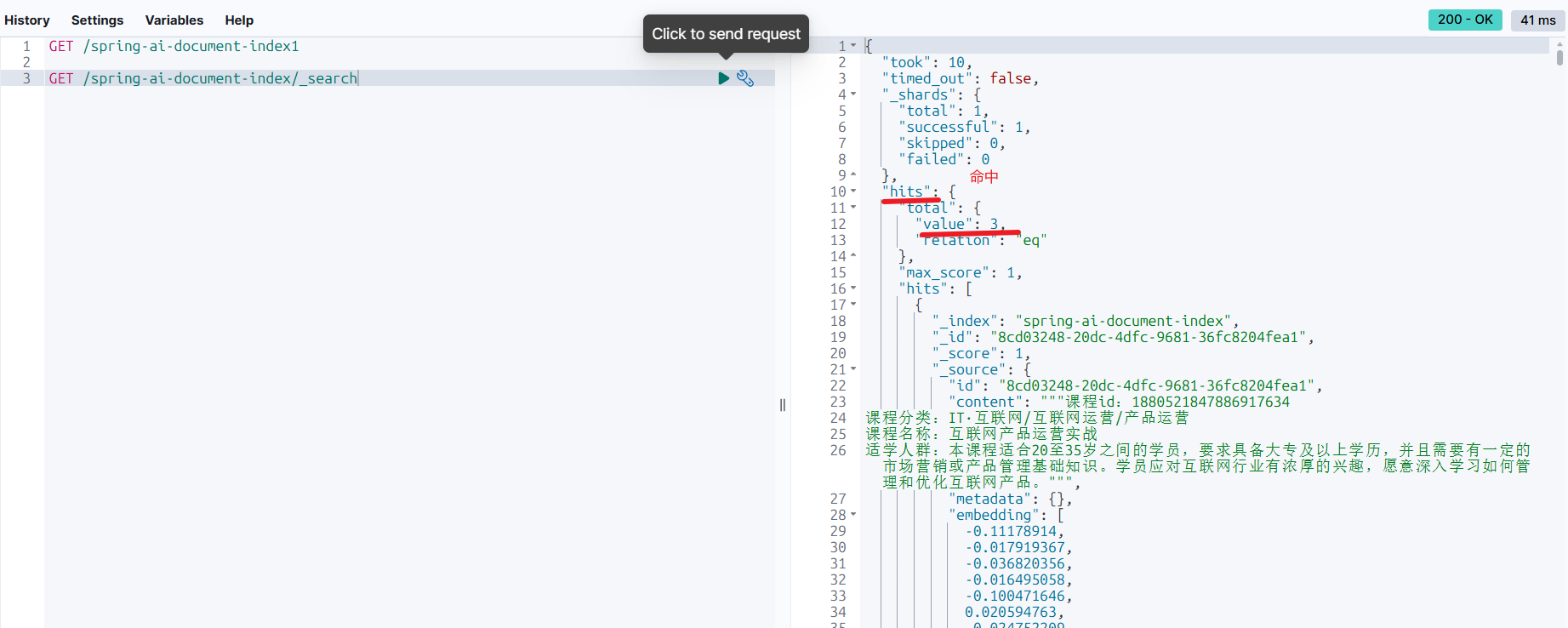
购买课程与知识库-写入数据到知识库:
在知识库中,需要写入一些数据,以供推荐课程使用
package com.tianji.aigc.controller;
import cn.hutool.core.collection.CollStreamUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@Slf4j
@RestController
@RequestMapping("/embedding")
@RequiredArgsConstructor
public class EmbeddingController {
private final VectorStore vectorStore;
@PostMapping
public void saveVectorStore(@RequestParam("messages") List<String> messages) {
_log_.info("保存到向量数据库中,消息数据:{}", messages);
//构建文档
List<Document> documents = CollStreamUtil._toList_(messages, message -> Document._builder_()
.text(message)
.build());
//存储到向量数据库中
this.vectorStore.add(documents);
_log_.info("保存到向量数据库成功, 数量:{}", messages.size());
}
}将传入的文本消息转换为向量并存储到向量数据库,用于后续的相似度搜索和语义检索。
依赖注入
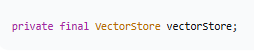
- `VectorStore`:向量数据库接口(可能是 Chroma、Pinecone、Milvus 等)
- `final` + `@RequiredArgsConstructor`:自动生成构造器注入
接口定义

| 注解 | 说明 |
| `@PostMapping` | 处理 POST 请求 |
| `@RequestParam("messages")` | 从请求参数中获取 `messages` |
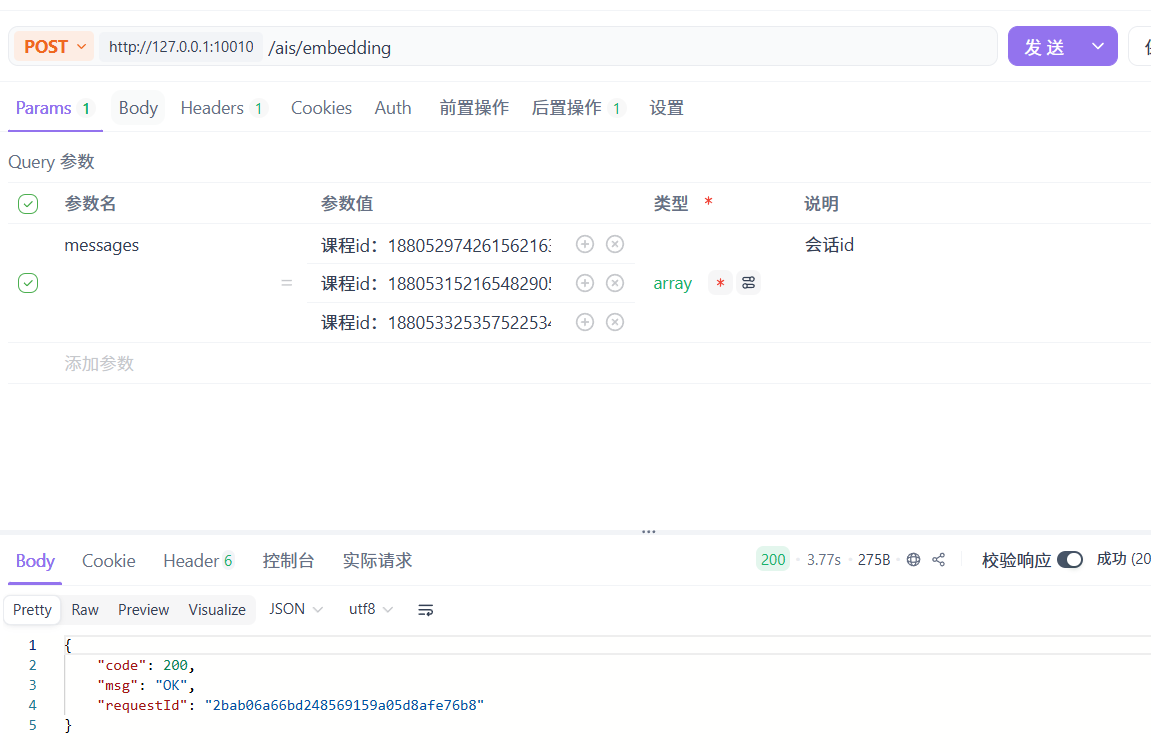
请求示例:
![]()
构建文档对象

作用:将字符串消息转换为向量数据库的 Document 对象

`CollStreamUtil.toList()`:Hutool 工具,结合了 Collection 和 Stream
存储到向量数据库
![]()
- 将每个 Document 的 text 字段转换为向量(embedding vector)
- 存储向量和原始文本
- 建立索引,支持相似度搜索
完整数据流

准备写入数据:

注入的是 es


先用向量模型进行向量化
然后进行保存
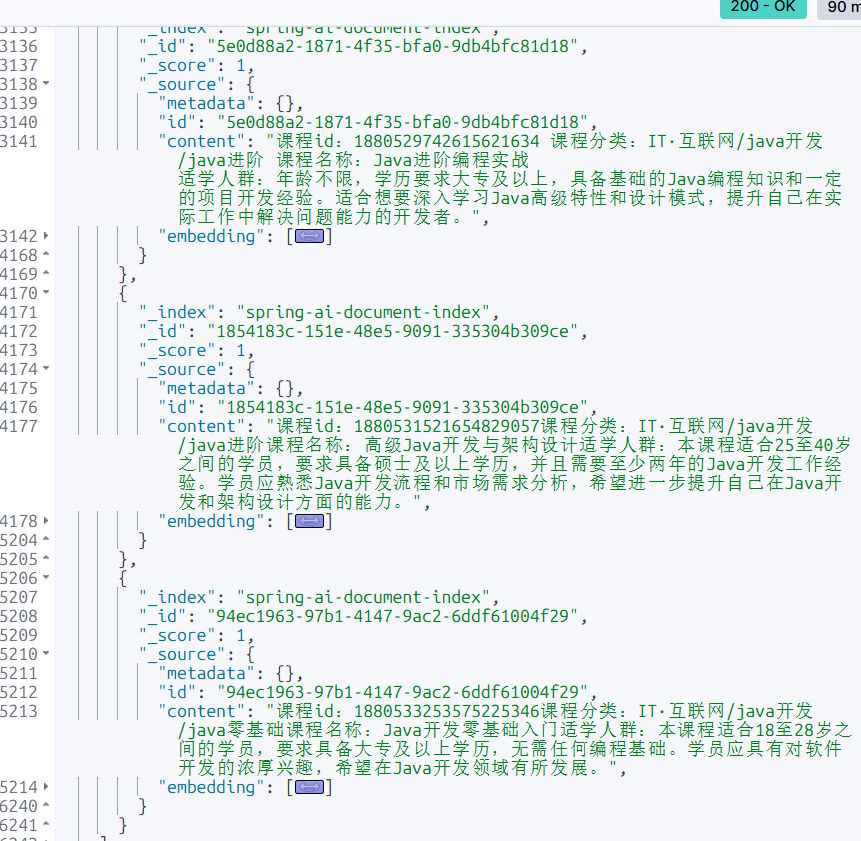
现在就又多了 3 条数据
下面是 1024 维上的数值

购买课程与知识库-集成到 chatClient:
依赖注入
![]()
- `VectorStore`:向量数据库接口
- 存储了之前通过 `/embedding` 接口保存的文本向量
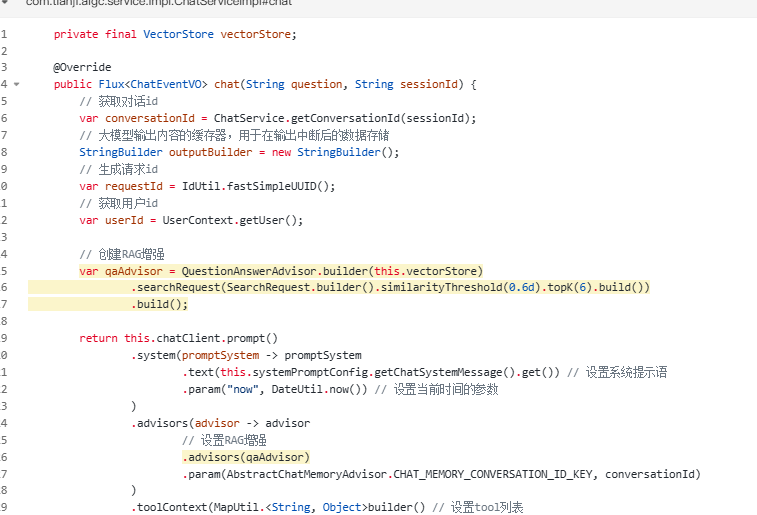
创建 RAG Advisor
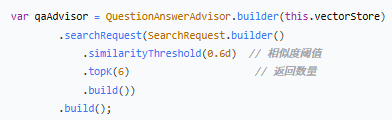
作用:构建一个 RAG 增强器,配置检索参数
应用到 AI 对话
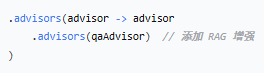
RAG 工作流程

参数详解
`similarityThreshold(0.6d)`
相似度阈值,只返回相似度 > 0.6 的结果
| 阈值 | 效果 |
| 0.9+ | 严格匹配,返回少但精准 |
| 0.6-0.7 | 平衡,推荐值 |
| 0.5- | 宽松,返回多但可能有噪音 |
`topK(6)`
最多返回 6 条最相似的结果
| topK | 效果 |
| 小(1-3) | 上下文少,回答简洁 |
| 中(4-6) | 平衡,推荐值 |
| 大(10+) | 上下文多,但可能引入噪音,消耗更多 token |
先在 apifox 上测下:
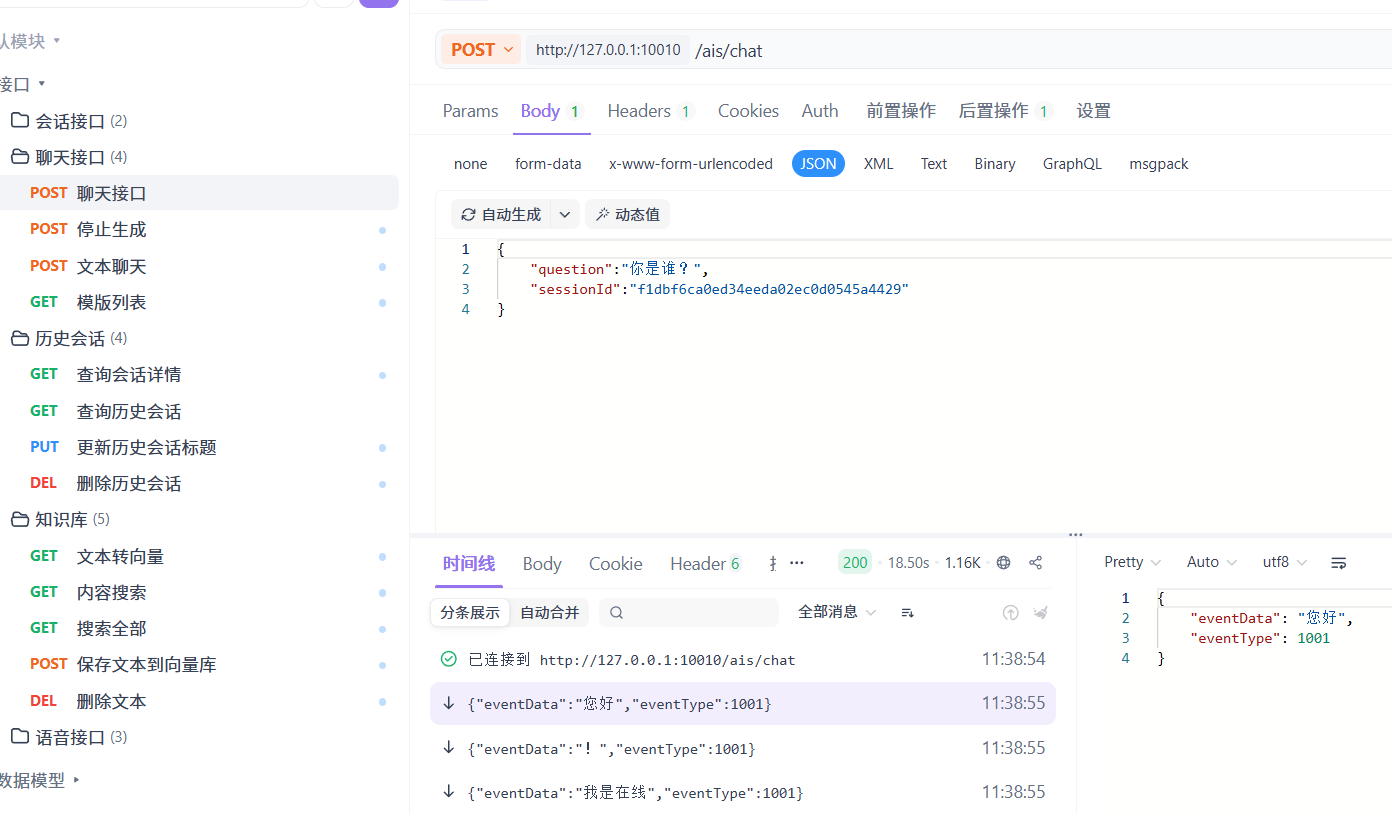
可以,然后前端测试
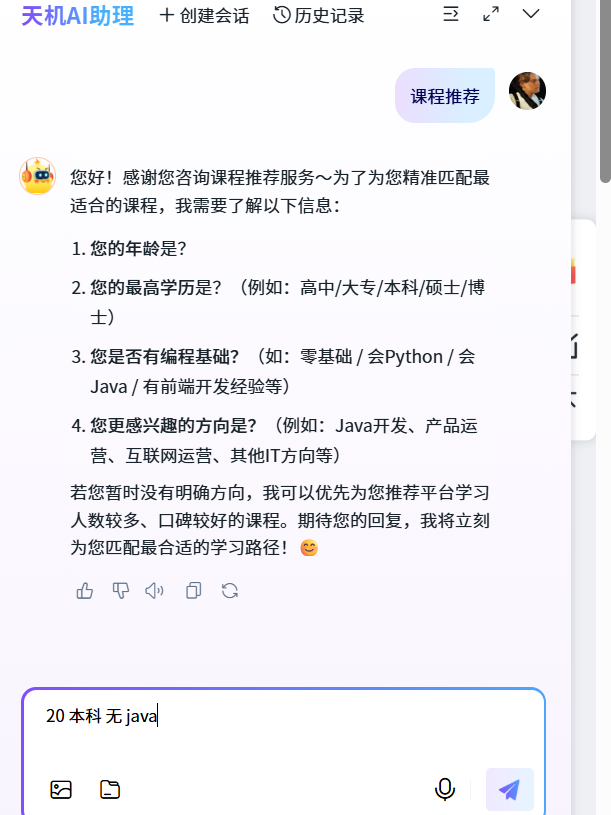
测试通过

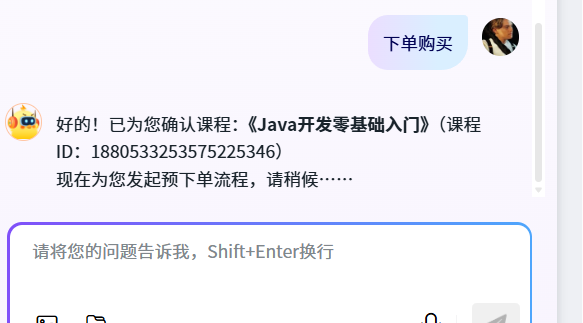
这里是因为调用工具,但那个工具还没有实现。
有些模型看到下单购买,不会去看 ID,所以可以换下模型试下
Max 效果比 Plus 好
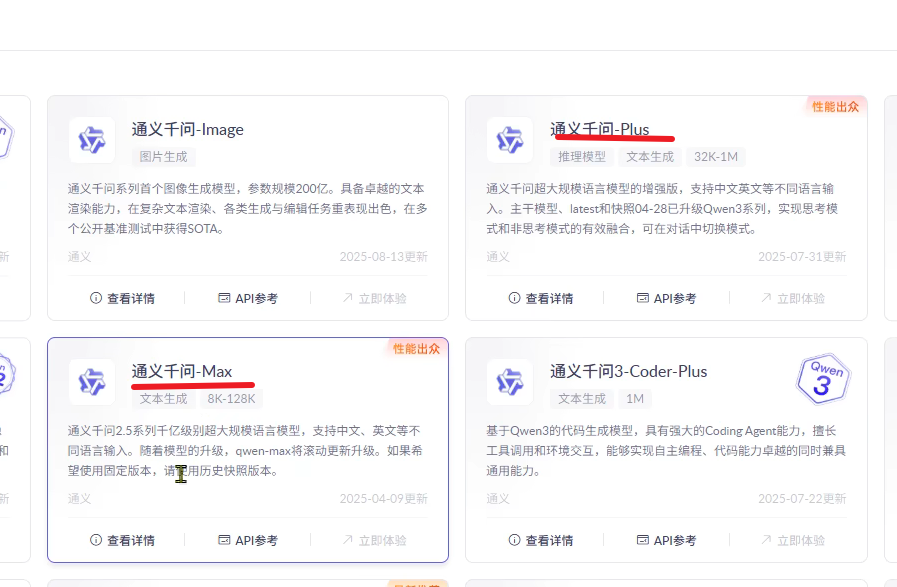
购买课程与知识库-实战任务:
练习 1:
前面我们只实现了向量库的新增操作,除了新增操作外,我们还可以实现如下的几个接口:

实现了这几个接口后,我们就不需要在 kibana 中操作了。
参考代码:
package com.tianji.aigc.controller;
import cn.hutool.core.collection.CollStreamUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@Slf4j
@RestController
@RequestMapping("/embedding")
@RequiredArgsConstructor
public class EmbeddingController {
private final VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
@PostMapping
public void saveVectorStore(@RequestParam("messages") List<String> messages) {
log.info("保存到向量数据库中,消息数据:{}", messages);
//构建文档
List<Document> documents = CollStreamUtil.toList(messages, message -> Document.builder()
.text(message)
.build());
//存储到向量数据库中
this.vectorStore.add(documents);
log.info("保存到向量数据库成功, 数量:{}", messages.size());
}
@GetMapping
public EmbeddingResponse embed(@RequestParam("message") String message) {
return this.embeddingModel.embedForResponse(List.of(message));
}
@DeleteMapping
public void deleteVectorStore(@RequestParam("ids") List<String> ids) {
// 删除向量数据库中的数据
this.vectorStore.delete(ids);
}
@GetMapping("/search")
public List<Document> search(@RequestParam("message") String message) {
return this.vectorStore.similaritySearch(SearchRequest.builder().query(message).topK(5).build());
}
@GetMapping("/search/all")
public List<Document> searchAll() {
// 搜索全部数据
return this.vectorStore.similaritySearch(SearchRequest.builder().query("").topK(999).build());
}
}练习 2:
-
按照SpringAI官方文档,实现使用Redis作为向量库存储,替换课程中的ES部分。👉 Redis :: Spring AI Reference
-
实现提示:使用Redis实现向量库,需要使用到redis-stack。
-

Docker 镜像网址:1ms.run
https://1ms.run/r/redis/redis-stack
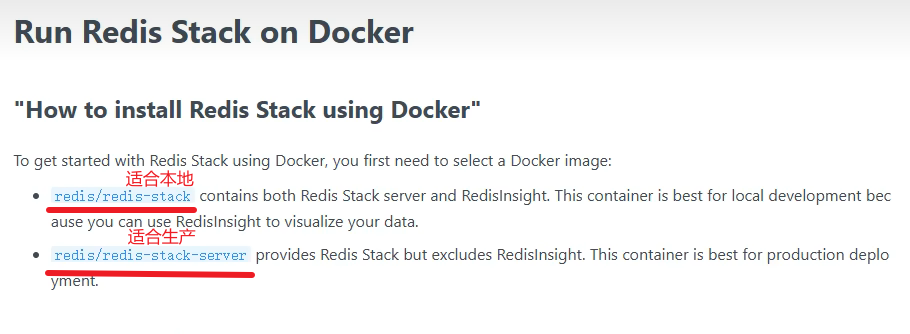

copy 过来之后记得改下

要走镜像的话,加下

当然最好不要用 latest 最新版本,因为你不知道是哪个版本
docker run -d \
--name redis-stack \
-p 16379:6379 \
-p 18001:8001 \
-e REDIS_ARGS="--requirepass 123456" \
docker.lms.run/redis/redis-stack:7.2.0-v17
docker run -d \
--name redis-stack \
-p 16379:6379 \
-p 18001:8001 \
-e REDIS_ARGS="--requirepass 123456" \
redis/redis-stack:7.2.0-v17第一个端口是 redis 的,第二个端口是 redisInsight,可视化界面的。下次运行的时候记得启动 redis-stack 服务.
执行一下,这里我有魔法,就不用这个镜像了
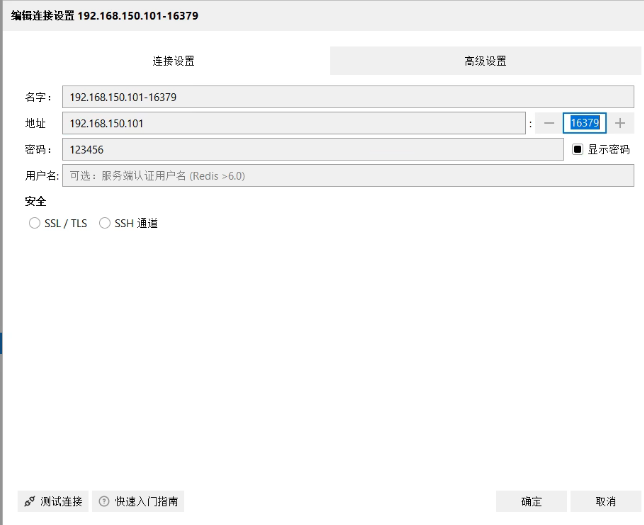
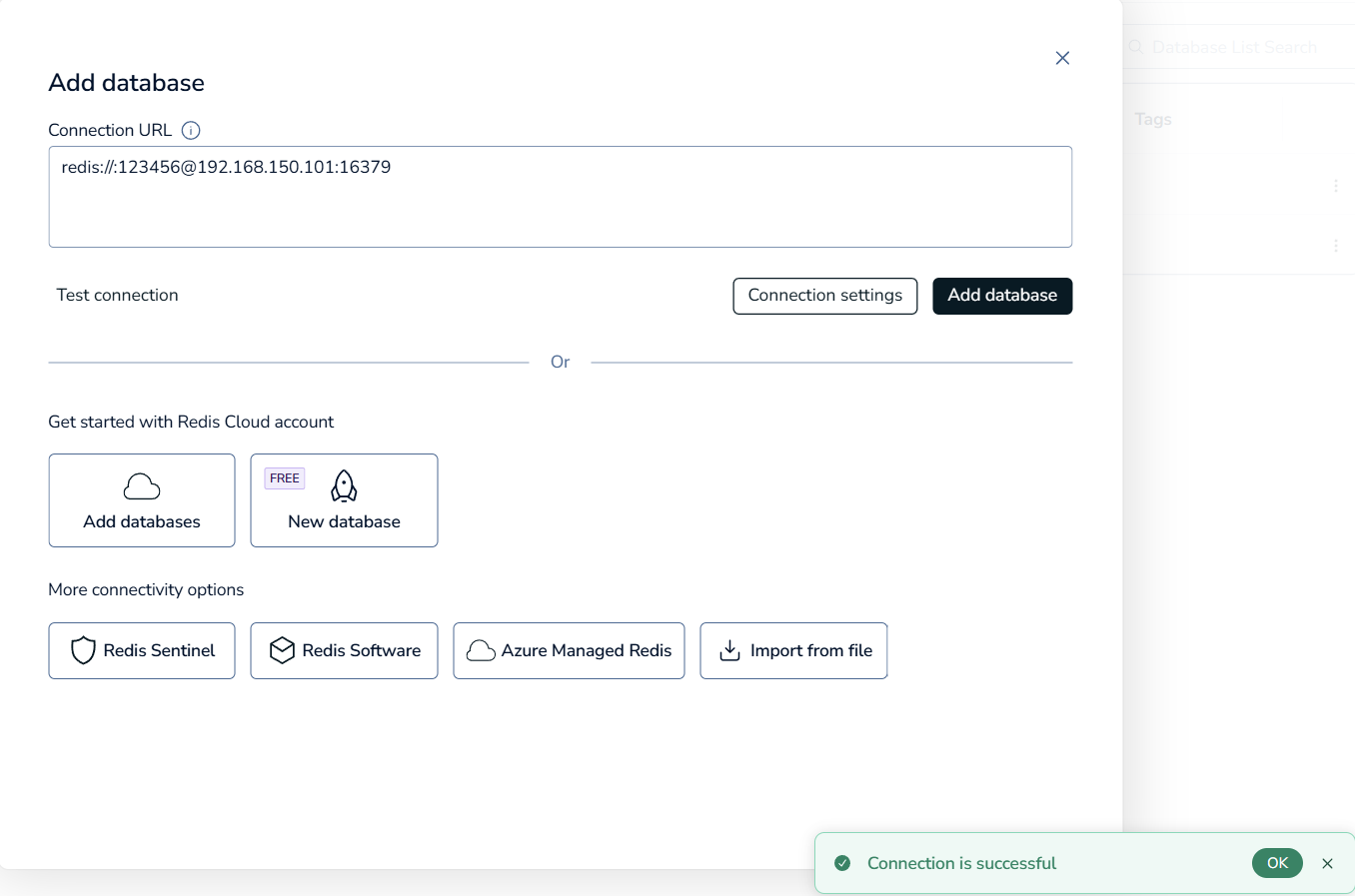
完整格式
![]()
逐部分解析

各部分组成
| 部分 | 值 | 说明 |
| 协议 | `redis://` | 使用 Redis 协议连接 |
| 密码 | `:123456` | 冒号后面跟密码,前面没有用户名 |
| 主机 | `192.168.150.101` | Redis 服务器的 IP 地址 |
| 端口 | `16379` | Redis 服务的端口号 |
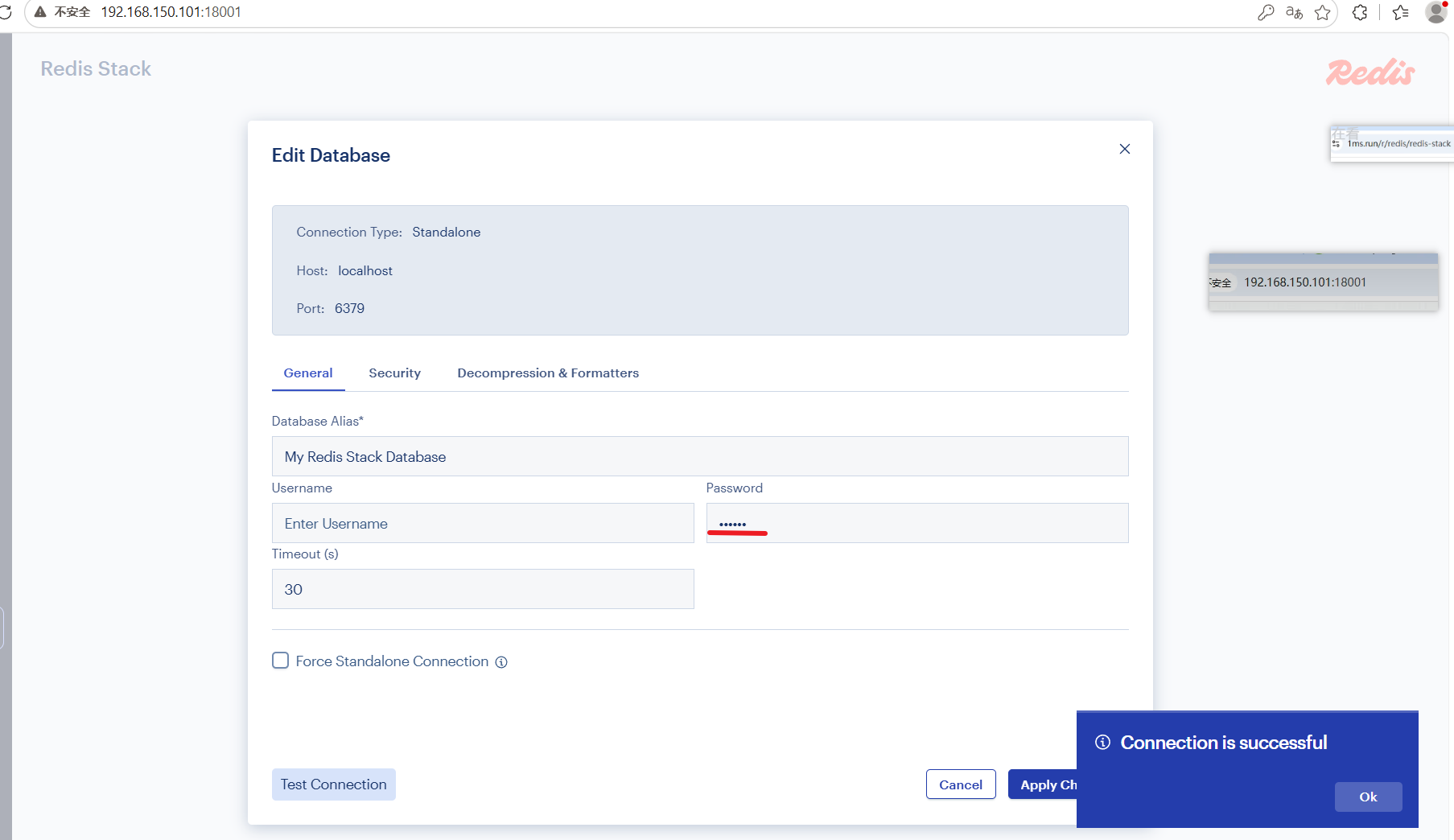
http://192.168.150.101:18001/redis-stack/browser
这样就有个可视化界面了
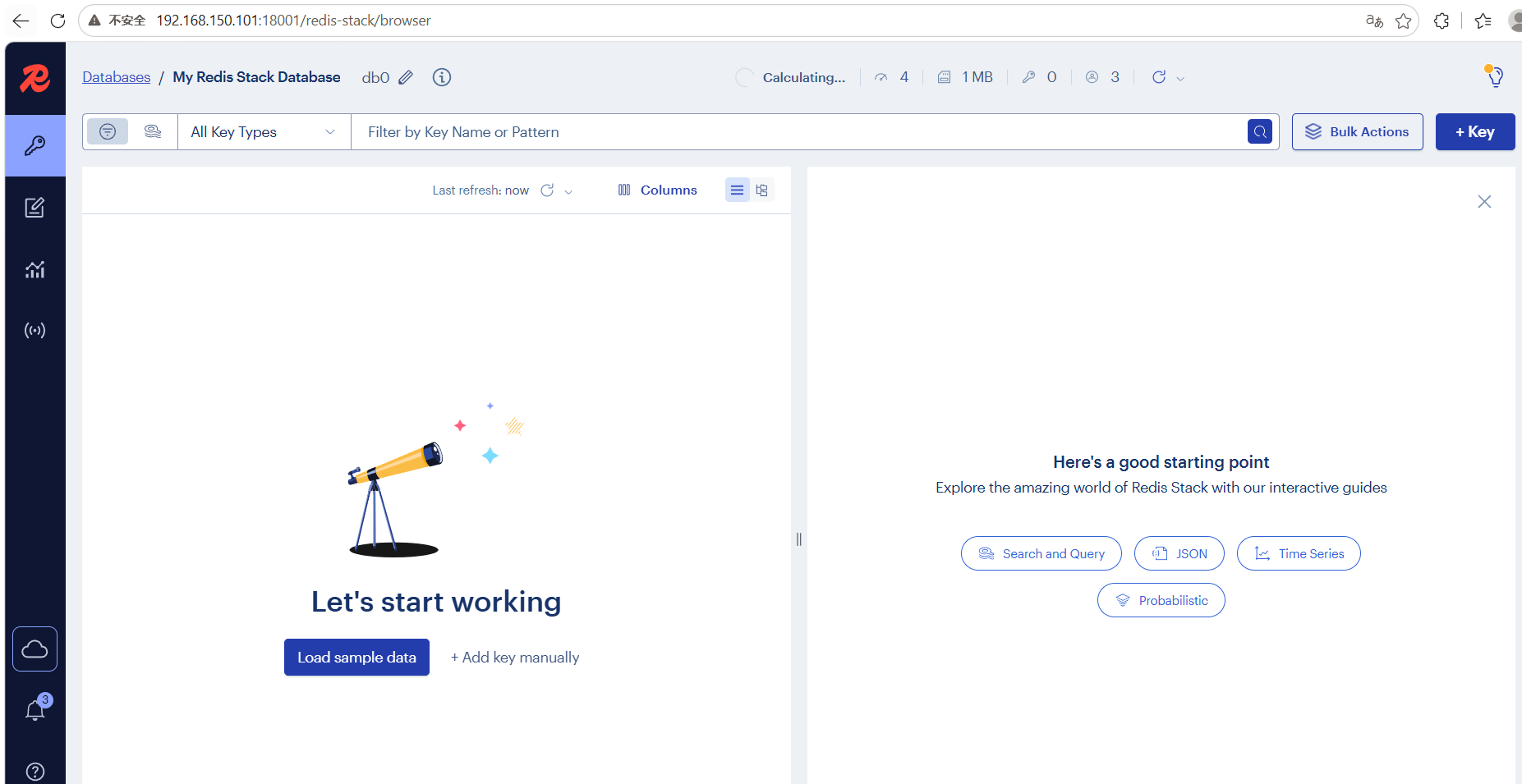
项目集成 spring-ai-redis 向量存储
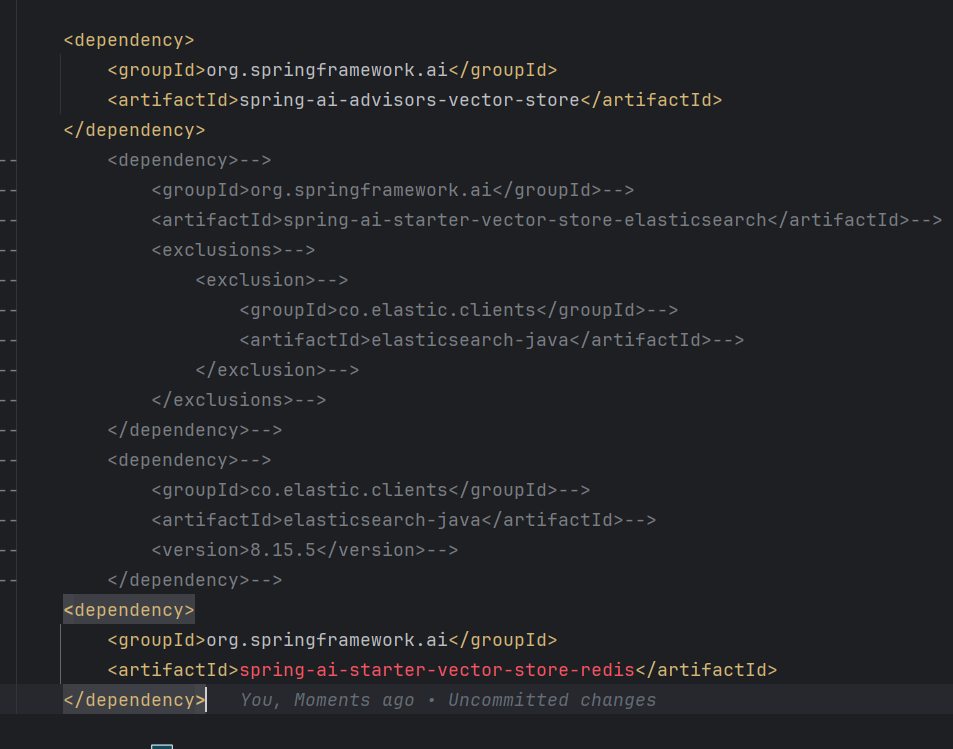
先注释掉 es 向量库,然后加入 redis 向量库依赖,vectorstore 才不会出现歧义
改下 application-local.yml 当中的配置
先把原先的配置注释掉,不然两个会覆盖,原先的只是提供基础的 redis 操作,而新的不仅还。
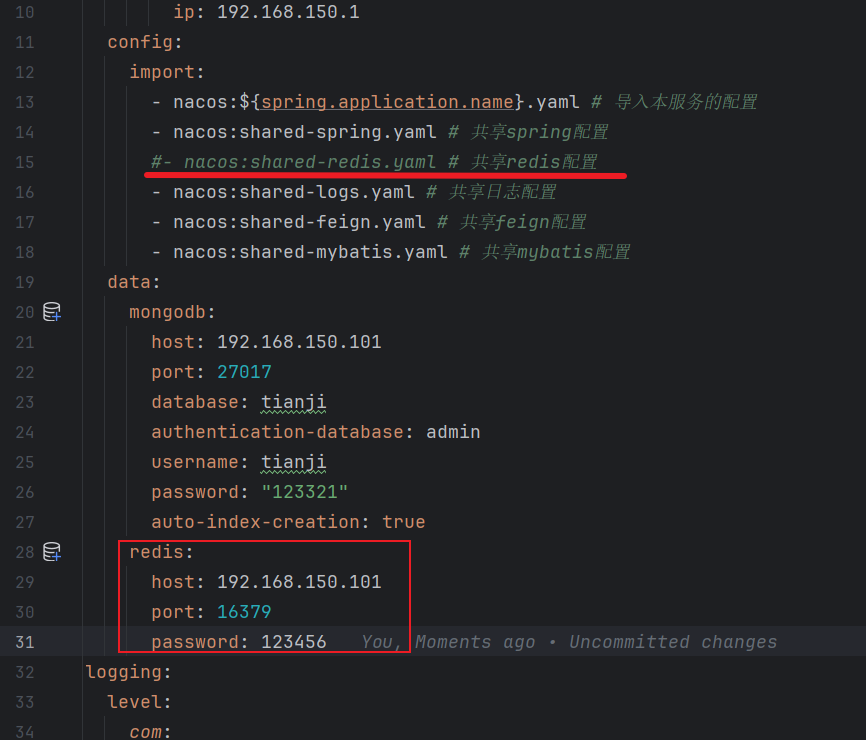
在 nacos 配置中把 es 的注释掉,加入 redis
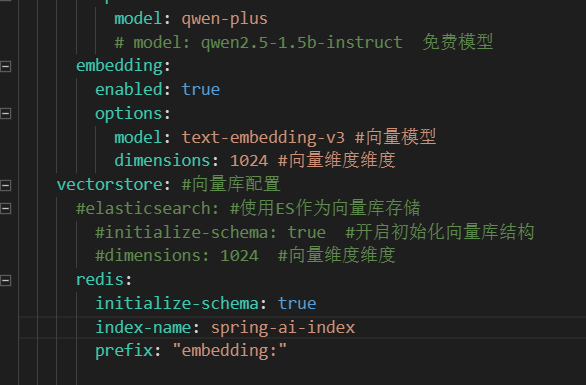
`initialize-schema: true`
| 项目 | 说明 |
| 作用 | 应用启动时自动创建 Redis 索引结构 |
| 值 | `true` = 自动创建,`false` = 手动创建 |
| 首次使用 | 建议设为 `true`,让框架自动建索引 |
| 生产环境 | 可以设为 `false`,由 DBA 统一管理 |
`index-name: spring-ai-index`
| 项目 | 说明 |
| 作用 | Redis 索引的名称 |
| 值 | `spring-ai-index` |
| 用途 | 标识这个索引是 Spring AI 使用的 |
| 查询时 | 需要通过这个名字指定使用哪个索引 |
![]()
`prefix: "embedding:"`
| 项目 | 说明 |
| 作用 | Redis Key 的前缀 |
| 值 | `"embedding:"` |
| 用途 | 区分不同用途的数据 |
Redis 中实际存储的 Key:

这个时候启动还是会报错的,得在配置当中加上这个
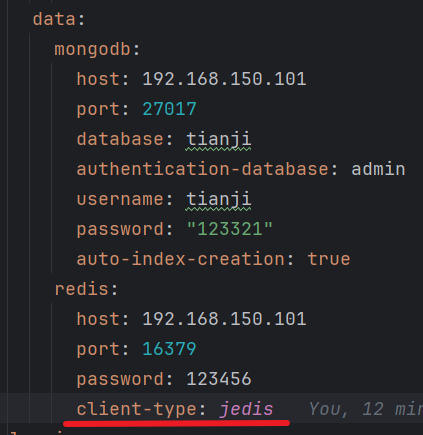
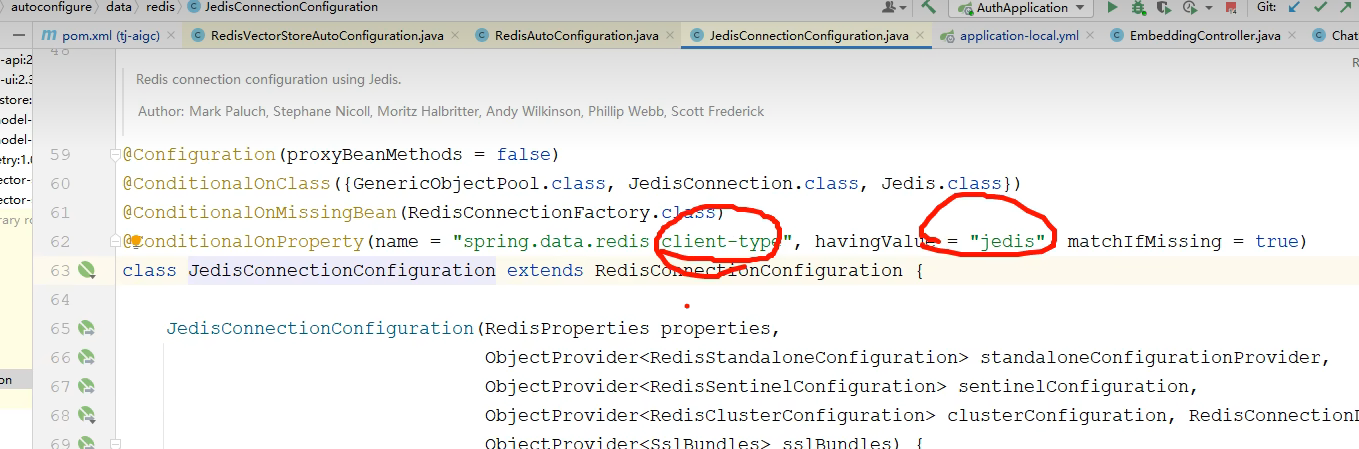
`client-type: jedis` 用于指定 Spring Boot 使用 Jedis 作为 Redis 的客户端驱动。
Spring Boot 支持三种 Redis 客户端:
| client-type | 说明 | 特点 |
| jedis | Apache Jedis | 同步阻塞,线程不安全(需用连接池) |
| lettuce | Lettuce(默认) | 异步非阻塞,线程安全,基于 Netty |
| none | 禁用自动配置 | 手动配置 |
| 对比项 | Jedis | Lettuce |
| 线程安全 | ❌ 需要连接池 | ✅ 线程安全 |
| 连接池 | ✅ 必须 | ⚠️ 可选 |
| 异步支持 | ❌ | ✅ |
| 响应式支持 | ❌ | ✅ |
| 默认配置 | ❌ | ✅ (Spring Boot) |
| 适用场景 | 传统同步项目 | 现代项目推荐 |
`client-type: jedis` 指定使用 Jedis 作为 Redis 客户端驱动,但 Spring Boot 默认推荐 Lettuce,除非有特殊需求,否则可以省略此配置。但这里就是得用 jedis,不然不能生效。
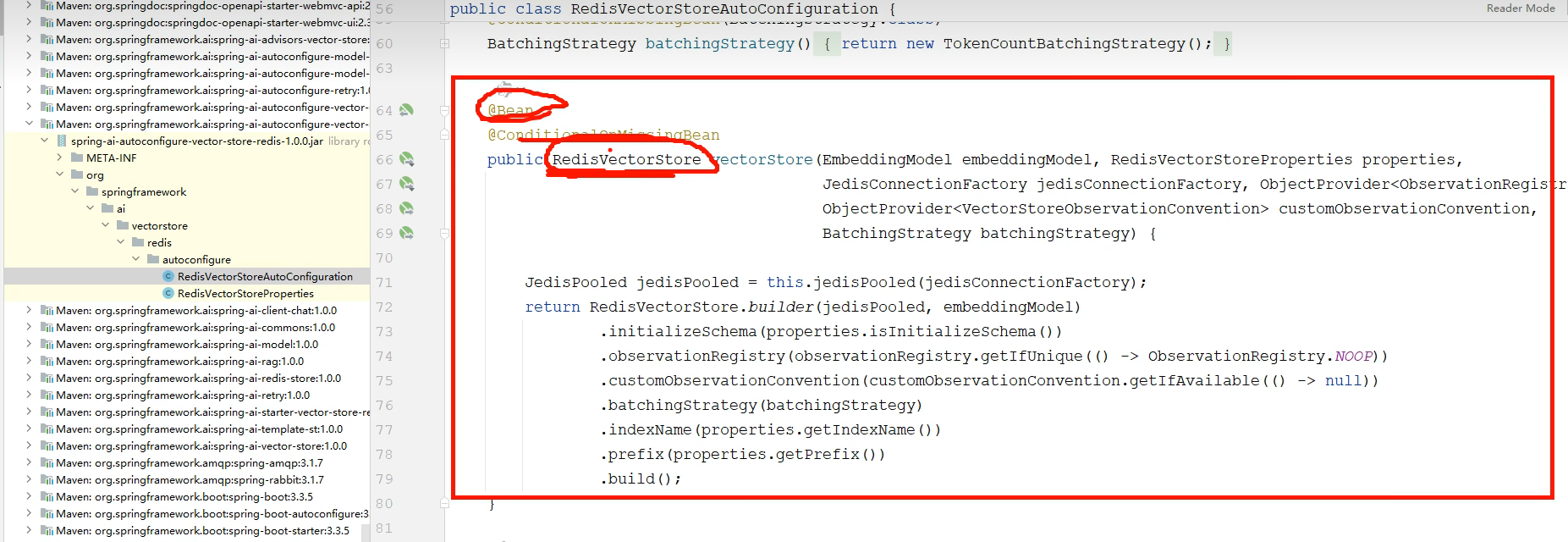
测试一下:
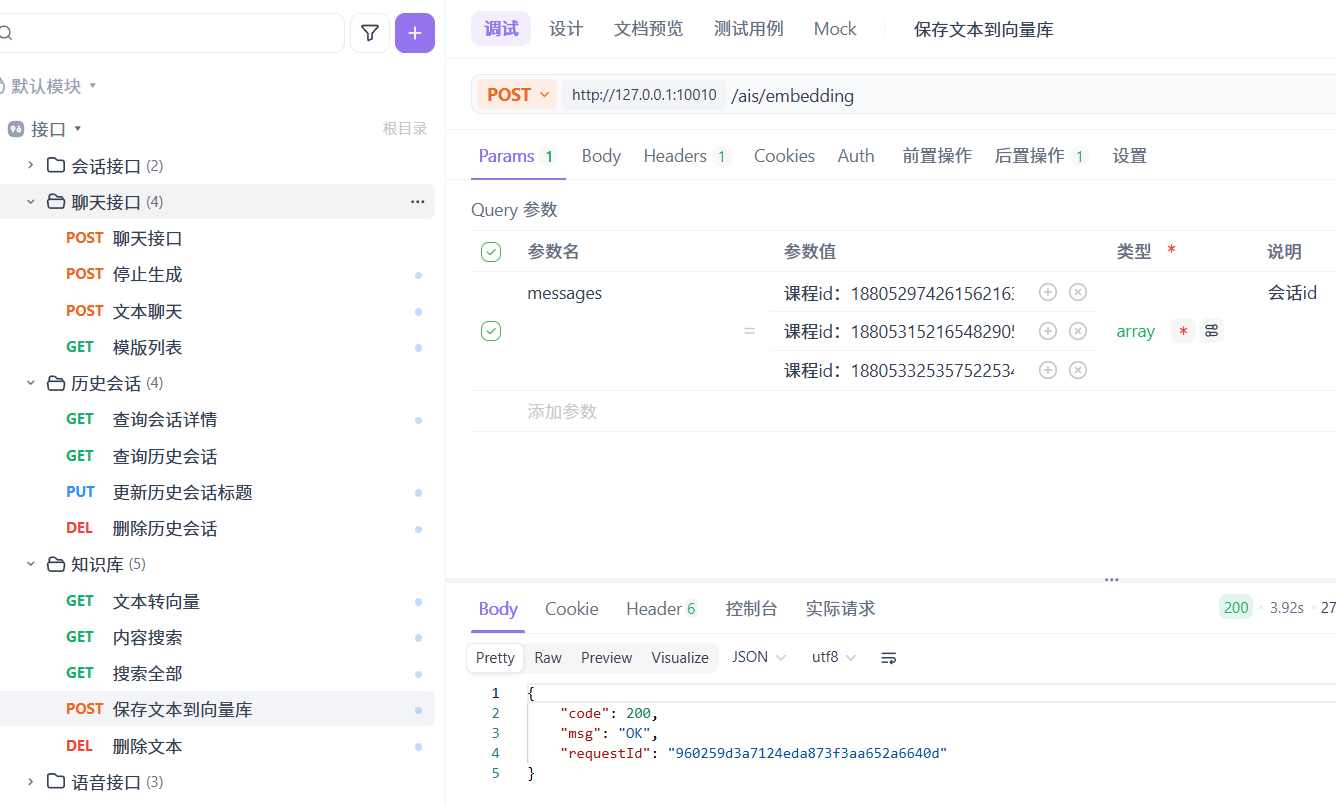
测试成功:
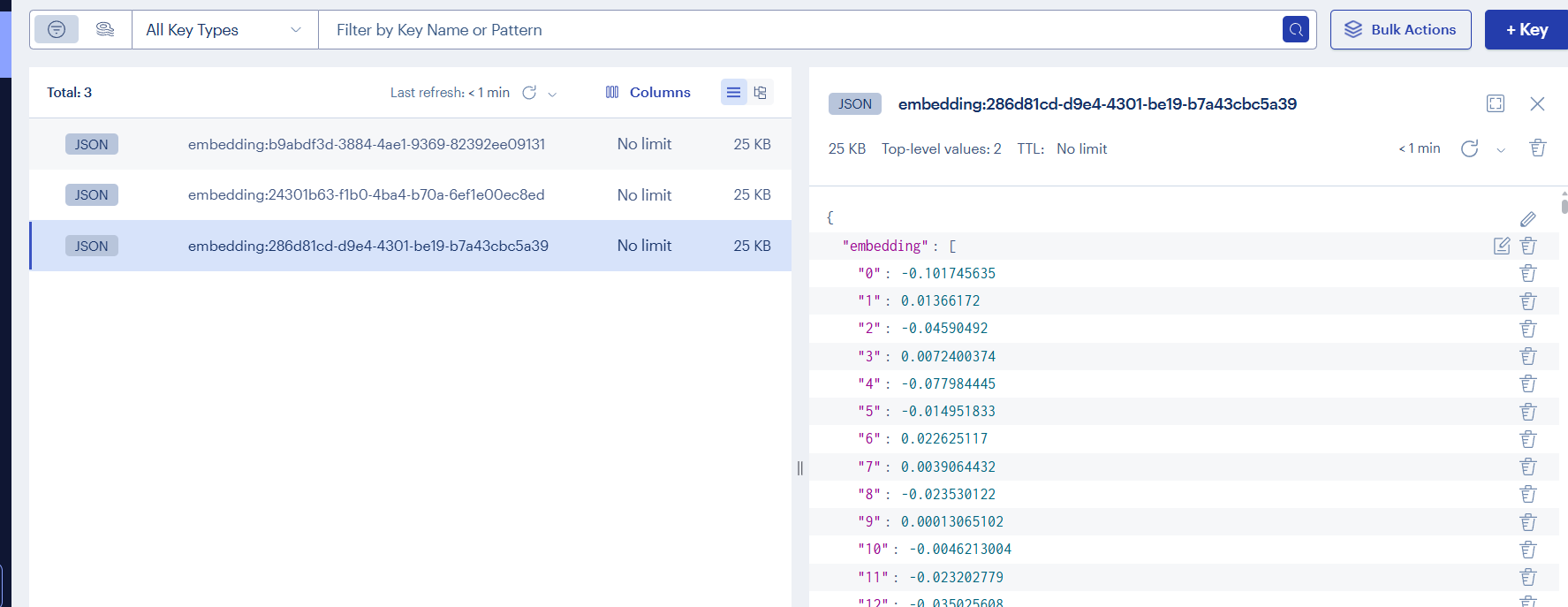
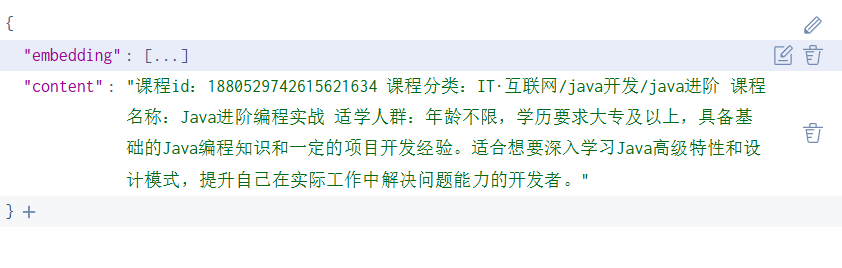
前端测试通过:

如果对你有帮助的话,请点赞,关注,收藏。热爱可抵一切!👍 ❤️ 🔥
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)